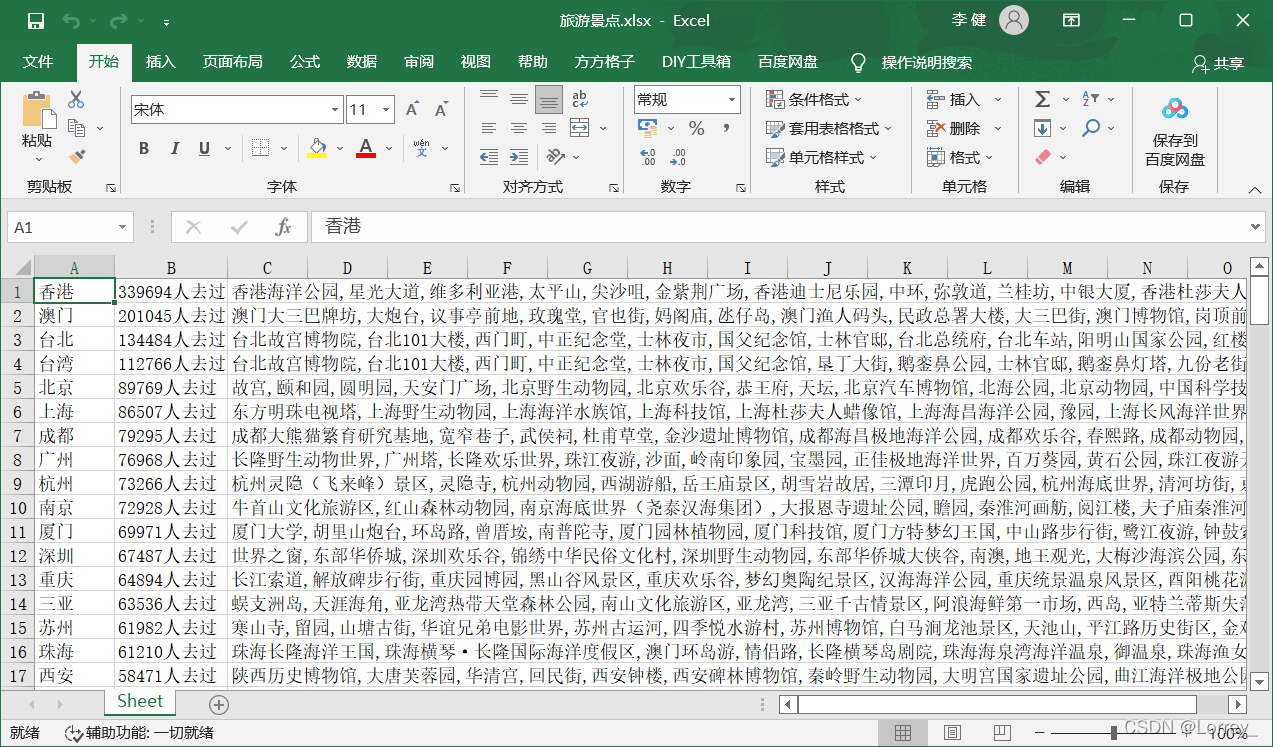
今天的目标是各地旅游景点
废话不多说,直接开始
由于本次爬取后的数据保存到Excel,所以要提前安装相关库,这里我用的是pip
win+R cmd到命令行输入以下内容(要确保python环境正常)
pip install Workbook
pip install openpyxl
接下来就可以开始代码操作了
# -- coding: utf-8 --
import requests
from lxml import html
from openpyxl import Workbook
#创建Excel
wb=Workbook()
ws=wb.active
#获取数据
url='https://place.qyer.com/china/citylist-0-0-1/'
def getpage(url):
#请求头,模拟浏览器登录
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.88 Safari/537.36'}
#访问链接,获取HTML
r = requests.get(url, headers=headers)
retext = r.text
# 解析数据
ht = html.fromstring(retext)
#使用xpath获取
city = ht.xpath('/html/body/div[5]/div/div[1]/ul/li')
for i in city:
name = i.xpath('./h3/a/text()')[0]
beento = i.xpath('./p[@class="beento"]/text()')[0]
list = i.xpath('./p[@class="pois"]/a/text()')
list2 = ''
# for j in list:
# list2=list2+','+j.strip()
# print(name,beento,list2[1:])
list = [place.strip() for place in list]
list2 = ','.join(list)
datalist = [name, beento, list2]
ws.append(datalist)
for i in range(1,10):
url='https://place.qyer.com/china/citylist-0-0-{}/'.format(i)
getpage(url)
#Excel保存
fileanme="D:\Python\Project\test4" #路径可以自己设置,我这里是python源文件同级目录
wb.save("旅游景点.xlsx")运行代码