相关库的导入
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.applications import MobileNetV2
from tensorflow.keras.layers import AveragePooling2D
from tensorflow.keras.layers import Dropout
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Input
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.applications.mobilenet_v2 import preprocess_input
from tensorflow.keras.preprocessing.image import img_to_array
from tensorflow.keras.preprocessing.image import load_img
from tensorflow.keras.utils import to_categorical
from sklearn.preprocessing import LabelBinarizer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from imutils import paths
import matplotlib.pyplot as plt
import numpy as np
import argparse
import os
构造参数解析器并解析参数
- 数据集:带口罩和不戴口罩的数据集的输入路径
- plot:输出训练图的路径,将使用matplotlib生成
- 模型:生成的口罩检测器模型的存储路径
#path 为你文件夹路径
parser = argparse.ArgumentParser()
parser .add_argument("-d", "--dataset", required=True, help="path to input dataset",default="path")
parser .add_argument("-p", "--plot", type=str, default="plot.png", help="path to output loss/accuracy plot")
parser .add_argument("-m", "--model", type=str,default="mask_detector.model",help="path to output face mask detector model")
args = vars(parser .parse_args())
设置学习率、epoch、batch_size
rate = 1e-4
epoch = 20
batch_size = 32
数据集的构建
preprocess_input(),这是tensorflow下keras自带的类似于一个归一化的函数,其对传入的图像做了归一化处理,能够加快图像的处理速度。paths.list_images函数能够直接获取文件夹下图片路径,即使有子文件夹。
imagePaths = list(paths.list_images(args['dataset']))
print(len(imagePaths))
data = []
labels = []
for imagePath in imagePaths:
print(imagePath)
label = imagePath.split(os.path.sep)[-2]
#导入数据,调整size为(224, 224)
image = load_img(imagePath, target_size=(224, 224))
image = img_to_array(image)
# 归一化
image = preprocess_input(image)
data.append(data)
labels.append(labels)
data = np.array(data, dtype= 'float32')
labels = np.array(labels)
# 对图像标签的独热编码
encoder = LabelBinarizer()
labels = encoder.fit_transform(labels)
# 转为二进制
labels = to_categorical(labels)
#分割数据集
x_train, x_test, y_train, y_test = train_test_split(data, labels, test_size= 0.2, stratify= labels, random_state= 42)
数据增强
ImageDataGenerator()是keras.preprocessing.image模块中的图片生成器,同时也可以在batch中对数据进行增强,扩充数据集大小,增强模型的泛化能力。比如进行旋转,变形,归一化等等。
- rotation_range(): 旋转范围
- width_shift_range(): 水平平移范围
- height_shift_range(): 垂直平移范围
- zoom_range(): 缩放范围
- fill_mode: 填充模式, constant, nearest, reflect
- horizontal_flip(): 水平反转
- vertical_flip(): 垂直翻转
aug = ImageDataGenerator(
rotation_range=20,
zoom_range=0.15,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.15,
horizontal_flip=True,
fill_mode="nearest"
)
模型微调
微调设置是一个三步过程:
- 加载预先通过ImageNet训练的MobileNet权重
- 构造一个新的FC头,并将其附加到Baseline上以代替旧的头
- 冻结网络的基本层:在反向传播过程中,这些基本层的权重不会被更新,而头层的权重将被调整
baseModel = MobileNetV2(weights='imagenet', include_top= False, input_tensor= Input(shape=(224, 224,3)))
headModel = baseModel.output
headModel = AveragePooling2D(pool_size = (7, 7)(headModel))
headModel = Flatten(name= 'flatten')(headModel)
headModel = Dense(128, activation= 'relu')(headModel)
headModel = Dropout(0.5)(headModel)
headModel = Dense(2, activation='softmax')(headModel)
model = Model(inputs = baseModel.input, outputs = headModel)
#冻结网络的基本层:在反向传播过程中,这些基本层的权重不会被更新,而头层的权重将被调整
for layer in baseModel.layers:
layer.trainable = False
#使用Adam优化器、学习率衰减计划和二进制交叉熵编译我们的模型。
optimizer = Adam(lr = rate, decay = rate/epoch )
model.compile(loss="binary_crossentropy", optimizer=optimizer, metrics=["accuracy"])
#数据增强对象(aug)将提供一批经过修改的图像数据
H = model.fit(
aug.flow(x_train, y_train, batch_size=batch_size),
steps_per_epoch=len(x_train) // batch_size,
validation_data=(x_train, y_train),
validation_steps=len(x_train) // batch_size,
epochs=x_train)
predIdxs = model.predict(x_test, batch_size=batch_size)
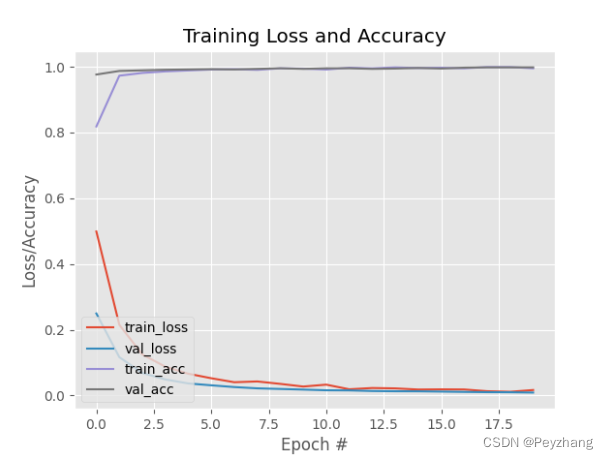
绘制loss曲线
N = epoch
plt.style.use("ggplot")
plt.figure()
plt.plot(np.arange(0, N), H.history["loss"], label="train_loss")
plt.plot(np.arange(0, N), H.history["val_loss"], label="val_loss")
plt.plot(np.arange(0, N), H.history["accuracy"], label="train_acc")
plt.plot(np.arange(0, N), H.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend(loc="lower left")
plt.savefig(args["plot"])
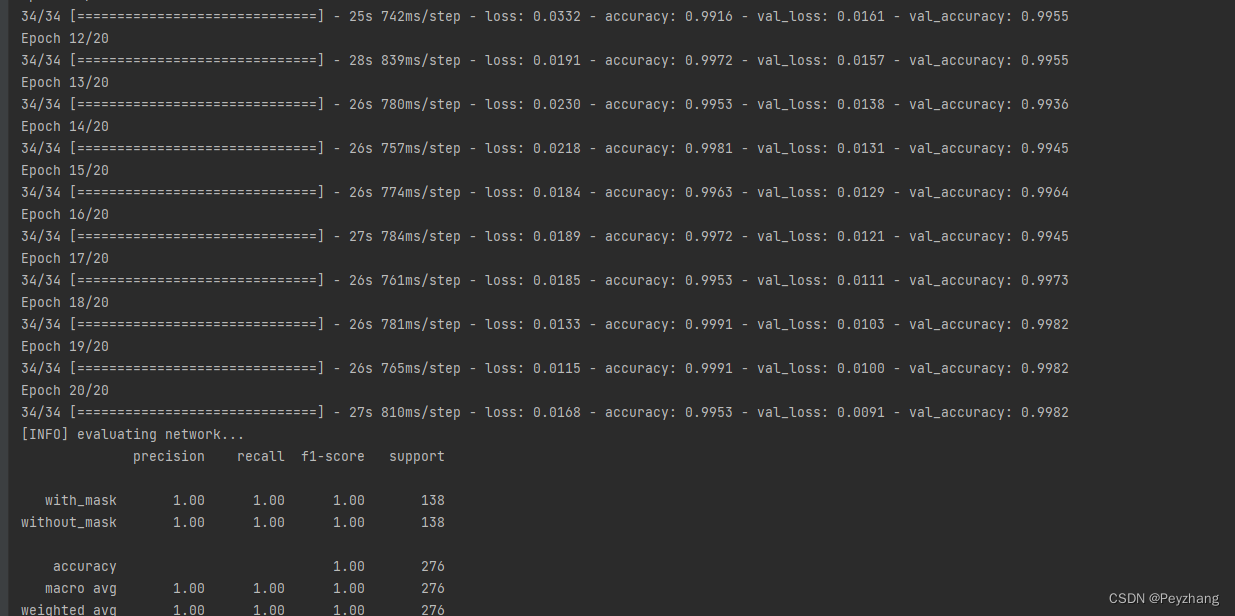
效果展示: