(一)idea工具开发数据生成模拟程序
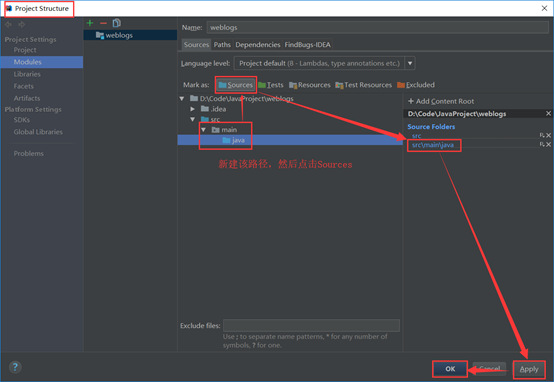
1.在idea开发工具中构建weblogs项目(Java项目),然后设置sources目录。
在java目录下新建ReadWrite类
package main.java;
import java.io.*;
public class ReadWrite {
static String readFileName;
static String writeFileName;
public static void main(String args[]){
readFileName = args[0];
writeFileName = args[1];
try {
// readInput();
readFileByLines(readFileName);
}catch(Exception e){
}
}
public static void readFileByLines(String fileName) {
FileInputStream fis = null;
InputStreamReader isr = null;
BufferedReader br = null;
String tempString = null;
try {
System.out.println("以行为单位读取文件内容,一次读一整行:");
fis = new FileInputStream(fileName);// FileInputStream
// 从文件系统中的某个文件中获取字节
isr = new InputStreamReader(fis,"GBK");
br = new BufferedReader(isr);
int count=0;
while ((tempString = br.readLine()) != null) {
count++;
// 显示行号
Thread.sleep(300);
String str = new String(tempString.getBytes("UTF8"),"GBK");
System.out.println("row:"+count+">>>>>>>>"+tempString);
method1(writeFileName,tempString);
//appendMethodA(writeFileName,tempString);
}
isr.close();
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
if (isr != null) {
try {
isr.close();
} catch (IOException e1) {
}
}
}
}
public static void method1(String file, String conent) {
BufferedWriter out = null;
try {
out = new BufferedWriter(new OutputStreamWriter(
new FileOutputStream(file, true)));
out.write("\n");
out.write(conent);
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
out.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}2.参照前面idea工具项目打包方式,将该项目打成weblogs.jar包,然后上传至bigdata-pro01.kfk.com节点的/opt/jars目录下(目录需要提前创建)






在三个节点上新建/opt/jars路径
[kfk@bigdata-pro01 ~]$ cd /opt/
[kfk@bigdata-pro01 opt]$ ll
total 16
drwxr-xr-x. 2 kfk kfk 4096 Oct 30 16:21 datas
drwxr-xr-x. 8 kfk kfk 4096 Oct 25 09:50 modules
drwxr-xr-x. 2 kfk kfk 4096 Oct 25 09:47 softwares
drwxr-xr-x. 2 kfk kfk 4096 Oct 19 09:28 tools
[kfk@bigdata-pro01 opt]$ sudo mkdir jars
[kfk@bigdata-pro01 opt]$ ll
total 20
drwxr-xr-x. 2 kfk kfk 4096 Oct 30 16:21 datas
drwxr-xr-x 2 root root 4096 Oct 31 15:29 jars
drwxr-xr-x. 8 kfk kfk 4096 Oct 25 09:50 modules
drwxr-xr-x. 2 kfk kfk 4096 Oct 25 09:47 softwares
drwxr-xr-x. 2 kfk kfk 4096 Oct 19 09:28 tools
[kfk@bigdata-pro01 opt]$ sudo chown -R kfk:kfk jars/
[kfk@bigdata-pro01 opt]$ ll
total 20
drwxr-xr-x. 2 kfk kfk 4096 Oct 30 16:21 datas
drwxr-xr-x 2 kfk kfk 4096 Oct 31 15:29 jars
drwxr-xr-x. 8 kfk kfk 4096 Oct 25 09:50 modules
drwxr-xr-x. 2 kfk kfk 4096 Oct 25 09:47 softwares
drwxr-xr-x. 2 kfk kfk 4096 Oct 19 09:28 tools
[kfk@bigdata-pro01 opt]$ cd jars/(用FileZilla或者Xftp等工具上传)
[kfk@bigdata-pro01 jars]$ ls
weblogs.jar3.将weblogs.jar分发到另外两个节点
1)在另外两个节点上分别创建/opt/jars目录
mkdir /opt/jars2)将weblogs.jar分发到另外两个节点
scp weblogs.jar bigdata-pro02.kfk.com:/opt/jars/
scp weblogs.jar bigdata-pro03.kfk.com:/opt/jars/3)分配执行权限
[kfk@bigdata-pro01 jars]$ chmod 777 weblogs.jar
[kfk@bigdata-pro01 jars]$ ll
total 4
-rwxrwxrwx 1 kfk kfk 2201 Oct 31 15:37 weblogs.jar4.编写运行模拟程序的shell脚本
1)在bigdata-pro02.kfk.com节点的/opt/datas目录下,创建weblog-shell.sh脚本。

vi weblog-shell.sh
#/bin/bash
echo "start log......"
#第一个参数是原日志文件,第二个参数是日志生成输出文件
java -jar /opt/jars/weblogs.jar /opt/datas/weblog.log /opt/datas/weblog-flume.log创建输出文件(节点2和节点3)

修改weblog-shell.sh可执行权限
chmod 777 weblog-shell.sh2)将bigdata-pro02.kfk.com节点上的/opt/datas/目录拷贝到bigdata-pro03节点.kfk.com
scp -r /opt/datas/ bigdata-pro03.kfk.com:/opt/datas/3)修改bigdata-pro02.kfk.com和bigdata-pro03.kfk.com节点上面日志采集文件路径。以bigdata-pro02.kfk.com节点为例。
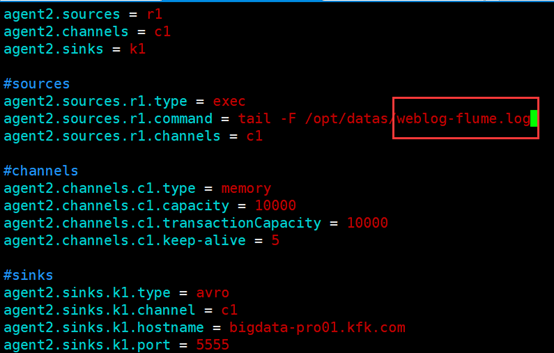
vi flume-conf.properties
agent2.sources = r1
agent2.channels = c1
agent2.sinks = k1
agent2.sources.r1.type = exec
#修改采集日志文件路径,bigdata-pro03.kfk.com节点也是修改此处
agent2.sources.r1.command = tail -F /opt/datas/weblog-flume.log
agent2.sources.r1.channels = c1
agent2.channels.c1.type = memory
agent2.channels.c1.capacity = 10000
agent2.channels.c1.transactionCapacity = 10000
agent2.channels.c1.keep-alive = 5
agent2.sinks.k1.type = avro
agent2.sinks.k1.channel = c1
agent2.sinks.k1.hostname = bigdata-pro01.kfk.com
agent2.sinks.k1.port = 5555(二)编写启动flume服务程序的shell脚本
1.在bigdata-pro02.kfk.com节点的flume安装目录下编写flume启动脚本。
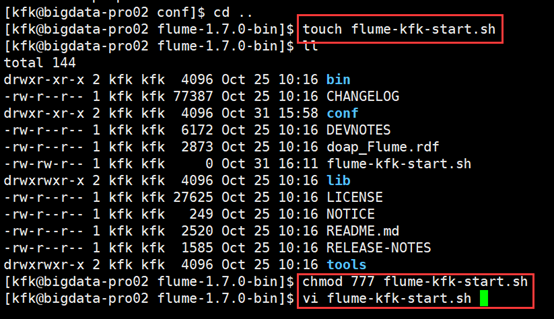
vi flume-kfk-start.sh
#/bin/bash
echo "flume-2 start ......"
bin/flume-ng agent --conf conf -f conf/flume-conf.properties -n agent2 -Dflume.root.logger=INFO,console然后修改一下日志目录

2.在bigdata-pro03.kfk.com节点的flume安装目录下编写flume启动脚本。
vi flume-kfk-start.sh
#/bin/bash
echo "flume-3 start ......"
bin/flume-ng agent --conf conf -f conf/flume-conf.properties -n agent3 -Dflume.root.logger=INFO,console3.在bigdata-pro01.kfk.com节点的flume安装目录下编写flume启动脚本。
vi flume-kfk-start.sh
#/bin/bash
echo "flume-1 start ......"
bin/flume-ng agent --conf conf -f conf/flume-conf.properties -n agent1 -Dflume.root.logger=INFO,console(三)编写Kafka Consumer执行脚本
1.在bigdata-pro01.kfk.com节点的Kafka安装目录下编写Kafka Consumer执行脚本
vi kfk-test-consumer.sh
#/bin/bash
echo "kfk-kafka-consumer.sh start ......"
bin/kafka-console-consumer.sh --zookeeper bigdata-pro01.kfk.com:2181,bigdata-pro02.kfk.com:2181,bigdata-pro03.kfk.com:2181 --from-beginning --topic test2.将kfk-test-consumer.sh脚本分发另外两个节点
scp kfk-test-consumer.sh bigdata-pro02.kfk.com:/opt/modules/kakfa_2.11-0.8.2.1/
scp kfk-test-consumer.sh bigdata-pro03.kfk.com:/opt/modules/kakfa_2.11-0.8.2.1/(四)启动模拟程序并测试
在bigdata-pro02.kfk.com节点和bigdata-pro03.kfk.com节点启动日志产生脚本,模拟产生日志是否正常。
/opt/datas/weblog-shell.sh 

(五)启动数据采集所有服务
1.启动Zookeeper服务
bin/zkServer.sh start2.启动hdfs服务
在启动之前别忘了我们选择使用的集群还不是HA的hdfs集群,所以需要替换过来。(在所有节点进行以下操作)
[kfk@bigdata-pro01 ~]$ cd /opt/modules/hadoop-2.6.0/etc/
[kfk@bigdata-pro01 etc]$ ls
hadoop hadoop-ha
[kfk@bigdata-pro01 etc]$ mv hadoop hadoop-dist
[kfk@bigdata-pro01 etc]$ ls
hadoop-dist hadoop-ha
[kfk@bigdata-pro01 etc]$ mv hadoop-ha hadoop
[kfk@bigdata-pro01 etc]$ ls
hadoop hadoop-dist
[kfk@bigdata-pro01 etc]$ cd ..
[kfk@bigdata-pro01 hadoop-2.6.0]$ cd data/
[kfk@bigdata-pro01 data]$ ls
jn tmp tmp-ha
[kfk@bigdata-pro01 data]$ mv tmp tmp-dist
[kfk@bigdata-pro01 data]$ ls
jn tmp-dist tmp-ha
[kfk@bigdata-pro01 data]$ mv tmp-ha tmp
[kfk@bigdata-pro01 data]$ ls
jn tmp tmp-dist然后启动dfs服务
sbin/start-dfs.sh(节点1)
sbin/hadoop-daemon.sh start zkfc(节点1和2)3.启动HBase服务
[kfk@bigdata-pro01 hadoop-2.6.0]$ cd ../hbase-0.98.6-cdh5.3.0/
[kfk@bigdata-pro01 hbase-0.98.6-cdh5.3.0]$ bin/start-hbase.sh
bigdata-pro01.kfk.com: starting zookeeper, logging to /opt/modules/hbase-0.98.6-cdh5.3.0/bin/../logs/hbase-kfk-zookeeper-bigdata-pro01.kfk.com.out
bigdata-pro02.kfk.com: starting zookeeper, logging to /opt/modules/hbase-0.98.6-cdh5.3.0/bin/../logs/hbase-kfk-zookeeper-bigdata-pro02.kfk.com.out
bigdata-pro03.kfk.com: starting zookeeper, logging to /opt/modules/hbase-0.98.6-cdh5.3.0/bin/../logs/hbase-kfk-zookeeper-bigdata-pro03.kfk.com.out
starting master, logging to /opt/modules/hbase-0.98.6-cdh5.3.0/bin/../logs/hbase-kfk-master-bigdata-pro01.kfk.com.out
bigdata-pro03.kfk.com: starting regionserver, logging to /opt/modules/hbase-0.98.6-cdh5.3.0/bin/../logs/hbase-kfk-regionserver-bigdata-pro03.kfk.com.out
bigdata-pro02.kfk.com: starting regionserver, logging to /opt/modules/hbase-0.98.6-cdh5.3.0/bin/../logs/hbase-kfk-regionserver-bigdata-pro02.kfk.com.out
bigdata-pro01.kfk.com: starting regionserver, logging to /opt/modules/hbase-0.98.6-cdh5.3.0/bin/../logs/hbase-kfk-regionserver-bigdata-pro01.kfk.com.out
[kfk@bigdata-pro01 hbase-0.98.6-cdh5.3.0]$ jps
4001 Jps
3570 DFSZKFailoverController
3954 HRegionServer
3128 NameNode
3416 JournalNode
1964 QuorumPeerMain
3854 HMaster
3231 DataNode但是现在虽然启动成功了,再jps一次发现HMaster又没了,查看日志如下:
2018-11-01 10:06:28,185 INFO [master:bigdata-pro01:60000] http.HttpServer: Jetty bound to port 60010
2018-11-01 10:06:28,185 INFO [master:bigdata-pro01:60000] mortbay.log: jetty-6.1.26.cloudera.4
2018-11-01 10:06:28,640 INFO [master:bigdata-pro01:60000] mortbay.log: Started [email protected]:60010
2018-11-01 10:06:28,757 DEBUG [main-EventThread] master.ActiveMasterManager: A master is now available
2018-11-01 10:06:28,760 INFO [master:bigdata-pro01:60000] master.ActiveMasterManager: Registered Active Master=bigdata-pro01.kfk.com,60000,1541037986041
2018-11-01 10:06:28,768 INFO [master:bigdata-pro01:60000] Configuration.deprecation: fs.default.name is deprecated. Instead, use fs.defaultFS
2018-11-01 10:06:28,889 FATAL [master:bigdata-pro01:60000] master.HMaster: Unhandled exception. Starting shutdown.
java.net.ConnectException: Call From bigdata-pro01.kfk.com/192.168.86.151 to bigdata-pro01.kfk.com:9000 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:422)
at org.apache.hadoop.net.NetUtils.wrapWithMessage(NetUtils.java:783)
at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:730)
at org.apache.hadoop.ipc.Client.call(Client.java:1415)
at org.apache.hadoop.ipc.Client.call(Client.java:1364)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:206)
at com.sun.proxy.$Proxy14.setSafeMode(Unknown Source)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.setSafeMode(ClientNamenodeProtocolTranslatorPB.java:639)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:497)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:187)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:102)
at com.sun.proxy.$Proxy15.setSafeMode(Unknown Source)
at org.apache.hadoop.hdfs.DFSClient.setSafeMode(DFSClient.java:2373)
at org.apache.hadoop.hdfs.DistributedFileSystem.setSafeMode(DistributedFileSystem.java:1007)
at org.apache.hadoop.hdfs.DistributedFileSystem.setSafeMode(DistributedFileSystem.java:991)
at org.apache.hadoop.hbase.util.FSUtils.isInSafeMode(FSUtils.java:448)
at org.apache.hadoop.hbase.util.FSUtils.waitOnSafeMode(FSUtils.java:896)
at org.apache.hadoop.hbase.master.MasterFileSystem.checkRootDir(MasterFileSystem.java:442)
at org.apache.hadoop.hbase.master.MasterFileSystem.createInitialFileSystemLayout(MasterFileSystem.java:153)
at org.apache.hadoop.hbase.master.MasterFileSystem.<init>(MasterFileSystem.java:129)
at org.apache.hadoop.hbase.master.HMaster.finishInitialization(HMaster.java:808)
at org.apache.hadoop.hbase.master.HMaster.run(HMaster.java:613)
at java.lang.Thread.run(Thread.java:745)
Caused by: java.net.ConnectException: Connection refused
at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method)
at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:717)
at org.apache.hadoop.net.SocketIOWithTimeout.connect(SocketIOWithTimeout.java:206)
at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:529)
at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:493)
at org.apache.hadoop.ipc.Client$Connection.setupConnection(Client.java:606)
at org.apache.hadoop.ipc.Client$Connection.setupIOstreams(Client.java:700)
at org.apache.hadoop.ipc.Client$Connection.access$2800(Client.java:367)
at org.apache.hadoop.ipc.Client.getConnection(Client.java:1463)
at org.apache.hadoop.ipc.Client.call(Client.java:1382)
... 22 more
2018-11-01 10:06:28,898 INFO [master:bigdata-pro01:60000] master.HMaster: Aborting
2018-11-01 10:06:28,898 DEBUG [master:bigdata-pro01:60000] master.HMaster: Stopping service threads
2018-11-01 10:06:28,898 INFO [master:bigdata-pro01:60000] ipc.RpcServer: Stopping server on 60000
2018-11-01 10:06:28,899 INFO [RpcServer.listener,port=60000] ipc.RpcServer: RpcServer.listener,port=60000: stopping
2018-11-01 10:06:28,902 INFO [RpcServer.responder] ipc.RpcServer: RpcServer.responder: stopped
2018-11-01 10:06:28,902 INFO [RpcServer.responder] ipc.RpcServer: RpcServer.responder: stopping
2018-11-01 10:06:28,902 INFO [master:bigdata-pro01:60000] master.HMaster: Stopping infoServer
2018-11-01 10:06:28,914 INFO [master:bigdata-pro01:60000] mortbay.log: Stopped [email protected]:60010
2018-11-01 10:06:28,947 INFO [master:bigdata-pro01:60000] zookeeper.ZooKeeper: Session: 0x166ccea23d00003 closed
2018-11-01 10:06:28,947 INFO [master:bigdata-pro01:60000] master.HMaster: HMaster main thread exiting
2018-11-01 10:06:28,947 INFO [main-EventThread] zookeeper.ClientCnxn: EventThread shut down
2018-11-01 10:06:28,947 ERROR [main] master.HMasterCommandLine: Master exiting
java.lang.RuntimeException: HMaster Aborted
at org.apache.hadoop.hbase.master.HMasterCommandLine.startMaster(HMasterCommandLine.java:194)
at org.apache.hadoop.hbase.master.HMasterCommandLine.run(HMasterCommandLine.java:135)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70)
at org.apache.hadoop.hbase.util.ServerCommandLine.doMain(ServerCommandLine.java:126)
at org.apache.hadoop.hbase.master.HMaster.main(HMaster.java:2822)解决办法:

三个节点都作此修改。然后停掉所有进程,按照上面的步骤重新启动。
重启dfs后发现连个节点都standby状态:
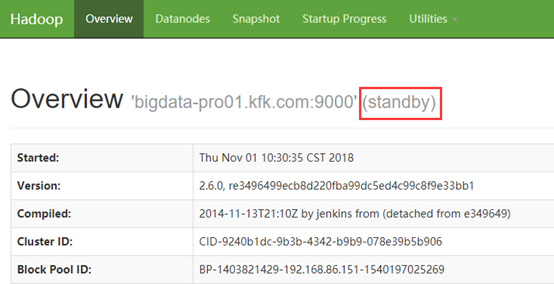

解决方案:


然后重新格式化zookeeper:
[kfk@bigdata-pro01 hadoop-2.6.0]$ bin/hdfs zkfc –formatZK再次重启所有进程:
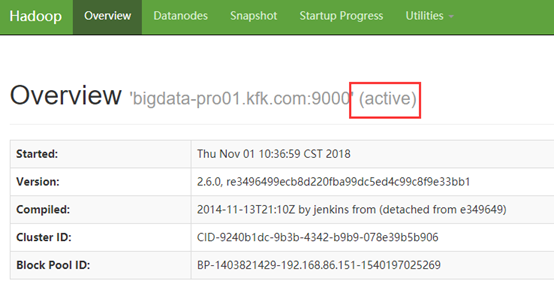
第一个节点变为active状态!
然后再启动hbase:
[kfk@bigdata-pro01 hbase-0.98.6-cdh5.3.0]$ bin/start-hbase.sh
bigdata-pro03.kfk.com: starting zookeeper, logging to /opt/modules/hbase-0.98.6-cdh5.3.0/bin/../logs/hbase-kfk-zookeeper-bigdata-pro03.kfk.com.out
bigdata-pro01.kfk.com: starting zookeeper, logging to /opt/modules/hbase-0.98.6-cdh5.3.0/bin/../logs/hbase-kfk-zookeeper-bigdata-pro01.kfk.com.out
bigdata-pro02.kfk.com: starting zookeeper, logging to /opt/modules/hbase-0.98.6-cdh5.3.0/bin/../logs/hbase-kfk-zookeeper-bigdata-pro02.kfk.com.out
starting master, logging to /opt/modules/hbase-0.98.6-cdh5.3.0/bin/../logs/hbase-kfk-master-bigdata-pro01.kfk.com.out
bigdata-pro03.kfk.com: regionserver running as process 2581. Stop it first.
bigdata-pro02.kfk.com: starting regionserver, logging to /opt/modules/hbase-0.98.6-cdh5.3.0/bin/../logs/hbase-kfk-regionserver-bigdata-pro02.kfk.com.out
bigdata-pro01.kfk.com: starting regionserver, logging to /opt/modules/hbase-0.98.6-cdh5.3.0/bin/../logs/hbase-kfk-regionserver-bigdata-pro01.kfk.com.out
[kfk@bigdata-pro01 hbase-0.98.6-cdh5.3.0]$ jps
8065 HRegionServer
7239 NameNode
8136 Jps
7528 JournalNode
7963 HMaster
1964 QuorumPeerMain
7342 DataNode
7678 DFSZKFailoverController
并且在节点2上启动HMaster:[kfk@bigdata-pro02 hbase-0.98.6-cdh5.3.0]$ bin/hbase-daemon.sh start master
starting master, logging to /opt/modules/hbase-0.98.6-cdh5.3.0/bin/../logs/hbase-kfk-master-bigdata-pro02.kfk.com.out
[kfk@bigdata-pro02 hbase-0.98.6-cdh5.3.0]$ jps
1968 QuorumPeerMain
5090 HRegionServer
5347 Jps
4614 NameNode
5304 HMaster
4889 DFSZKFailoverController
4781 JournalNode
4686 DataNode 打开网址查看状态:http://bigdata-pro01.kfk.com:60010/master-status
创建hbase业务表
4.启动Kafka服务[kfk@bigdata-pro01 kafka_2.11-0.8.2.1]$ bin/kafka-server-start.sh config/server.properties(三个节点都执行此操作) 
创建业务数据topic(在任一节点执行以下命令)
bin/kafka-topics.sh --zookeeper localhost:2181 --create --topic weblogs --replication-factor 1 --partitions 1 
(七)环境修改
因为我们用的是flume1.7版本的,这个时候我们应该配合kafka0.9系列的,而我们用的是kafka0.8的,所以我们要换掉。首先把0.9版本的kafka上传上来:

[kfk@bigdata-pro01 flume-1.7.0-bin]$ cd /opt/softwares/
[kfk@bigdata-pro01 softwares]$ ls
apache-flume-1.7.0-bin.tar.gz hbase-0.98.6-cdh5.3.0.tar.gz kafka_2.11-0.8.2.1.tgz zookeeper-3.4.5-cdh5.10.0.tar.gz
hadoop-2.6.0.tar.gz jdk-8u60-linux-x64.tar.gz kafka_2.11-0.9.0.0.tgz
[kfk@bigdata-pro01 softwares]$ tar -zxf kafka_2.11-0.9.0.0.tgz -C ../modules/
[kfk@bigdata-pro01 softwares]$ cd ../modules/
[kfk@bigdata-pro01 modules]$ ll
total 28
drwxrwxr-x 6 kfk kfk 4096 Oct 31 16:33 flume-1.7.0-bin
drwxr-xr-x 11 kfk kfk 4096 Oct 22 12:09 hadoop-2.6.0
drwxr-xr-x 23 kfk kfk 4096 Oct 23 10:04 hbase-0.98.6-cdh5.3.0
drwxr-xr-x. 8 kfk kfk 4096 Aug 5 2015 jdk1.8.0_60
drwxr-xr-x 7 kfk kfk 4096 Oct 31 16:45 kafka_2.11-0.8.2.1
drwxr-xr-x 6 kfk kfk 4096 Nov 21 2015 kafka_2.11-0.9.0.0
drwxr-xr-x 15 kfk kfk 4096 Oct 22 15:56 zookeeper-3.4.5-cdh5.10.0修改配置文件:
server.properties
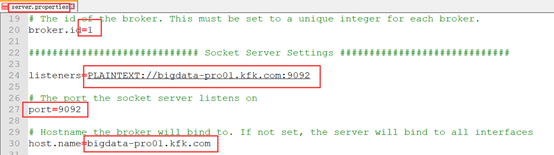

mkdir kafka-logs(在所有节点新建目录,用于存放日志文件)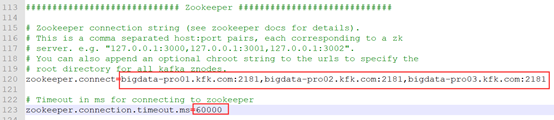
zookeeper.properties(和zookeeper的配置文件一致)

consumer.properties

producer.properties

把kafka分发都另外的两个节点去
scp -r kafka_2.11-0.9.0.0/ bigdata-pro02.kfk.com:/opt/modules/
scp -r kafka_2.11-0.9.0.0/ bigdata-pro03.kfk.com:/opt/modules/在节点2和节点3也把相应的配置文件修改一下
server.properties
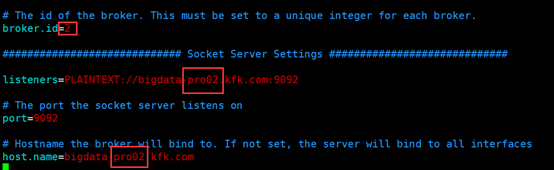
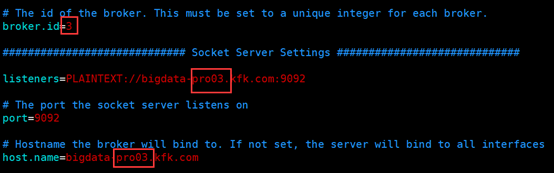
在zookeeper下把以前的topic删除掉
WATCHER::
WatchedEvent state:SyncConnected type:None path:null
[zk: localhost:2181(CONNECTED) 0] ls /
[controller_epoch, brokers, zookeeper, yarn-leader-election, hadoop-ha, rmstore, admin, consumers, config, hbase]
[zk: localhost:2181(CONNECTED) 1] ls /brokers
[ids, topics]
[zk: localhost:2181(CONNECTED) 2] ls /brokers/topics
[test, weblogs]
[zk: localhost:2181(CONNECTED) 3] rmr /brokers/topics/test
[zk: localhost:2181(CONNECTED) 4] rmr /brokers/topics/weblogs
[zk: localhost:2181(CONNECTED) 5] ls /brokers/topics
[]启动所有节点的kafka
bin/kafka-server-start.sh config/server.properties 
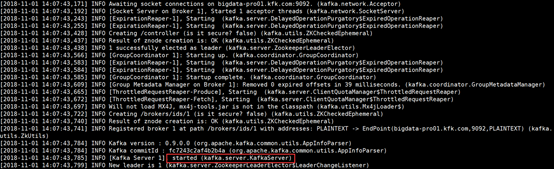
创建topic
bin/kafka-topics.sh --zookeeper bigdata-pro01.kfk.com:2181,bigdata-pro02.kfk.com:2181,bigdata-pro03.kfk.com:2181 --create --topic weblogs --replication-factor 1 --partitions 1 
修改flume配置
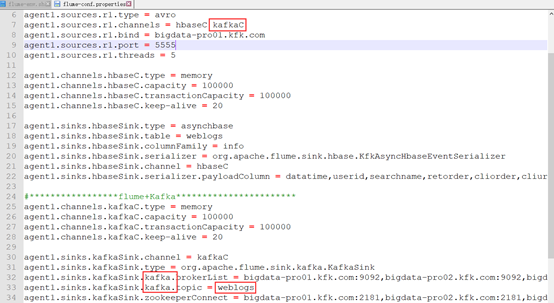
配置flume相关环境变量

export JAVA_HOME=/opt/modules/jdk1.8.0_60
export HADOOP_HOME=/opt/modules/hadoop-2.6.0
export HBASE_HOME=/opt/modules/hbase-0.98.6-cdh5.3.0启动节点1的flume。
启动节点1的flume时报错:Bootstrap Servers must be specified,解决方案见博客:Flume启动错误之:Bootstrap Servers must be specified
修改配置后重新启动:
[kfk@bigdata-pro01 flume-1.7.0-bin]$ ./flume-kfk-start.sh
flume-1 start ......
Info: Sourcing environment configuration script /opt/modules/flume-1.7.0-bin/conf/flume-env.sh
Info: Including Hadoop libraries found via (/opt/modules/hadoop-2.6.0/bin/hadoop) for HDFS access
Info: Including HBASE libraries found via (/opt/modules/hbase-0.98.6-cdh5.3.0/bin/hbase) for HBASE access
Info: Including Hive libraries found via () for Hive access然后个其他节点的flume
[kfk@bigdata-pro02 flume-1.7.0-bin]$ ./flume-kfk-start.sh
flume-2 start ......
[kfk@bigdata-pro03 flume-1.7.0-bin]$ ./flume-kfk-start.sh
flume-3 start ......报错:


作以上修改,打包上传,然后重新启动节点1的flume。
在节点2和节点3产生数据
./weblog-shell.sh 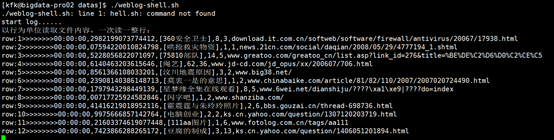

查看我们的hbase的表有么有接收到数据
bin/hbase shell执行指令:


(八)完成数据采集全流程测试(总结)
1.在bigdata-pro01.kfk.com节点上启动flume聚合脚本,将采集的数据分发到Kafka集群和hbase集群。
./flume-kfk-start.sh2.在bigdata-pro02.kfk.com节点上完成数据采集
1)使用shell脚本模拟日志产生
cd /opt/datas/
./weblog-shell.sh2)启动flume采集日志数据发送给聚合节点
./flume-kfk-start.sh3.在bigdata-pro03.kfk.com节点上完成数据采集
1)使用shell脚本模拟日志产生
cd /opt/datas/
./weblog-shell.sh2)启动flume采集日志数据发送给聚合节点
./flume-kfk-start.sh4.启动Kafka Consumer查看flume日志采集情况
bin/kafka-console-consumer.sh --zookeeper bigdata-pro01.kfk.com:2181,bigdata-pro02.kfk.com:2181,bigdata-pro03.kfk.com:2181 --topic weblogs --from-beginning5.查看hbase数据写入情况
./hbase-shell
count/scan 'weblogs'
以上就是博主为大家介绍的这一板块的主要内容,这都是博主自己的学习过程,希望能给大家带来一定的指导作用,有用的还望大家点个支持,如果对你没用也望包涵,有错误烦请指出。如有期待可关注博主以第一时间获取更新哦,谢谢!同时也欢迎转载,但必须在博文明显位置标注原文地址,解释权归博主所有!