一、准备工作
在开始研究Flink CDC原理之前(本篇先以CDC1.0版本介绍,后续会延伸介绍2.0的功能),需要做以下几个工作(本篇以Flink1.12环境开始着手)
-
打开Flink官网(查看Connector模块介绍)
-
打开Github,下载源码(目前不能放链接,读者们自行在github上搜索)
apache-flink
flink-cdc-connectors
debezium
- 开始入坑
二、设计提议
2.1、设计动机
CDC(Change data Capture,捕捉变更数据)在企业中是一种比较流行的模式,主要用于数据同步、搜索索引、缓存更新等场景;社区早期需要支持能够将变更日志直接提取及解释为Table API和SQL的功能以此来扩宽Flink的使用场景。
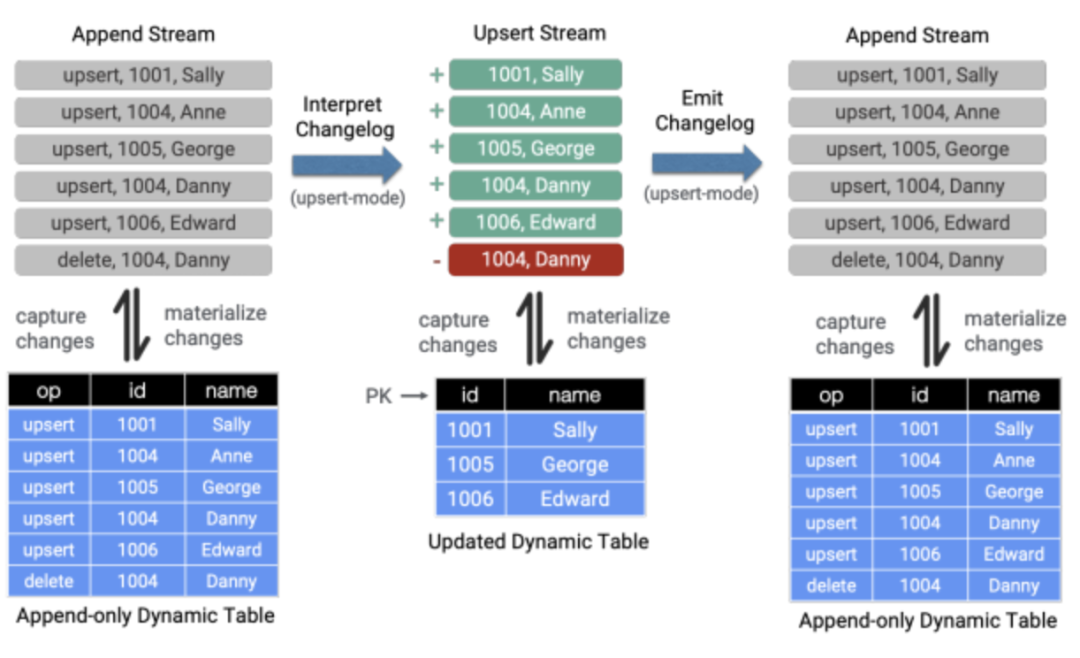
从另一方面来讲早期提出了“动态表”的概念,并定义了在流上的两种模式:append模式和update模式。Flink已经支持将流转换为动态表的append模式,但还不支持update模式,所以对changelog的解释是为了填补缺失的一块拼图,以此来获得完整的动态表概念。当然现在不仅仅支持update,还支持retract模式,后面会单独讲解。
2.2、CDC工具选型
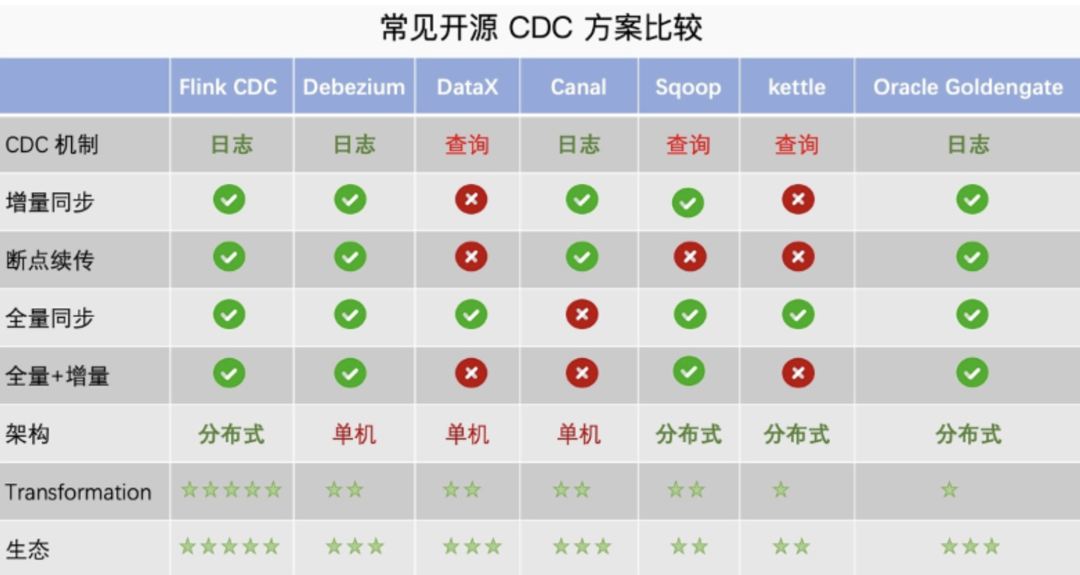
常见的CDC方案比较如下图:
一、功能完善
对于CDC工具,目前有很多选型,如Debezium、Canal等流行解决方案;目前Debezium支持Mysql,PG,SQL Server,Oracle,Cassandra和Mongo,如果Flink支持Debezium,那么也就意味着可以Flink可以连接下面截图中所有数据库的变更日志,对于完善整个生态系统是有利的。其中Debezium支持全量+增量同步,非常灵活,使得Exactly-Once成为可能。
Debezium支持的数据库类型如下图:

二、拥抱社区,便于扩展
如果选择Debezium作为Flink的嵌入式引擎,可以作为一个依赖包嵌入到代码库,而不用通过kafka connector运行,同样也可以不再需要直接与 MySQL 服务器通信,不需要处理复杂快照、GTID、锁等等优点。同时可以拥抱Debezium社区并与之合作
三、内部数据结构相似
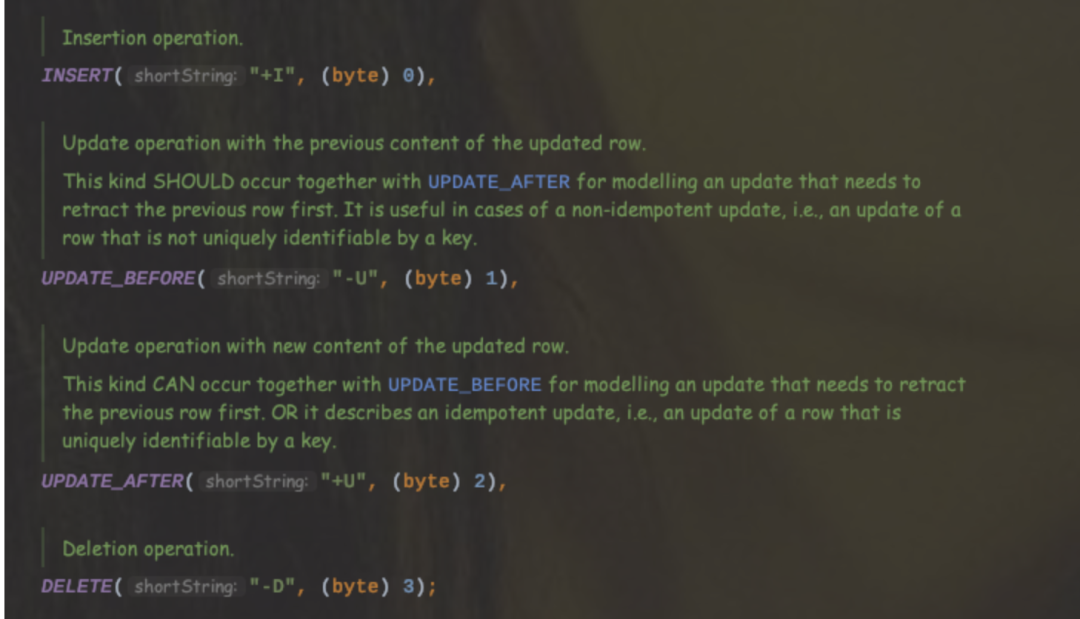
对于Flink SQL内部的数据结构RowData类型都有一个元数据RowKind,有4种类型,即插入(Insert)、更新(更新前UPDATE_BEFORE,更新后UPDATE_AFTER)、删除(DELETE),可以发现这四种数据类型和Binlog的结构基本保持一致。
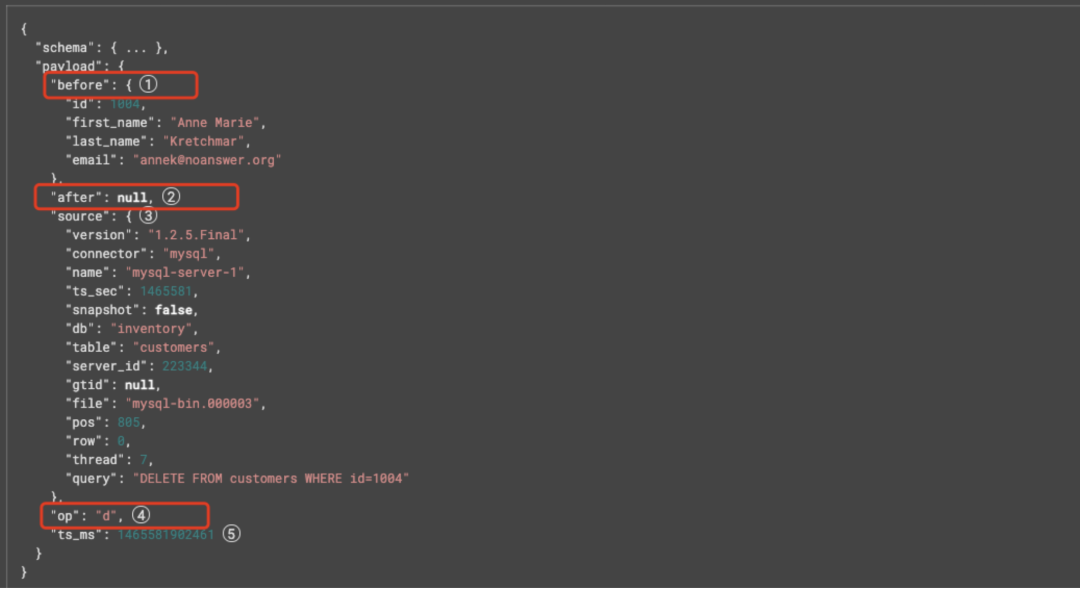
这里解释下Debezium的数据结构中各个元数据字段的含义:
· before字段:是一个可选字段,代表事件发生前行的状态,如果是一个create操作,那么该字段值为null。
· after字段:是一个可选字段,代表事件发生后行的状态,如果是一个delete操作,那么该字段值为null。
· source:是一个必选字段,包括事件的元信息,如offset,binlog文件,数据库和表。
· ts_ms:代表的是Debezium处理事件的时间戳
· OP字段:该字段也有4种取值,分别是C(create)、U(Update)、D(Delete)、Read®。对于U操作,其数据部分同时包含了Before和After。
三、Concepts
这里会涉及到很多的概念,大家先有一个认知,后面会单独拆分进行讲解。
3.1、Stream
流的概念其实很好理解,**Stream具有两个特性:有界性和变化模式。**那么接下来分别介绍这两个特性:
- 变化模式:
如上图所示:动态表模式有两种,append模式和replace模式(upsert和retract)。接下来简单介绍下两者之间的区别
对于append模式,很容易理解。如果表定义中未指定主键,那么就通过将流记录作为新的一行附加到表中,一旦将记录添加到表中,那么就永远不会更新或者删除。
对于Replace模式,如果表中定义了主键key,那么当不存在具有相同键属性的记录,就会插入到表中,否则就会进行替换。那么针对replace模式,又细分为upsert和retract两者模式:
对于Upsert模式,包含Upsert(insert 和 update)和DELETE两种消息,该模式和retract模式的主要区别在于UPDATE更改会使用单个消息进行编码,效率会更高_些。_
对于Retract模式,一个update流包含ADD和RETRACT消息,对于一个Insert更改会编码成ADD消息,对于DELETE更改会编码成RETRACT消息,对于UPDATE变更,会编码为Updated-Before作为retract消息和ADD消息。该种模式对于update事件需要拆解为两个消息,效率会相对低些。这里简单介绍下什么是回撤流,如下图所示:
Operation |
User |
Count(url) |
Mark |
I(Insert) |
Mary |
1 |
|
I(Insert) |
Bob |
1 |
|
-U(Update-Before) |
Mary |
0 |
会删除该记录 |
+U(Update-After) |
Mary |
2 |
|
I(Insert) |
Liz |
1 |
|
-U(Update-Before) |
Bob |
0 |
会删除该记录 |
+U(Update-After) |
Bob |
2 |

- 有界性
有界流:由大小有界限的事件组成,作业查询处理当前可用的数据并将在此之后结束。
无界流:由无限的事件组成,如果输入是无界流,则查询会在所有数据到来时连续处理。
3.总结:
Boundedness \ Change Mode |
Append |
Update |
Unbounded |
Append Unbounded Stream e.g. Kafka logs |
Update Unbounded Stream e.g. continuously capture changes of MySQL table |
Bounded |
Append Bounded Stream e.g. a parquet file in HDFS, a MySQL table |
Update Bounded Stream e.g. capture changes of MySQL table until a point of time |
3.2、动态表Dynamic Table
动态表是随时间变化的表,可以像传统的常规表一样进行查询。动态表可以转换为流,流可以转换为动态表(需要具有相同模式,转换方式取决于表模式是否包含主键的定义)。注意:在 Flink SQL 中创建的所有表都是动态表,对动态表的查询会生成一个新的动态表(根据输入进行更新),查询是否终止取决于输入的有界性。
DynamicTable 是一个概念对象,stream 是一个物理表示。
3.3、Changelog
Changelog(变更日志)是一个附加流(append stream),由包含变更操作列(用于插入/删除标志或将来更多)的行和实际的元数据列组成。对于Flink CDC的设计其目标就是提取变更日志的事件,并将它们转换为变更操作(如insert,update,delete事件)。
从一个append stream转换为update stream(即解释变更日志 Interpret Changelog)。
从一个update stream转换为append stream(发出变更日志 Emit Changelog)。
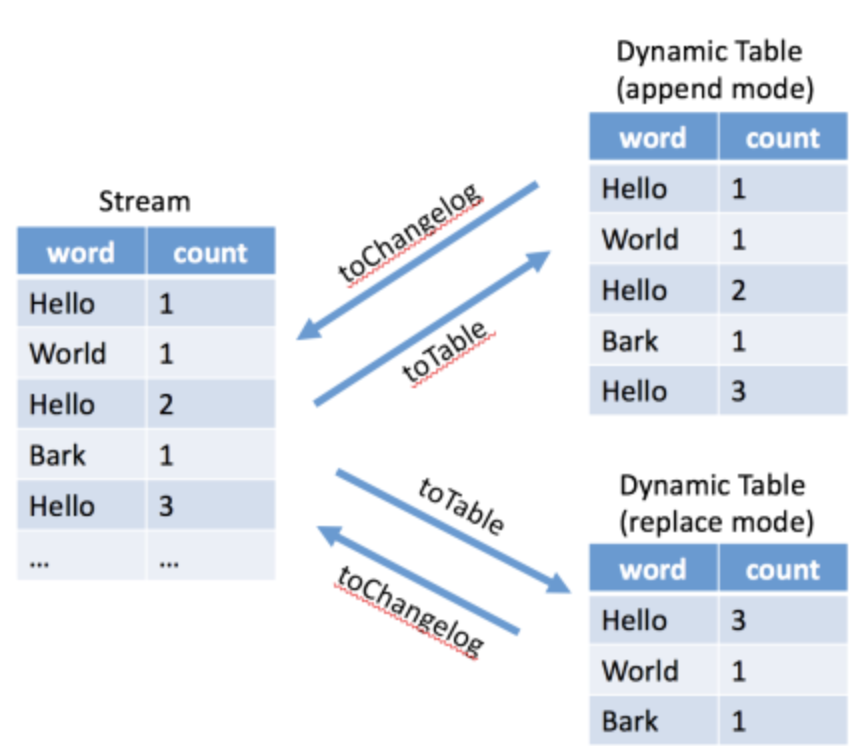
在Flink SQL中,数据从一个算子流向另外一个算子时都是以一种Changelog Stream的方式,任意时刻的Changelog Stream都可以翻译成一个表或者一个流,如下图所示:
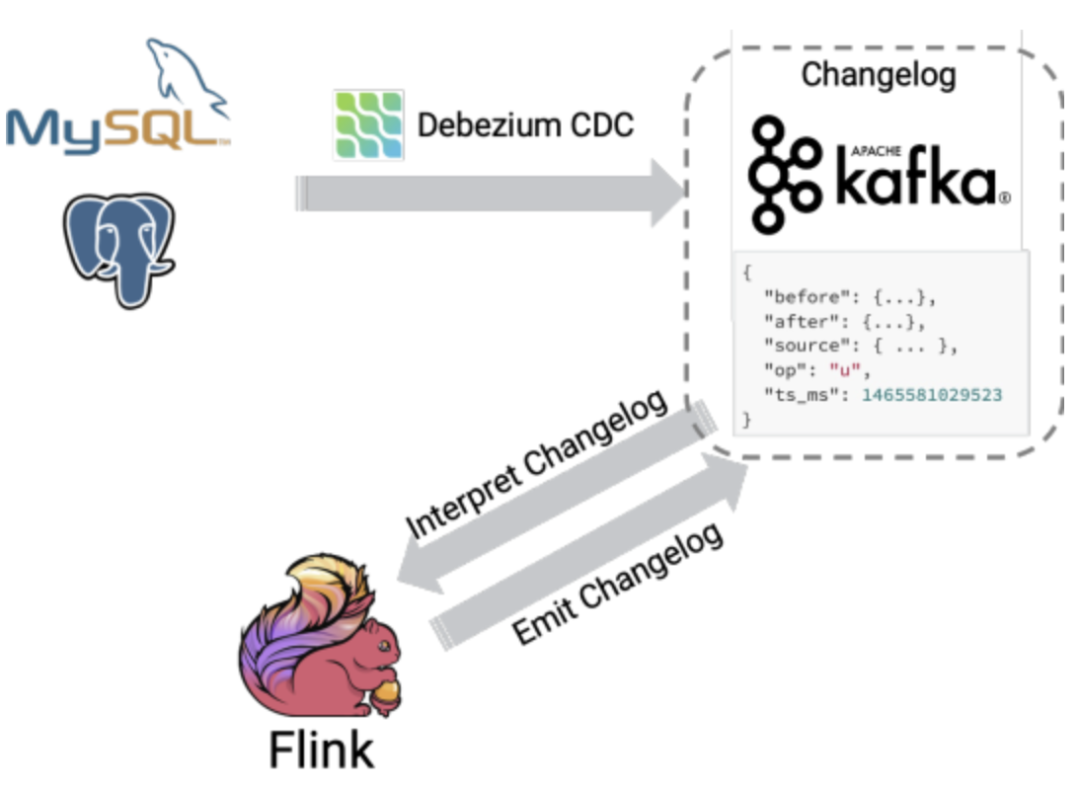
下图将完整的展示Stream类型和Table之间的转换:
不同的CDC工具对于Changelog可能有不同的编码方式,那么对于flink来说也是一个很大的挑战。这里以目前两个比较流行的解决方案:Debezium和Canal为例分别介绍一下:
- 拿Debezium来说,Debezium是一个构建在Kafka Connector之上的CDC工具,它可以将实时更改流传输到Kafka中 ,Debezium为Kafka的变更日志生成了统一的格式,以更新操作为例:
{
"before": {
"id": 1004,
"first_name": "Anne",
"last_name": "Kretchmar",
"email": "[email protected]"
}, //before作为可选字段,如果是create操作,则该字段为null
"after": {
"id": 1004,
"first_name": "Anne Marie",
"last_name": "Kretchmar",
"email": "[email protected]"
}, //after作为可选字段,如果是delete操作,则该字段为null
"source": { ... },//强制字段,标识事件元信息,如offset,binlog file,database,table 等等。
"op": "u", //强制字段,用来描述操作类型,如C(create),U(update),D(delete)
"ts_ms": 1465581029523
}
默认情况下,Debezium 会为删除操作输出两个事件:DELETE 事件和Tombstone(墓碑)事件(具有空值/有效负载),该 tombstone事件用于Kafka压缩机制。需要注意的是:Debezium并不是一个存储系统,而是代表了一个存储格式,该格式基于JSON格式,可以将反序列化结果行转换为ChangeRow或者Tuple2<Boolean,Row>。
- Canal是国内流行的CDC工具,用来捕获Mysql到其他系统的变更,支持JSON格式和protobuf格式的Kafka和RocketMQ流变化,这里以update操作为例:
{
"data": [
{//表示真实的数据,如果是更新操作,则是更新后的状态,如果是删除操作,则是删除之前的状态。
"id": "13",
"username": "13",
"password": "6BB4837EB74329105EE4568DDA7DC67ED2CA2AD9",
"name": "Canal Manager V2"
}
],
"old": [ //可选字段,如果不是update操作,那么该字段为null
{
"id": "13",
"username": "13",
"password": "6BB4837EB74329105EE4568DDA7DC67ED2CA2AD9",
"name": "Canal Manager"
}
],
"database": "canal_manager",
"es": 1568972368000,
"id": 11,
"isDdl": false,
"mysqlType": {...},
"pkNames": [
"id"
],
"sql": "",
"sqlType": {...},
"table": "canal_user",
"ts": 1568972369005,
"type": "UPDATE"
}
Flink针对这两个主流的CDC工具编码格式都进行了支持,可以通过format="canal-json"或者format=“debezium-json”。
四、源码追溯
从上面的小节中提到Flink选用Debezium作为嵌入式引擎实现CDC,目前Flink CDC已经支持的连接器如下表格:
注意:对于Mongo的连接器支持需要在Flink CDC2.0版本中使用
Database |
Version |
MySQL |
Database: 5.7, 8.0.xJDBC Driver: 8.0.16 |
PostgreSQL |
Database: 9.6, 10, 11, 12JDBC Driver: 42.2.12 |
MongoDB |
Database: 4.0, 4.2, 5.0MongoDB Driver: 4.3.1 |
Flink CDC Connectors连接器对应的Flink版本如下表格:
Flink CDC Connector Version |
Flink Version |
1.0.0 |
1.11.* |
1.1.0 |
1.11.* |
1.2.0 |
1.12.* |
1.3.0 |
1.12.* |
1.4.0 |
1.13.* |
2.0.0 |
1.13.* |
4.1、Debezium-Mysql
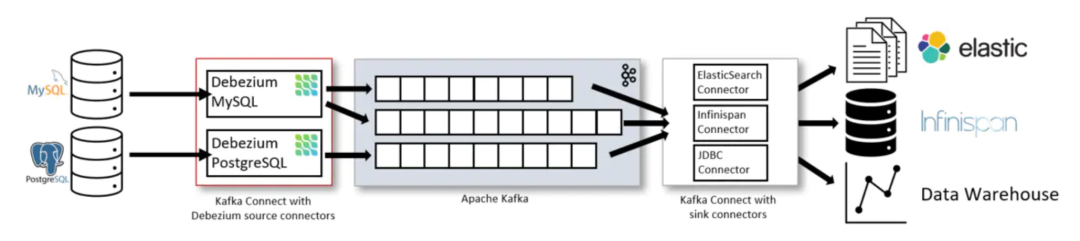
在深入了解下Flink是如何结合Debezium,以及具体的交互流程之前先来简单看下Debezium是如何实现事件变更捕获的。下图是Debezium(以Debezium1.2版本为例)在整个CDC链路中的角色:
以Mysql例,在使用Debezium前,需要准备以下几点工作:
4.1.0、准备工作
1、需要对mysql账户进行授权
GRANT SELECT, RELOAD, SHOW DATABASES, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'user' IDENTIFIED BY 'password';
2、开启Mysql binlog
-- 1、检查是否已经开启
SELECT variable_value as "BINARY LOGGING STATUS (log-bin) ::"
FROM information_schema.global_variables WHERE variable_name='log_bin';
--2、配置服务文件,开启binlog
server-id = 223344
log_bin = mysql-bin
binlog_format = ROW
binlog_row_image = FULL
expire_logs_days = 10
3、开启GTID
全局事务标识符(GTIDs)可以唯一地识别集群内服务器上发生的事务。虽然Debezium MySQL Connector不需要,但使用GTIDs可以简化复制,更容易确认主服务器和从服务器是否一致,GTIDS只在Mysql5.6+之后才能使用
-- 1、开启gtid_mode
gtid_mode=ON
--2、开启enforce_gtid_consistency
enforce_gtid_consistency=ON
--3、检测是否生效
show global variables like '%GTID%';
4.1.1、Performs Database Snapshots(全量读取)
当Mysql Connector第一次启动的时候会先对数据库执行初始化一致性快照,其主要是因为通常Mysql会被设置为在一定时间段后清除binlog,所以为了保证exactly-once,先做快照。默认快照模式为inital,可以通过snapshot.mode参数调整。接下来看具体快照的细节:
-
先获取一个全局读锁来阻塞其他客户端写入(如果Debezium检测到不允许使用全局锁的时候就会改换为表级别的锁),需要注意的是:快照本身并不能阻止其他客户执行DDL,因为这可能会干扰Connector试图读取binlog位置和表 Schema。全局读锁在读取binlog位置时被保留,然后在后面的步骤中释放。
-
开启一个可重复读的事务以此来确保后续所有的读取都是针对一致的快照进行的。
-
读取当前binlog位置。
-
读取Connecto配置所允许库表对应的Schema。
-
释放全局读锁/表级别锁,这个时候其他客户端可以写入。
-
将DDL变更语句写入对应的topic中(这里也是为了保证一致性来保存所有的DDL语句,当connector在崩溃或者被优雅停止后重新启动的时候就可以从这个topic中读取所有的DDL语句来重建特定时间点下的表结构直到崩溃前binlog的那个点以此防止schema不一致出现异常)。
-
扫描库表,并在特定表的topic上为每一行生成一个事件。
-
提交事务,在Connector偏移量中记录已完成的快照。
如果Connector在制作快照的时候发生了失败,那么在重新启动的时候会创建一个新的快照,一旦快照完成,就会从binlog相同位置开始读取,这样不会丢失任何变更事件。如果Connector停止时间过长,并且当MySQL服务器清除较早的binlog文件时,Connector的最后位置可能会丢失。当Connector重新启动时,MySQL服务器不再有起点,Connector会执行另一个初始快照。
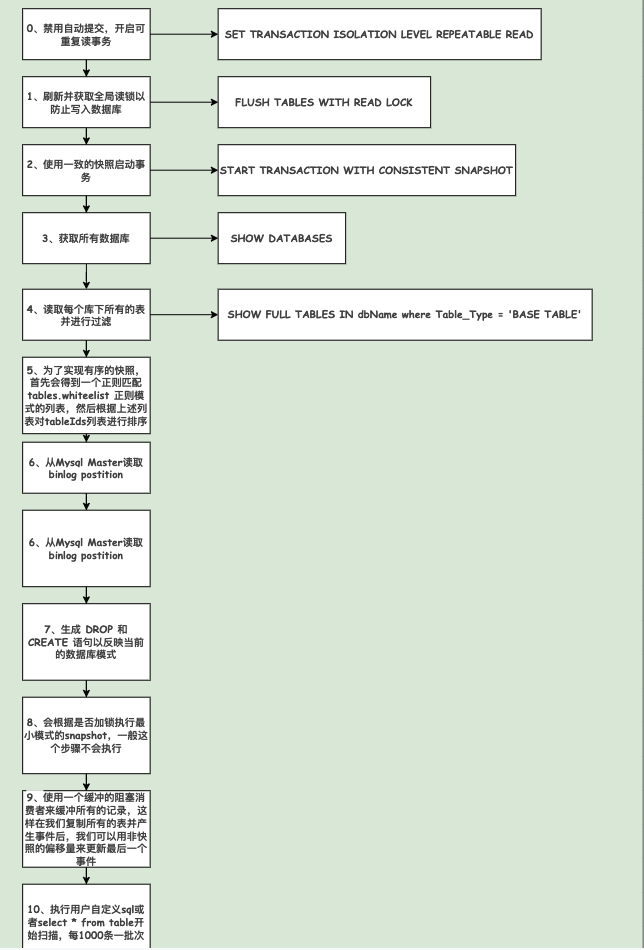
4.1.2、增量读取
-
初始化一个Binlog客户端,并将会开启一个线程名为binlog-client
-
client会注册事件监听器,这里面会调用一个handleEvent方法,主要进行offset更新、转发事件处理、心跳通知等逻辑,例如当mysqld写入切换到一个新的binlog时候或执行flush logs或当前binlog文件大小大于max_binlog_size的时候,会重新设置binlog position。
-
配置一系列反序列化器根据事件类型不同进行解析,比如事件的delete、update、insert。然后会分别调用handleDelete、handleUpdate、handleInsert等事件处理器进行处理。
-
监听到一个事件到来的时候会根据具体的事件类型分别调用具体的处理器,这里不作为重点讲解。本篇主要讲解flink如何接收到这部分数据并转换自身所支持的数据结构。
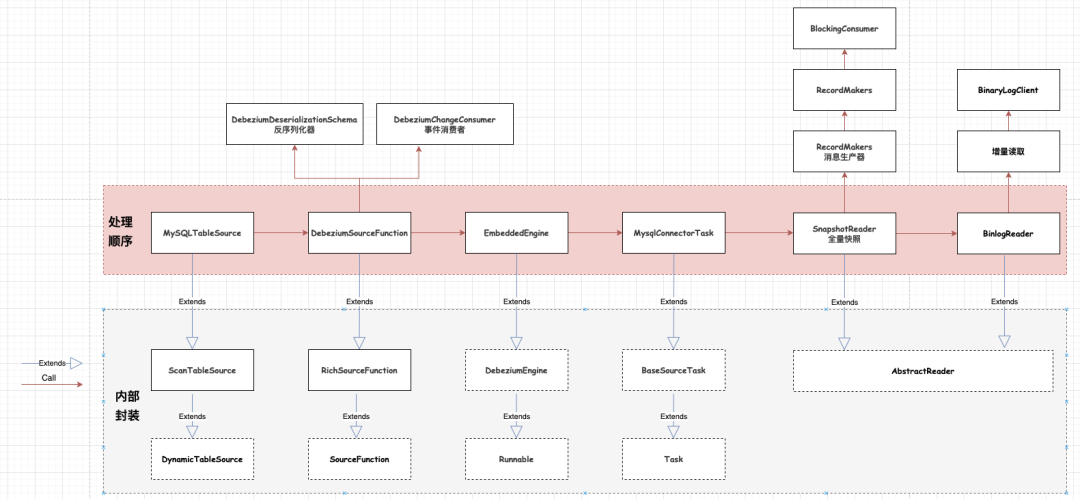
4.2、Flink-cdc-mysql
关于Flink是如何调用Debezium引擎的,会有单独的篇文来介绍。这里先给出一个调用关系图,读者后续有时间可以自行阅读
4.3、Debezium-Mysql Properties
以下表格是debezium自带的配置文件,在flink cdc中依然是可以复用的,只需要在使用之前加上“debezium.”前缀即可生效。
Property |
Default |
Description |
name |
Connector的唯一名称,如果名字相同会失败报错 |
|
connector.class |
Connector连接器的加载类,对于Mysql连接器使用io.debezium.connector.mysql.MySqlConnector |
|
tasks.max |
1 |
Connector创建的最大任务数,对于mysql来说只使用一个任务。 |
database.hostname |
Mysql数据库地址 |
|
database.port |
3306 |
Mysql数据库端口 |
database.user |
Mysql数据库认证用户名 |
|
database.password |
Mysql数据库认证密码 |
|
database.server.name |
Mysql服务名称 |
|
database.server.id |
random |
Mysql服务ID |
database.history.kafka.topic |
存放库表历史Schema的Topic |
|
database.history.kafka.bootstrap.servers |
存放库表历史Schema的kafka地址 |
|
database.whitelist |
empty string |
一个可选的逗号分隔的正则表达式列表,与要监控的数据库名称相匹配;任何不包括在白名单中的数据库名称将被排除在监控之外。默认情况下,所有数据库都将被监控。不能与database.blacklist一起使用 |
database.blacklist |
empty string |
一个可选的逗号分隔的正则表达式列表,与数据库名称相匹配,以排除在监控之外;任何不包括在黑名单中的数据库名称将被监控。不能与database.whitelist一起使用 |
table.whitelist |
empty string |
一个可选的逗号分隔的正则表达式列表,用于匹配要监控的表的全称表标识符;任何不包括在白名单中的表将被排除在监控之外。每个标识符的形式是databaseName.tableName。默认情况下,连接器将监控每个被监控数据库中的每个非系统表。不能与table.blacklist一起使用 |
table.blacklist |
empty string |
一个可选的逗号分隔的正则表达式列表,用于匹配要从监控中排除的表的全称表标识符;任何不包括在黑名单中的表都将被监控。每个标识符的形式是databaseName.tableName。不能与table.whitelist一起使用 |
column.blacklist |
empty string |
一个可选的逗号分隔的正则表达式列表,该列表与应从更改事件消息值中排除的列的全称名称相匹配。列的全称是数据库名.表名.列名,或者数据库名.模式名.表名.列名 |
column.truncate.to.length.chars |
n/a |
一个可选的逗号分隔的正则表达式列表,它与基于字符的列的完全限定名称相匹配,如果字段值长于指定的字符数,其值应在变更事件消息值中被截断。在一个配置中可以使用具有不同长度的多个属性,尽管在每个属性中长度必须是一个正整数。列的全称是数据库名.表名.列名的形式 |
column.mask.with.length.chars |
n/a |
当列长度超过指定长度,那么多余的值由*来替换 |
column.mask.hash.hashAlgorithm.with.salt.salt |
n/a |
列加盐操作 |
time.precision.mode |
adaptive_time_microseconds |
时间、日期和时间戳可以用不同种类的精度表示,包括。adaptive_time_microseconds(默认)根据数据库列的类型,使用毫秒、微秒或纳秒的精度值,准确捕获日期、数据时间和时间戳的值,但TIME类型的字段除外,它总是被捕获为微秒。adaptive(已弃用)根据数据库列的类型,使用毫秒、微秒或纳秒的精度,完全按照数据库中的时间和时间戳值来捕捉;或者connector总是使用Kafka Connector内置的时间、日期和时间戳的表示法来表示时间和时间戳值,它使用毫秒精度,而不管数据库列的精度 |
decimal.handling.mode |
precise |
指定连接器应该如何处理DECIMAL和NUMERIC列的值:precision(默认)使用java.math.BigDecimal值精确表示它们,在变化事件中以二进制形式表示;或者使用double值表示它们,这可能会导致精度的损失,但会更容易使用。 string选项将值编码为格式化的字符串,这很容易使用,但会失去关于真正类型的语义信息 |
bigint.unsigned.handling.mode |
long |
指定BIGINT UNSIGNED列在变化事件中的表示方式,包括:precision使用java.math.BigDecimal表示数值,在变化事件中使用二进制表示法和Kafka Connect的org.apache.kafka.connect.data.Decimal类型进行编码; long(默认)使用Java的long表示数值,它可能不提供精度,但在消费者中使用起来会容易得多。只有在处理大于2^63的值时,才应该使用精确设置,因为这些值不能用long来表达。 |
include.schema.changes |
true |
指定是否要将数据库schema变更事件推送到Topic中 |
include.query |
false |
指定连接器是否应包括产生变化事件的原始SQL查询。 注意:这个选项要求MySQL在配置时将binlog_rows_query_log_events选项设置为ON。查询将不会出现在从快照过程中产生的事件中。 启用该选项可能会暴露出被明确列入黑名单的表或字段,或通过在变更事件中包括原始SQL语句而被掩盖。出于这个原因,这个选项默认为 "false" |
event.processing.failure.handling.mode |
fail |
指定connector在反序列化binlog事件过程中对异常的反应。 fail表示将传播异常,停止Connector Warn将记录有问题的事件及binlog偏移量,然后跳过 skip:直接跳过有问题的事件 |
inconsistent.schema.handling.mode |
fail |
指定连接器应该如何应对与内部Schema表示中不存在的表有关的binlog事件(即内部表示与数据库不一致)。 fail将抛出一个异常(指出有问题的事件及其binlog偏移),并停止连接器。 warn将跳过有问题的事件,并把有问题事件和它的binlog偏移量记录下来。 skip将跳过有问题的事件。 |
max.queue.size |
8192 |
指定阻塞队列的最大长度,从数据库日志中读取的变更事件在写入Kafka之前会被放入该队列。这个队列可以为binlog reader提供反向压力,例如,当写到Kafka的速度较慢或Kafka不可用时。出现在队列中的事件不包括在这个连接器定期记录的偏移量中。默认为8192,并且应该总是大于max.batch.size属性中指定的最大批次大小。 |
max.batch.size |
2048 |
指定在该连接器的每次迭代中应处理的每批事件的最大长度。默认值为2048 |
poll.interval.ms |
1000 |
指定连接器在每次迭代过程中等待新的变化事件出现的毫秒数。默认为1000毫秒,或1秒 |
connect.timeout.ms |
30000 |
指定该连接器在尝试连接到MySQL数据库服务器后,在超时前应等待的最大时间(毫秒)。默认值为30秒 |
tombstones.on.delete |
true |
控制是否应在删除事件后生成墓碑事件。 当为真时,删除操作由一个删除事件和一个后续的墓碑事件表示。当false时,只有一个删除事件被发送。 发出墓碑事件(默认行为)允许Kafka在源记录被删除后完全删除所有与给定键有关的事件。 |
message.key.columns |
empty string |
一个分号的正则表达式列表,匹配完全限定的表和列,以映射一个主键。 每一项(正则表达式)必须与代表自定义键的<完全限定的表>:<列的逗号分隔列表>相匹配。 完全限定的表可以定义为databaseName.tableName。 |
binary.handling.mode |
bytes |
指定二进制(blob、binary、varbinary等)列在变化事件中的表示方式,包括:bytes表示二进制数据为字节数组(默认),base64表示二进制数据为base64编码的String,hex表示二进制数据为hex编码的(base16)String |
connect.keep.alive |
true |
指定是否应使用单独的线程来确保与MySQL服务器/集群保持连接 |
table.ignore.builtin |
true |
指定是否应该忽略内置系统表。无论表的白名单或黑名单如何,这都适用。默认情况下,系统表被排除在监控之外,当对任何系统表进行更改时,不会产生任何事件。 |
database.history.kafka.recovery.poll.interval.ms |
100 |
用于指定连接器在启动/恢复期间轮询持久数据时应等待的最大毫秒数。默认值是100ms |
database.history.kafka.recovery.attempts |
4 |
在连接器恢复之前,连接器尝试读取持久化历史数据的最大次数。没有收到数据后的最大等待时间是recovery.attempts x recovery.poll.interval.ms |
database.history.skip.unparseable.ddl |
false |
指定连接器是否应该忽略畸形或未知的数据库语句,或停止处理并让操作者修复问题。安全的默认值是false。跳过应该谨慎使用,因为在处理binlog时,它可能导致数据丢失或混乱 |
database.history.store.only.monitored.tables.ddl |
false |
指定连接器是否应该记录所有的DDL语句或(当为true时)只记录那些与Debezium监控的表有关的语句(通过过滤器配置)。安全的默认值是false。这个功能应该谨慎使用,因为当过滤器被改变时,可能需要缺失的数据。 |
database.ssl.mode |
disabled |
指定是否使用加密的连接。默认是disabled,并指定使用未加密的连接。 如果服务器支持安全连接,preferred选项会建立一个加密连接,否则会退回到未加密连接。 required选项建立一个加密连接,但如果由于任何原因不能建立加密连接,则会失败。 verify_ca选项的行为类似于required,但是它还会根据配置的证书颁发机构(CA)证书来验证服务器的TLS证书,如果它不匹配任何有效的CA证书,则会失败。 verify_identity选项的行为与verify_ca类似,但另外验证服务器证书与远程连接的主机是否匹配。 |
binlog.buffer.size |
0 |
Binlog Reader使用的缓冲区的大小。 在特定条件下,MySQL Binlog可能包含Roldback语句完成的未提交的数据。典型示例正在使用SavePoints或混合单个事务中的临时和常规表更改。 当检测到事务的开始时,Debezium尝试向前滚动Binlog位置并找到提交或回滚,以便决定事务的更改是否会流流。缓冲区的大小定义了Debezium可以在搜索事务边界的同时的交易中的最大变化次数。如果事务的大小大于缓冲区,则Debezium需要重新卷起并重新读取流式传输时不适合缓冲区的事件。0代表禁用缓冲。默认情况下禁用。 注意:此功能还在测试 |
snapshot.mode |
initial |
指定连接器在启动允许快照时的模式。默认为inital,并指定仅在没有为逻辑服务器名称记录偏移时才能运行快照。 when_needed选项指定在启动时运行快照,只要它认为它需要(当没有可用偏移时,或者以前记录的偏移量在指定服务器中不可用的Binlog位置或GTID)。 never选项指定不运行快照。 schema_only选项只获取启动以来的更改。 schema_only_recovery选项是现有连接器的恢复选项,用来恢复损坏或者丢失的数据库历史topic |
snapshot.locking.mode |
minimal |
控制连接器是否持续获取全局MySQL读取锁(防止数据库的任何更新)执行快照。有三种可能的值minimal,extended,none。 minimal仅在连接器读取数据库模式和其他元数据时保持全局读取锁定仅适用于快照的初始部分。快照中的剩余工作涉及从每个表中选择所有行,即使在不再保持全局读取锁定状态时,也可以使用可重复读取事务以一致的方式完成。虽然其他MySQL客户端正在更新数据库。 extended指在某些情况下客户端提交MySQL从可重复读取语义中排除的操作,可能需要阻止所有写入的全部持续时间。 None将阻止连接器在快照过程中获取任何表锁。此值可以与所有快照模式一起使用,但仅在快照时不发生Schema更改时,才能使用。注意:对于使用MyISAM引擎定义的表,表仍将被锁定,只要该属性设置为MyISAM获取表锁定。InnoDB引擎获取的是行级锁 |
snapshot.select.statement.overrides |
控制哪些表的行将被包含在快照中。此属性包含一个以逗号分隔的完全限定的表(DB_NAME.TABLE_NAME)的列表。单个表的选择语句在进一步的配置属性中指定,每个表由 id snapshot.select.statement.overrides.[DB_NAME].[TABLE_NAME] 识别。这些属性的值是在快照期间从特定表检索数据时要使用的 SELECT 语句。对于大型的仅有附录的表来说,一个可能的用例是设置一个特定的点来开始(恢复)快照,以防止之前的快照被打断。 注意:这个设置只对快照有影响。从binlog捕获的事件完全不受其影响。 |
|
min.row.count.to.stream.results |
1000 |
在快照操作中,连接器将查询每个包含的表,为该表的所有行产生一个读取事件。这个参数决定了MySQL连接是否会将表的所有结果拉入内存,或者是否会将结果流化(可能会慢一些,但对于非常大的表来说是可行的)。该值指定了在连接器将结果流化之前,表必须包含的最小行数,默认为1000。将此参数设置为'0',可以跳过所有的表大小检查,并在快照期间始终流式处理所有结果 |
database.initial.statements |
建立到数据库的 JDBC 连接(不是事务日志读取连接)时要执行的 SQL 语句的分号分隔列表。使用双分号 (';;') 将分号用作字符而不是分隔符。注意:连接器可以自行决定建立 JDBC 连接,因此这通常仅用于配置会话参数,而不用于执行 DML 语句 |
|
snapshot.delay.ms |
连接器在启动后,进行快照之前需要等待的时间间隔;当在集群中启动多个连接器时可以避免快照中断 |
|
snapshot.fetch.size |
指定在快照时应该从表中一次性读取的最大行数 |
|
snapshot.lock.timeout.ms |
10000 |
指定在快照时等待获取表锁的最长时间,如果在指定时间间隔内未获取到表锁的时候,则快照失败 |
enable.time.adjuster |
MySQL 允许用户将年份值插入为 2 位或 4 位。在两位数字的情况下,该值会自动映射到 1970 - 2069 范围。这通常由数据库完成。当 Debezium 进行转换时设置为 true(默认值)。 当转换完全委托给数据库时设置为 false |
|
sanitize.field.names |
true when connector configuration explicitly specifies the key.converter or value.converter parameters to use Avro, otherwise defaults to false. |
是否对字段名称进行清理以符合 Avro 命名要求 |
skipped.operations |
跳过的 op操作的逗号分隔列表。操作包括:c 表示插入,u 表示更新,d 表示删除。默认情况下,不跳过任何操作 |