大家好,今天和各位分享一下深度学习中常见的标准化方法,在 Transformer 模型中常用的 Layer Normalization,从数学公式的角度复现一下代码。
看本节前建议各位先看一下 Batch Normalization:https://blog.csdn.net/dgvv4/article/details/130567501
Layer Normalization 的论文地址如下:https://arxiv.org/pdf/1607.06450.pdf
1. 原理介绍
深层网络训练时,网络层数的增加会增加模型计算负担,同时也会导致模型变得难以训练。随着网络层数的增加,数据的分布方式也会随着层与层之间的变化而变化,这种现象被称为内部协变量偏移(Internal Convariate Shift, ICS)。这要求模型训练时必须使用较小的学习率,且需要慎重地选择权重初值。ICS 导致训练速度减慢,同时也导致使用饱和的非线性激活函数(如sigmoid,正负两边都会饱和梯度为 0)时出现梯度消失问题。
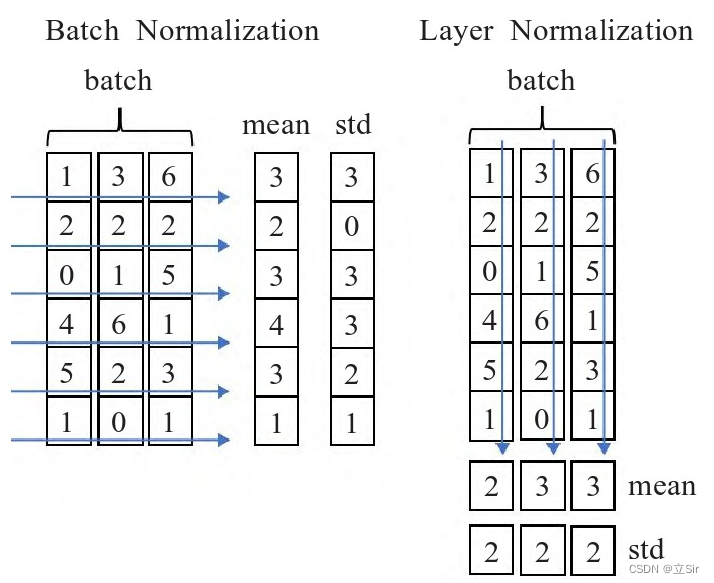
为解决内部协方差变化(ICS),思路是固定每一层输出的均值和方差,即层归一化算法(Layer Normalization,LN),层归一化算法用每个样本的均值和方差对输入进行归一化。LN 是在单个样本上操作,可以应用于小批次和 RNN。LN 和 BN 有相同的形式,只是不同的归一化方式。
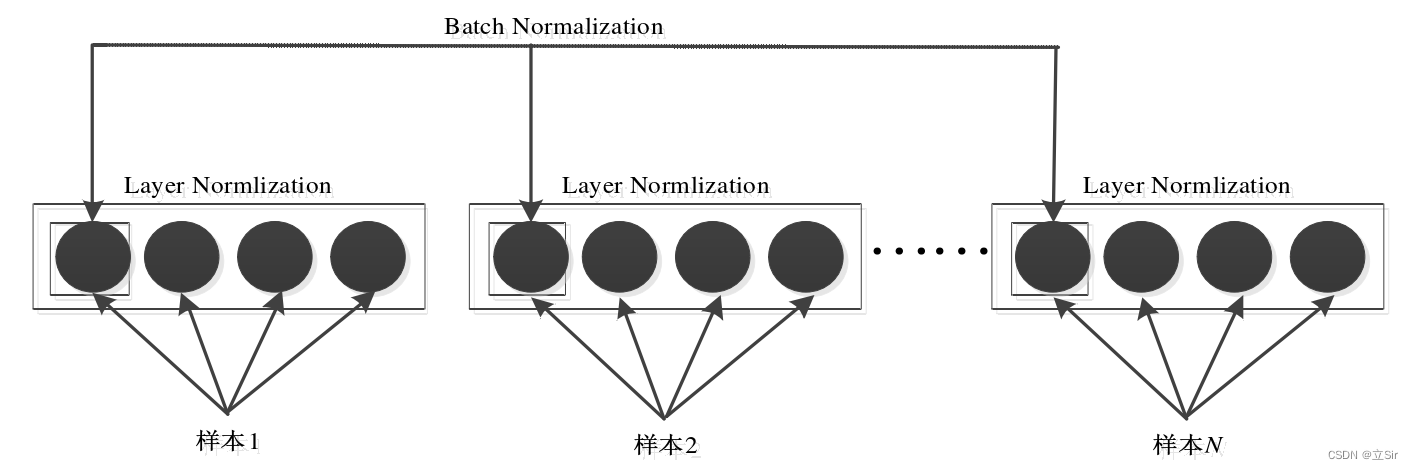
层归一化与批归一化算法的区别只在于统计值的获取方式上,下式是层归一化算法中均值和方差的计算方式,H 表示层的隐藏单元数, 代表第
层中的第
个神经元。
层归一化算法通过计算在一个训练样本上某一层所有的神经元的均值和方差来对输入进行归一化,像批归一化算法那样,同样也给每个神经元加入了增益 和偏置
来实现线性变换,这在归一化后激活函数前使用。
层归一化 LN 和批归一化 BN 不同的是,层归一化在训练和测试时执行同样的计算,由于 LN 与批次大小没有关系,LN 能够在递归神经网络的每个时间步上分别计算归一化操作所需要的均值和方差的值。实验结果表明,层归一化技术相对批归一化技术训练时间更短。
层归一化算法比较适合应用于全连接网络和递归神经网络,有学者尝试在卷积神经网络上采用层归一化算法,但是发现层归一化算法的效果没有批归一化算法好。这是因为对于全连接层,隐藏层中的全部单元对最终预测和重新定位做出相似的贡献,将所有输入缩放到一个图层效果很好。但是,类似贡献的假设在卷积神经网络不再适用,大量的隐藏单位的感受野位于图像边界附近很少被打开,因此来自同一层内其他隐藏单元的统计数据有很大不同。有学者认为认为需要进一步的研究使卷积网络中的层归一化工作取得好的效果。
总体来说,LN 较 BN 简单,它也是通过减少 ICS 来加速神经网络的训练。LN 在训练和测试时没有区别,只需要对当前隐藏层计算均值和方差而不需要保存每层的移动平均和方差用于测试且不受批次大小的限制,可以通过在线学习的方式一条一条的输入训练数据。
优点:批量较小时,效果好;适用于自然语言处理任务。
缺点:批量较大时,效果不如BN。
2. 代码展示
构造一个输入 shape=[B,C,H*W] 的张量,对每个样本在 [C, H*W] 这两个维度上做 LN

import torch
from torch import nn
class LN(nn.Module):
# 初始化
def __init__(self, normalized_shape, # 在哪个维度上做LN
eps:float = 1e-5, # 防止分母为0
elementwise_affine:bool = True): # 是否使用可学习的缩放因子和偏移因子
super(LN, self).__init__()
# 需要对哪个维度的特征做LN, torch.size查看维度
self.normalized_shape = normalized_shape # [c,w*h]
self.eps = eps
self.elementwise_affine = elementwise_affine
# 构造可训练的缩放因子和偏置
if self.elementwise_affine:
self.gain = nn.Parameter(torch.ones(normalized_shape)) # [c,w*h]
self.bias = nn.Parameter(torch.zeros(normalized_shape)) # [c,w*h]
# 前向传播
def forward(self, x: torch.Tensor): # [b,c,w*h]
# 需要做LN的维度和输入特征图对应维度的shape相同
assert self.normalized_shape == x.shape[-len(self.normalized_shape):] # [-2:]
# 需要做LN的维度索引
dims = [-(i+1) for i in range(len(self.normalized_shape))] # [b,c,w*h]维度上取[-1,-2]维度,即[c,w*h]
# 计算特征图对应维度的均值和方差
mean = x.mean(dim=dims, keepdims=True) # [b,1,1]
mean_x2 = (x**2).mean(dim=dims, keepdims=True) # [b,1,1]
var = mean_x2 - mean**2 # [b,c,1,1]
x_norm = (x-mean) / torch.sqrt(var+self.eps) # [b,c,w*h]
# 线性变换
if self.elementwise_affine:
x_norm = self.gain * x_norm + self.bias # [b,c,w*h]
return x_norm
# ------------------------------- #
# 验证
# ------------------------------- #
if __name__ == '__main__':
x = torch.linspace(0, 23, 24, dtype=torch.float32) # 构造输入层
x = x.reshape([2,3,2*2]) # [b,c,w*h]
# 实例化
ln = LN(x.shape[1:])
# 前向传播
x = ln(x)
print(x.shape)