从3月份到现在2个月过去了,整个数据平台从0到1,算是有了一个基本的样子,跌跌撞撞的勉强支撑起运营的一些基本业务,当然这仅仅是开始,下一步还要从零打造自己的UBS系统,想想都兴奋呢!接下来总结下自己这段时间的得失,以及下一阶段的演化目标。
关于产品架构的原则可以查看这里,我分了两篇来写:
https://www.cnblogs.com/buoge/p/9093096.html
目前的架构方式是这样的:
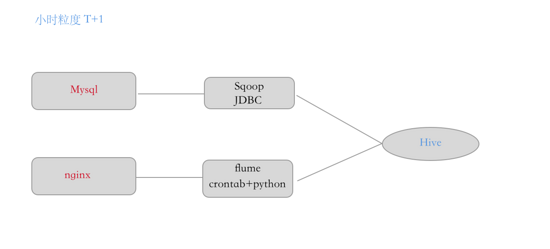
从使用Sqoop 定时从MySQL中同步数据,数据量大只能小水管的去fetch每次5-10W条记录,避免数据库压力过大
Flume tailagent 每汇总一小时然后传递logcenter,通过Python过滤后批量的Load到hive中
每日的报表在Hive的基础上会跑一些 MR 的Job, 作为每日的固化查询。
目前的缺点和不足:
问题: 日志读取,Hive入库和完成后删除log日志原始文件没有做完整的事务控制,load失败或是任务失败,原始日志已经删除了,尴尬:sweat:,目前解决方式是保留15天的原始日志
解决方案 :后续引入Kafka的日志回放功能,它有机制保证写入一次后在返回
问题 :各种crontab 飞起没有统一的调度平台,crontab 之间有依赖关系,但是crontab并没有做前后的依赖检查和重试
原因 :数据就我一个人,平台架构和业务要同时搞,老板在后面催没有这么多时间容许我慢慢的搞的这么精细
解决方案 :引入azkaban任务调度平台,统一管理
问题: Hue还没安装,神器不解释了,把各个集群的指标汇总在一起,HDFS,Yarn, MapReduce都能在一个页面直观的看到,而且还有个方便的功能就是Hive的web客户端,不用每次都去终端敲ssh命令,公司网垃圾ssh老是断浪费时间
问题: HDFS数据不能修改,只能删除重建,这里其实更适合日志类的信息,像订单分析和会员分析,需要做增量更新的记录则不合适,就几万条记录需要更新,但是把上亿级别的表删除在重建绝对是有问题的
问题: HDFS 同步有24小时的时间差,这期间线上的订单和会员信息已经发生了百万级别甚至更多的变化,而hadoop集群却没法及时的同步,从Hive出去的报表也不会包含这个空档期间的数据,准确性和实时性有待提高