使用Spark进行简单的数据统计
给定数据集为各年龄段不同性别的用户对电影观看情况的一个统计主要用了Spark中算子的一些操作
相关的数据文件

1. 年龄段在“18-24”的男性年轻人,最喜欢看哪10部
首先读取文件,在用户文件中读取符合条件的年轻人
val conf =new SparkConf().setAppName("read_gz_file").setMaster("local")
val sc =new SparkContext(conf)
val user = sc.textFile("users.dat")
val movies = sc.textFile("movies.dat")
val rating = sc.textFile("ratings.dat")
val M_user = user.map(_.split("::")).filter(temp =>
temp(2).toInt >= 18 & temp(2).toInt <= 24 & temp(1).equals("M") ).map{
x =>(x(0),(x(1),x(2)))
} 在rating文件中选择用户id和电影id,使用join操作,得出的对应信息,对value进行计数操作
val usrMo_Id = M_user.join(usr_movie).map(x => (x._1,x._2._2))//筛选出来的用户和他所对应的电影编号
val fav_movie = usrMo_Id.values.map(x =>(x,1)).reduceByKey(_+_).join(mov_Id).values.map(x=>
(x._2,x._1)).collectAsMap()//最喜欢的电影编号对应的名称
val topFav = fav_movie.toSeq.sortWith(_._2 > _._2).take(10)//进行排序,年龄在18-24的男性在对出现的次数进行排序的时候使用了collectAsmap的操作,变成sequence才会有sortwith的方法,即降序排列,这种方法代码比较长,在后面发现了一个比较好的,直接使用sortby(key,false)直接降序排序
统计结果
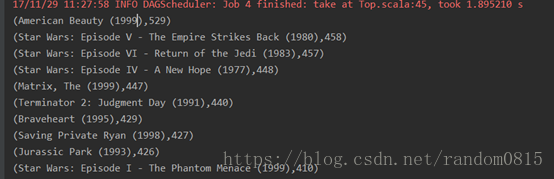
得分最高的10部电影;看过电影最多的前10个人;女性看多最多的10部电影;男性看过最多
的10部电影
1) 得分最高的10部电影在rating数据集中每个用户给电影都有一个打分,为了计算出的分最高的10个电影,要计算每个电影得分的平均值,首先在rating数据集中进行操作,主要使用了combinebykey函数,需要接收三个函数。为了保证平均数计算的准确性,将某个电影评分人数不够5人的就过滤掉了,组成了(电影id,平均分)这样的map集合
val top_rating = rating.map(_.split("::")).map(x => (x(1),x(2).toDouble)).combineByKey( rate => (rate,1), (acc:(Double,Int),rate) => (acc._1 + rate,acc._2+1), (acc1:(Double,Int),acc2:(Double,Int)) => (acc1._1 + acc2._1,acc1._2 + acc2._2) ).filter(_._2._2 > 5).map{ case (key, value) => (key, value._1 / value._2.toFloat)}进行join操作,把id和title对应起来,取出title和总数进行对应
val top_mov_name = mov_Id.join(top_rating).values.map{ x =>(x._1,x._2) }.sortBy(_._2,false).take(10)结果
2) 看过电影最多的前10个人
在rating中是所有看电影的用户,所以使用key进行map操作,进行计数,然后排序取出前十名
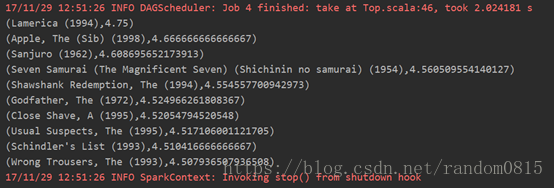
val top_user = usr_movie.keys.map(x => (x,1)).reduceByKey(_+_).
sortBy(_._2,false).take(10)//最爱看电影的十名用户结果
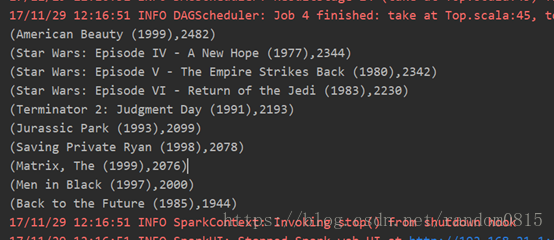
3) 男性看过最多的10部电影
筛选出全部的男性,在rating中进行的是join, 然后进行map操作筛选出全部男性用户对应的看的电影的编号因为join之后是一个key对应value是一个元组对的形式,选取value的第二个值,计算电影次数,和movie进行join找到对应的电影标题,最后得到的是(title,count)的形式
val Man_Id = M_user1.join(usr_movie).map(x => (x._1,x._2._2))//全部男性用户所对应的编号
val top_M_fav = Man_Id.values.map(x =>(x,1)).reduceByKey(_+_).join(mov_Id).values.map(x=>
(x._2,x._1)).sortBy(_._2,false).take(10)//全部男性最喜爱的10部电影结果
女性的统计方法和男性相同,只是筛选条件不同
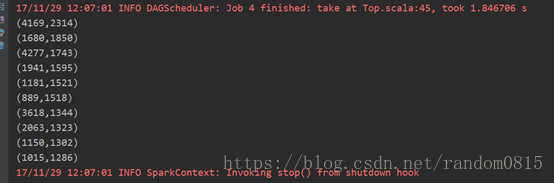
3. 利用数据集SogouQ2012.mini.tar.gz 将数据按照访问次数进行排序,求访问量前10的网站
gai’ti
object Sougou {
def main(args: Array[String]): Unit = {
val conf =new SparkConf().setAppName("read_gz_file").setMaster("local")
val sc =new SparkContext(conf)
val data = sc.textFile("SogouQ2012.mini.tar.gz")
//val data_rdd = data.collect()
val data_rdd = data.map(_.split("\t").last).map(x => (x,1)).reduceByKey(_+_)
.filter(_._2 != 1).sortBy(_._2,false)
data_rdd.take(10).foreach(println)
}
}该题目类似于wordcount的操作,这里主要是对Spark的一些Action算子的操作,具体的代码可以看这里
Sougou
movie
数据集