在数仓的建设之路中,其中必不可少的一个依赖组件就是调度系统。目前市面上也有很多优秀产品,如以DAG为核心的工作流系统:Azkaban、Oozie、Airflow、DolphinScheduler;以Quartz为代表的定时系统包括Elastic-Job、Xxl-Job、Saturn、PowerJob等,关于调度系统的重要性,这里不作阐述。
众所周知,在数仓的建设标准中,其中包括了及时性以及稳定性两个衡量指标,同时这两项指标的好坏也依赖于调度系统的运行是否正常以及功能是否丰富。那么本篇将围绕着数仓建设的标准来介绍下依赖的调度系统必备的几项功能点:
一、重跑回溯
1.1、任务回溯
在日常工作当中,对于ETL工程师或者建模工程师等数据人员来说调整开发口径或者修复计算逻辑并不是痛苦的事情,而历史数据的修复可以说是数据人的噩梦,有可能要花费上一周甚至一个月的时间。举个例子:某运营部门想要看每天近一年窗口截止当日的成功下单的用户数,对于开发这种需求来说可能两个小时就搞定了(当然下面的SQL并没有经过任何优化的,也没有涉及到任何模型,只是举例说明)。
--统计近一年,每天截止当日成功下单的用户数
select
'统计日',
count(distinct user_id) as uv
from dw_table
where create_date>=date_sub(统计日,365)
and create_date<='统计日'
and pay_status='成功下单'
然后正常运行了一个月后,运营同事突然找上门来说要调整口径,要看截止统计日的所有用户数,而且要重新修复上个月统计的所有指标数据。这个时候你是不是要炸天,然后你是不是要按照下面的SQL手动跑一个月的数据?
--统计截止2021-09-01 成功下单的用户数
select
'统计日',
count(distinct user_id) as uv
from dw_table
where create_date>=date_sub('2021-09-01',365)
and create_date<='2021-09-01'
--统计截止2021-09-02 成功下单的用户数
select
'统计日',
count(distinct user_id) as uv
from dw_table
where create_date>=date_sub('2021-09-02',365)
and create_date<='2021-09-02'
因此针对窗口统计类的任务或者需要自身依赖的任务或者支撑特征模型训练的场景下,当遇到口径调整修复数据的时候,人肉处理就显得无力。如果在调度系统层面能够支持回溯任意时刻的数据时(前提是依赖任务的数据能够覆盖到回溯日),那么这个时候就完全可以做到解放人力。
1.2、断点重跑
在日常开发当中,对于任务的调试出错是不可避免的,举个例子:对于统计类的任务(涉及到上亿级别的大表),完整的执行完任务可能需要耗时小时级别的,那么对于该任务又需要配置一个稽核节点以此来保证唯一性或者非空性,当在调试的过程中,因为稽核配置失误导致稽核出错,那么又需要重新调整验证修复,再花费几个小时重新执行。以此往复,开发完成一个任务可能要花费几天,大大降低了工作效率。
那如果调度系统能够支持节点重跑的话,只需要重新调整稽核节点,而不需要再次花费资源执行SQL节点,那么整个效率大大提升,而且也降低了资源的浪费。
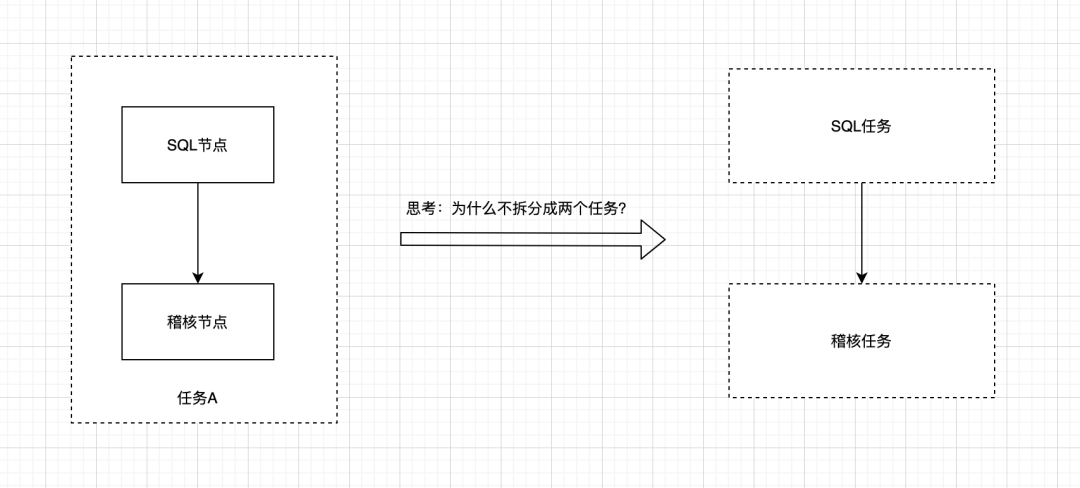
二、任务依赖
对于任务的依赖,目前有两种类型:自身依赖和上下游依赖。
2.1、自身依赖
在数仓建设的需求场景中,会出现当前任务的数据依赖于上个版本任务产出的数据。因此需要调度系统能够支持这种自身依赖的功能,对于DAG流的调度产品是能够支持的。
2.2、上下游依赖
对于上下游依赖的场景,是很容易理解的,例如在前面讲到稽核任务是依赖于SQL任务执行成功后才能够执行。
三、优先级设计
针对日常开发的数据需求,任务本身是可以进行定级的(即该任务是属于高级别、中等级别还是低级别的),优先级的设定要根据需求方对数据的时效性要求以及业务的重要性程度及面向用户重要性等多方面来抉择。
当然对于任务设定优先级的一个好处在于:从数仓分层的角度来说最底层是数据接入,在凌晨的时候会有大批量的同步任务被同时调用执行,那么这个时候也是属于资源最紧缺的。如果站在优先级的角度来看,并不是所有的任务都要同一时刻被调用,而是根据优先级的重要性依次执行,这个时候资源也会得到相对合理的分配,对于数据的及时产出也有了一定的保障。当然任务优先级的设定不能完全靠人工来维护,特别是对于上千万的任务量来说,毕竟每个人都不可能记得住整个链路的任务关系,所以需要依靠一套合理的算法基于人工设定的优先级来计算得出合理的优先级。具体如何设计合理的优先级,这里给出四种情况(参考倒推回溯法):
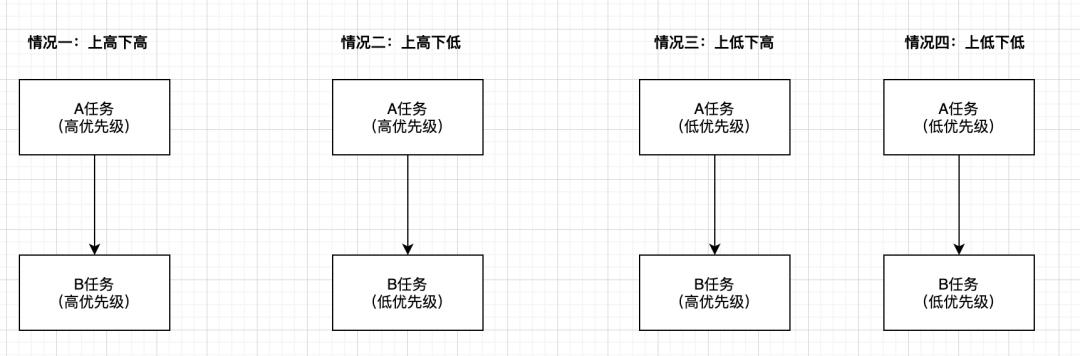
针对情况一:上高下高:当新开发一个B任务需要依赖A任务,而且B任务比较重要,那么这个时候就可以直接以人工制定的优先级为准。
针对情况二:上高下低:当新开发一个B任务需要依赖A任务,但是B任务并不是很重要,那么这个时候还是可以以人工制定的优先级为准。
针对情况三:上低下高:当新开发一个B任务需要依赖A任务,B任务很重要,但是发现A任务优先级并不是很高,那么这个时候就需要依靠合理的算法推导出A任务为高优先级并进行更改。
针对情况四:上低下低:当新开发一个B任务需要依赖A任务,B任务并不是很重要而且A任务也不重要,那么这个时候就可以直接以人工制定的优先级为准。
四、任务重试
在前面讲优先级设计的时候提到了夜间是资源最紧缺的时候,那么可能会有很多任务由于资源问题导致报错,因此需要调度系统能够支持自动重跑的功能,以此减少人为介入的情况。当然也有一种情况是由于任务本身逻辑问题导致的错误,而且任务执行非常耗时,重试会大大影响任务产出的实效,因此重试的次数需要进行合理的控制。
五、告警通知(问责制)
数据及时产出的最后一道防线就是需要人为介入,这个时候就需要引入值班制度,但为了保障值班人员的身心健康,应该尽量减少夜间观察次数。因此对于调度系统来说提供准确有效及时的告警服务是必不可少的,当然这里面又涉及到基础通信、设备、服务商等各种因素。
在保证了告警通知的基础下,还需要保证值班的质量效率,需要值班人员具有责任意识,及时处理问题才能真正的保证及时性,所以制度中需要引入事后问责形成完成的链路闭环保障真正的及时,因此还需要保障事中及时,这需要在告警和值班制度的基础上引入跨级通知的流程。
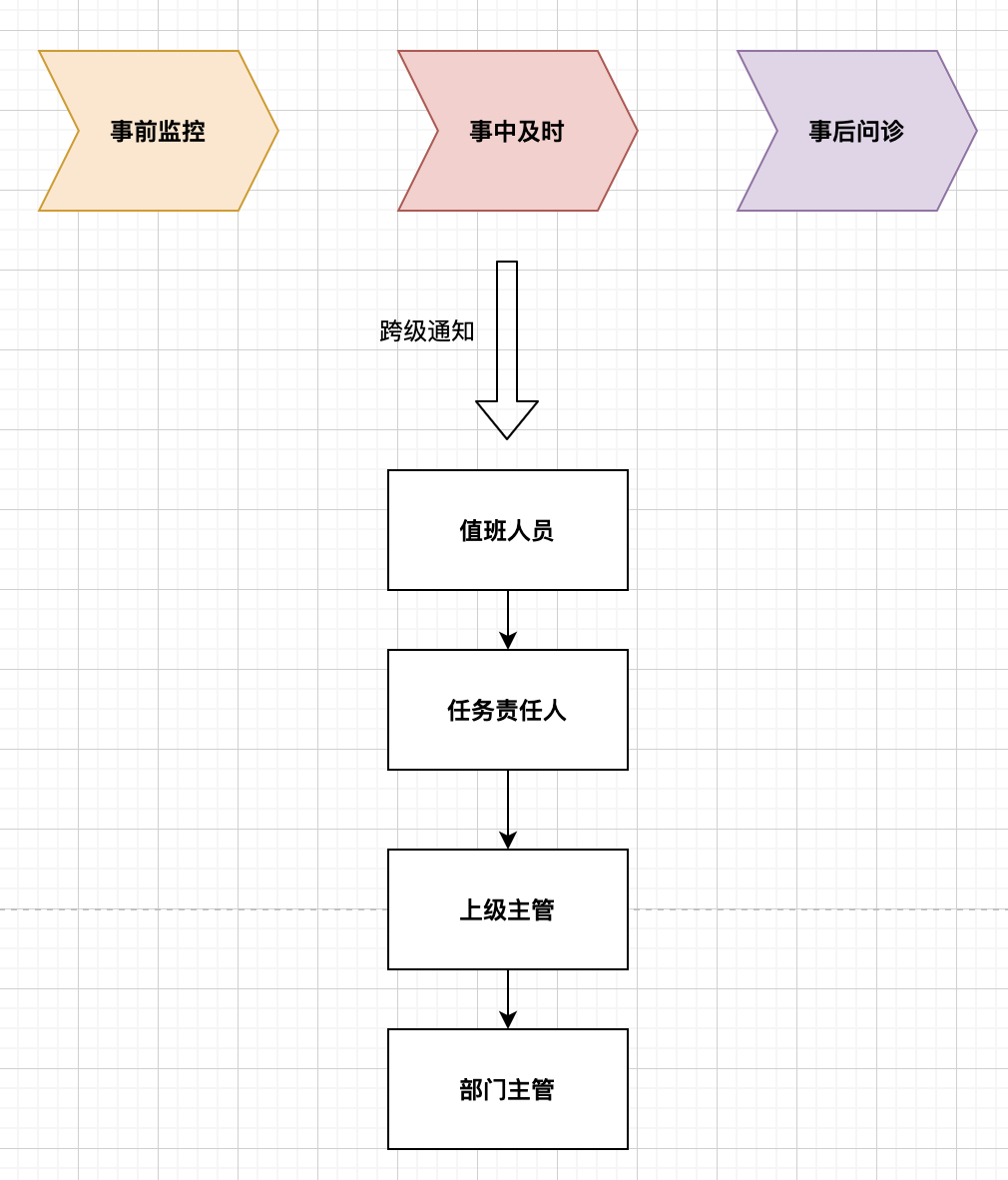
六、可视化
在数仓建设过程中,调度的任务数量是非常多的,其任务本身的调度类型以及依赖关系非常复杂,所以出错的概率也非常高,拥有可视化界面对于定位问题是非常友好的。
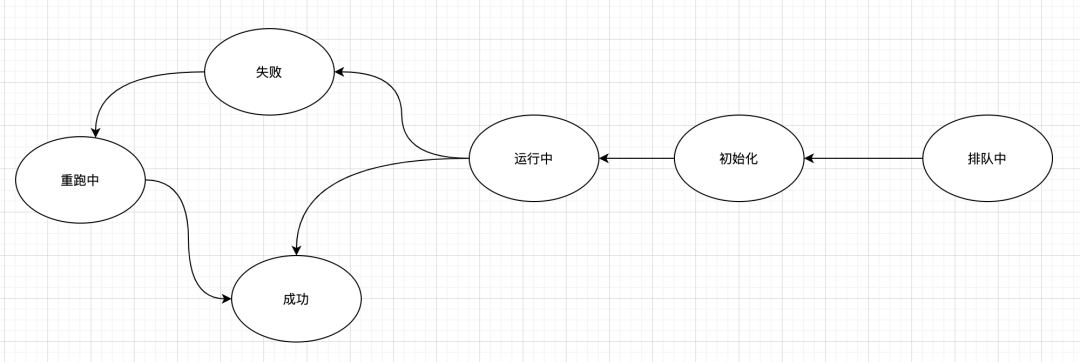
七、调度状态