一、分库分表方式
1.1 垂直切分
1.1.1 垂直分表(拆分字段——但每张表的数据量是不变的)
把一张表的一部分字段存在一张新表里面,将另一部分字段存在另一张新表中

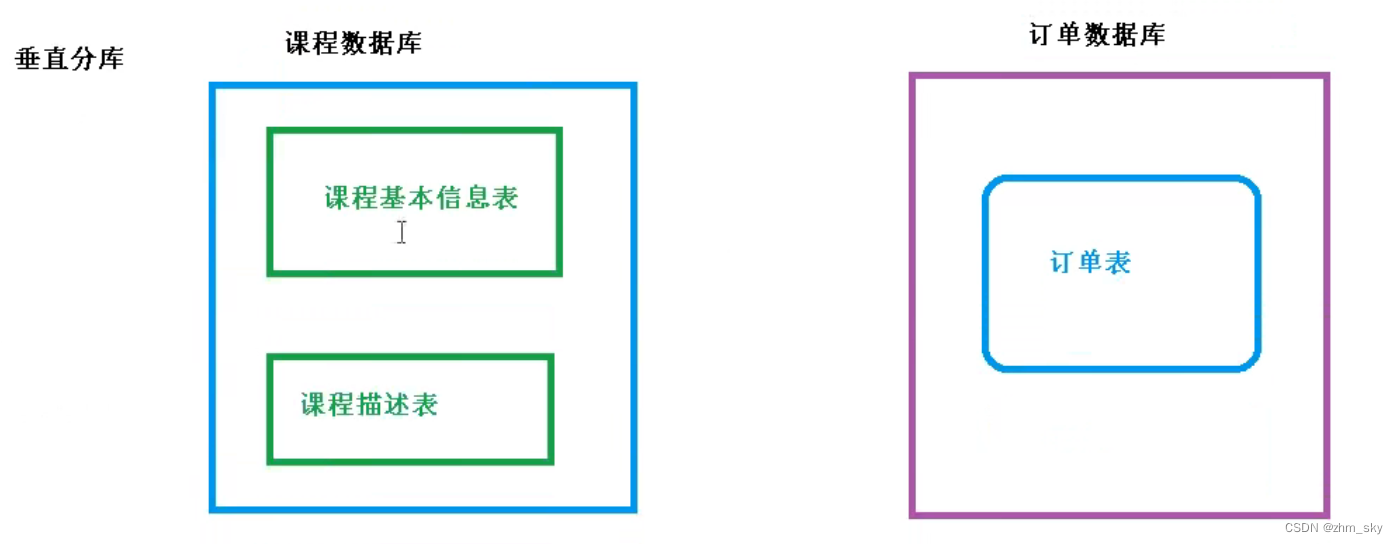
1.1.2 垂直分库(专库专表)
把单一数据库按照业务拆分,专库专表,减少单一数据库压力
1.2 水平切分
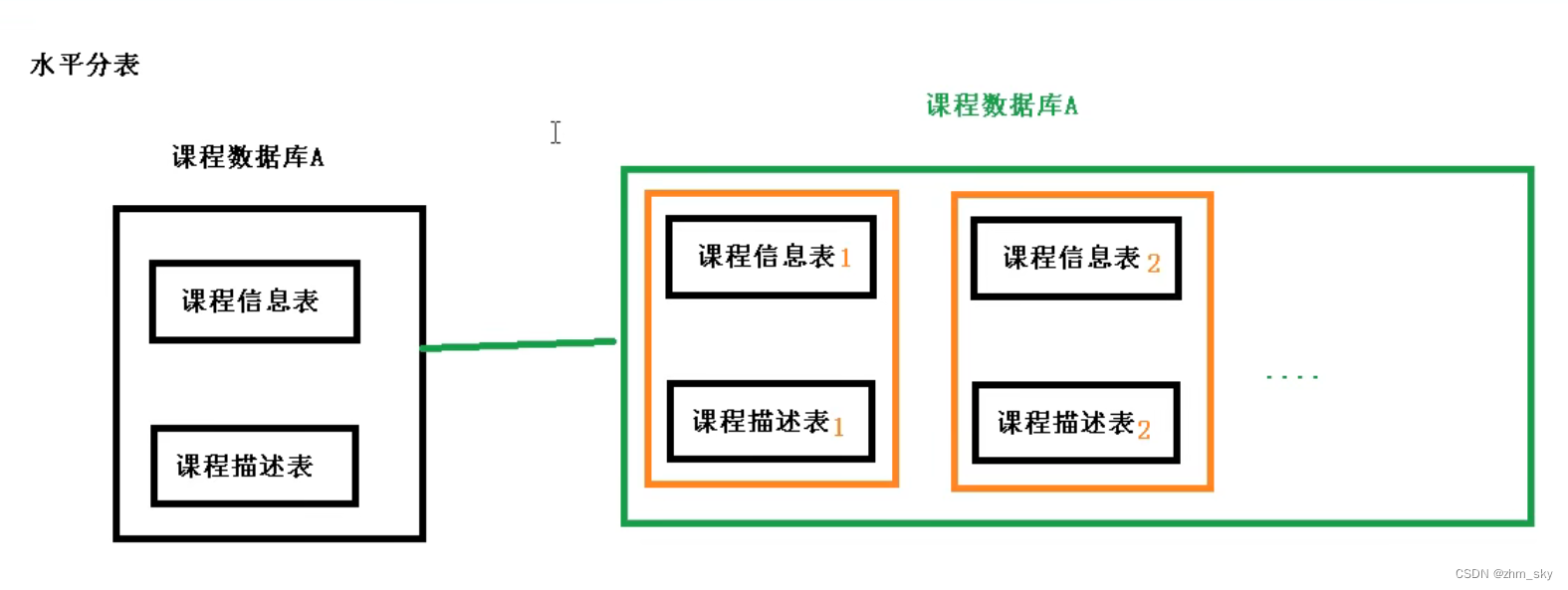
1.2.1 水平分表
在原数据表的基础上复制几份结构相同的副本数据表,再根据特定的规则进行读取,进一步减少单表压力
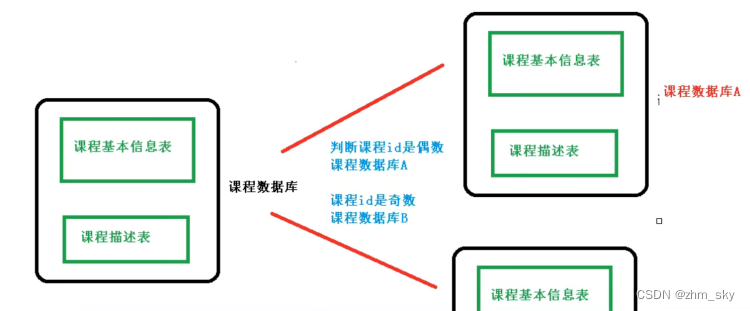
1.2.2 水平分库
在原数据库的基础上复制几份结构相同的副本数据库,再根据特定的规则进行读取,进一步缓解单库压力
二、分库分表的应用和问题
2.1 应用
(1)在数据库设计时就要考虑垂直分库和垂直分表
(2)随着数据量的不断增加,不要马上考虑做水平切分,首先考虑缓存处理、读写分离、索引等方式,如果这些方式不能根本解决问题,再考虑做水平分库和分表
2.2 问题
(1)跨节点连接查询(当要连接查询时,需要去不同的数据库单独查出来再进行数据拼接汇总)
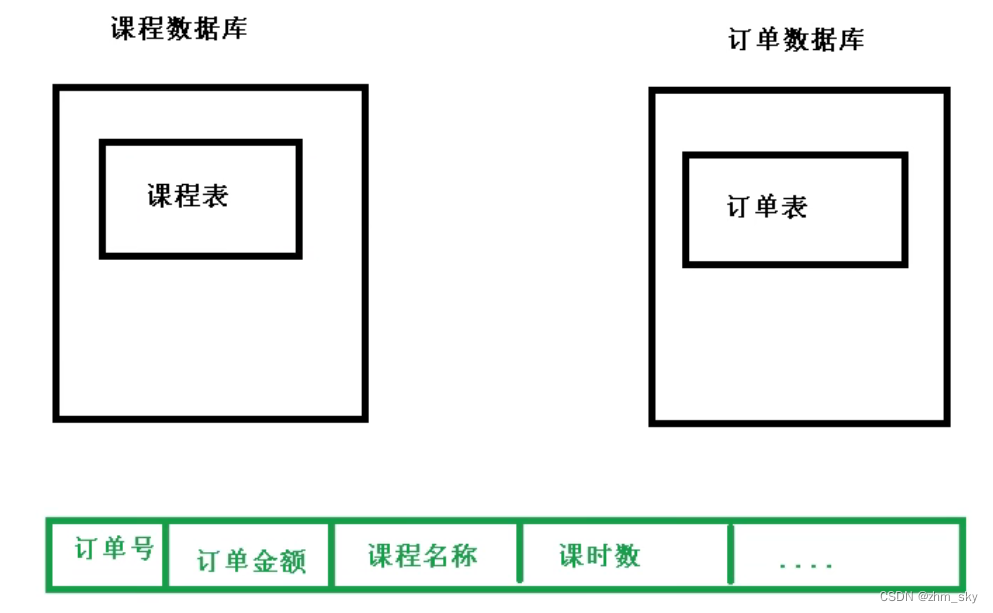
(2)多数据源管理问题
三、sharding-Jdbc(轻量的Java框架、JDBC的增强版)
它并不是做分库分表,而是对分库分表之后的数据表做相关操作,主要功能:数据分片、读写分离
3.1 水平分表
3.1.1 环境搭建
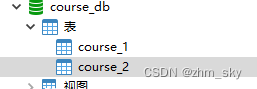
(1)创建一个数据库course_db及两张表,分别为course_1和course_2,两者表结构相同
(2)引入依赖
<!-- 引入druid -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.2.11</version>
</dependency>
<!-- 引入mybatis-plus -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.4.3.4</version>
</dependency>
<!-- mysql驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.49</version>
</dependency>
<!-- sharding-JDBC -->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>
(3)配置文件(官方文档)
# shardingjdbc 分片策略
# 配置数据源,给数据源起名称
spring.shardingsphere.datasource.names=db1
# 一个实体类对应多张表,覆盖
spring.main.allow-bean-definition-overriding=true
# 配置数据源具体内容,包含连接池,驱动,地址,用户名和密码
spring.shardingsphere.datasource.db1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.db1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.db1.url=jdbc:mysql://127.0.0.1:3306/course_db?useUnicode=true&&characterEncoding=utf-8&&useSSL=false
spring.shardingsphere.datasource.db1.username=root
spring.shardingsphere.datasource.db1.password=root
# 指定course表分布情况,配置表在哪个数据库里面,表名称都是什么 m1.course_1, m1.course_2
spring.shardingsphere.sharding.tables.course.actual-data-nodes=db1.course_$->{
1..2}
# 指定course表的主键生成策略
spring.shardingsphere.sharding.tables.course.key-generator.column=cid
spring.shardingsphere.sharding.tables.course.key-generator.type=SNOWFLAKE
# 数据表分片策略 约定cid为偶数存course_1表, 为奇数存course_2表
spring.shardingsphere.sharding.tables.course.table-strategy.inline.sharding-column=cid
spring.shardingsphere.sharding.tables.course.table-strategy.inline.algorithm-expression=course_$->{
cid % 2+1}
# 开启sql输出日志
spring.shardingsphere.props.sql.show=true
(4)插入数据测试
@Test
public void addCourse() {
for (int i = 1; i < 10; i++) {
Course course = new Course();
course.setCname("Java "+i);
course.setUserId(100L);
course.setCstatus("Normal");
courseMapper.insert(course);
}
}
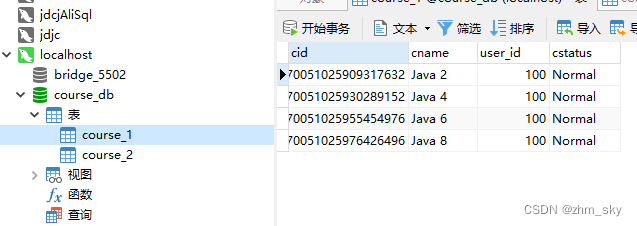
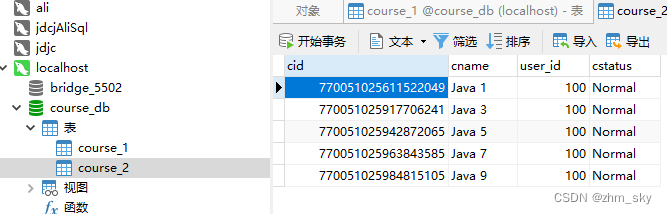
主键cid是偶数的全部分在了course_1表,奇数分在了course_2表
(5)查询测试
@Test
public void selectCourse() {
QueryWrapper<Course> wrapper = new QueryWrapper<>();
wrapper.eq("cid",770051025917706241L);
System.out.println(courseMapper.selectOne(wrapper));
}

770051025917706241是奇数,所以查询还是在course_2表
3.2 水平分库
3.2.1 环境搭建
(1)创建两个结构相同的数据库
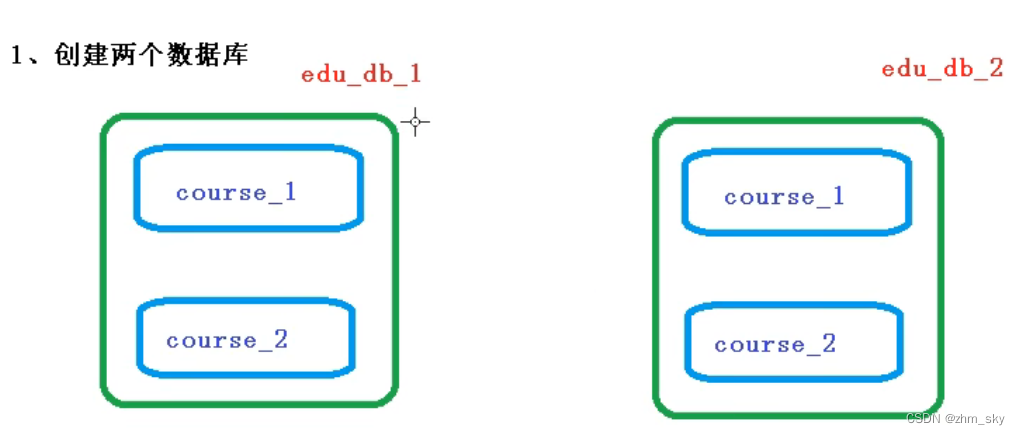
数据库规则:
userid为偶数时添加到edu_db_1数据库,为奇数时添加到edu_db_2数据库
表规则:
cid为偶数时添加到course_1表,为奇数时添加到course_2表

(2)配置文件
# shardingjdbc 分片策略(水平分库)
# 配置数据源,给数据源起名称(对应两个数据库)
spring.shardingsphere.datasource.names=db1,db2
# 一个实体类对应多张表,覆盖
spring.main.allow-bean-definition-overriding=true
# 配置第一个数据源具体内容,包含连接池,驱动,地址,用户名和密码
spring.shardingsphere.datasource.db1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.db1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.db1.url=jdbc:mysql://127.0.0.1:3306/edu_db_1?useUnicode=true&&characterEncoding=utf-8&&useSSL=false
spring.shardingsphere.datasource.db1.username=root
spring.shardingsphere.datasource.db1.password=root
# 配置第二个数据源具体内容,包含连接池,驱动,地址,用户名和密码
spring.shardingsphere.datasource.db2.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.db2.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.db2.url=jdbc:mysql://127.0.0.1:3306/edu_db_2?useUnicode=true&&characterEncoding=utf-8&&useSSL=false
spring.shardingsphere.datasource.db2.username=root
spring.shardingsphere.datasource.db2.password=root
# 指定数据库分布情况,数据表分布情况
# db1 db2 course_1 course_2
spring.shardingsphere.sharding.tables.course.actual-data-nodes=db$->{
1..2}.course_$->{
1..2}
# 指定course表的主键生成策略
spring.shardingsphere.sharding.tables.course.key-generator.column=cid
spring.shardingsphere.sharding.tables.course.key-generator.type=SNOWFLAKE
# 指定数据库分片策略(默认的,也就是对全部表的user_id字段都生效)
#spring.shardingsphere.sharding.default-database-strategy.inline.sharding-column=user_id
#spring.shardingsphere.sharding.default-database-strategy.inline.algorithm-expression=edu_db_$->{user_id%2+1}
# 指定数据库分片策略(指定表的某些字段生效)
spring.shardingsphere.sharding.tables.course.database-strategy.inline.sharding-column=user_id
spring.shardingsphere.sharding.tables.course.database-strategy.inline.algorithm-expression=db$->{
user_id % 2+1}
# 数据表分片策略 约定cid为偶数存course_1表, 为奇数存course_2表
spring.shardingsphere.sharding.tables.course.table-strategy.inline.sharding-column=cid
spring.shardingsphere.sharding.tables.course.table-strategy.inline.algorithm-expression=course_$->{
cid % 2+1}
# 开启sql输出日志
spring.shardingsphere.props.sql.show=true
(3)测试
@Test
public void insertCourse() {
for (int i = 1; i <= 10; i++) {
Course course = new Course();
//数据库(偶数在1 奇数在2)
course.setUserId(11L);
course.setCname("水平分库-" + i);
course.setCstatus("Normal");
courseMapper.insert(course);
}
}
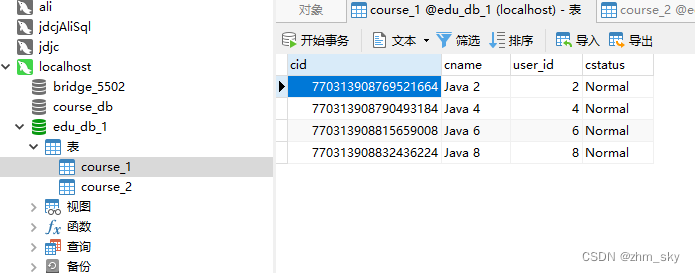
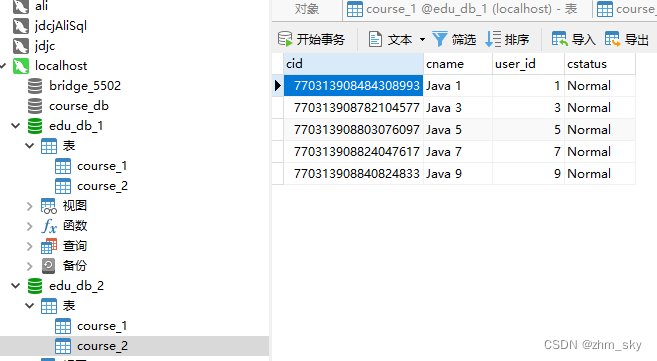
user_id为偶数存1号库,user_id为奇数存2号库;
cid为偶数存1号表,cid为奇数存2号表
3.3 垂直分库(专库专表)
3.3.1 环境搭建
(1)创建数据库
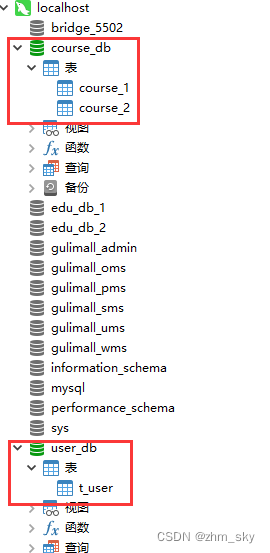
在上面水平分库的基础上再添加一个一个数据库user_db,并创建一张表t_user
(2)配置文件
# shardingjdbc 分片策略(垂直分库————专库专表)
# 配置数据源,给数据源起名称(对应两个数据库)
spring.shardingsphere.datasource.names=db1,db2,db3
# 一个实体类对应多张表,覆盖
spring.main.allow-bean-definition-overriding=true
# 配置第一个数据源具体内容,包含连接池,驱动,地址,用户名和密码
spring.shardingsphere.datasource.db1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.db1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.db1.url=jdbc:mysql://127.0.0.1:3306/edu_db_1?useUnicode=true&&characterEncoding=utf-8&&useSSL=false
spring.shardingsphere.datasource.db1.username=root
spring.shardingsphere.datasource.db1.password=root
# 配置第二个数据源具体内容,包含连接池,驱动,地址,用户名和密码
spring.shardingsphere.datasource.db2.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.db2.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.db2.url=jdbc:mysql://127.0.0.1:3306/edu_db_2?useUnicode=true&&characterEncoding=utf-8&&useSSL=false
spring.shardingsphere.datasource.db2.username=root
spring.shardingsphere.datasource.db2.password=root
# 配置第三个数据源具体内容,包含连接池,驱动,地址,用户名和密码
spring.shardingsphere.datasource.db3.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.db3.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.db3.url=jdbc:mysql://127.0.0.1:3306/user_db?useUnicode=true&&characterEncoding=utf-8&&useSSL=false
spring.shardingsphere.datasource.db3.username=root
spring.shardingsphere.datasource.db3.password=root
#--------------------------------------user_db数据库里面t_user 专库专表----------------------------------------------
# 配置user_db数据库里面t_user专库专表
spring.shardingsphere.sharding.tables.t_user.actual-data-nodes=db3.t_user
# 指定course表的主键生成策略
spring.shardingsphere.sharding.tables.t_user.key-generator.column=user_id
spring.shardingsphere.sharding.tables.t_user.key-generator.type=SNOWFLAKE
# 数据表分片策略 user表
spring.shardingsphere.sharding.tables.t_user.table-strategy.inline.sharding-column=user_id
spring.shardingsphere.sharding.tables.t_user.table-strategy.inline.algorithm-expression=t_user
#----------------------------------------edu_db_数据库里面course表 水平分库--------------------------------------------
# 配置edu_db_数据库里面course表的情况
spring.shardingsphere.sharding.tables.course.actual-data-nodes=db$->{
1..2}.course_$->{
1..2}
# 指定course表的主键生成策略
spring.shardingsphere.sharding.tables.course.key-generator.column=cid
spring.shardingsphere.sharding.tables.course.key-generator.type=SNOWFLAKE
# 数据表分片策略 约定cid为偶数存course_1表, 为奇数存course_2表
spring.shardingsphere.sharding.tables.course.table-strategy.inline.sharding-column=cid
spring.shardingsphere.sharding.tables.course.table-strategy.inline.algorithm-expression=course_$->{
cid % 2+1}
# 指定数据库分片策略(默认的,也就是对全部表的user_id字段都生效)
#spring.shardingsphere.sharding.default-database-strategy.inline.sharding-column=user_id
#spring.shardingsphere.sharding.default-database-strategy.inline.algorithm-expression=edu_db_$->{user_id%2+1}
# 指定数据库分片策略(指定表的某些字段生效)
spring.shardingsphere.sharding.tables.course.database-strategy.inline.sharding-column=user_id
spring.shardingsphere.sharding.tables.course.database-strategy.inline.algorithm-expression=db$->{
user_id % 2+1}
# 开启sql输出日志
spring.shardingsphere.props.sql.show=true
(3)测试
@Test
public void addUser(){
User user = new User();
user.setUsername("lucy");
user.setUstatus("Normal");
userMapper.insert(user);
}
@Test
public void findUser(){
List<User> users = userMapper.selectList(null);
System.out.println(users);
}
注意:数据表对应的实体类表名一定要和数据库表名相同(一定要能对应,否则可能会抛datasourse is null的异常)——最好指明数据库表名
四、Sharding-JDBC操作公共表
4.1 公共表
(1)存储固定数据的表,表数据很少发生变化,查询时经常进行关联
(2)在每个数据库中都有结构完全相同的表
实现操作公共表,也就是对每个数据库中的公共表同时进行添加、修改、删除操作
添加配置:
# 配置公共表
spring.shardingsphere.sharding.broadcast-tables=t_common
spring.shardingsphere.sharding.tables.t_common.key-generator.column=common_id
spring.shardingsphere.sharding.tables.t_common.key-generator.type=SNOWFLAKE
五、读写分离
5.1 概念
为了确保数据库的稳定性,大多拥有双机热备的功能,原理:主数据库(master)处理事务性增、删、改操作;从数据库(slave)处理select操作。
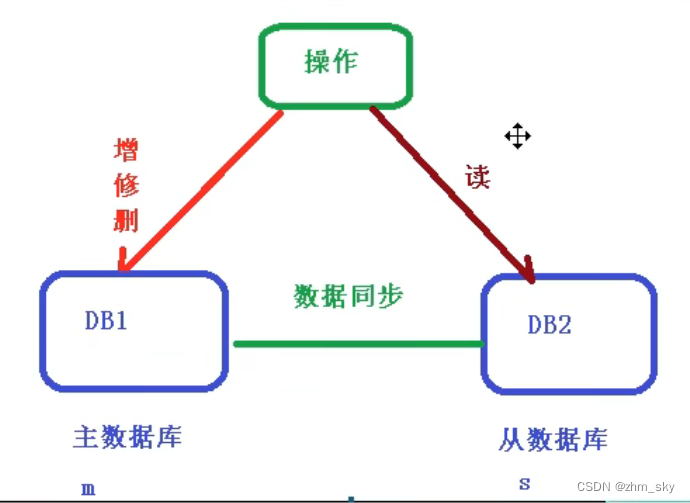
主从复制:当主服务器有写操作时,从服务器自动获取
原理:从服务器实时监控主服务器的binlog日志,当用户对主服务器进行写操作时改变了binlog日 志,从服务器拉取binlog日志读取并解析执行。从而实现与主数据库达到同步效果。
读写分离:写操作在主服务器,读操作在从服务器
5.2 mysql配置读写分离
(1)创建两个mysql数据库服务
直接复制之前mysql安装根目录,
修改配置(端口号、安装目录、数据存放目录),
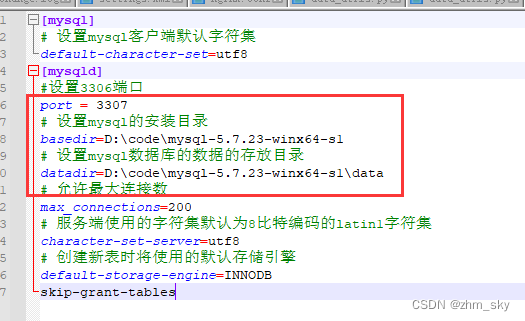
为修改后的从数据库安装windows服务,mysqls1是服务名
cmd管理员权限:
注册服务
mysqld install mysqls1 --defaults-file=“D:\code\mysql-5.7.23-winx64-s1\my.ini”
删除服务
sc delete 服务名称
连接从数据库,
(2)配置mysql主从数据库
修改主数据库配置文件my.ini
[mysqld]
#开启日志
log-bin = mysql-bin
#设置服务id,主从不能一致
server-id = 1
#选择ROW模式
binlog_format=ROW
#设置需要同步的数据库
binlog-do-db=user_db
#屏蔽系统库同步
binlog-ignore-db=mysql
binlog-ignore-db=information_schema
binlog-ignore-db=performance_schema
修改从数据库配置文件my.ini
[mysqld]
#从服务器配置
#开启日志
log-bin=mysql-bin
#设置服务id,主从不能一致
server-id=2
#选择ROW模式
binlog_format=ROW
#设置需要同步的数据库
replicate_wild_do_table=user_db.%
#屏蔽系统库同步
replicate_wild_ignore_table=mysql.%
replicate_wild_ignore_table=information-schema.%
replicate_wild_ignore_table=performance_schema.%