Springboot实现文件断点续传-基于GridFS
需求介绍
我们后台是使用GridFS存储文件对象的,之前客户端都是Web浏览器,网络环境相对较为稳定,所以我们直接提供文件下载就行。但最近新增需求需要在移动端进行文件下载,这就有问题了。如果移动端在网络环境好的情况下下载文件肯定没问题,但移动设备的信号很容易波动、不稳定,下载链接很容易中断或出错,如果还是之前的方式就要重新下载了,这既浪费了时间又浪费了流量,所以在移动端以前的方式就不合适了。
这个时候我们就参考使用bt下载文件的模式来,实现断点续传功能,我们基于文件大小进行拆分,比如将文件分为10份,如果中间下载出现问题,只需要接着之前的部分接着下载就行,最后合并成一个文件。
接下来介绍后端java实现的方式。展示核心方法。
后端实现
service接口
定义文件传输接口,如下所示:
/**
* 通过文件id获取数据
*
* @param id 文件id
* @param range Range请求头
* @param request HttpServletRequest
* @param response HttpServletResponse
*/
void resumeDownload(String id, String range, HttpServletRequest request, HttpServletResponse response);
service实现类
下面是具体的实现方法,说明一下我是使用mongodb的一张表存储了文件信息,所以我是先去FileModel查询出文件信息,再到gridFS中获取具体文件流。如果实现方式和我不一样,那就不需要这个获取信息的步骤。
主要的思路就是让前端传range范围(前端通过其他接口已经获取了文件大小),如下图的filesize字段。
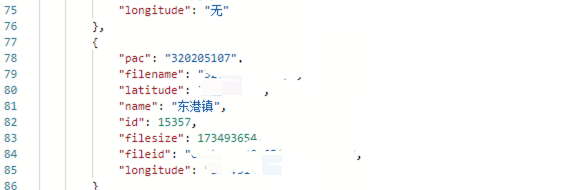
比如bytes=0-1000,文件大小10000这就是返回文件的前百分之十,前端通过range就可以记录文件传输的情况,就算中途断开了,前端也可以接着之前的部分下载,这就实现了断点续传。
基于range不仅可以断点续传,还可以实现多线程文件下载,在APP端可以基于文件大小进行拆分,每个线程下载一部分文件,最后当文件下载完成后合并成一个文件。
@Resource
private FileRepository fileRepository;
@Resource
private GridFsTemplate gridFsTemplate;
@Resource
private GridFSBucket fsBucket;
@Override
public void resumeDownload(String id, String range, HttpServletRequest request, HttpServletResponse response) {
Optional<FileModel> fileInfoByName = fileRepository.findById(id);
if (!fileInfoByName.isPresent()) {
return;
}
FileModel fileModel = fileInfoByName.get();
String objectId = fileModel.getFsId();
Query query = Query.query(Criteria.where("_id").is(objectId));
GridFSFile gridFSFile = gridFsTemplate.findOne(query);
try {
assert gridFSFile != null;
try (GridFSDownloadStream in = fsBucket.openDownloadStream(gridFSFile.getObjectId())) {
GridFsResource resource = new GridFsResource(gridFSFile, in);
InputStream inputStream = resource.getInputStream();
long contentLength = fileModel.getSize();
String contentType = fileModel.getContentType();
String formFileName = fileModel.getName();
String fileName = URLEncoder.encode(formFileName, "UTF-8").replaceAll("\\+", "%20");
long start = 0;
long end = contentLength - 1;
if (range != null && range.startsWith("bytes=")) {
String[] values = range.split("=")[1].split("-");
start = Long.parseLong(values[0]);
if (values.length > 1) {
end = Long.parseLong(values[1]);
response.setHeader(HttpHeaders.CONTENT_TYPE, "application/octet-stream");
}
} else {
response.setHeader(HttpHeaders.CONTENT_TYPE, contentType);
}
if (start >= contentLength || end >= contentLength) {
response.setStatus(HttpServletResponse.SC_REQUESTED_RANGE_NOT_SATISFIABLE);
return;
}
long rangeLength = end - start + 1;
response.addHeader(HttpHeaders.CONTENT_DISPOSITION, "fileName=\"" + fileName);
response.setHeader(HttpHeaders.CONTENT_LENGTH, String.valueOf(rangeLength));
response.setHeader(HttpHeaders.CONTENT_RANGE, "bytes " + start + "-" + end + "/" + contentLength);
response.setHeader(HttpHeaders.ACCEPT_RANGES, "bytes");
// 该语句的作用是设置HTTP响应的状态码为206,表示服务器已经成功处理了部分GET请求,客户端可以通过Range头信息指定需要获取的资源范围,服务器返回指定范围内的资源。这通常用于支持断点续传等功能。 设置后浏览器无法通过url直接请求下载
// response.setStatus(HttpServletResponse.SC_PARTIAL_CONTENT);
// 设置内容长度是为了让客户端能够正确接收到完整的响应数据,避免数据不完整或丢失的情况发生。如果不设置内容长度,客户端可能会在接收到部分数据后就关闭连接,导致服务器端的数据无法完整地传递给客户端。
response.setContentLengthLong(rangeLength);
IOUtils.copyLarge(inputStream, response.getOutputStream(), start, end);
response.flushBuffer();
}
} catch (IOException e) {
logger.error("Error while streaming file " + id, e);
}
}
controller层
这里就比较简单了,将service接口注入,并调用刚刚的方法就行
@Resource
FileService fileService;
@ApiOperation(value = "断点续传,通过文件id获取文件")
@GetMapping("/resumeDownload/{id}")
public void resumeDownload(@PathVariable String id,
@RequestHeader(value = "Range", required = false) String range,
HttpServletRequest request,
HttpServletResponse response) {
fileService.resumeDownload(id, range, request, response);
}
问题记录
在实现过程中还是遇到了些问题
Web容器问题
原本项目中使用的是undertow而不是tomcat,但执行上面的方法文件能下载但会报错。报错信息如下所示:
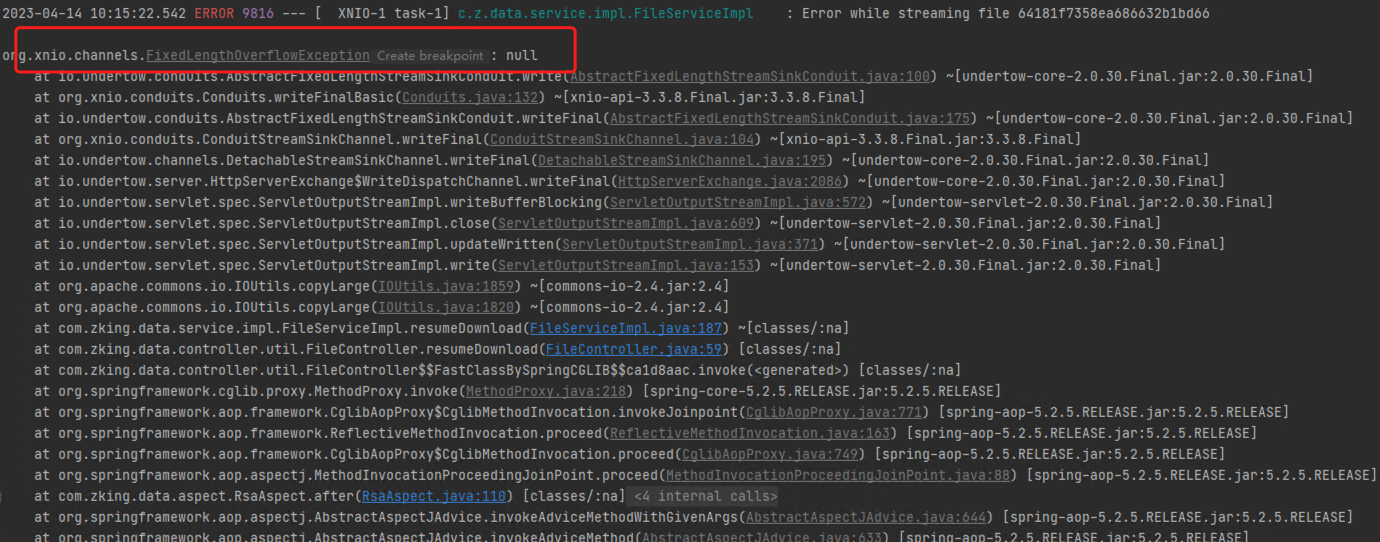
这就很奇怪了,文件代码都正常执行了,但还是会报错。在网上搜也没有找到具体的原因。如有大佬知到原因的请告知在下。
解决方法:我将undertow换回了tomcat就正常不报错了。对比两者不同如下:
Tomcat和Undertow都是Java Web服务器,但它们的性能特征略有不同。
Tomcat是一个成熟的Web服务器,经过多年的发展和改进,已经成为Java Web服务器的事实标准。它支持各种Web协议和技术,如HTTP、WebSocket、Servlet、JSP、EL等。Tomcat的性能非常好,可以处理大量的并发请求,但在处理静态文件和小型请求时,它的性能可能会稍有下降。
Undertow是一个轻量级的Web服务器,它专注于处理高性能的Web请求。它的设计目标是快速、轻量级和灵活,因此它可以在小型设备和云环境中运行。Undertow采用非阻塞I/O和事件驱动架构,可以很好地处理高并发请求,特别是在处理小型请求和静态文件时,它的性能比Tomcat更好。
总的来说,如果您需要一个成熟的Web服务器,可以处理各种Web协议和技术,那么Tomcat是一个不错的选择。如果您需要一个快速、轻量级和灵活的Web服务器,可以处理高并发请求,特别是小型请求和静态文件,那么Undertow可能更适合您的需求。