当你处理几百几千几万的数据统计时,可能直接用一个列表存储数据然后算算统计,查找什么的就完事了。
但是当你处理的数据表有上百万上千万条记录,用传统的excel工作表已经很难查看了,因为xls文件的最大数目是65536,csv(据我所了解),里一个csv文件的最大显示数目是1024*1024=1048576,也就是一百多万。因此你的数据表必须由其它显示工具查阅—数据库。
一个千万级数据表导入数据库前后需要注意什么?为什么需要注意,浅谈一下。
数据库存储
数据库存储的方法能友好的保存你的数据,方便查阅统计,但是需要注意以下几点问题:
1. 建表时的数据类型选取
我们知道建表的时候需要保证:数据库的表和原数据的表没有内容上的差异 。因此建表的时候要选取合适的数据类型,和类型的长度。数据类型有int char text float …
误区:使用原数据表的数据类型一定能得到相同的数据
换一个问法:
使用pandas的默认dtype读取csv文件的时候得到的数据和原数据会完全一样吗?
答案是:不一定一样!
案例引入,导入一个原数据表某个字段为float类型的,在pandas以dtype = object也就是默认和原数据表的数据类型完全一样的时候。得到的数据库是这样的:

然而,实际情况下的表应该是这样的:
我们可以一眼就看出第一个表的数据与实际的数据表已经发生了一小点的改变。这是一个存在的精度损失问题在工程的数值上其实可是忽略不计,但在计算上显然很麻烦,且以改变原有的数据模样。
解决办法,以numpy.str类型读取
因此在导入表时,需要根据实际的情况来确定数据类型,而不是千篇一律的选取默认的数据类型。使用pandas读取时,可以参考这样…
| 1 |
csvPath = r"name.csv" |
储的数据量很大,阔且你也不知道你的数据类型有多大的时候,最好选最大的保存。能用varchar 255 ,如果报错了,没关系只是某条记录数据突然太长了,换大一点的数据类型,如text…你可能会想,为啥不一开始用text呢…
2. 建表时的编码与预处理存储
不管是数据表的大小也要注意这个问题,但是大的数据表耽误的时间更多!!!
- 选数据库的编码 直接选utf8mb4吧,别问了。。。减少某些特定字符的出错抛出的异常
- 另外,特别注意一个点是当你的字符串文本中含有引号,和#的时候你会发现你导出文本的时候会出错,为什么呢,因为python代码里的# 是注释,不管你三七二十一,遇到成对的引号出现后有一个# ,视为注释,请看:
假设一个文本为:[今天话题“#说说你身边的逗逼”,大家有什么想说的呢。]
导入数据库后取出文本处理,请看:
| 1 |
a = "今天话题"#说说你身边的逗逼”,大家有什么想说的呢。" |
此时的文本已经不是原来的文本了,变成了你的文本加注释了…
那么怎么解决呢?解决没有唯一的方法,但是有简单的方法。
第一,我建议在存储数据之前就把数据预处理一下,根据实际情况把数据中的 引号,#去掉,或者替换。
第二,综合考虑这种错误出现的次数和数据量的大小情况下,可以考虑异常处理,用re去匹配相应的内容…
接上,这里多说一点
或许你可以启动异常处理在遇到这种情况后用re去匹配你需要的一些文本内容,显得你的代码质量很高…但是这本来就是一个存储设计的弊端没有避免产生的。所以说好的数据结构,数据的存储,可以避免你后来那多余和繁琐的算法,在整体设计上,一定一定要考虑清楚,这里可是几百万几千万的数据表!
3. 建表时添加索引和自增问题
添加索引 能定位某条数据记录的位置,对实际很有帮助,添加了会方便解决很多问题,起码一下知道出错是在哪里。
4. navicat导入与程序导入的比较
navicat,简直是数据库管理的神器,新建,导入,查看,统计,建表,修改,转移数据表等等操作,对记不好命令的你简直是好得不得了。
如果你是千万级的大数据表存在云数据库,那么导入的时候要主要什么呢?
- 当你的导入数据表中没有字段解释,需要自己设计字段表,在你设计字段之后,导入的情况下:
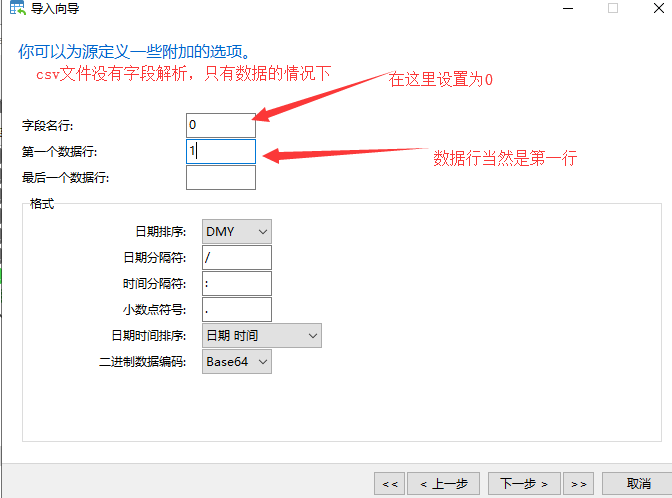
接下来就不用多说了,看着就会做了 - 当你的数据库是云数据库,数据表又很大的时候,那么导入一个数据表的时间通常就需要好几个小时,这时候需要保证你们家的网络稳定,和不受你的电脑自动睡眠等等因素干扰
** 以下操作请勿模仿:我最近刚尝试了一个三千五百多万的数据表,导入大概需要4个小时左右,我是直接本地的csv文件直接存在云数据库上。由于导入之后不管,以为网络稳定等等,数据表在导入中途也就过了两三个小时后,出现了部分导入错误,大概就是网络不行什么的,连接的错误,忘记截图了…因此我又浪费了几个小时!!! - 接上,导入navicat导入错误后,我去尝试了使用程序导入。我的设计思路是第一,先用pandas读取文件,然后加载到内存,生成sql批量导入命令,然后导入:
代码为:
先警告,小的数据表可以参考以下代码,大数据表怕你的cpu顶不住!!!请勿模仿
| 1 |
#coding:utf8 |
然后经过等待了一个多小时后:

最后,cpu 顶不住了,说不干了。
- 接上,上面用python pandas读取后然后启用批量导入的方法,cpu受不了,那么有好点的方法吗?可以,我们可以一次1000,或者10000的批量导入,但是使用pandas给我的感觉是太慢了!!!我不得不想一个更加合理的方案。
- 最终解决方案:
1.用navicat,先导入本地数据库
2.在本地建立与云数据库的连接
3.本地数据库数据传输到云数据库
第一,在本地导入数据库速度,和导入云数据库的用时差不多。但是导入本地不需要网络,从csv–>table在本地完成!
第二,从本地数据库到云数据库传输是table–>table的传输,navicat上传输非常快,不用半个小时就传输完成一个三千五百多万的数据表到云数据库了。
总结
数据表小的时候可以随时修改数据表,来适合应用程序的调用;数据表大了,去更改数据表会繁琐且容易出错,用代码去调用也需要复杂的计算。
设计存储表之前应综合考虑表的编码问题,字段存储类型,和合适的存储方法等等问题。