一.背景介绍
随着ChatGPT等大型语言模型(LLM)的发布,应用开发者越来越倾向于将LLM集成到自己的应用中。然而,由于LLM生成结果的不确定性和不准确性,目前还无法仅依靠LLM提供智能化服务。因此,LangChain应运而生,其主要目标是将LLM与开发者现有的知识和系统相结合,以提供更智能化的服务。
借用一段话来总体阐述一下LangChain,有人问过 Harrison:为什么开发者要用 LangChain 而不是直接使用 OpenAI 或者 Hugging Face 上的模型?
Harrison 的回答是:Hugging Face、OpenAI、Cohere 可以提供底座模型和 API,但是在产品中集成和使用它们仍然需要大量的工作,说白了LangChain是帮助人们更容易地构建 LLM 支持的应用。
接下来就来说说他为啥被称做为应用利器,在说他之前先来阐述一下LLM当前模型本身的局限性。
二.构建GPT应用远远不是调用API
-
它只有“脑子”没有“手臂”,无法在外部世界行动,不论是搜索网页、调用 API 还是查找数据库,这些能力都无法被OpenAI的 API 提供;说白了只使用openAI不是商业应用,不能产品化。
-
甚至它的“脑子”也不完美,OpenAI 的训练数据截止至 2021 年,并且没有任何企业和个人的私有数据,这让模型只能根据自己的“记忆”回答问题,并且经常给出与事实相悖的答案。一个解决方法是在 Prompt 中将知识告诉模型,但是这往往受限于 token 数量,在 GPT-4 之前一般是 4000 个字的限制。
作为用户、使用者我们想GPT拥有以下能力:
-
拥有创作能力,比如让他写一篇文章、写一首诗,
-
希望他有Context(上下文语义信息)且能接入自定义、私有化数据。
三.友好且优美的库-LangChain
LangChain优势
-
它非常模块化,还通过 Chain、Agent、Memory 对 LLM 的抽象帮助开发者提高了构建较复杂逻辑应用的效率;而且每个模块有很好的可组合性,有点像“为 LLM 提供了本 SOP”,能实现 LLM 与其他工具的组合、Chain 与 Chain 的嵌套等逻辑;
-
它一站式集成了所有工具,从各种非结构化数据的预处理、不同的 LLM、中间的向量和图数据库和最后的模型部署,贡献者都帮 LangChain 跟各种工具完成了迅速、全面的集成。
-
它没有太多技术壁垒,只是替大家省下来了码代码的时间
那么他又是如何解决上述"脑子"和"手臂"的问题呢?
“脑子”的问题目前已经有了成熟的解决方案来绕开 token 数量的限制。通常的方法借鉴了 Map Reduce 的思想,涉及到给文档切片、使用 Embedding 引擎、向量数据库和语义搜索。关于“手臂”的探索也早就有很多,OpenAI 的 WebGPT 给模型注入了使用网页信息的能力,Adept训练的 ACT-1 则能自己去网站和使用 Excel、Salesforce 等软件,PaLM 的 SayCan 和 PaLM-E 尝试让 LLM 和机器人结合,Meta 的 Toolformer 探索让 LLM 自行调用 API,普林斯顿的 Shunyu Yao 做出的 ReAct 工作通过结合思维链 prompting 和这种“手臂”的理念让 LLM 能够搜索和使用维基百科的信息。
有了这些工作,在开源模型或者 API 之上,开发者们终于可以做有相对复杂步骤和业务逻辑的 AI 应用。而 LangChain 是一个开源的 Python 库(后续又推出了 Typescript 版本),封装好了大量的相关逻辑和代码实现,开发者们可以直接调用,大大加速了构建一个应用的速度。
如果没有 LangChain,这些探索可能首先将被局限在 Adept、Cohere 等有充足产研资源的公司身上,或仅仅停留在论文层面。然后随着时间推移,开发者需要闷头码个几周来复现这些逻辑。但是有了 LangChain,做一个基于公司内部文档的问答机器人通常只需要两天,而直接 fork 别人基于 LangChain 的代码构建个人的 Notion 问答机器人则只需要几个小时。
我们举个例子来具体看下LangChain是如何工作的。
四.为一本 300 页的书构建问答机器人
我自己知道的第一个使用 Map Reduce 思想的应用是 Pete Hunt 的 summarize.tech,一个基于 GPT-3 的 YouTube 视频总结器。不是一股脑将 YouTube 视频的文稿做总结,而是先将它分成很多的文本块(chunk),对每个块分别总结,最后给用户交付的是“摘要的摘要”,过程中消耗的 token 数能节省很多。
事实上,这不光能让成本降低,还可以解决单个 Prompt 中 token 数量限制的问题。随着 12 月 OpenAI 新的 Embedding 引擎推出和 ChatGPT 让更多 AI 应用开发者入场,这种做法目前已经成为解决 Context 问题的绝对主流做法。
下面我们以一个 300 页的书的问答机器人为例,给读者展示下 LangChain 如何封装这个过程。
1. 哪怕是 GPT 的 32k token 限制,300 页的书也绝对超过了,因此我们需要引入上文这种 Map Reduce 的做法;
2. LangChain 提供了许多 PDF loader 来帮助上传 PDF,然后也提供许多类型的 splitter 让你可以将长文本切成数百个文本块,并尽量避免这么切可能导致的语义缺失;
3. 有了文本块之后,你可以调用 OpenAI 的 Embedding 引擎将它们分别变成 Embeddings,即一些大的向量;
4. 你可以在本地存储这些向量或者使用 Pinecone 这样的云向量数据库存储它们;
5. 调用 LangChain 的 QA Chain 就可以进行问答了,这背后发生的是 —— 输入的问题也被 Embedding 引擎变成向量,然后使用 Pincone 的向量搜索引擎找到语义最接近的一些 Embedding,将它们再拼接在一起作为答案返回。
LangChain 在过程中提供了完整的集成,从 OpenAI 的 LLM 本身、Embedding 引擎到 Pinecone 数据库,并且将整体的交互逻辑进行了封装。如果你想用别人基于 LangChain 的代码 fork 这个 PDF 问答机器人,基本只需要换一下 OpenAI API key、Pincone API key 和用的这份 PDF。
是不是很方便快捷的存在,他的快捷标签远远不止这些,以下摘要来自LangChain -Github官方wiki。
五.拼接好 LLM 的大脑和四肢
基础功能

让 LLM 拥有上下文和行动能力
目前基于 LangChain 开发的第一用例是建立使用私有数据的问答机器人,而大多数开发者想到要导入私有数据,第一选择就是基于 LangChain 来做。可以说 LangChain 是目前将上下文信息注入 LLM 的重要基础设施。Harrison 在去年 11 月为 LangChain 总结的 4 大价值主张支柱也都围绕这一点,体现出了很优美的模块化和可组合性特点:
LLM 和 Prompts
如果是一个简单的应用,比如写诗机器人,或者有 token 数量限制的总结器,开发者完全可以只依赖 Prompt。此外,这也是更复杂的 Chain 和 Agent 的基础。LangChain 在这一层让切换底层使用的 LLM、管理 Prompt、优化 Prompt 变得非常容易。

此处最基础的能力是 Prompt Template。一个 Prompt 通常由 Instructions、Context、Input Data(比如输入的问题)和 Output Indicator(通常是对输出数据格式的约定)。使用 LangChain 的 Prompt Template 很好地定义各个部分,同时将 Input Data 留作动态输入项。
围绕 Prompt,LangChain 还有很多非常有意思的小功能,比如 0.0.9 版本上的两个能力:Dyanamic Prompts 可以检查 Prompt 的长度,然后调整 few-shots 给出的示例数量,另一个Example Generation 可以检查 Prompt 里 token 数量还有剩余的话就再多生成些示例。
Chain
当一个应用稍微复杂点,单纯依赖 Prompting 已经不够了,这时候需要将 LLM 与其他信息源或者 LLM 给连接起来,比如调用搜索 API 或者是外部的数据库等。LangChain 在这一层提供了与大量常用工具的集成(比如上文的 Pincone)、常见的端到端的 Chain。

今天 LangChain 封装的各种 Chain 已经非常强劲,一开始 300 页 PDF 的案例中用到的是它的 QA Chain,我再举一些足够简单、易于理解的 Chain 作为例子:
它的第一个 Chain 可以让完全没有技术背景的读者也对 Chain 有个概念 —— 这个 Chain 叫做 Self Ask with Search,实现了 OpenAI API 和 SerpApi(Google 搜索 API)的联动,让 LLM 一步步问出了美国网球公开赛冠军的故乡。

还有一个很直观的 Chain 是 API chain,可以让 LLM 查询 API 并以自然语言回答问题,比如下面这个示例中 LLM 使用了 Open-Mateo(一个开源的天气查询 API)来获取旧金山当天的降雨量:

Agent
Agent 封装的逻辑和赋予 LLM 的“使命”比 Chain 要更复杂。在 Chain 里,数据的来源和流动方式相对固定。而在Agent 里,LLM 可以自己决定采用什么样的行动、使用哪些工具,这些工具可以是搜索引擎、各类数据库、任意的输入或输出的字符串,甚至是另一个 LLM、Chain 和 Agent。

所以 Agent 究竟能干什么呢?下面是我最喜欢的一个例子。
众所周知,ChatGPT 能听懂你的几乎所有问题,但是老胡编乱造。另外有一个叫 Wolfram Alpha 的科学搜索引擎,拥有天文地理的各类知识和事实,只要能听懂你提问就绝不会出错,可惜之前只能用官方给的语法搜索,非常难用。所以它的创始人 Wolfram 老师一直在鼓吹 ChatGPT 与 Wolfram Alpha 结合的威力。
23 年 1 月 11 日,LangChain 贡献者 Nicolas 完成了 ChatGPT 和 Wolfram Alpha 的集成。Agent 可以像下图一样运行,自行决定是否需要工具和 Wolfram Alpha,在回答“从芝加哥到东京的距离”时选择了调用它,在回答“Wolfram 是否比 GPT-3 好”时选择不调用它,自行回答。

Memory
LangChain 在上述的 3 层都做得很好,但是在 Memory 上一直相对薄弱,Harrison 自己不懂,一直由非全职的贡献者 Sam Whitmore 贡献相关代码,他也承认 LangChain 在这块儿有些技术债。
对于不了解 Memory 是什么的读者,你在 ChatGPT 每个聊天 session 都会出现在入口的左侧,OpenAI 会贴心地为你生成小标题,在每个 session 的问答里 ChatGPT 都能记住这个对话的上文(不过也是因为每次请求都会把之前的问答 token 都传给 OpenAI),但是新的对话 session 中的 ChatGPT 一定不记得之前 session 中的信息。LangChain 中的 Chain 在前几个月一直也都是这种无状态的,但是通常开发 App 时开发者希望 LLM 能记住之前的交互。
在前 ChatGPT 时代,LangChain 不久还是实现了 Memory 的概念,在不同的 Query 间传递上下文,实现的方法跟开始的总结 300 页 PDF 类似:
•总体而言的方法是记录之前的对话内容,将其放到 Prompt 的 Context 里;
•记录有很多的 tricks,比如直接传递上下文,或者对之前的对话内容进行总结,然后将总结放 Prompt 里。
在 Scale AI 今年的 Hackthon 决赛上,Sam 又为 LangChain 做了 Entity Memory 的能力,可以为 LLM 和用户聊天时 Entity 提供长期记忆上下文的能力。
在 ChatGPT 发布后,LangChain 又优化了 Memory 模块,允许返回 List[ChatMessage],将逻辑单元拆分为了更小的组件,更符合模块化的思想。
六.一站式粘合所有工具
全过程一站式的集成
从非结构化数据的预处理到不同模型结果的评估,开发者所需要的工具和库 LangChain 基本都有现成的集成。
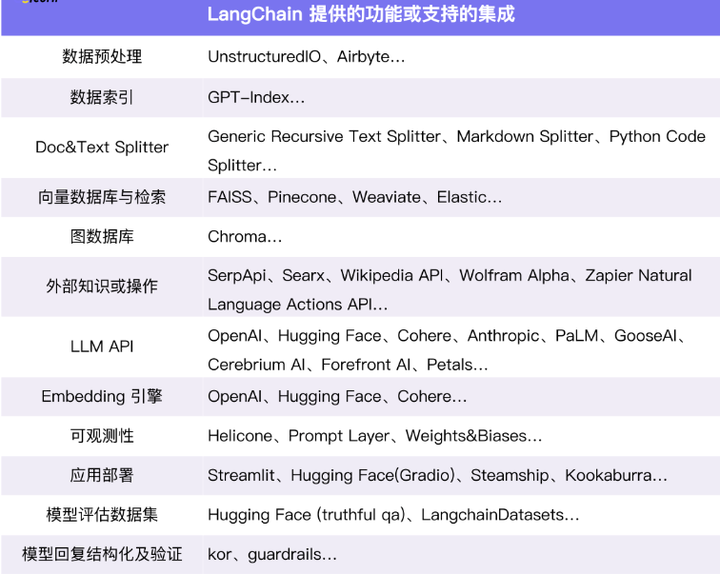
LLM自由切换
LangChain 作为 Universal Layer 在 LLM 身上包了一层,让用户可以更自由地在多个 LLM、Embedding 引擎等之间切换,以避免单点风险和降低成本。
这里的逻辑和 Universal API 很像 —— 每个 LLM 提供者的 API 数据结构不同,但是 LangChain 包了一层后做了遍 Data Normalization。从想象力的角度看,LangChain 有一定的编排价值,如果 Model as a Service 和多模型是未来,那么 LangChain 的价值会比想象中厚一些。
以上就是全部内容了。