Python爬虫老生常谈的话题了
像兼职接单、爬取小说电影榜单、商业化的数据收集等,在大数据时代它能用到的地方还是蛮多的。
业余玩玩小意思,如果是想要往这方面学精学深,那得下一番功夫了。
爬虫能力按层次来分大概也可以分为初级、中级、高级、更高一级这四个水平,要说爬虫技术能不能达到巅峰?
反正我是不敢说有,毕竟学海无涯、学无止境,可以朝着这个目标奋斗哈哈~

一、初级爬虫
掌握Python的语法和一些常用库的使用
虽然说学爬虫不需要做到那么精通Python,但如果你是零基础上手编程,基础语法还是要认真去学的万丈高楼平地起!
【初级爬虫的技能要求】
- Python 【语言基础】
- requests 【请求相关】
- lxml【解析相关】
- XPath 【解析相关】
- BeautifulSoup【解析相关】
- PyQuery 【解析相关】
- MySQL 【数据库】
- MongoDB【数据库】
- Elasticsearch
- Kafka【消息队列相关】
这个阶段最主要的就是掌握Python语法基础、常用库的使用;
请求库的话一般Requests能应付大部分简单网站的爬取,当然是在没有反爬机制的前提下。
Selenium的话主要是用它来模拟真实浏览器对URL进行访问,从而对网页进行爬取,往往要配合PhantomJS使用,Selenium+PhantomJS可以抓取使用JS加载数据的网页。
解析常用到XPath、BeautifulSoup、PyQuery 或者正则表达式,初级的话能够熟练两三种解析库基本也够用了。
正则一般用来满足特殊需求、以及提取其他解析器提取不到的数据,正常情况下我会用bs4,bs4无法满足就用正则。
没有基础的话,在Python入门这一块需要消化的知识点还是不少的。
除了Python之外,基础的计算机网络知识、CSS、HTML等这些都是需要补充学习的。
那些陌生的密密麻麻的知识点介绍,有些同学看了可能会当场劝退!
给零基础初学者的一点建议是:明确好自己的学习目标,掌握好自己的学习节奏!
Python的语法还算是简单,虽然也很多,一步一步来呗!
初级水平的爬虫主要重在基础,能爬着基本的网站玩玩,碰到有反爬的网站就不太行了,只能说你的爬虫之路还任重而道远。

二、中级爬虫
职业爬虫师的基本水平
【中级爬虫的技能要求】
- Ajax【能通过Ajax接口获取数据】
- Puppeteer【基于JS的爬虫框架,可直接执行JS】
- Pyppeteer【基于Puppeteer开发的python版本,需要python异步知识】
- Selenium【常见的自动化工具,支持多语言】
- Splash【JavaScript渲染服务】
- 多进程【python多任务基础】
- 多线程【python多任务基础】
- 协程【python多任务基础】
- fiddler 【抓包工具】
- mitmproxy【中间人代理工具】
- appium【自动化工具】
- adb【安卓adb工具】
- Charles【抓包工具】
这个阶段就是爬虫技能的升级了,Ajax —多线程 —多进程等是重点的学习内容;
现在很多网站的数据可能都是通过接口的形式传输的,或者即使不是接口那也是一些 JSON 的数据,然后经过 JavaScript 渲染得出来的。
如果还是用requests来爬是行不通的,所以大多数情况需要分析 Ajax,知道这些接口的调用方式之后再用程序来模拟。
但如果有些接口带着加密参数,比如token、sign的话,这时候就得去分析网站的JavaScript 逻辑。
简单粗暴的方法就是死抠代码!
找出里面的代码逻辑,不过这事费时间费精力也费脑子,它的加密做的特厉害的话,你几天几夜不睡觉研究可能也不一定解的出来。
还有一种方法相对省事一点,就是用 Puppeteer、Selenium、Splash来模拟浏览器的方式来爬取,这样就不用死抠Ajax 和一些 JavaScript 逻辑的过程,提取数据自然就简单一点。
单线程的爬虫简单是简单,但是速度慢啊!
碰上个网络不好啥的,茶都要等凉凉了,利用多进程、多线程、协程能大幅度提升爬虫的速度,相关的库有threading和multiprocessing。
不过需要注意的一点是别把人家网站搞挂了!用 aiohttp、gevent、tornado 等等,基本上你想搞多少并发就搞多少并发,速度是成倍提上了。
同时也注意一下自己的爬虫别被反爬干掉了,总之悠着点爬!
有同学学到这里的时候会发现越学越难了,看是看完了,但看了什么记不起来了,你需要反复练习。
在学习的时候多找一些有针对性的项目练练手,通过自己独立把代码敲出来来加深记忆和巩固。
三、高级爬虫
进一步提高爬取效率
【高级爬虫的技能要求】
- RabbitMQ【消息队列相关】
- Celery【消息队列相关】
- Kafka【消息队列相关】
- Redis【缓存数据库 -----》 其实mongodb也可以充当这个角色】
- Scrapy-Redis【scrapy的redis组件】
- Scrapy-Redis-BloomFilter【scrapy的布隆过滤器】
- Scrapy-Cluster 【分布式解决方案】中文资料 英文资料
- 验证码破解
- IP代理池
- 用户行为管理
- cookies池 崔神建的代理池开源代码地址
- token池
- sign
- 账号管理
能达到这个层次的话,一般赚外快是不在话下了,赚的自然不少。
这个阶段主要是两个重点:分布式爬虫和应对反爬的处理技巧。
【分布式爬虫】
分布式爬虫通俗的讲就是多台机器多个 spider 对多个 url 的同时处理问题,分布式的方式可以极大提高程序的抓取效率。
虽然听起来也很厉害,其实也是利用多线程的原理让多个爬虫同时工作,当你掌握分布式爬虫,实现大规模并发采集后,自动化数据获取会更便利。
需要掌握 Scrapy +MongoDB + Redis 这三种工具,但是分布式爬虫对电脑的CPU和网速都有一定的要求。
现在主流的 Python 分布式爬虫还是基于 Scrapy 的,对接 Scrapy-Redis、Scrapy-Redis-BloomFilter 或者用 Scrapy-Cluster 等等。
他们都是基于 Redis 来共享爬取队列的,多少会遇到一些内存的问题。
所以有些人也考虑对接到了其他的消息队列上面,比如 RabbitMQ、Kafka 等等,解决一些问题,效率也不差。
【应对反爬】
有爬虫就有反爬,什么滑块验证、实物勾选、IP检测(豆瓣和github,在检测到某一客户端频繁访问后,会直接封锁IP)、封号…各种奇葩的反爬都有。
这时候就得知道如何去应付这些常见的反爬了;
常见的反爬虫措施:
字体反爬
基于用户行为反爬虫
基于动态页面的反爬虫
IP限制
UA限制
Cookie限制
应对反爬的处理手段有:
控制IP访问次数频率,增加时间间隔
Cookie池保存与处理
用户代理池技术
字体反加密
验证码OCR处理
抓包
这里提示一点:不要去挑战反爬,搞过了大家懂得哈!
四、更高一级的爬虫
需要掌握一下这几点技能
- JS逆向【分析目标站点JS加密逻辑】
- APP逆向【xposed可在不改变原应用代码基础上植入自己的代码】
- 智能化爬虫
- 运维
【JS逆向】
这就回到了前面讲过的这个Ajax 接口会带着一些参数的这个问题。
现在随着前端技术的进步和网站反爬意识的增强,很多网站选择在前端上下功夫。
那就是在前端对一些逻辑或代码进行加密或混淆。用Selenium 等方式来爬行是行,效率还是低了,JS逆向则是更高级别的爬取技术。
但问题是难!JS逆向的修炼掉头发是少不了的!
【APP逆向】
现在越来越多的公司都选择将数据放到 App 上面,在一些兼职网站上APP数据爬取这一类的报价在几千左右,这块是酬劳比较高的。
基本的就是利用抓包工具,Charles、Fiddler等,抓到接口之后,直接拿来模拟。
想实现自动化爬取的话,安卓原生的 adb 工具也行,现在Appium 是比较主流的。
APP逆向听着好像很简单,实际跟JavaScript逆向一样的烧脑。
【智能化爬虫】
如果说我要爬取一万个新闻网站数据,要一个个写 XPath的话我估计会见不到明天的太阳,如果用智能化解析技术,在不出意外的情况下,分分钟可以搞定。
用智能化解析,不论是哪个网站,你只需要把网页的url传递给它,就可以通过算法智能识别出标题、内容、更新时间等信息,而不需要重复编写提取规则。
简而言之就是爬虫与机器学习技术相结合,使得爬虫更加智能化。
【运维】
主要体现在部署和分发、数据的存储和监控这几个方面,Kubernetes 、Prometheus 、Grafana是爬虫在运维方面用的比较多的技术。
最后我想说的是:学海无涯、学无止境,好好珍惜你的头发!
关于Python技术储备
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
一、Python学习大纲
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
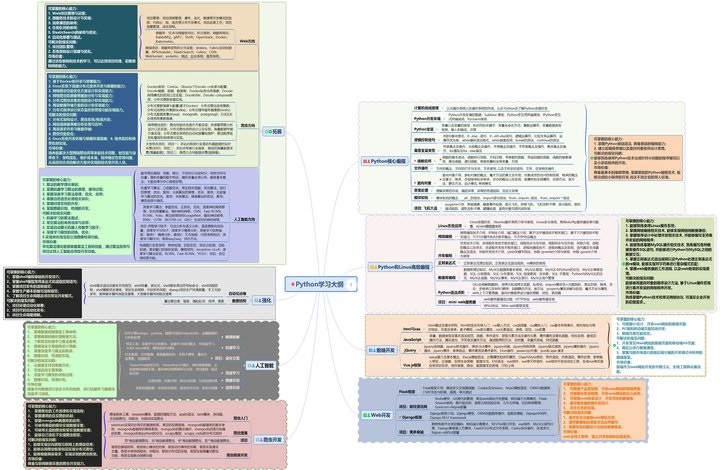
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
CSDN:Python零基础入门到实战全套学习资料,免费分享
二、Python必备开发工具
三、入门学习视频
四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
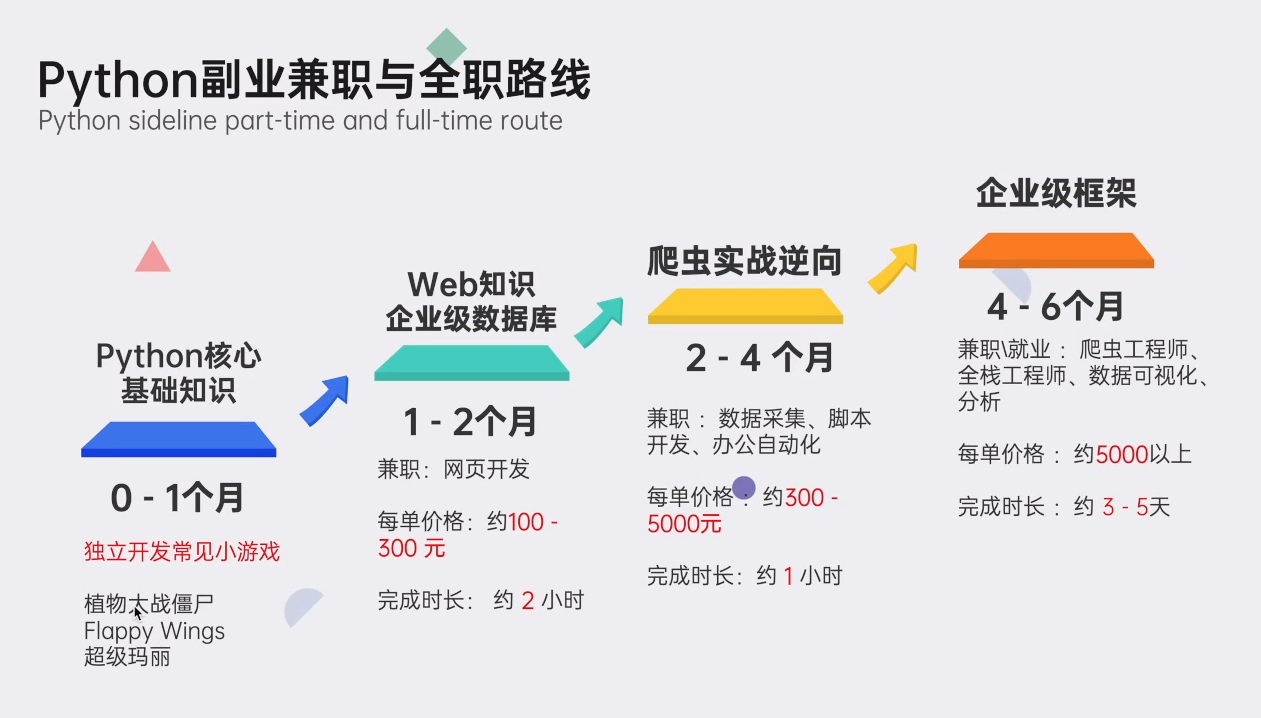
五、Python副业兼职与全职路线
六、互联网企业面试真题
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。
这份完整版的Python全套学习资料已经上传CSDN,朋友们如果需要也可以扫描下方csdn官方二维码或者点击主页和文章下方的微信卡片获取领取方式,【保证100%免费】
