CBAM卷积注意力模块用法及代码实现
CBAM
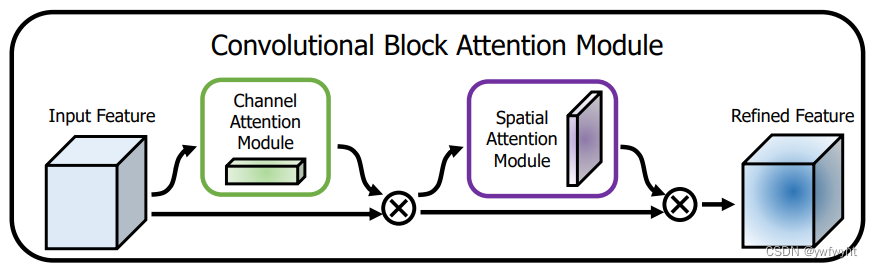
CBAM( Convolutional Block Attention Module )是一种轻量级注意力模块的提出于2018年。CBAM包含CAM(Channel Attention Module)和SAM(Spartial Attention Module)两个子模块,分别在通道上和空间上添加注意力机制。这样不仅可以节约参数和计算力,而且保证了其能够做为即插即用的模块集成到现有的网络架构中去。可以无缝的集成到CNNs中,并且可以与基本CNNs一起端到端的训练。
通道注意力让网络关注图像“是什么”,而空间注意力则让网络关注图像中物体“在哪“。
Channel Attention模块(CAM)
通道注意力模块:通道维度不变,压缩空间维度。关注输入图片中有意义的信息(不同channel中有不同的信息)
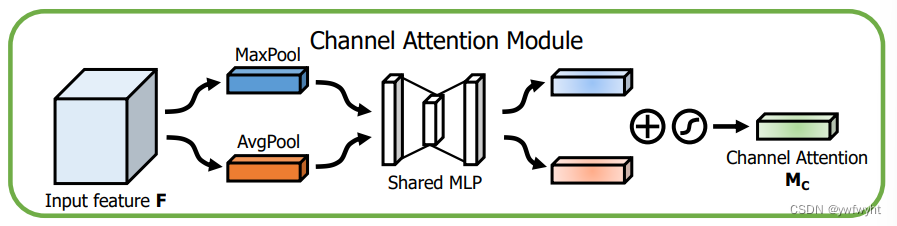
在通道注意力模块中,通过将输入的特征图分别经过最大池化以及平均池化,将特征图从C × H × W变为C × 1 × 1的大小,然后经过两层共享全连接层(shared MLP)中,它先将通道数压缩为原来的1/r(Reduction,减少率)倍,再扩张到原通道数,再将这两个输出进行elementwise逐元素相加操作,经过sigmoid激活,最终即可获得通道注意力模块的特征图。再将这个输出结果乘原图,变回C × H × W的大小。
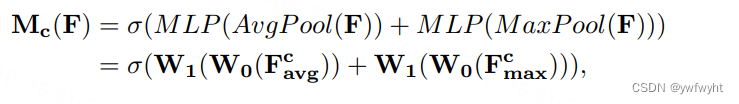
通道注意力机制(Channel Attention Module)是将特征图在通道维度不变,压缩空间维度,得到一个一维矢量后再进行操作。通道注意力关注的是这张图上哪些内容是有重要作用的。平均值池化对特征图上的每一个像素点都有反馈;而最大值池化在进行梯度反向传播计算时,只有特征图中响应最大的地方有梯度的反馈。
Spatial Attention模块(SAM)
空间注意力模块:空间维度不变,压缩通道维度。该模块关注的是目标的位置信息。
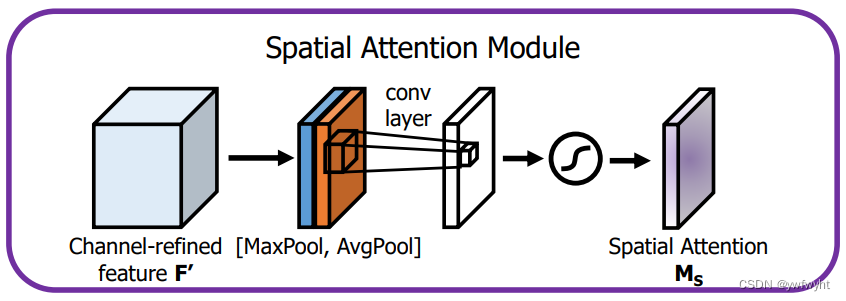
在空间注意力模块中,是将通道注意力模块输出的特征图作为输入对通道进行压缩。依次做一个基于channel维度的最大池化和平均池化得到两个1 × H × W特征图,最大池化的操作就是在通道上提取最大值,提取的次数是H × W;平均池化的操作就是在通道上提取平均值,提取的次数也是是H × W;从而可以获得一个2通道的特征图。然后将两层进行torch.cat操作。然后进行7 × 7卷积,降为1个channel,再经sigmoid获得空间注意力模块输出的特征图。最后将输出结果乘原图变回C × H × W大小。
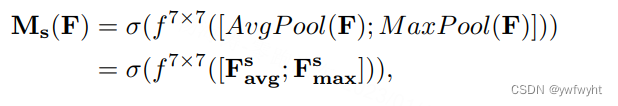
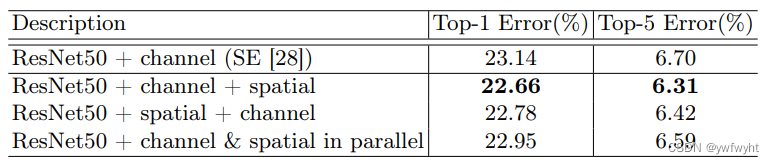
实验表明,我们可以看出CBAM模型中,先通过channel,再通过spatial,会获得更好的准确率和更低的错误率。
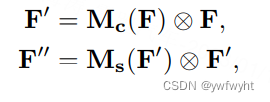
论文:https://arxiv.org/abs/1807.06521
代码实现
https://github.com/Jongchan/attention-module
代码1如下:
import torch
import torch.nn as nn
class CBAM(nn.Module):
def __init__(self, channel, reduction=16, spatial_kernel=7):
super(CBAM, self).__init__()
# channel attention 压缩H,W为1
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.avg_pool = nn.AdaptiveAvgPool2d(1)
# shared MLP
self.mlp = nn.Sequential(
# Conv2d比Linear方便操作
# nn.Linear(channel, channel // reduction, bias=False)
nn.Conv2d(channel, channel // reduction, 1, bias=False),
# inplace=True直接替换,节省内存
nn.ReLU(inplace=True),
# nn.Linear(channel // reduction, channel,bias=False)
nn.Conv2d(channel // reduction, channel, 1, bias=False)
)
# spatial attention
self.conv = nn.Conv2d(2, 1, kernel_size=spatial_kernel,
padding=spatial_kernel // 2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
max_out = self.mlp(self.max_pool(x))
avg_out = self.mlp(self.avg_pool(x))
channel_out = self.sigmoid(max_out + avg_out)
x = channel_out * x
max_out, _ = torch.max(x, dim=1, keepdim=True)
# print('max_out:',max_out.shape)
avg_out = torch.mean(x, dim=1, keepdim=True)
# print('avg_out:',avg_out.shape)
a=torch.cat([max_out, avg_out], dim=1)
# print('a:',a.shape)
spatial_out = self.sigmoid(self.conv(torch.cat([max_out, avg_out], dim=1)))
# print('spatial:',spatial_out.shape)
x = spatial_out * x
# print('x:',x.shape)
return x
代码2如下:
class CBAM(nn.Module):
'''CBAM包含CAM通道注意力模块(Channel Attention Module)和SAM空间注意力模块(Spartial Attention Module)两个子模块,
分别进行通道和空间上的Attention。这样不只能够节约参数和计算力,并且保证了其能够做为即插即用的模块集成到现有的网络架构中去。
'''
def __init__(self, in_channels, out_channels, r = 0.5):
super(CBAM, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=1, padding=1)
self.shared_mlp_cbam_1 = nn.Linear(out_channels, int(out_channels*r))
self.shared_mlp_cbam_2 = nn.Linear(int(out_channels*r), out_channels)
self.conv_cbam = nn.Conv2d(2, 1, kernel_size=7, stride=1, padding = 3)
def forward(self, x):
B, C, H, W = x.shape
x = self.conv1(x)
Fc_avg = x.mean(dim = -1).mean(dim = -1)
Fc_max = x.max(dim = -1)[0].max(dim = -1)[0]
Fc = torch.sigmoid(self.shared_mlp_cbam_2(torch.relu(self.shared_mlp_cbam_1(Fc_avg))) +
self.shared_mlp_cbam_2(torch.relu(self.shared_mlp_cbam_1(Fc_max))))
Fc = Fc.unsqueeze(-1).unsqueeze(-1).repeat((1,1,H,W))
Fc = torch.mul(x, Fc) #
Fs_avg = Fc.mean(dim = 1, keepdim=True)
Fs_max = Fc.max(dim = 1, keepdim = True)[0]
Fs = torch.sigmoid(self.conv_cbam(torch.cat((Fs_avg, Fs_max), dim = 1)))
Fs = Fs.repeat((1, C, 1, 1))
Fs = torch.mul(Fc, Fs)
return (x + Fs)
在网络中,即插即用
可参考链接
class ResnetFPN4_CBAM(nn.Module):
def __init__(self,
num_channels,
cbam_block=ResidualBlockCBAM,
cfg=None):
super(ResnetFPN4_CBAM, self).__init__()
self.cfg = cfg
# Block 1
block = []
block.append(nn.Conv2d(num_channels, num_channels, kernel_size = 3, stride = 1, padding = 1))
block.append(nn.BatchNorm2d(num_channels))
block.append(cbam_block(num_channels, num_channels))
self.block1 = nn.Sequential(*block)
# Block 2
block = []
block.append(nn.Conv2d(num_channels, num_channels, kernel_size = 3, stride = 2, padding = 1))
block.append(nn.BatchNorm2d(num_channels))
block.append(cbam_block(num_channels, num_channels))
block.append(cbam_block(num_channels, num_channels))
self.block2 = nn.Sequential(*block)
# Block 3
block = []
block.append(nn.Conv2d(num_channels, 2*num_channels, kernel_size = 3, stride = 2, padding = 1))
block.append(nn.BatchNorm2d(2*num_channels))
block.append(cbam_block(2*num_channels, 2*num_channels))
block.append(cbam_block(2*num_channels, 2*num_channels))
self.block3 = nn.Sequential(*block)
# Block 4
block = []
block.append(nn.Conv2d(2*num_channels, 4*num_channels, kernel_size = 3, stride = 2, padding = 1))
block.append(nn.BatchNorm2d(4*num_channels))
block.append(cbam_block(4*num_channels, 4*num_channels))
block.append(cbam_block(4*num_channels, 4*num_channels))
self.block4 = nn.Sequential(*block)
# FPN
self.up1 = nn.ConvTranspose2d(num_channels, 2*num_channels, kernel_size = 3, stride = 1, padding = 1)
self.up2 = nn.ConvTranspose2d(num_channels, 2*num_channels, kernel_size = 3, stride = 2, padding = 1, output_padding = (1,1))
self.up3 = nn.ConvTranspose2d(2*num_channels, 2*num_channels, kernel_size = 3, stride = 4, padding = 1, output_padding = (3,3))
self.up4 = nn.ConvTranspose2d(4*num_channels, 4*num_channels, kernel_size = 5, stride = 8, padding = 1, output_padding = (5,5))
def forward(self, x):
### Backbone ###
x = self.block1(x)
up_1 = self.up1(x)
x = self.block2(x)
up_2 = self.up2(x)
x = self.block3(x)
up_3 = self.up3(x)
x = self.block4(x)
up_4 = self.up4(x)
### Neck ###
out = torch.cat((up_1, up_2, up_3, up_4),1)
return out