探索视觉Transformer和卷积神经网络(CNNs)在图像分类任务中的有效性。
图像分类是计算机视觉中的关键任务,在工业、医学影像和农业等各个领域得到广泛应用。卷积神经网络(CNNs)是该领域的一项重大突破,被广泛使用。然而,随着论文《Attention is all you need》的出现,行业开始转向Transformer。Transformer在人工智能和数据科学领域取得了显著进展。例如,ChatGPT的出色性能最近就展示了Transformer的有效性。类似地,《ViT》论文提供了Vision Transformer的概述。在本文中,我将尝试比较CNNs和ViTs(Vision Transformer)在Food-101数据集上进行图像分类的性能。需要注意的是,选择使用CNNs还是ViTs取决于多个因素,包括工作类型、训练时间和计算能力,并不能直接断言Transformer比CNNs更好。本分析旨在提供对它们在这个特定任务中性能的见解。
数据集
由于有限的计算能力,我将易于访问的Food-101数据集分成了10个类别,该数据集包含大约101,000张图像。该数据集可以直接从PyTorch和TensorFlow中使用:
-
https://pytorch.org/vision/main/generated/torchvision.datasets.Food101.html
https://www.tensorflow.org/datasets/catalog/food101
https://huggingface.co/datasets/food101
如果您想下载数据集,可以使用以下链接:
-
https://data.vision.ee.ethz.ch/cvl/datasets_extra/food-101/
我将数据集分成了以下10个类别:
['samosa','pizza','red_velvet_cake', 'tacos', 'miso_soup', 'onion_rings', 'ramen', 'nachos', 'omelette', 'ice_cream']注意:类别名称的顺序与上述列表不同。
图像经过转换和调整大小为256x256,并标准化为均值为0,方差为1。在数据集的子集之后,将数据集分为训练集和验证集,其中7500张图像用于训练,2500张图像用于测试。
以下是数据集中的示例图像:

为了比较CNNs和ViTs的性能,我使用了预训练的DenseNet121架构作为CNNs的模型,以及ViT-16作为Vision Transformers的模型。选择DenseNet121是基于其密集的架构,拥有121层,使其成为与ViTs在训练时间、层数以及硬件和内存要求方面进行比较的合适候选模型。对于ViTs,我使用了ViT-Base模型,它由12层和86M个参数组成。
DenseNet121
DenseNet-121是一个非常著名的CNN架构,用于图像分类,它是DenseNet模型系列的一部分,旨在解决深度神经网络中可能出现的梯度消失问题。它有121个层,使用了卷积层、池化层和全连接层的组合。其中有4个稠密块,每个稠密块由多个带有BatchNorm和ReLU激活的卷积层组成。在稠密块之间,有过渡层,使用池化操作来减小特征图的空间维度。以下是DenseNet的架构示意图:
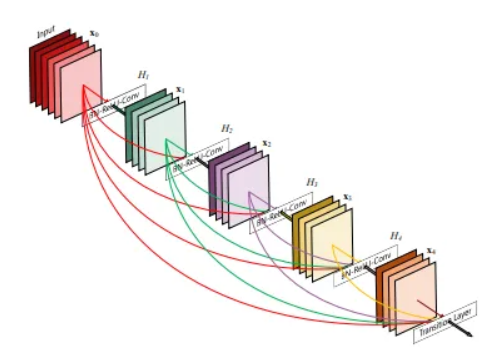
DenseNet架构
预训练模型使用了PyTorch提供的模型。模型经过了10个epochs的训练。
# Constants
NUM_CLASSES = 10
LEARNING_RATE = 0.001
# Model
densenet = torch.hub.load('pytorch/vision:v0.10.0', 'densenet121', pretrained=True)
for param in densenet.parameters():
param.requires_grad = False
# Change classifier layer
densenet.classifier = nn.Linear(1024,NUM_CLASSES)
# Loss, Optimizer
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(densenet.classifier.parameters(), lr=LEARNING_RATE)准确率 vs Epochs和损失 vs Epochs的图表:
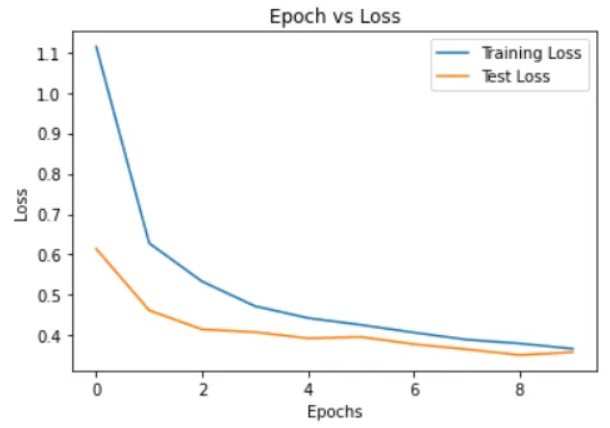
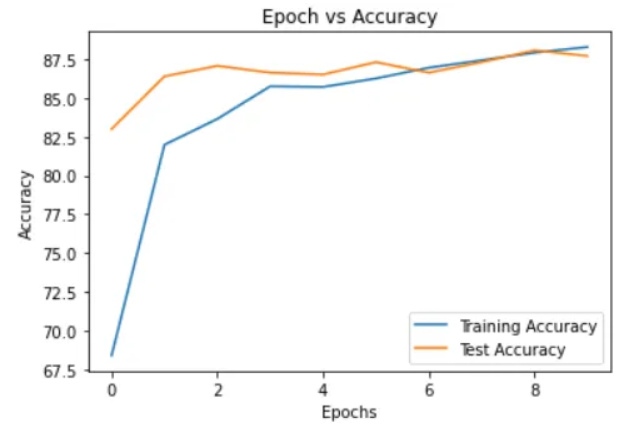
在最后一个epoch中,训练损失为0.3671,测试损失为0.3586,训练准确率为88.29%,测试准确率为87.72%。
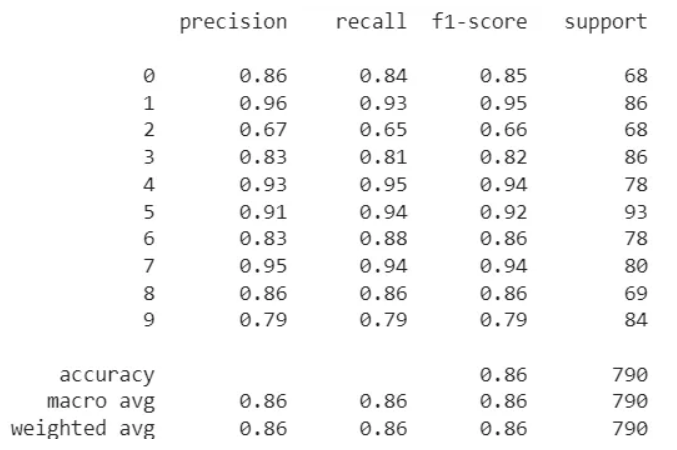
分类别结果:
ViT-16
ViT-16是Vision Transformer(ViT)的一种变体,由于在各种图像分类基准测试中能够达到最先进的结果,它在ViT论文之后变得非常受欢迎。ViT-16由一个Transformer编码器和一个用于分类的多层感知机(MLP)组成。Transformer编码器由16个相同的Transformer层组成,每个层包含一个自注意机制和一个前馈神经网络。网络的输入是扁平化的图像块序列,通过将输入图像分成不重叠的块,并将每个块扁平化为向量而获得。
每个Transformer层中的自注意机制允许网络在进行预测时专注于图像的不同部分。特别地,它计算输入序列中每对位置的注意权重,使得网络能够根据它们与当前分类任务的相关性来关注不同的图像块。每个Transformer层中的前馈神经网络然后对自注意机制的输出进行非线性变换。
在Transformer编码器之后,输出被传递到MLP分类器中,该分类器由两个具有ReLU激活的全连接层和一个用于分类的softmax输出层组成。MLP将最终Transformer层的输出作为输入,并将其映射到输出类别上的概率分布。
以下是ViT的架构示意图:
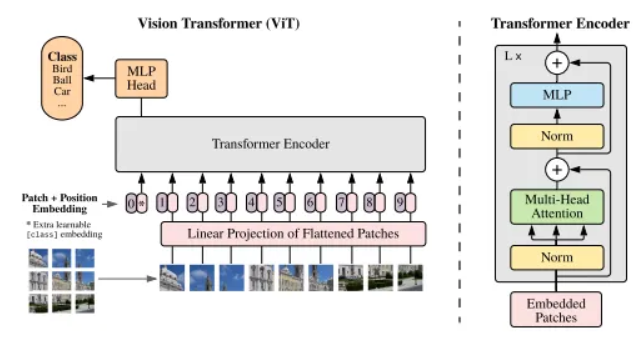
Vision Transformer架构
在将图像输入Transformer编码器模型之前,我们需要首先将输入图像分割成块,然后扁平化这些块。下面是图像被分割成块的示例:

将样本输入图像分割成块
我尝试了从头构建Transformer模型,但性能并不好。然后我尝试了迁移学习,使用了预训练的ViT-16模型和PyTorch提供的默认权重。我还对适用于ViT的图像应用了相应的转换操作。
# Default weights
pretrained_weights = torchvision.models.ViT_B_16_Weights.DEFAULT
# Model
vit = vit_b_16(weights=pretrained_weights).to(device)
for parameter in vit.parameters():
parameter.requires_grad=False
# Change last layer
vit.heads = nn.Linear(in_features=768, out_features=10)
# Auto Transforms
vit_transforms = pretrained_weights.transforms()准确率 vs Epochs和损失 vs Epochs的图表:
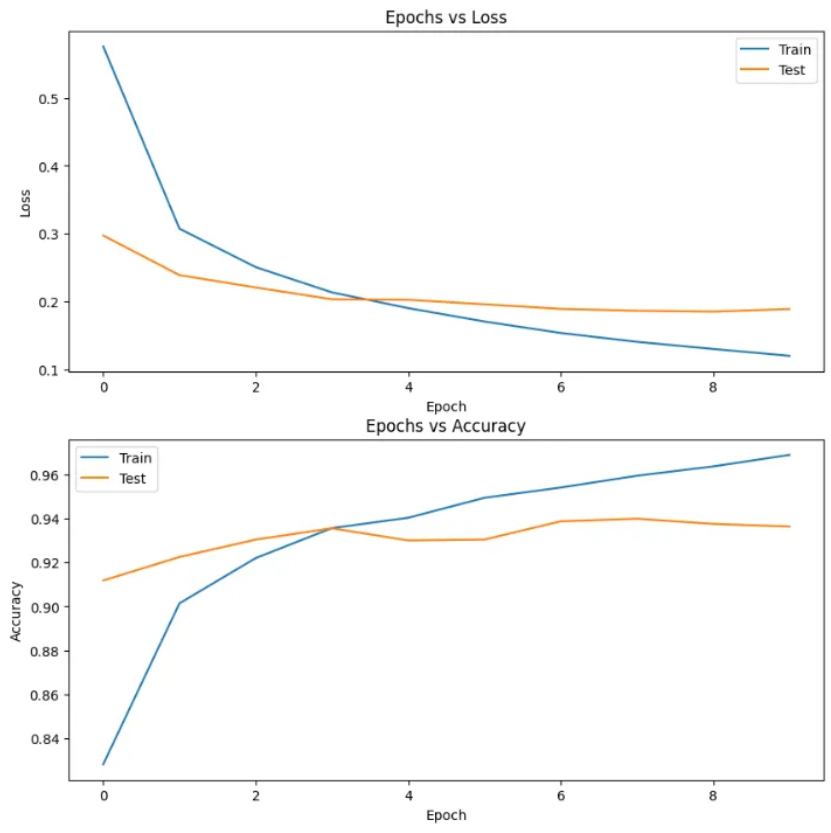
在最后一个epoch中,训练损失为0.1203,测试损失为0.1893,训练准确率为96.89%,测试准确率为93.63%。
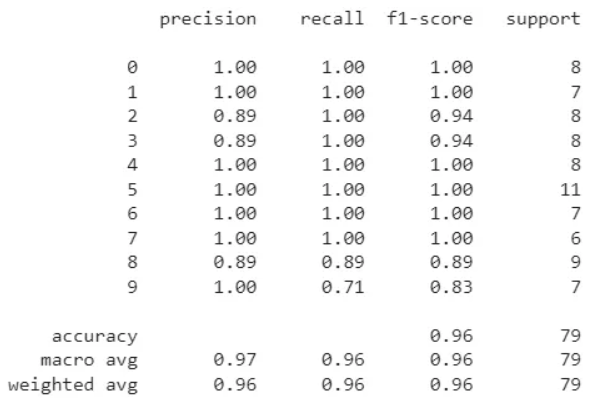
分类别的结果:
预测结果:
以下是对于ViT-16模型的一些使用未见过数据的预测结果 —

类别:5 名称:比萨
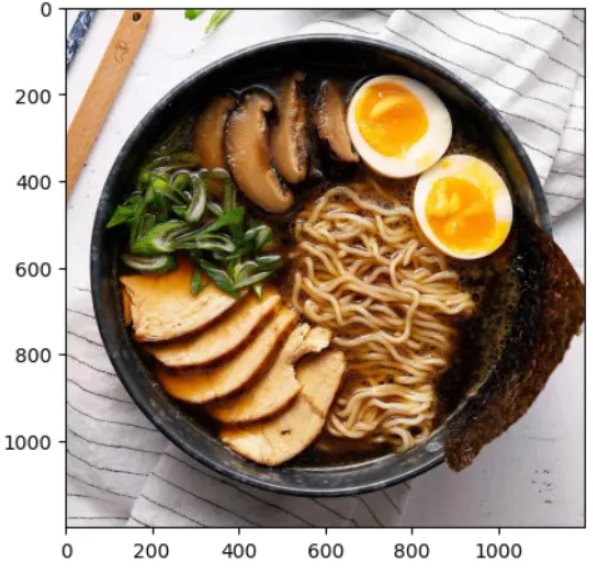
类别:6 名称:拉面

类别:8 名称:萨莫萨饼
注意:类别名称的顺序与上述列表不同
在大多数情况下,ViT-16能够正确分类未见过的数据。
结论
在这个特定任务中,ViT-16在图像分类方面的性能优于DenseNet121。准确率和图表曲线也显示了两者之间的显著差异。分类报告显示,ViT的f1-score相比DenseNet更好。
然而,需要注意的是,虽然Vision Transformer在某些情况下可能优于CNN,但不能一概而论地认为它们比CNN架构更好。每个架构的性能取决于各种因素,如使用情况、数据规模、训练时间、参数调整、硬件的内存和计算能力等。
· END ·
HAPPY LIFE
