在前面的博客中,我们已经梳理过语言表示和语言模型,之所以将这两部分内容进行梳理,主要是因为分布式的词向量语言表示方式和使用神经网络语言模型来得到词向量这两部分,构成了后来的word2vec的发展,可以说是word2vec的基础。
1.什么是词向量
词向量,简单的说,就是使用固定维度的向量来表示一个词,分为One-Hot Representation和Distributed Representation两种,详细解释在前面已经讲过,这里不再赘述。在实际应用中,基于one-hot的向量虽然在传统的机器学习算法中取得了不错的成绩,但Distributed 的向量可以说更加具有鲁棒性,因为其考虑了语义的信息,更具合理性。借鉴大神的《word2vec中的数学原理详解》中的比喻似乎更加贴切,One-Hot Representation向量中只有一个非零分量,非常集中(有点孤注一掷的感觉),而对于Distributed Representation向量中,含有大量的非零分量,相对分散(有点平摊风险的感觉),把词的信息分散到各个分量上去了。
接下来所要讲的word2vec就是Distributed Representation词向量的一种形式。
2. word2vec
词向量的训练方式在前面已经说过,就是通过训练神经网络语言模型(NNLM)来获得,而word2vec是为一群用来产生词向量的相关模型。word2vec 是 Google 于 2013 年开源推出的一个用于获取 word vector 的工具包,它简单、高效。NNLM一般是一个三层的神经网络结构(这里,很多人将word2vec称为deep learning,其实从网络结构上来看,远没有达到deep learning的层次):输入层、隐藏层和输出层(softmax层)。
word2vec是如何定义数据的输入和输出呢?主要分为两种:CBOW模型(Continuous Bag-of-Words Model)和Skip-Gram模型(Continuous Skip-Gram Model)。在Tomas Mikolov的论文中,CBOW和Skip-Gram的结构其实也非常简单,都只包含三层结构:输入层(INPUT)、投影层(PROJECTION)(或者说是隐藏层是一个意思)和输出层(OUTPUT)。CBOW是在已知上下文w(t-2)、w(t-1)、w(t+1)和w(t+2)的情况下来预测中心词w(t),其结构如下左图;Skip-Gram是在已知中心词w(t)的情况下来预测上下文w(t-2)、w(t-1)、w(t+1)和w(t+2),其结构如下右图。
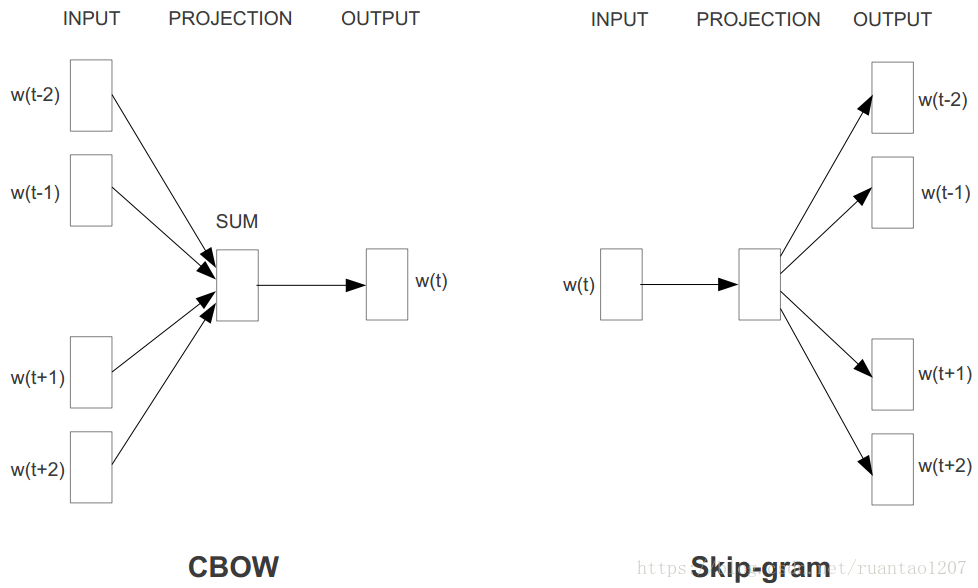
仔细一想,是不是觉得CBOW模型其实特别类似于n-gram,只不过n-gram是只使用历史信息来预测当前词,而CBOW使用了当前词的左右信息来同时预测。而Skip-gram只不过是将CBOW模型反过来预测罢了。
2.1 模型定义
我们设置一个大小为 t 的窗口,在语料库里随机抽取一个词 w(t),这个核心词的前 c 个和后 c 个单词构成该词的上下文,即
context(w(t)) = (w(t-c),...,w(t-1),w(t+1),...,w(t+c))
CBOW模型:最大化P(w(t)|context(w(t))),用context去预测词w;
Skip-Gram模型:最大化P(context(w(t))|w(t)),用词w去预测context。
但是在word2vec的第一篇论文【1】中,其实并没有给出具体模型的构建,而是在第二篇论文【2】中提到了Skip-Gram模型公式,即优化目标。
给定一个训练的序列w1,w2,...,wT,具体是最大化均值对数似然概率(Average Log Probability):
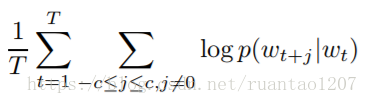
而两个词之间的 skip-gram 概率 p(wt+j|wt) 可以这样定义,就是在最后使用了一个Softmax:
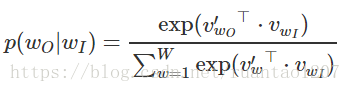
分子是把 输入词w 对应的词向量和 输出context(w) 里的某个词对应的词向量做内积,分母是把 输入词w 对应的词向量和词汇表中的所有词向量做内积。最后得到的结果要经过一个 Softmax,得到真正的概率。
由上述公式可知,在分母中,需要对输入词w和词汇表中的所有词的词向量做内积运算,时间复杂度过高,开销太大,因此效率低下。例如,词汇表的大小为|V|,一般包含(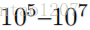
特别鸣谢:
【4】word2vec 笔记
【5】word2vec原理