接上篇,将安全运营的定义为“使用算法能力提取关键信息”,以此来规避算法误判漏判带来的责任问题,同时提升运营人员的工作效率。在这篇尝试对语言模型的使用方法做一下讨论和分享。
1. 语言模型
先聊一下语言模型。(这里刻意规避了“大模型”这个词,主要是对其应用方式的理解还不深刻)
直到ChatGPT出来之前,我都没有太关注过NLP领域相关的算法应用,主要是认为和我们更常涉及的应用领域,如分类、推荐等,有比较大的差异。

个人认为,语言模型的独特之处,在于“特征的离散性”。我们常见的特征分为两种:1)在推荐等领域中,人为去计算的各类特征,比如用户的年龄、性别、活跃时间等,这些特征都经过人工预处理,转化成向量,供算法去使用的;2)在图片、音视频领域中,这些内容本质上是一堆数字信号,因此输入本身就是向量化的。而语言是人类诞生的一种高效信息载体,虽然最终会以图形或声音的方式呈现出来,但语言本身如何进行编码,却隐藏在我们的大脑中。因此,NLP首先遇到的问题就是如何将文本变成向量,也就是NLP中反复提及的embedding。
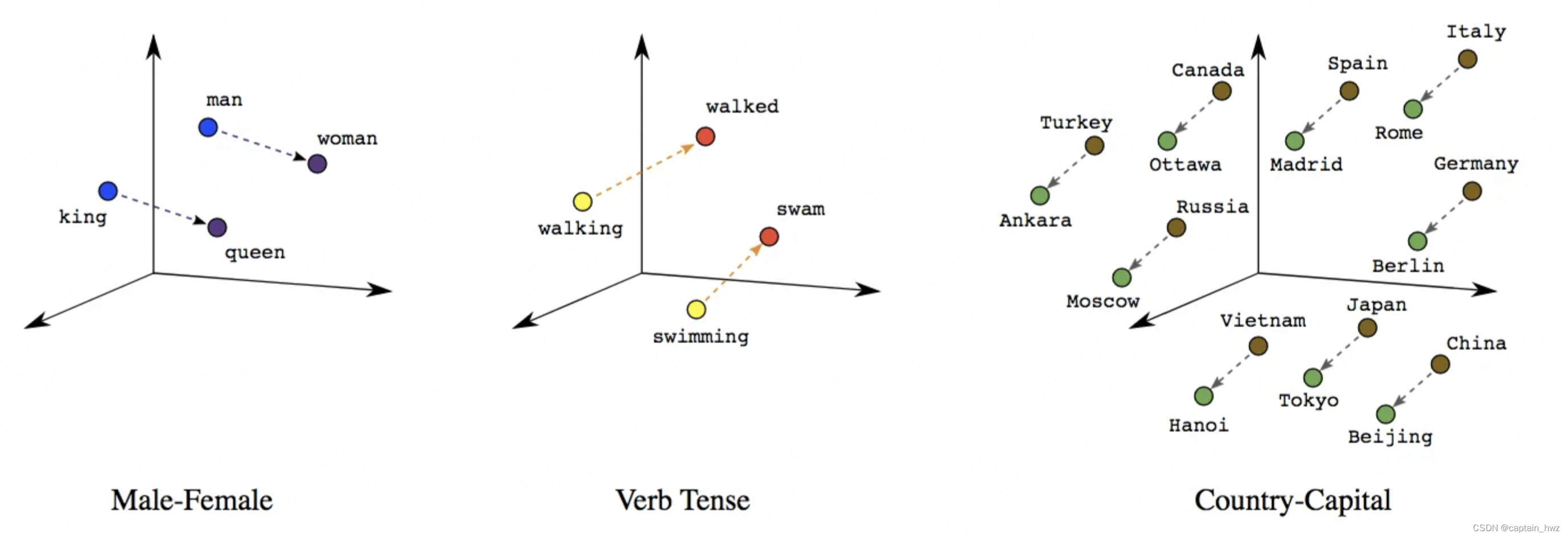
而安全领域也存在着这种隐藏在大脑内的认知关系。最简单的,Web安全中SQL注入就有很多特征和对抗,不同的payload,不同的编码。即使WAF具备了检测逻辑,也会带来误报过高的问题。但其实在安全专家进行人工运营的时候,大部分情况下是能够做出精准判断的。差距主要有两点:
1)人接收的信息量更大,可以去关联上下文,可以去查看进程,可以去研读代码等等。所以安全的一个长期发展方向就是找到更多的数据切面,将更多的日志关联起来,HIDS/RASP/SIEM等
2)人是能够理解payload的具体含义的。写规则的时候,我们会告诉机器去检测哪些关键字,但机器并不理解关键字的含义,所以攻击者可以尝试去绕过。
我之前提过,ChatGPT出来之后,证明在NLP领域下,机器开始理解人类世界了。因为机器见到的不再是精心构造的特征,而是相当原始的token。当算法去学习一项任务的时候,它尝试去捕捉这些原始的token中的复杂关系,正如人类的思维一样。 也因此,我会认为,语言模型的成功,意味着安全领域下的专家经验,可以逐步被替代。
2. 基于RNN的做法
在transformer出现之前,RNN是NLP领域最经典的模型结构,它巧妙了处理了特征中的时序关系。因此,在时序场景中,通常都会看到RNN的身影。比如,安全场景中的事件序列。
下面借助一篇论文展开讨论RNN的应用方式。
Van Ede, Thijs, et al. "Deepcase: Semi-supervised contextual analysis of security events." 2022 IEEE Symposium on Security and Privacy (SP). IEEE, 2022.
这篇论文的目标定义为了,提取事件序列中的关键事件,从而提供强可解释性。同时这些关键事件也可用于后续的加工处理,如相似性判断等。论文中设计了如下的模型结构:

经典RNN中的Encoder和Decoder结构比较类似,输出目标是预测下一个事件。而在安全事件研判中,我们不需要去进行预测,而是一个找关键特征和分类任务。因此,论文中将RNN的Decoder替换成了一个线性层输出,输出的目标是每一个事件对应的权重。
简单来说,就是使用RNN的Encoder去对事件序列进行信息压缩,相当于embedding的过程。然后基于Encoder后的向量,去嵌套其他算法完成目标任务。
该论文的主要启发在于,我们可以通过构造算法结构,来满足可解释性的需求。而可解释性,通常体现为特征的权重。类似于,我们在做复杂事件判断的时候,往往依靠的是“直觉”。虽然“直觉”怎么产生的很复杂,但我们通常能够说出其中的关键因素是哪些。
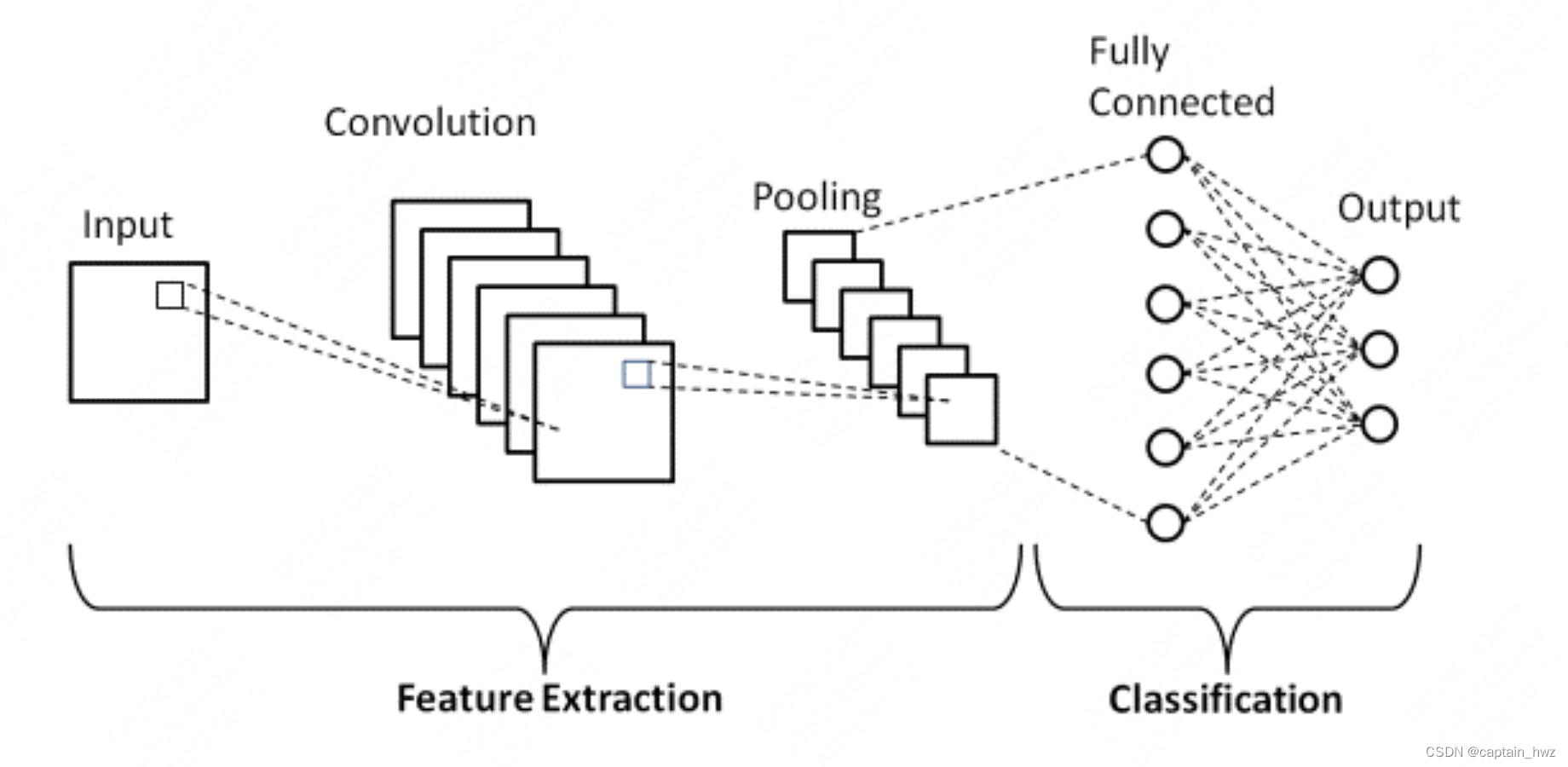
这个结构也让我想起了CNN中的分层思路:先卷积作特征提取,再池化作压缩,最后全连接完成分类特定任务。每一层的输出都是可以被呈现的,分别提取了哪些特征。比如先提取线和边,再构造局部形状等。
这篇论文不满足需求的地方在于,它设定的输入是事件序列。而事件是一个需要经过提前编码的东西,适用性会受到限制。
3. 基于Bert的做法
Transformer的提出,除了解决了RNN的串型训练问题,还将预训练的模式引入到了NLP领域,大幅度降低了应用的门槛。在ChatGPT中,可以看到预训练好的模型已经包含了相当丰富的专业知识。因此,对比RNN需要从0开始训练模型,从预训练出发,尝试用更纯粹的NLP模型来解决安全领域的问题,会是一个更有意思的尝试。
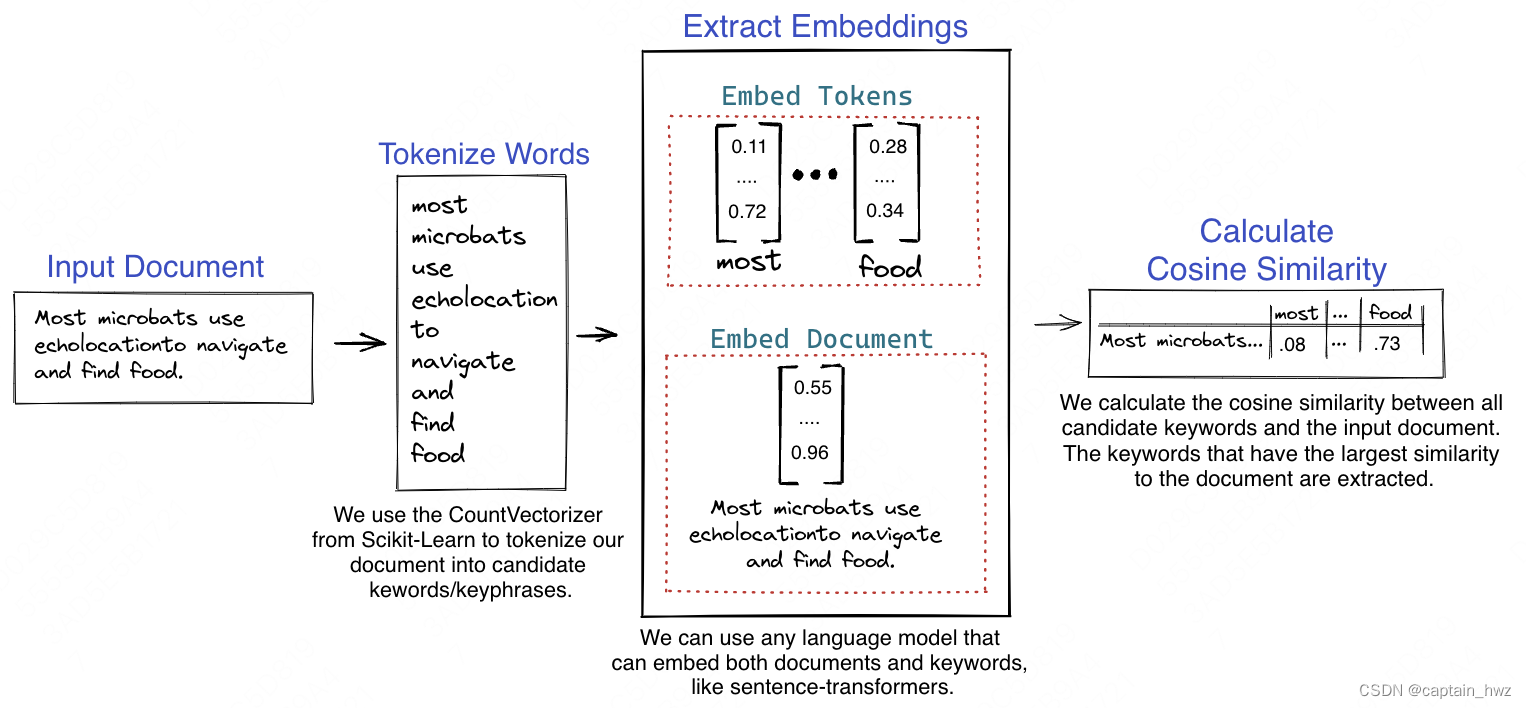
NLP中embedding是一个很神奇的存在,它能够将离散的token转变为向量的形式。而转化后的向量本身,也包含了相当多的信息。例如,直接计算向量之间的余弦相似度,通常就能够代表不同词之间的含义相近程度。基于这个原理,可以使用训练好的embedding,来完成关键词提取工作,比如KeyBERT。
结合上一篇讲的,将告警运营当成一个分类+关键词提取的过程,可以设计如下的算法结构:(这里也可以参考上述的RNN结构来设计,但涉及的自定义开发工作量会更多。因此,不在论证阶段展开。)
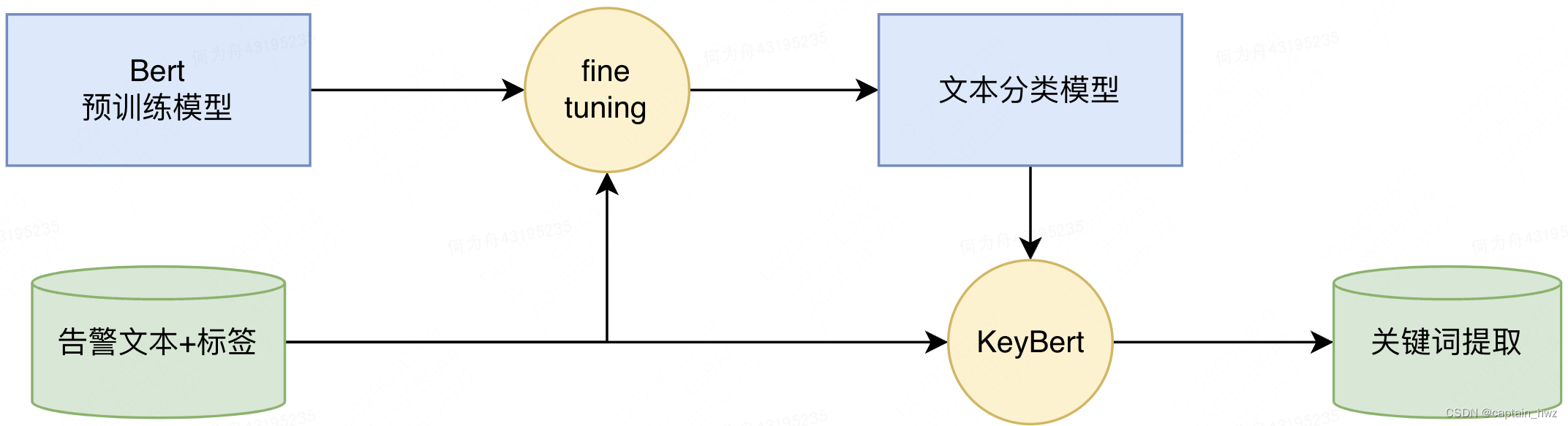
这个算法本身是简单拼凑,不难实现。核心在于,如何将告警信息进行“文本化”。 通常来说,我们处理的告警信息是个结构化的数据,比如JSON格式,它其中包含了时间、IP、可疑payload、关联的其他节点等各式信息。而使用Bert预训练模型意味着我们不能够人为将它进行编码,而是需要把结构化的数据构造成文本的形式。幸运的是,预训练好的模型足够强大,对文本语法基本不挑剔,在试验中,直接把键值对作拼接,就能够取得还不错的效果。
很难说这是一种进步还是退步。直觉上,把信息进行人工编码,可以提升机器学习的效率,但也使得人工编码本身成为机器上限。而将结构化信息转化成更原始的文本信息,机器的学习空间更大,但任务复杂度也更高,“大力出奇迹”。这也意味必须依靠预训练模型才能够实现,不然训练量过于庞大,无法普适。
4. 基于GPT的做法
Bert和GPT的差异,主要在于Bert更擅长处理特定目标的任务(如分类),而GPT更强调“生成式”这个效果,依靠“预测”下一个词来完成各种任务。随着OpenAI把参数量大幅度扩增,大模型的智能开始“涌现”(参数量达到某个临界点后,结果表现突然上升),似乎意味着“万物皆可生成”。
事实上人类也是依靠“生成式”来完成各种任务的,不论思维方式如何,最终输出都是以一段话、一系列动作等形态来呈现的。
进入“生成式”的应用场景后,如何设计Prompt变成了主要工作。因为生成式的输出是不固定的(问ChatGPT同样的问题,给出的答案不论是结构还是内容,都是不同的),并不利于成为一个接口对接其他上下游系统。因此,我们需要构造合适的Prompt,并进行一定的fine-tuning,确保GPT学会这个Prompt对应的问答模式。
具体实现思路上,会参照Bert的模式,先训练GPT完成分类任务,再训练GPT完成关键词提取。

以上过程使用OpenAI提供的API即可完成。但会遇到的一个问题是,往往并不存在“告警文本+关键词”的训练样本(日常运营过程中,安全专家会对结果做出判断,但不会把判断过程写下来)。在OpenAI自己实现的过程中,会构造人工打标的奖励模型来解决这类问题,但相关API并不开放,因此对构造样本集提出了一定的挑战。
现有模式下暂时没想到合适的解法,除非自己搭建GPT环境(成本略高,Bert还勉强能够本机跑下来,GPT则相当以来GPU环境),又或者干点脏活累活,一点一点积攒人工打标数据。
5. 总结
通过近期的研究和一些简单试验,会认为NLP模型是提升算法在安全领域下发挥潜力的方向。它使得机器看到的内容和人保持一致,而不在局限于人工编码带来的上限。同时,借助预训练得到的知识储备,快速完成目标任务的学习和适用。
但试验过程中,也会遇到一些困难,比如:
1)目前NLP模型的输入长度都相对受限制。而安全运营场景下,尤其是在接入SOAR之后,一起事件的关联信息是相当丰富的。而将事件文本化,本身就会降低信息传输的效率,很难将文本长度压缩到目标范围内。这个时候,要么事先剥除无用信息,要么把文本做分段输入。但不论哪种做法,都会带来实现难度的大幅提升。
2)NLP模型的复杂度提升,可控性也有所下降。虽然能够完成关键词提取任务,但模型是如何判定的,仍然难以琢磨。尝试使用过SHAP来探究,但目前看效果并不理想,有待进一步挖掘。这种不确定性,对于调整模型结构、优化样本集等工作,都带来了更多的“玄学”属性。

整体来说,个人倾向于认为语言模型下的智能涌现,代表着未来的发展方向。但目前的算法成熟度仍然处于初期,至少对于如何普适性的应用(而不是集中在大厂手里),仍然有很大的发展空间。而在当前条件下,做一些探索性质的工作,大概率抵不过算法整体的发展趋势,但有利于加深对算法本身的理解,为后续做好技能储备。
