系列文章目录
RT-THREAD 内核快速入门(三) 信号量,互斥量,事件
文章目录
前言
这是这个系列编程的最后一篇,内容是中断与内存管理。学完这篇就能解决之前的疑惑为什么创建线程分为动态创建与静态创建,为什么不能在中断里面使用malloc,为什么线程比中断执行优先级要低。中断部分是中断锁以及中断的底半处理,内存管理介绍内存堆的使用。
一、中断
1.中断处理过程
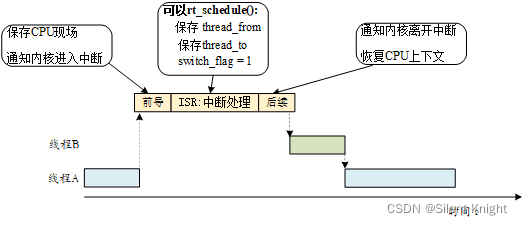
中断分前导过程,中断处理以及中断后续。中断进入过程与通常MCU的中断处理过程是类似的。
前导处理:CPU自动将当前环境的上下文寄存器压入栈中,并通知内核进入中断状态。
中断处理:在中断里面进行设置线程调度相关的操作(线程实际还未调度),并手动设置PendSV异常(PendSV 异常是专门用来辅助上下文切换的,且被初始化为最低优先级的异常)。
中断后续:通知内核离开中断状态,之后再进入PenSV中断辅助线程切换,线程才调度完毕。PenSV中断里面调用(rt_hw_context_switch_to(rt_uint32 to))函数进行线程调度,在Cortex-M架构的CPU都是在PenSV中断进行实际线程的调度。
//系统中断处理函数
void SysTick_Handler(void)
{
/* enter interrupt */
rt_interrupt_enter();//通知内核进入中断状态
rt_tick_increase();//线程调度设置
/* leave interrupt */
rt_interrupt_leave();//通知内核离开中断
}
2.中断应用
中断锁
中断锁是最简单的禁止线程访问临界区的方式,在前面我们了解到了,线程切换实际是在中断里面的,只要禁止了中断,线程不能切换,其他线程就不能访问临界区了。这是最简单粗暴的方式了,简单粗暴有简单粗暴的问题,最大的问题就是实时性得不到保存,中断都禁止了就不能进行任何有关于RTOS的操作,系统时值也得不到更新。所以中断锁适合简单的变量相加,一两行代码的样子,这样会比互斥量来的高效。
这里设计到的两个函数就是:
关闭全局中断API和打开中断API
//关闭全局中断
rt_base_t rt_hw_interrupt_disable(void);
//打开全局中断
void rt_hw_interrupt_enable(rt_base_t level);
我们看一下RTT官方通知线程进入中断的代码,这种变量+n的方式使用中断是十分简洁高效的。
void rt_interrupt_enter(void)
{
rt_base_t level;
level = rt_hw_interrupt_disable();
rt_interrupt_nest ++;
rt_hw_interrupt_enable(level);
}
对于操作复杂的事情,使用互斥量会更好
/* 获得互斥量锁 */
rt_mutex_take(sem_lock, RT_WAITING_FOREVER);
do_some_complexthing();
/* 释放互斥量锁 */
rt_mutex_release(sem_lock);
低半处理
低半处理是为了在加快中断的相应速度,用户需要保证所有的中断服务程序在尽可能短的时间内完成,尽可能不耽误其他中断的相应。因此中断用来做通知和接收数据,而不是用来处理数据。
中断处理:
上半处理:
在中断仅仅是用来接收或者缓冲数据,然后在中断里面仅作通知,通知线程去处理数据(处理数据通常是比较消耗时间的)。
低半处理:
中断结束后,线程获得中断的数据进行处理。
例子:
从串口中断接收字符串,当接收到结束字符串就通知线程进行处理,然后发送这个字符串的信息。
上半处理代码简单例子:
#define REVC_FLAG `A`
#define REVC_BUFF_MAX 50
rt_uint8_t reve_buff[REVC_BUFF_MAX];
rt_uint8_t count_buf=0;//计数接收数量
void HAL_UART_RxCpltCallback(UART_HandleTypeDef *huart)
{
rt_uint8_t temp_char;
//串口1
if(huart == &huart1)
{
HAL_UART_Receive_IT(&huart1,(uint8_t *)&temp_char,1,0xFFFF);//阻塞方式打印
if(temp_char!=REVC_FLAG||)
{
reve_buff[count_buf++]=temp_char;
}
//发送信号
if(reve_buff[count_buf]==REVC_FLAG)
{
rt_sem_release(usart1_sem);
}
HAL_UART_Receive_IT(&huart1,receive_data,2u);
}
}
低半处理
//发送线程入口函数
void sent_thread_enter(void)
{
while(1)
{
//获得信号
rt_sem_take(usart1_sem, RT_WAITING_FOREVER);
HAL_UART_Transmit(&huart1,reve_buff,count_buf,0xFFFF);
//之后就是清空缓存区与计数值
Clear_sent_data();
}
}
中断也有中断的问题,中断对于发送速度比较低的情况能很好的应对,但是如果发送速度多了,系统持续进入中断,时间花费在调度上面浪费比较多,想要就可以在某一段时间发送速度快的时候改为轮询的接收方式,减少系统调度时间。
二、内存管理
一般芯片分为两个部分ROM与RAM,ROM是芯片存放代码的地方,自己也可以把需要保存的数据存放在ROM里面。RAM是存放变量的地方。它们的最核心的区别是掉电ROM掉电数据不丢失,RAM掉电数据丢失。ROM的读写速度比RAM要慢,
1.程序内存分布
MDK编译器输出的信息
Program Size: Code=92614 RO-data=234398 RW-data=3740 ZI-data=58780
FromELF: creating hex file...
"SIT_CODE\SIT_CODE.axf" - 0 Error(s), 3 Warning(s).
Build Time Elapsed: 00:00:23
一般编译器将MCU会将程序分为
-
Code:代码段,存放程序的代码部分;
-
RO-data:只读数据段,存放程序中定义的常量;
-
RW-data:读写数据段,存放初始化为非 0 值的全局变量;
-
ZI-data:0 数据段,存放未初始化的全局变量及初始化为 0 的变量;
在生成的.map文件中会有相关统计
==============================================================================
Total RO Size (Code + RO Data) 327012 ( 319.35kB)
Total RW Size (RW Data + ZI Data) 62520 ( 61.05kB)
Total ROM Size (Code + RO Data + RW Data) 328304 ( 320.61kB)
==============================================================================
RO+RW部分就是需要写入Flash的大小。
2.内存中的堆(Stack)栈(Heap)
内存中的堆栈与数据结构中的堆栈是不一样的。堆和栈都是一块内存,都是存放在RAM里面的。区别是堆是由程序自动分配的,想到了啥,没错,局部变量,我们不需要申请,这里的数据是在堆上面的。而栈是需要主动申请的,通过malloc的方式,容易导致内存泄漏。栈比堆灵活,但速度比堆要慢。这由于内存分配有啥关系。在MCU中堆栈是可以手动进行分配的,以STM32的启动文件为例,可以通过手动设置堆栈的大小使得符合项目的需求,如果我们使用。
;*******************************************************************************
;* <<< Use Configuration Wizard in Context Menu >>>
;
; Amount of memory (in bytes) allocated for Stack
; Tailor this value to your application needs
; <h> Stack Configuration
; <o> Stack Size (in Bytes) <0x0-0xFFFFFFFF:8>
; </h>
Stack_Size EQU 0x2000
AREA STACK, NOINIT, READWRITE, ALIGN=3
Stack_Mem SPACE Stack_Size
__initial_sp
; <h> Heap Configuration
; <o> Heap Size (in Bytes) <0x0-0xFFFFFFFF:8>
; </h>
Heap_Size EQU 0X1000
运行前后内存分配:
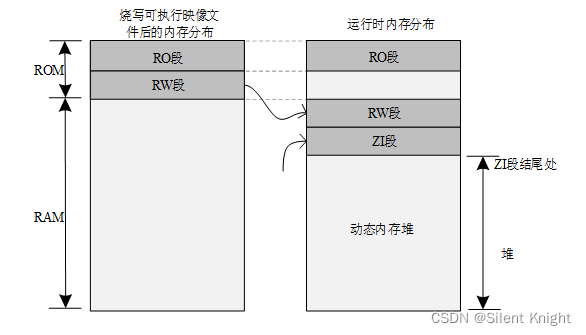
可见运行前,数据都在ROM(flash)中,直到运行的时候把RW+ZI段的数据移动到RAM里面。
2.静态内存堆与动态内存堆
Rt-thead内核将内存分为动态内存堆与静态内存堆。它们的区别在于动态内存堆是程序运行时候进行分配的(malloc的方式分配),而静态内存堆在编译的时候进行分配,存放在RW段。静态内存没有动态内存堆灵活,但是运行速度比动态内存堆要快,内存不能回收。
在RTT标准版中,RAM中未使用的内存区域都定义为动态内存堆,详细看上图。而在RTT-nano中,动态内存堆其实是通过分配一块大的数组(连续的内存块作为动态内存堆)。
这是标准RTT内核的动态内存堆大小的定义:上图图示,将未使用的RAM作为动态内存的大小
#ifdef RT_USING_HEAP
rt_system_heap_init((void *)HEAP_BEGIN, (void *)HEAP_END);
#endif
void rt_system_heap_init(void *begin_addr, void *end_addr)
{
/* initialize a default heap in the system */
rt_memheap_init(&_heap,
"heap",
begin_addr,
(rt_uint32_t)end_addr - (rt_uint32_t)begin_addr);
}
RTT-nano定义:定义一个rt_heap[RT_HEAP_SIZE];数组作为内存堆。
#if defined(RT_USING_USER_MAIN) && defined(RT_USING_HEAP)
/*
* Please modify RT_HEAP_SIZE if you enable RT_USING_HEAP
* the RT_HEAP_SIZE max value = (sram size - ZI size), 1024 means 1024 bytes
*/
#define RT_HEAP_SIZE (15*1024)
static rt_uint8_t rt_heap[RT_HEAP_SIZE];
RT_WEAK void *rt_heap_begin_get(void)
{
return rt_heap;
}
RT_WEAK void *rt_heap_end_get(void)
{
return rt_heap + RT_HEAP_SIZE;
}
#endif
三、动态创建与静态创建
知道上面这些就解决了为什么RTT创建的线程,信号量,互斥量,邮箱分为动态创建和静态创建了。下面简单介绍它们的区别。
相同点:
-
创建的变量都是分配在RAM中的,一个编译时后分配,一个运行时分配。
-
使用方式的一样的。只是内存分配不同而已。
不同点:
- 运行的速度不一样。静态比动态要快。
- 静态创建不能被回收,动态创建的内存可以被回收。
- 灵活度不一样,动态线程做可以运行时候创建线程和回收线程等操作。
根据不同特点可以灵活运用两种方式进行动静态的创建,利用他们的优势,规避劣势。比如一次性线程就可以使用动态创建的方式,创建一个动态线程,用完就释放内存。永久不释放的线程就使用静态量,加快运行速度。
四、内存算法
RTT在使用动态内存的时候一共有三种算法,根据RAM的不同可以选择不同的算法去管理动态内存。我也不是做算法这块的,没有研究,这里简单说一下使用场景以及为什么使用。
使用内存管理算法的优势
1:能够确定分配内存的时间。由于是RTOS实时操作系统分配时间是需要可预测的,这才能达到稳定的计时,而一般的分配算法做不到。
2:避免运行过程中过多的内存碎片,导致不能申请到需要大小的内存块。
3:能够根据不同大小的内存选择不同的算法优化效率。
1.三种内存管理算法
-
小内存块的分配管理(小内存管理算法):适合内存少于2M的MCU(RAM)。
-
大内存块的分配管理(slab 管理算法):系统资源比较丰富的MCU,提供了一种近似多内存池管理算法的快速算法。
-
多内存堆的分配情况(memheap 管理算法):方法适用于系统存在多个内存堆的情况,它可以将多个内存 “粘贴” 在一起,形成一个大的内存堆,用户使用起来会非常方便。
使用注意:
- 使用时候只能选择其中的一个或者不选
- 不能在中断中使用,因为它可能会引起当前上下文被挂起等待。当线程需要分配内存堆的时候,而内存不够会线程挂起,有线程内存释放的时候,会唤醒申请的线程分配内存。
- 使用方法都是一样的,也就是接口类似。
2.内存堆管理例程
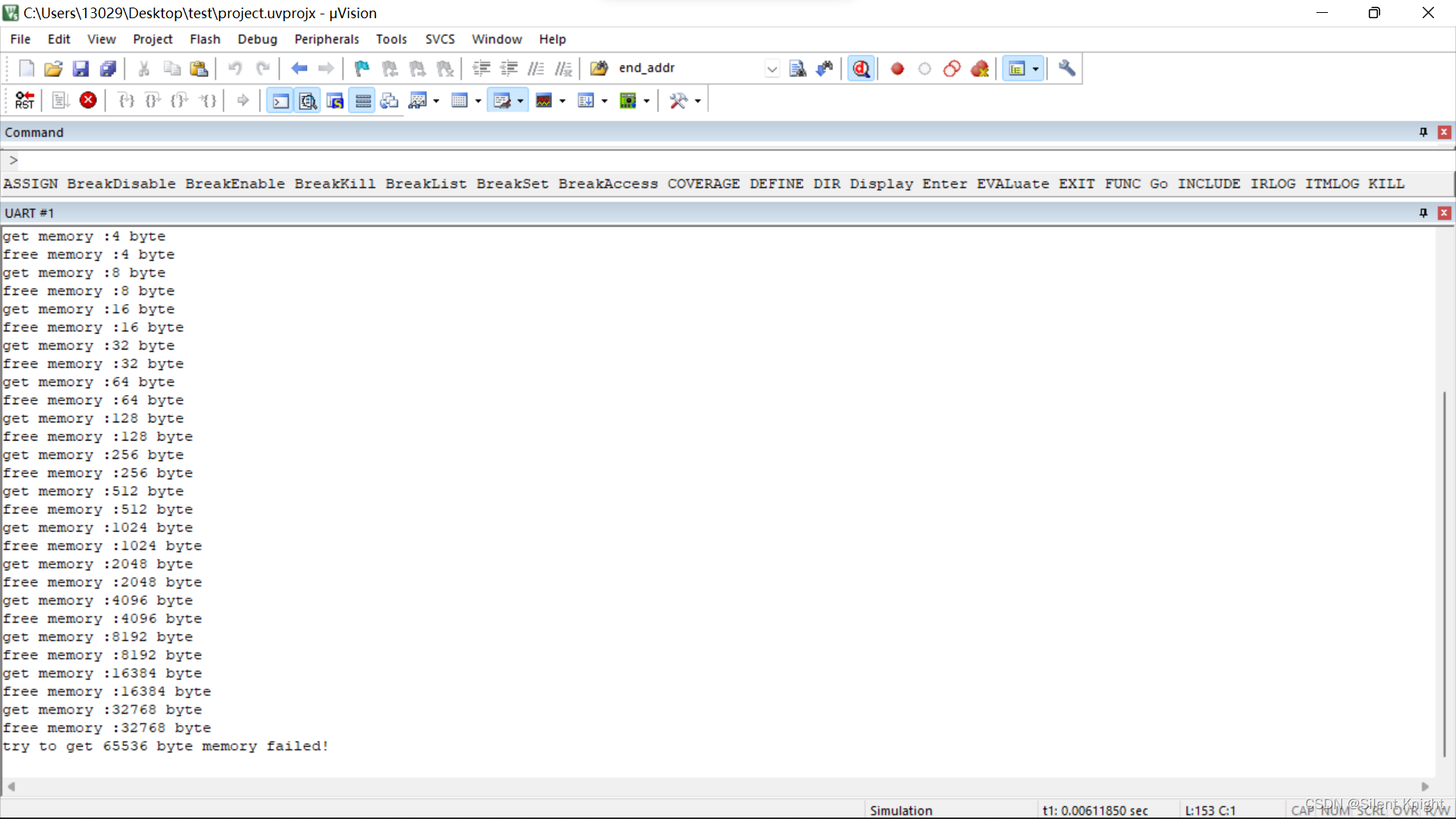
这里使用和malloc和free的使用差不多,与静态分配的变量使用区别是没有变量名作为地址访问,需要函数指针,依然用RTT官方的例程。
#include <rtthread.h>
#define THREAD_PRIORITY 25
#define THREAD_STACK_SIZE 512
#define THREAD_TIMESLICE 5
/* 线程入口 */
void thread1_entry(void *parameter)
{
int i;
char *ptr = RT_NULL; /* 内存块的指针 */
for (i = 0; ; i++)
{
/* 每次分配 (1 << i) 大小字节数的内存空间 */
ptr = rt_malloc(1 << i);
/* 如果分配成功 */
if (ptr != RT_NULL)
{
rt_kprintf("get memory :%d byte\n", (1 << i));
/* 释放内存块 */
rt_free(ptr);
rt_kprintf("free memory :%d byte\n", (1 << i));
ptr = RT_NULL;
}
else
{
rt_kprintf("try to get %d byte memory failed!\n", (1 << i));
return;
}
}
}
int dynmem_sample(void)
{
rt_thread_t tid = RT_NULL;
/* 创建线程 1 */
tid = rt_thread_create("thread1",
thread1_entry, RT_NULL,
THREAD_STACK_SIZE,
THREAD_PRIORITY,
THREAD_TIMESLICE);
if (tid != RT_NULL)
rt_thread_startup(tid);
return 0;
}
/* 导出到 msh 命令列表中 */
MSH_CMD_EXPORT(dynmem_sample, dynmem sample);
运行结果: