目录
安装nfs客户端nfs-client-provisioner
下载软件和镜像
VMware软件
电脑不能运行15.5.0版本,换成16.2.5
傻*注册,切换到英文页面(地址的cn改成en)才能用英文验证码
Ubuntu镜像
Ubuntu 20.04.6 LTS (Focal Fossa)https://releases.ubuntu.com/20.04/![]() https://releases.ubuntu.com/20.04/
https://releases.ubuntu.com/20.04/


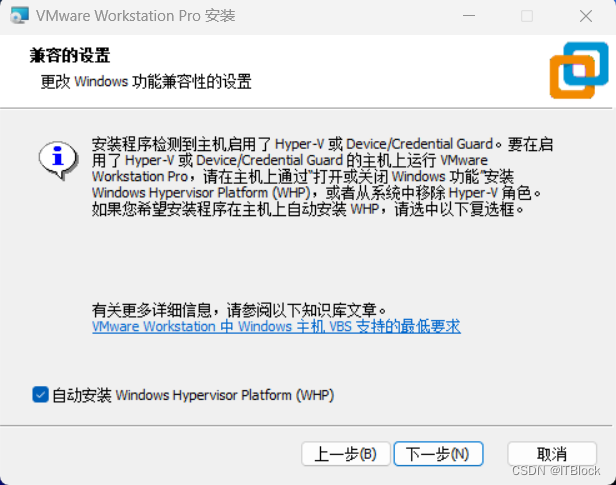
之前本地安装过docker-desktop附装了wsl还是hyper-V的虚拟机,可能就会弹出这个,自动安装下一步
16版本许可证ZF3R0-FHED2-M80TY-8QYGC-NPKYF
安装成功
安装和配置ubuntu
安装ubuntu,按以下步骤进行
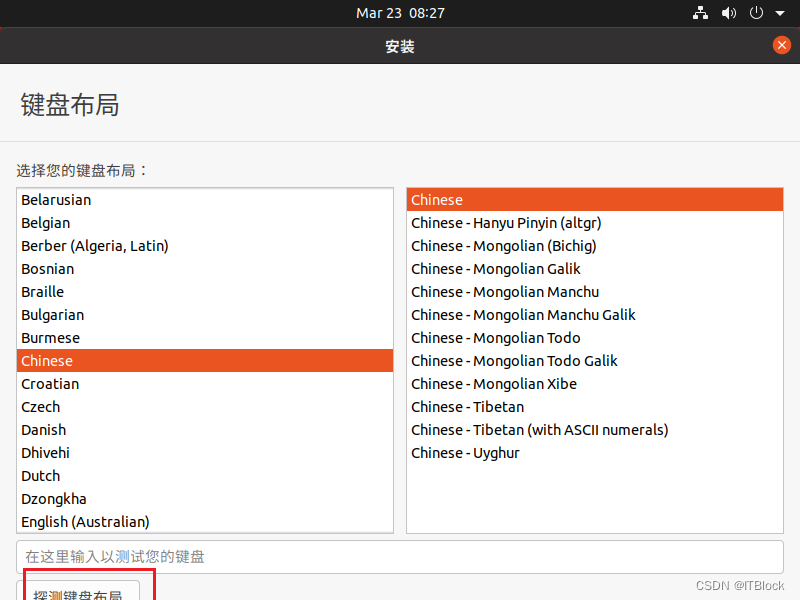
显示不全,图形界面下方的下一步按钮显示不出来,可能是显示器比例问题,停止虚拟机,
修改显示器成其他比例也不行
解决方案:快捷键 win键 + 鼠标左键按住安装弹窗,往上拖
继续按教程安装

安装完成
担心中途可能受网络限制无法下载一些资源包,配置虚拟机科学上网
一定要打开LAN,少走十年弯路
宿主机命令Ipconfig,找到正在上网的网卡,wifi或以太网接口,wifi的两个都可用:
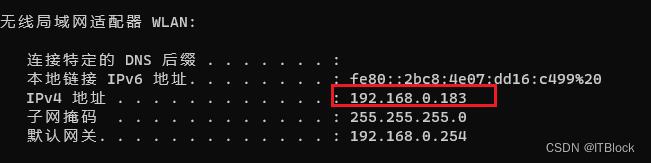
或
虚拟机网络设置中打开网络代理,选择手动,填写上面宿主机ipv4地址、科学上网工具代理的端口
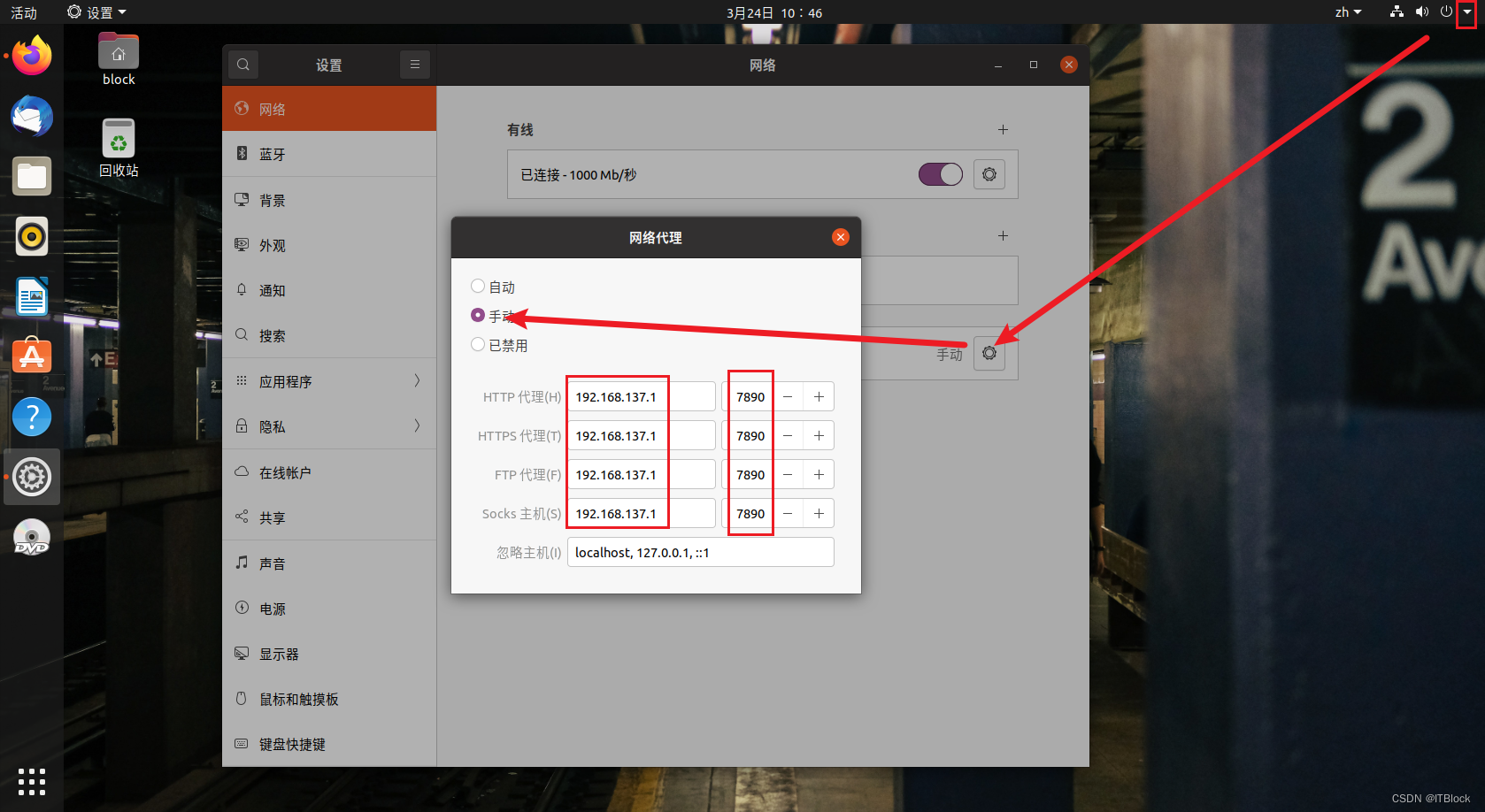
叉掉即可保存,浏览器可连google
部署k8s
1master、1worker
修改网络配置

参考如下配置虚拟机网络
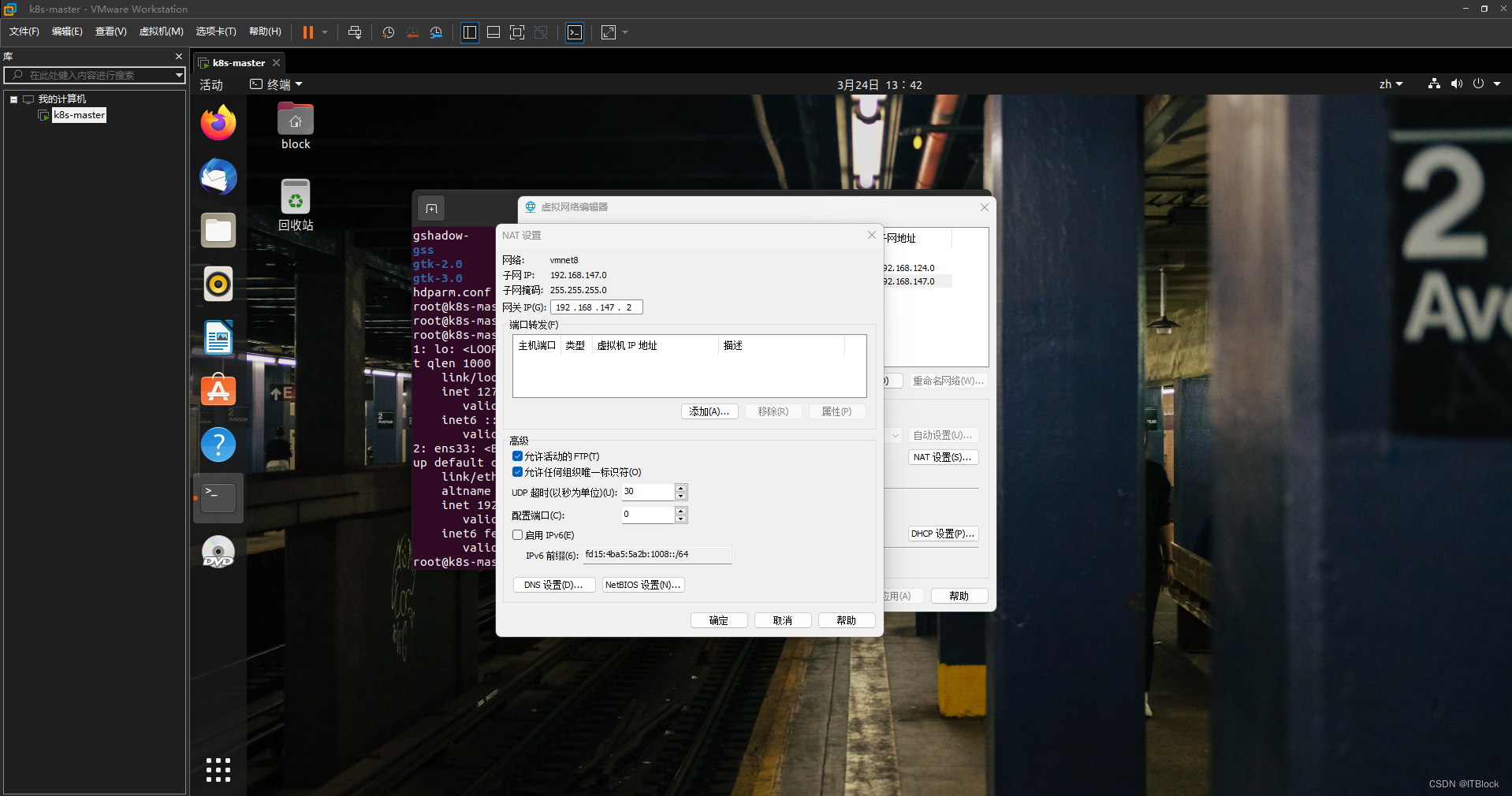
Vmware编辑 ->虚拟网络编辑 -> vmnet8管理员身份更改设置 -> nat设置 -> 网关ip
![]()
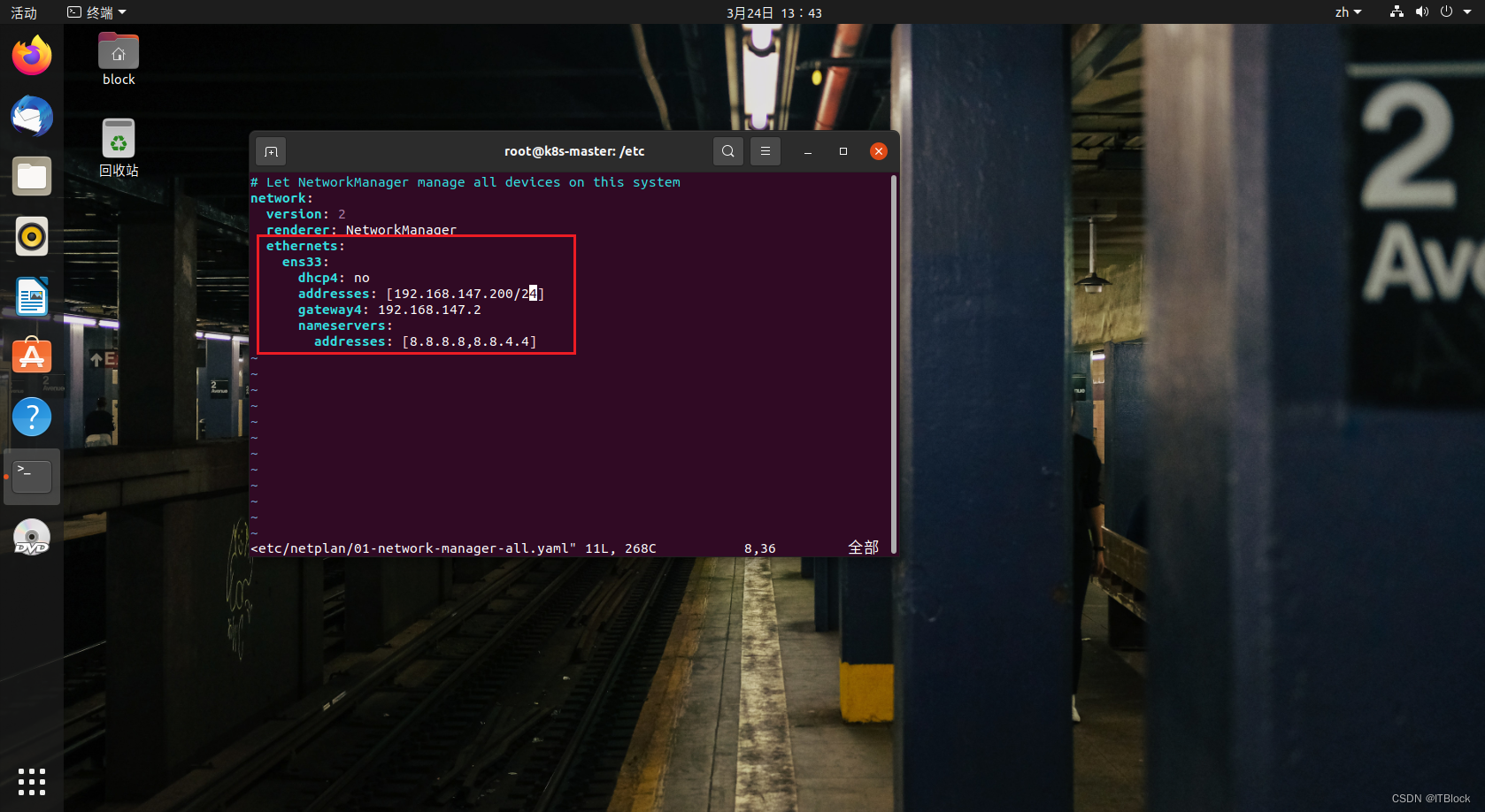
添加如下配置,addresss前24位需要和网关前24位相同(同一网段才能直接访问),gateway4填上面的网关地址,其余配置相同即可
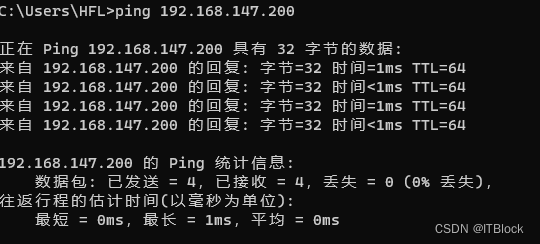
生效
![]()
修改成功

安装openssh

允许root连接
![]()
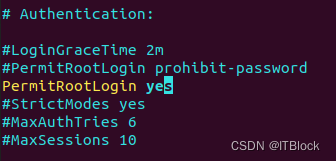
重启ssh
![]()
连接成功
k8s相关环境准备
继续按文章设置主机名、关闭防火墙和虚拟交换、转发桥接流量、安装docker、安装kubeadm
所有命令master和node节点都需要执行
注意点1
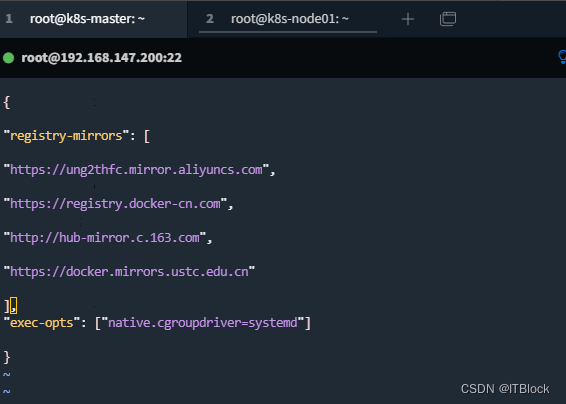
修改/etc/docker/daemon.json文件配置镜像源
配置镜像源参考如下:
注意点2
安装指定版本的k8s(高版本的kubeadm无法安装低版本的k8s)
apt-get install -y kubectl=1.22.1-00 kubelet=1.22.1-00 kubeadm=1.22.1-00
部署k8s
部署k8s参考如下
部署master
导出默认配置:
kubeadm config print init-defaults > kubeadm-config.yaml
自行修改以下注意点

或命令行(未实施)
kubeadm init \
--apiserver-advertise-address=192.168.147.200 \
--image-repository registry.aliyuncs.com/google_containers \
--kubernetes-version v1.22.1 \
--service-cidr=10.96.0.0/12 \
--pod-network-cidr=10.244.0.0/16 \
--ignore-preflight-errors=all
先安装镜像(master和node都要装)
kubeadm config images pull --config kubeadm-config.yaml
master节点init集群(tee保存日志,因为后续拓展节点要用上里面的内容)
kubeadm init --config=kubeadm-config.yaml | tee kubeadm-init.log
报错(博客中有说改 cgroup驱动,但我没改,下面补上)
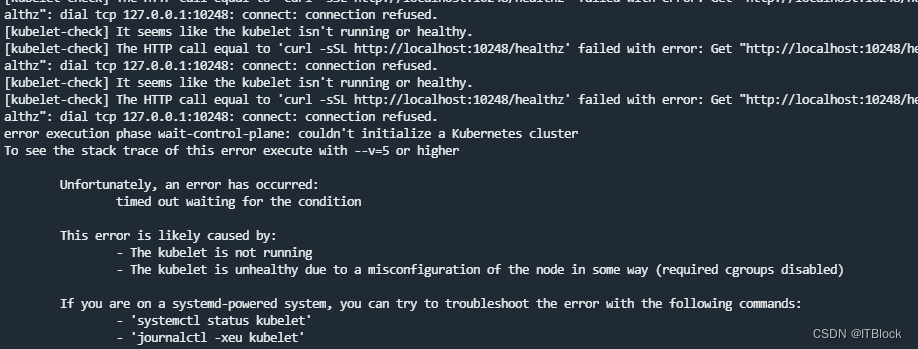
Master节点部署成功
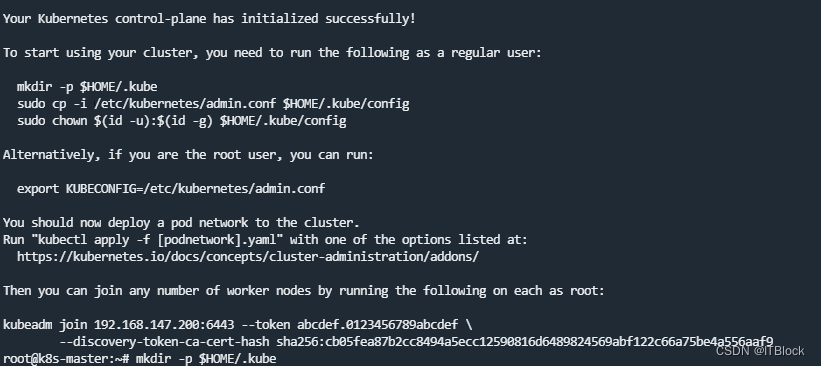
按控制台提示输入命令(为kubetcl创建访问集群的凭证)
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
正常访问

部署node01
切换到node节点执行上面控制台输出的命令
kubeadm join 192.168.147.200:6443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:cb05fea87b2cc8494a5ecc12590816d6489824569abf122c66a75be4a556aaf9
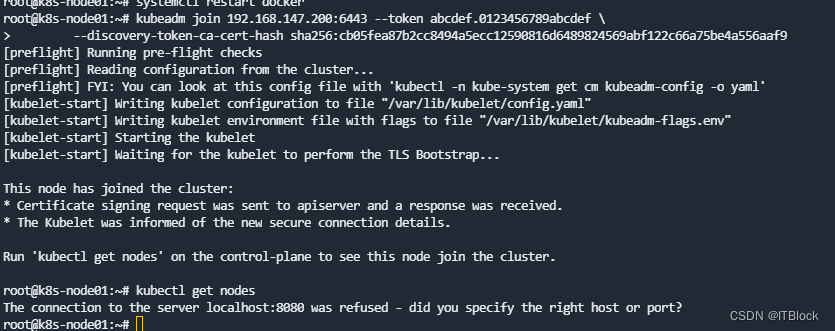
Node节点添加成功

保存重要文件
mkdir -p /usr/local/install-k8s/core
mv kubeadm-init.log kubeadm-config.yaml /usr/local/install-k8s/core
配置网络插件flannel
Node节点还是notready,因为还没给他添加网络配置
# 创建文件夹
mkdir -p /usr/local/install-k8s/plugin/flannel
# 进入flannel文件夹
cd /usr/local/install-k8s/plugin/flannel
# 下载flannel配置文件
wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
# 安装flannel
kubectl create -f kube-flannel.yml
开始安装CNI插件flannel,先查看所有的pod,发现coredns一直在pending,输入命令查看coredns详情:


提示有taint,这是因为默认master节点是不可以调度的,node01又还在配置网络,集群没有可以调度的节点,就会一直pending,等待配置完即可
片刻后,一切正常:
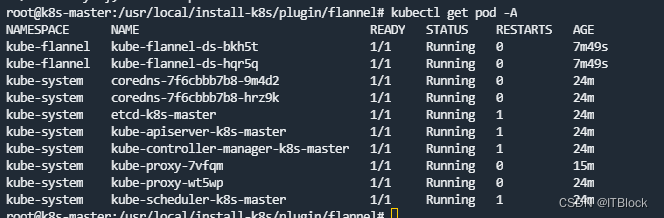
Node节点已就绪

部署kubesphere
配置默认StorageClass(NFS)
wget保存文件
apply立刻报错
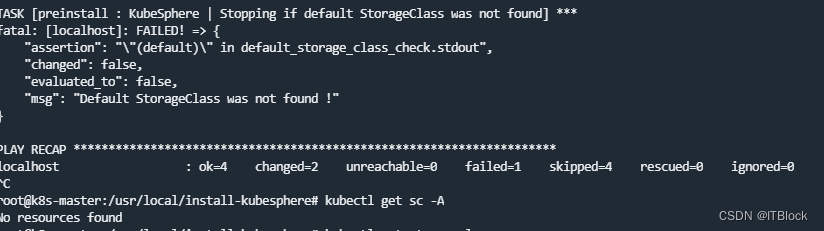
去看官网才知道必须要有默认sc
安装nfs服务端
参考如下配置sc,使用nfs类型
配置Ubuntu的nfs服务端(我搭在了master节点,尝试装在node节点,但不知道为什么使用客户端去mount的时候总是卡死,可能是因为当时我node节点既作为服务端,又作为客户端出了问题,但我在master节点上用客户端去mount也不行,以后再复盘一次,后面把master和node上的nfs安装包都卸掉,把master作为服务端、node作为客户端就行)

理论上客户端不需要安装,下面会起一个nfs-client-provisioner的容器,当我们yaml配置文件需要一个和pvc匹配的pv时,这个容器会自动连接nfs服务端,在挂载的目录下创建一个目录作为pv,集群里可直接使用这个pv,容器内部可能就是去mount了服务端,集群要找pv,就去容器里找mount到容器里的目录
安装nfs客户端nfs-client-provisioner
配置sc
这里可能会出现下面的情况,启动nfs-client-provisioner后事件里报错找不到flannel相关的东西,这个是因为nfs-client-provisioner运行的节点不受flannel管理(比如我的master节点初始化时默认是不参与调度的,可能就不受flannel管理),但很神奇的是,他虽然报这个错,但过一段时间他又能正常运行了,而且是运行在node节点上,可能是集群调他到node上了
![]()

安装kubesphere
我当时看到 nfs-client-provisioner在运行,立刻就开始输命令安装kubesphere,但装完后发现,但看到kubesphere自带的普罗米修斯还在pending
![]()
查看原因describe
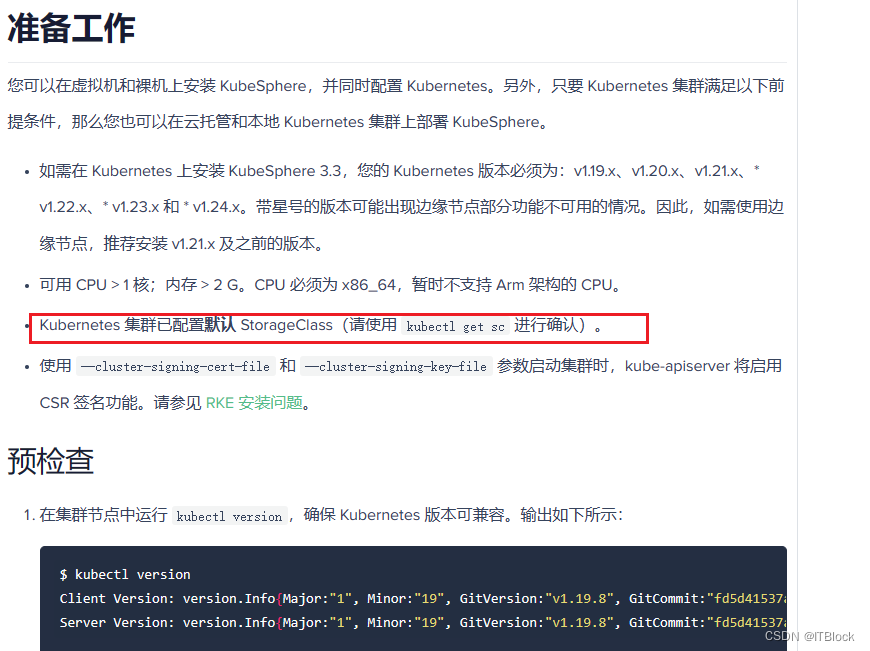
0/2 nodes are available: 2 pod has unbound immediate PersistentVolumeClaims.
这说明nfs并没有配置成功,kubectl logs发现 Nfs客户端内部报错,PV没有自动创建
waiting for a volume to be created, either by external provisioner “fuseim.pri/ifs” or manually created by system administrator
解决
这里我重启了虚拟机(可能nfs-client-provisioner又会报错,我的就是报错了,而且事件中没有显示创建成功之类的信息,但又能正常running)
然后测试了一下pvc(test-claim),成功
普罗米修斯也可以挂载PVC了
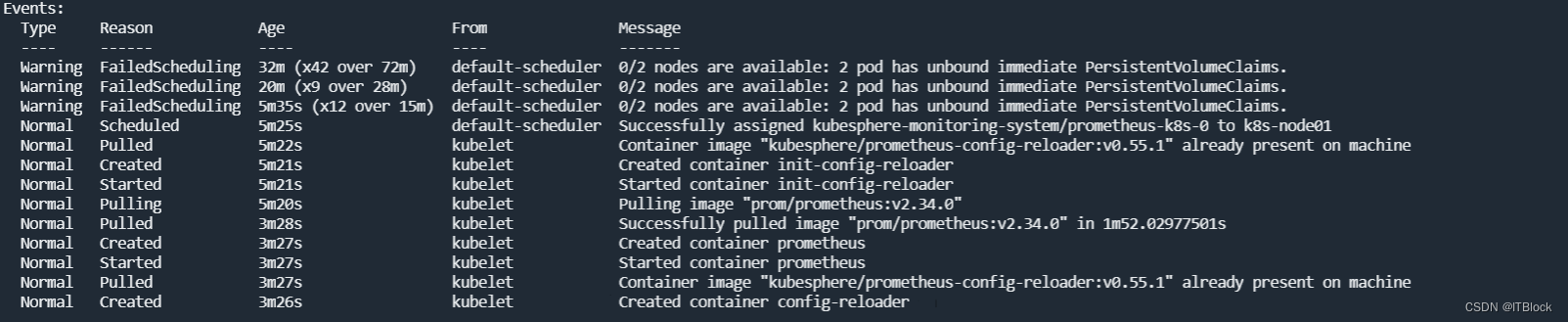
Node节点上mount服务端的目录进行检查,确实有创建
![]()
Nfs客户端provisioner自动创建PV相关知识
安装devops插件
安装后的kubesphere没有devops功能,看官网,动态添加
日志最后显示一大段报错
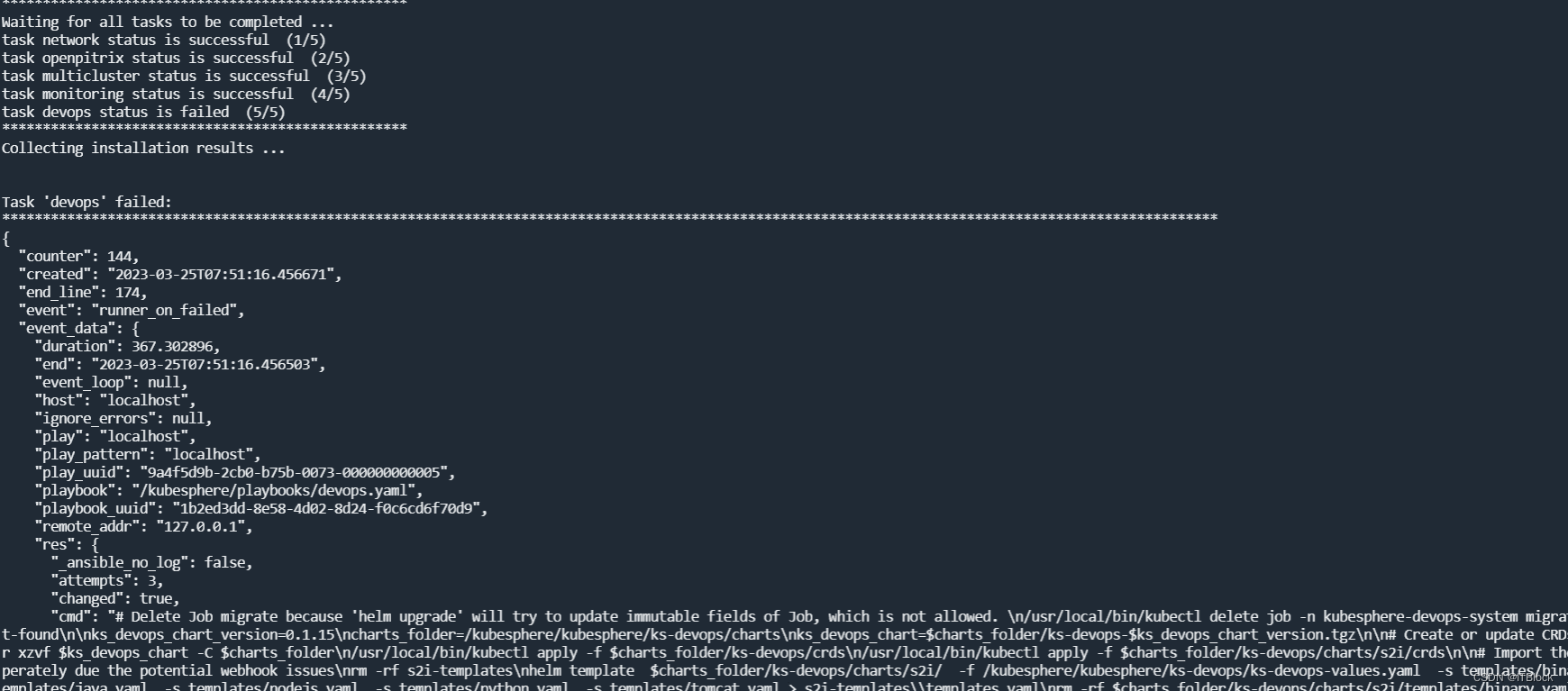
组件基本没起来
先卸载devops热插拔组件
我还删除了很多附带安装的组件,openldap、minio、argocd等,将大部分devops相关的东西都一一删掉
怀疑安装失败是由于内存不够以及当时没开代理
给node节点加了4g的内存,开代理、重新安装devops时调整devops的内存要求

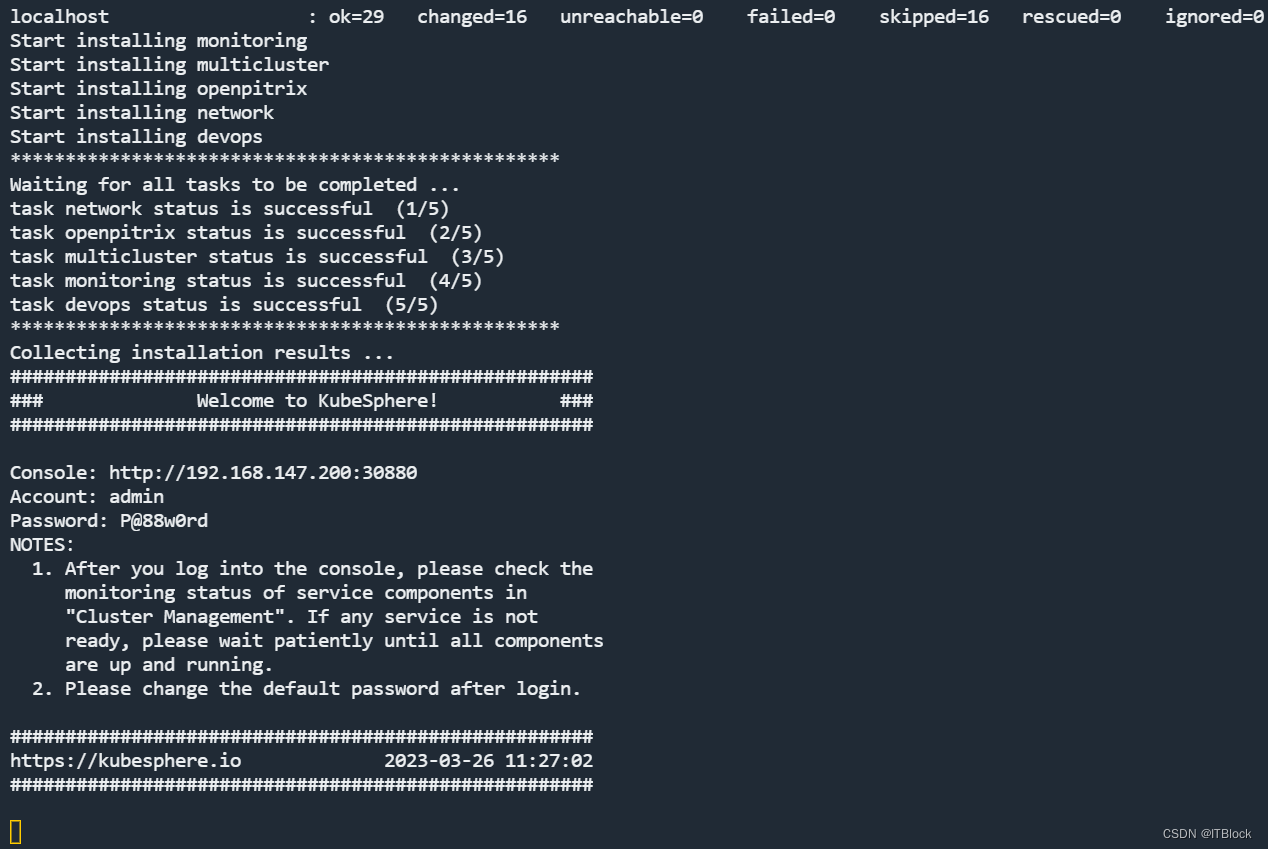
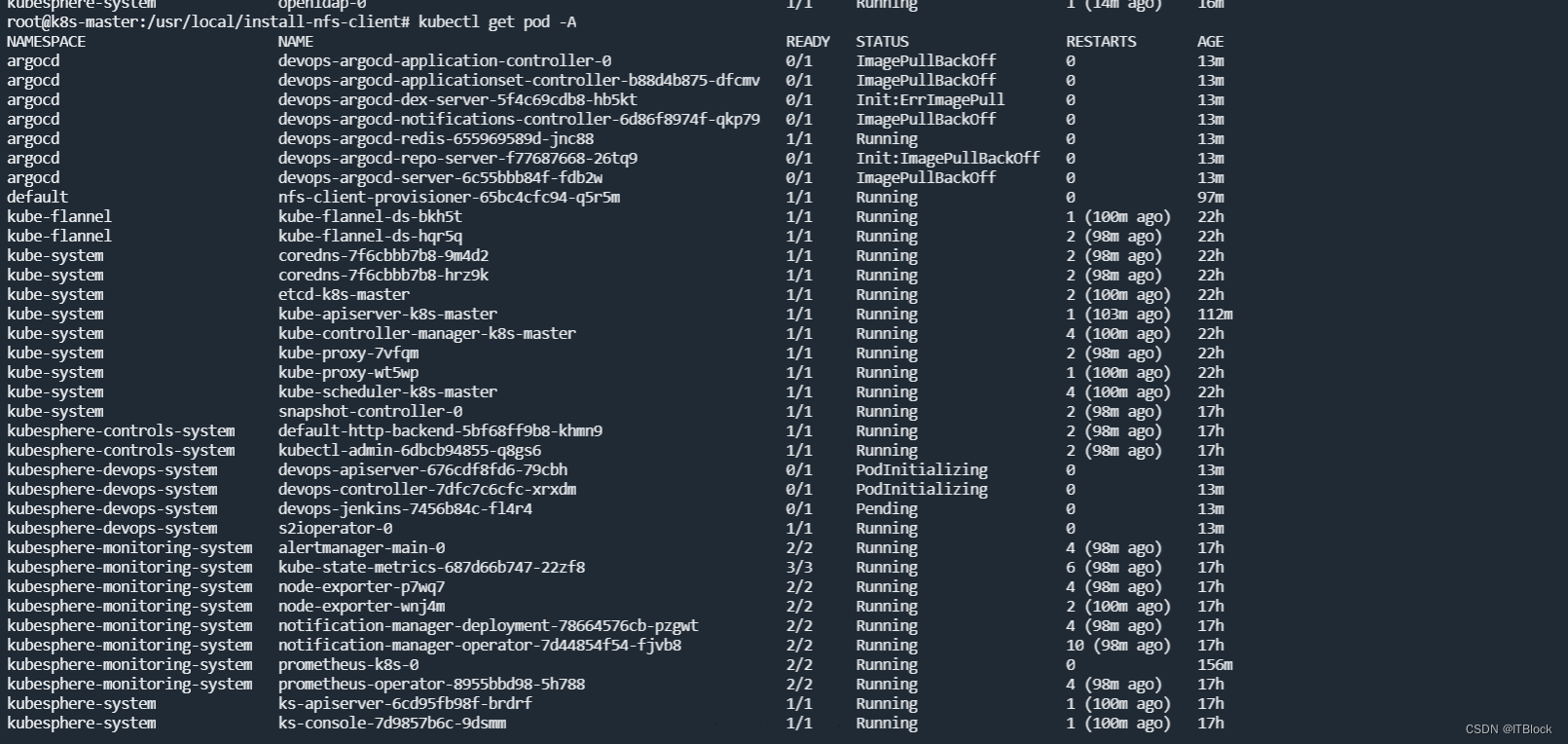
安装看似成功了,但有很多pod还在创建(拉镜像)
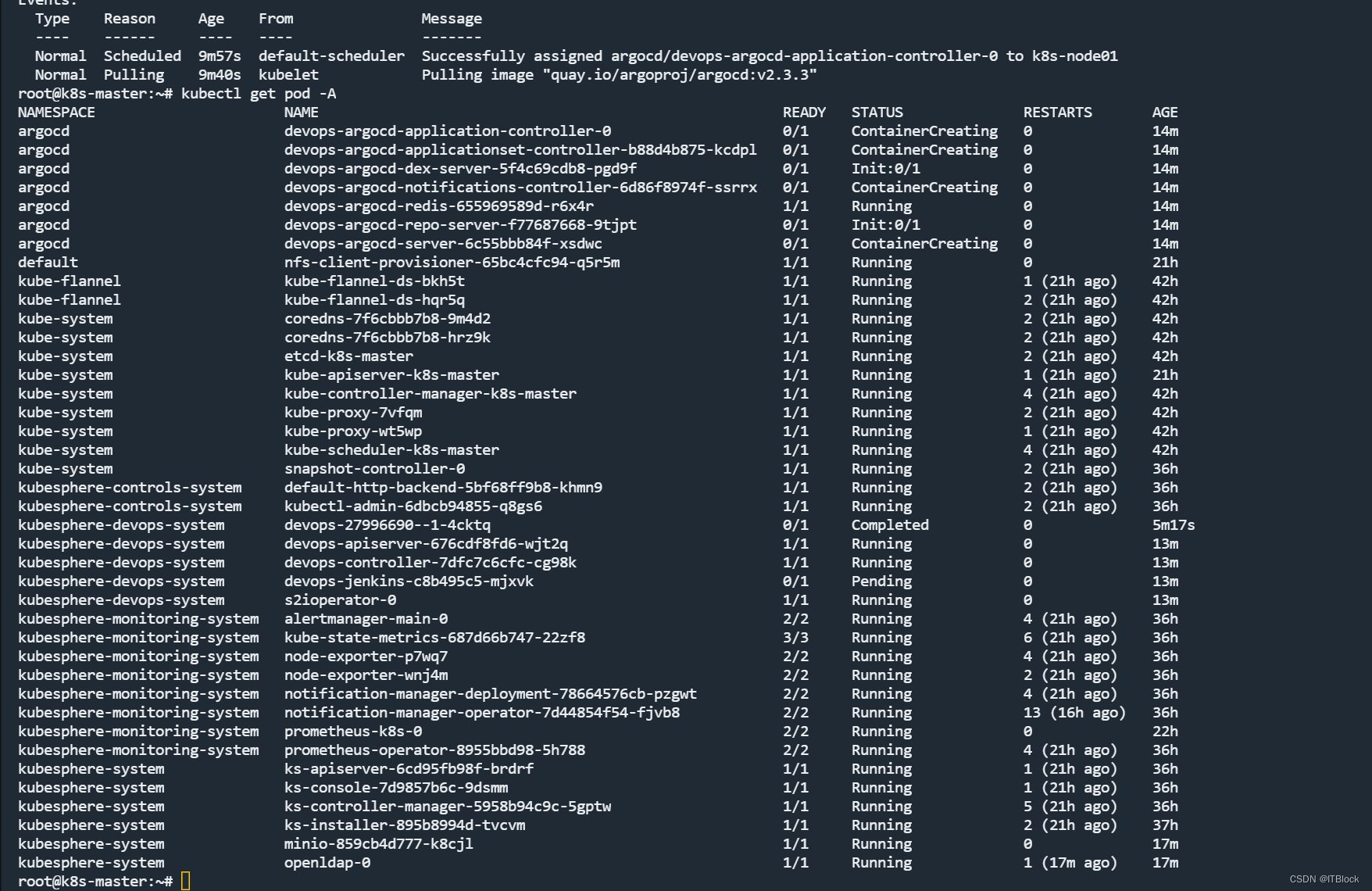
看到argocd很多pod都用一个镜像,直接docker帮他拉下来
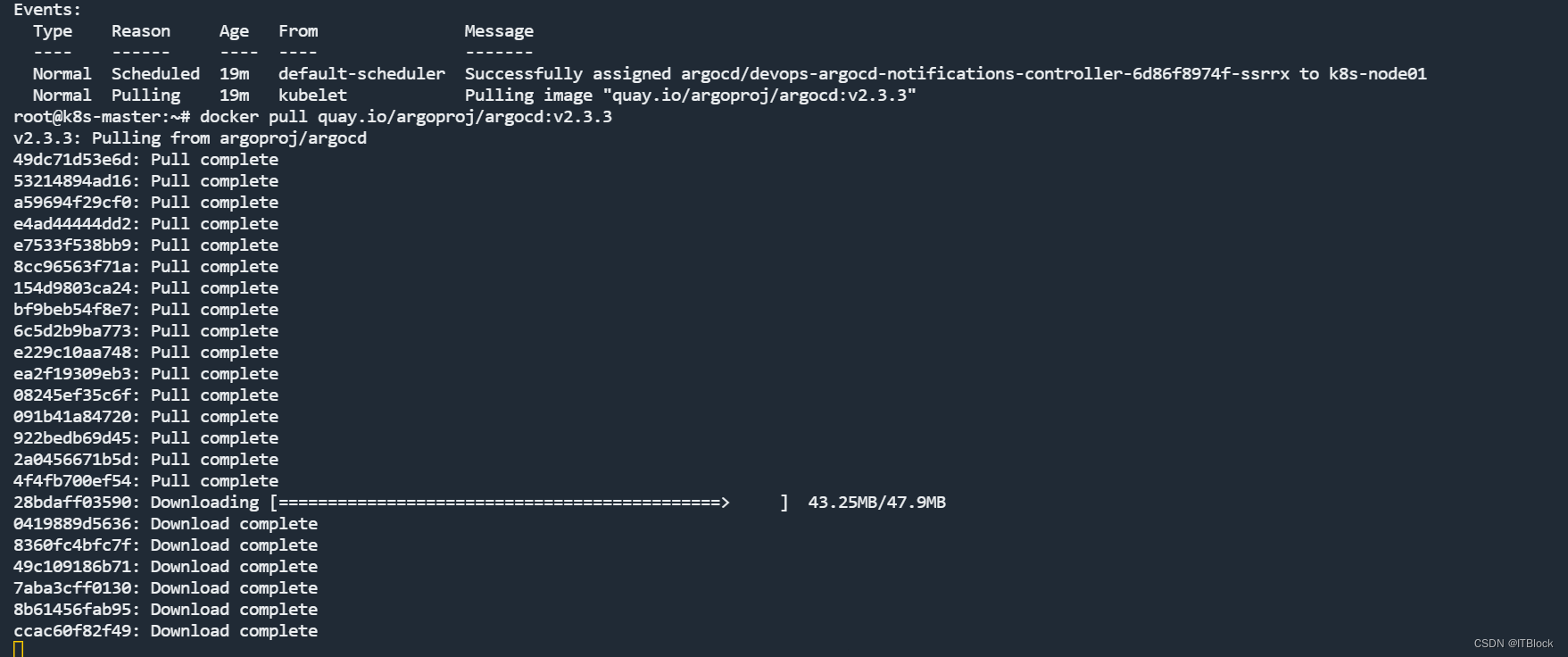
等待,argocd已就绪

前面的截图中有个devops-2799…的pod处于complete,直接删了并没有重启,可能只是个检查相关的pod,不影响
还有个看似很核心的pod一直在pending
![]()
查看发现他没被调度

发现是CPU资源不足,describe中查看信息,cpu至少要2个核,我node节点总共就分了2个核,加大虚拟机cpu分配(加多2个核),其实这个限制可以在enable时调整内存那块改cpu限制
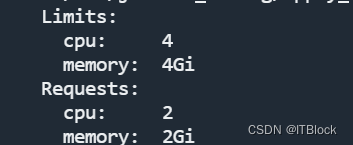
改cpu好像要重启虚拟机,重启(重启集群,nfs-client又挂了,镜像的标签是latest,以后要改成固定版本,等他拉镜像)
![]()

Devops-jenkins开始拉镜像了

拉失败了

docker帮他拉
这个镜像挺大的,可能会拉失败(我第一次就失败了)
第二次

拉完镜像,devops-jenkins成功拉起
![]()
虽然running但ready0/1,describe发现就绪探针出错
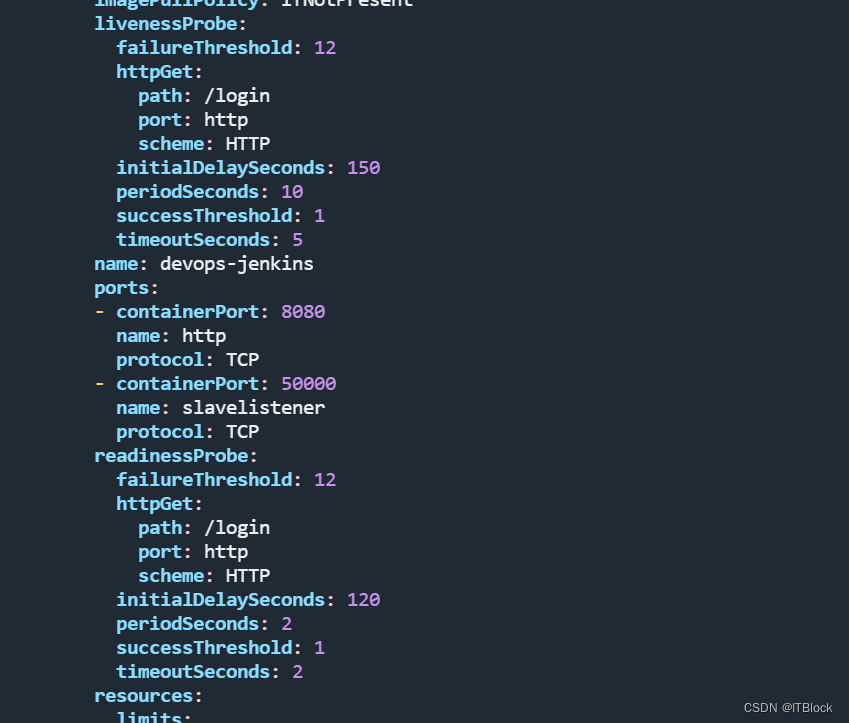
增加就绪检测的延时initialDelaySeconds
导出deploy配置
![]()
修改配置
![]()
就绪改成120秒,存活改成150
重新部署
![]()
还是不行

尝试再加大延迟时间(就绪7分,存活7分半)
重新导出yaml修改再部署,不然会说版本没变化不给更新
就绪有问题,存活没报错

真跑起来了
![]()
后续再加大就绪和存活探针的延时,我是延迟到了8分和8分半,就都没有报错了,如果不行就尝试再加大延时,这样唯一的缺点就是每次启动集群都要等上10来分钟才能访问kubesphere的一些页面
成功部署devops
kubesphere-devops入门
去官网学习怎么使用,第一次一定要跟着完整做一遍
运行流水线(会显示队列中),发现每次都要启动一个base的pod
![]()
第一次要拉一个很大的镜像,可以直接用docker帮他拉

base还要起一个jnlp容器,要拉另外一个大镜像jenkins/inbound-agent:4.10-2
流水线运行成功
流水线运行结束后base也会自动销毁
进入jenkins自带的dashboard(账号密码已经初始化成kubesphere的初始值):
![]()
这里我认为理应是修改后的密码,但还是要用初始密码,原因还不确定,但devops-jenkins容器内部有一段时间一直在报类似下面的异常:
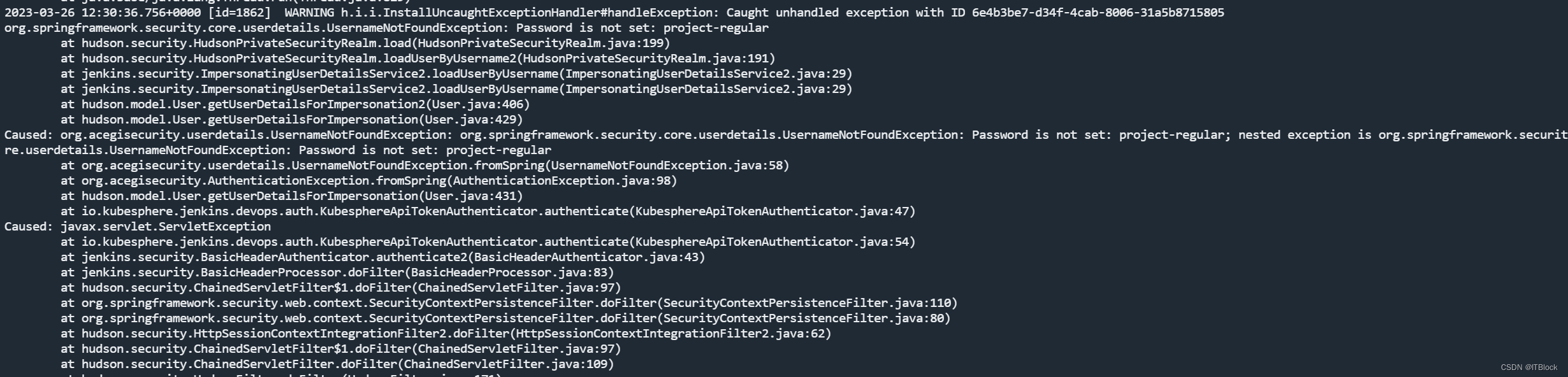
可能是jenkins密码和kubesphere没同步导致的
Kubesphere-devops部署成功,感谢文章中引用到、以及过程中为解决各种小问题参考过的博客。