一、初衷
深度学习从2015年发展到现在,模型也在不断地迭代优化;
现在许多新的模型往往是站在巨人的肩膀上,在这里想记录下baseline模型发展的一个历程,以及不断更新的内容;不会将模型的每一层剖开来将,而是将关键的创新点进行重点记录,当然也包括了一些个人理解和思考,如果有不对或者不全的地方欢迎沟通,也希望在以后工作中不断完善对模型的理解;
BaseLine指的是什么呢?
通常我们又称BaseLine模型为分类模型,往往入门都是用它来实现一个分类任务。但这些模型不仅仅出现在分类任务中,而是整个CV领域的基石。在后面接触到的检测、分割、关键点回归等任务,都离不开一个关键的步骤——特征提取;这个关键步骤都是基于特征提取后的特征图进行后续的操作,BaseLine模型在这些任务中都是必不可少的,并且选取不同的模型,对整个任务的性能也有很大影响(当然不排除自己设计模型进行特征提取)
二、AlexNet
意义:属于开篇鼻祖的模型,拉开了卷积网络统治计算机视觉的序幕;
这个模型比较简单,直接看一下网络结构图:
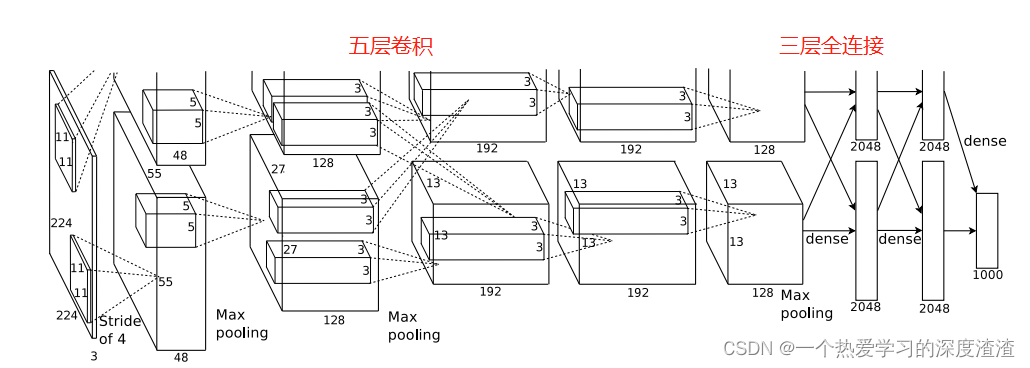
这个网络有一个特点,在于在两个GPU上并行训练并且最后融合,是为了使用更多的训练资源,这种网络结构的设定的思想在新的网络中也有涉及,这里可以先Mark一下;
重点概念
一、ReLU激活函数的提出,有什么优势?
首先ReLU和Sigmoid等激活函数都是非线性激活函数,因为如果用线性激活函数,那么多层隐藏层的神经网络和单层是没有区别的,也就失去了卷积网络的特点;
这里来对比下Sigmoid函数和ReLU函数,首先看一下公式,这是一定要记住的;
Sigmoid计算公式:
y = 1 1 + e − x y=\frac{1}{1+e^{-x}} y=1+e−x1
梯度公式:
y ′ = y ∗ ( 1 − y ) y^{\prime}=y *(1-y) y′=y∗(1−y)
ReLu计算公式:
y = m a x ( 0 , x ) y = max(0, x) y=max(0,x)
梯度公式:
y ′ = { 1 , x > 0 undefined, x = 0 0 , x < 0 y^{\prime}=\left\{\begin{array}{cc} 1, & x>0 \\ \text { undefined, } & x=0 \\ 0, & x<0 \end{array}\right. y′=⎩⎨⎧1, undefined, 0,x>0x=0x<0
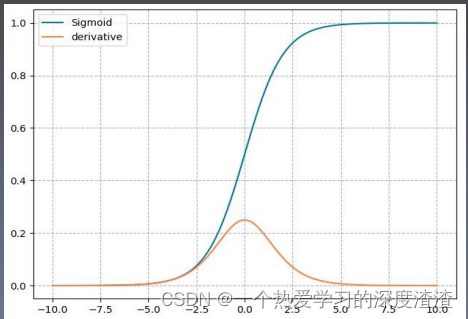
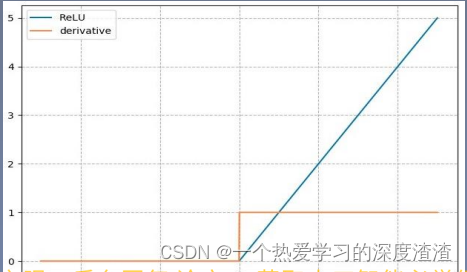
从上面两张图可以看出,sigmoid函数在x值取很大或很小的时候,梯度几乎为0,会造成梯度消失;
ReLU有以下有点:
1、使网络训练更快(因为计算简单且梯度在大于0处逐渐增大)
2、防止梯度消失;
3、使得网络具有稀疏性(当x为负数,梯度为0,神经元不参与训练)
思考:
ReLU在小于0处,梯度也为0,这个是不是有可以改进的空间?
Leaky relu是对ReLU的一个改进,解决了上述的问题;
计算公式:
y = m a x ( 0.01 x , x ) y = max(0.01x, x) y=max(0.01x,x)
二、卷积层输出大小的计算?
我们传入卷积的参数有:输入图片大小I * I、卷积核大小K * K、步长S、填充Padding为P
输出大小计算公式:
O = ( I − K + 2 P ) / S + 1 O = (I - K+2P) / S +1 O=(I−K+2P)/S+1
三、Dropout的概念
对神经元进行随机失活,作用是减少过拟合,提高网络的泛化能力;
详细一些的讲解可以参考这篇文章:https://zhuanlan.zhihu.com/p/77609689
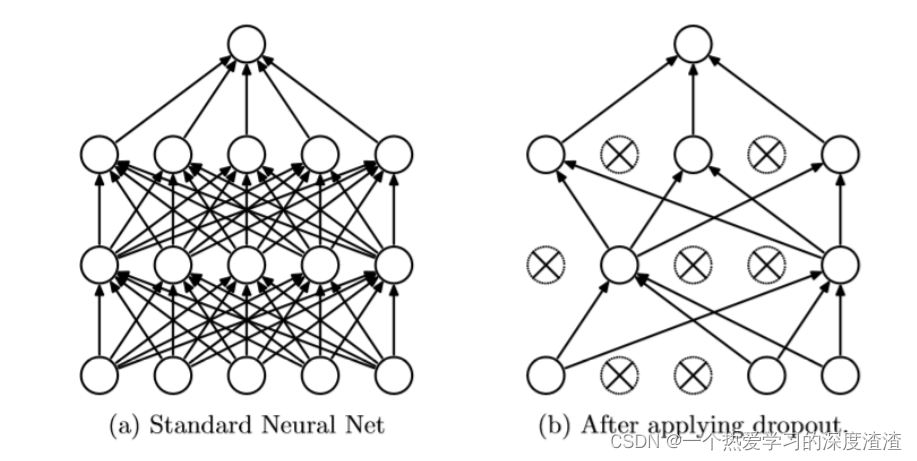
注意:测试时需要将神经元的输出乘以失活的比例p;
三、VGG
意义:VGG至今还不断被其他网络作为骨干结构,它的提出开启了小卷积核、深度卷积的时代;
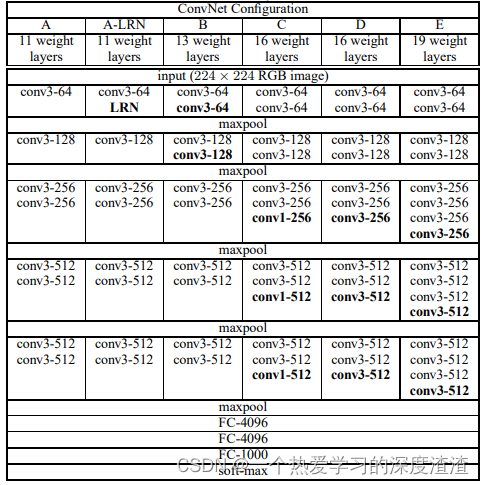
该图为论文中给出VGG不断演变的过程,目前主要使用的是VGG16【D】和VGG19【E】;
重点概念
一、堆叠3x3卷积的一个作用?为什么小卷积核比大卷积核好?
实际上卷积的作用就是不断提取输入图像特征,在AlexNet中采用大的卷积核,这样子下采样的速度比较快,模型的层数也堆叠的不多。在VGG中使用3x3卷积核后,通常为2倍的概率进行下采样,有利于加深网络的层数;
优点:
1、增大感受野
2个3 * 3堆叠等价于1个5 * 5,两者的感受野相同;
2、减少计算量
三个3x3卷积核需要的参数量为27C
一个7x7卷积核需要的参数量为49C
二者的感受野相同,但用3x3卷积核参数量减少了44%
拓展思考:**1x1卷积核有什么作用呢?**在下一个网络会进行讲解;
二、怎样可以将网络设置成任意尺寸输入?
当模型中存在全连接层的时候,模型的输入是固定的,能否将全连接层进行替换呢?
将最后的全连接层替换成卷积层,如下图所示:
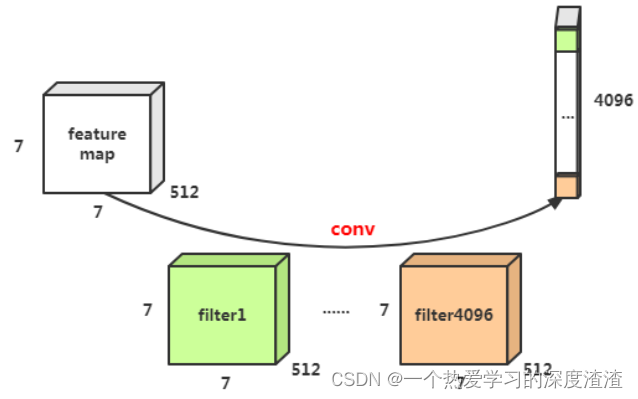
这里的思想很重要,随着网络的发展,全连接层由于其庞大的计算量和对输入尺寸的限制,慢慢被卷积取代;
当然最重要的在于,在后续的FCN中,也是采用全卷积的形式,得以实现编解码的网络结构;
四、GoogleNet
这里GoogleNet又分为V1、V2、V3、V4四个版本,由于其在如今并不常用,这里就主要介绍其关键思想;
这里就不分版本了,主要讲解一下重要的概念,GoogleNet重要的在其一些trick;
首先需要了解的就是Inception模块
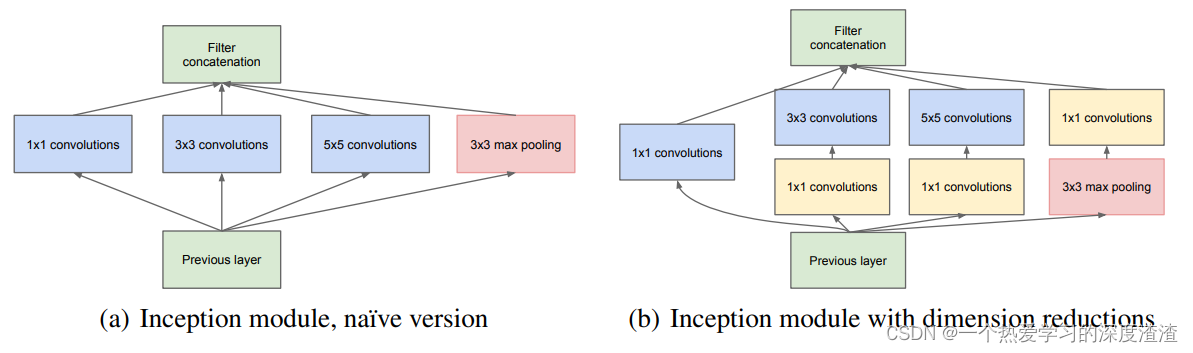
特点:提高计算资源利用率,增加网络深度和宽度的同时,参数少量增加;
重点概念
一、1x1卷积的作用?
这个概念属于很重要的一个概念,在Inception模块中有使用,并且在ResNet中也有使用;
特点:只改变输出的通道数,不改变输出的宽度和高度;
作用:
1、起到升维或降维的作用,可以用来压缩厚度,可以用于最后的分类输出;
2、增加非线性,可以保持通道数不变加上一层1x1卷积;
3、减少计算量,将通道数减少后,计算量自然就减少了;
二、辅助损失是什么概念?
这个概念在后续的网络中并不常见,主要是为了提取中间层信息用于分类;
实现:在中间层输出时强制计算一个损失,与最后输出的损失进行加权;
个人理解:
这个trick其实没有很大必要,在后续网络中想利用中间层的信息,可以采用特征融合的方法,用concat或者add的方式,比起辅助损失作用更大;
三、稀疏矩阵的一个定义?
我们会经常听到一个概念,使得网络具有稀疏性,那么稀疏性是怎样的呢,又有什么优势?
稀疏矩阵:
矩阵中数值为0的元素数量远远多于非0元素数量,且无规律;
稠密矩阵:
矩阵中数值非0的元素数量远远多于0元素的数量,且无规律;
优点:稀疏矩阵可以分解成密集矩阵计算来加快收敛速度,简单总结就是不仅能降低内存还能提高训练速度;
四、BN层的作用是什么?
参考文章:https://blog.csdn.net/weixin_42080490/article/details/108849715
全称为Batch Normalization,主要是为了解决随着网络加深,训练越来越慢,收敛越来越慢的问题;
问题出现的原因:
随着网络层数的堆叠,每一层参数的更新会导致会导致上层的输入数据分布发生变化,这样使得高层输入分布变化会异常剧烈,使得高层要不断去重新适应底层的参数更新;这种情况也称为内部协变量偏移,也就是ICS;
在神经网络训练过程中使得每一层神经网络的输入保持相同的分布;
实际用法:将数据变化到均值为0标准差为1的标准正态分布,使得激活函数的输入值落在敏感区域,网络的输出就不会很大,可以得到较大的梯度,避免了梯度消失问题的产生,也起到加快训练的作用;
主要作用:
1、加快网络的训练和收敛速度(这里GoogleNetV2版本中期相比上个版本速度快了10倍)
2、控制梯度爆炸防止梯度消失;
3、防止过拟合;
注意:
使用了BN层后,我们就可以抛弃dropout这个操作,并且也不用对权值的初始化过于关注了,还可以用更大的学习率来加速模型收敛,好处真的很多,基本上每个网络都会加上这样的结构;
五、卷积分解是什么策略?
1、大卷积核分解成小卷积核堆叠;
这里也就是之前介绍的用两个3x3卷积代替一个5x5卷积;
2、分解为非对称卷积;
也就是将一个nxn的卷积分解成一个1xn和一个nx1卷积的堆叠;
这里主要也是为了减少网络参数,但这个策略只在网络特征图分辨率较小时才有用,所以在后续的网络中也不常见
六、标签平滑策略是什么?
问题:
传统的One-hot编码存在一个问题,也就是过度自信,容易导致过拟合;
解决方法:
提出标签平滑,将One-hot编码中置信度为1的那一项进行衰减,避免过度自信,将衰减的那部分confience平均分到每一个类别中;
例子:
原来标签值为(0,1,0,0) ——>>(0.00025,0.99925,0.00025,0.00025)
再传入损失函数中即可;
五、ResNet
ResNet作为和VGG同为工业界最受欢迎的卷积神经网络结构,其重要模块如下图所示:
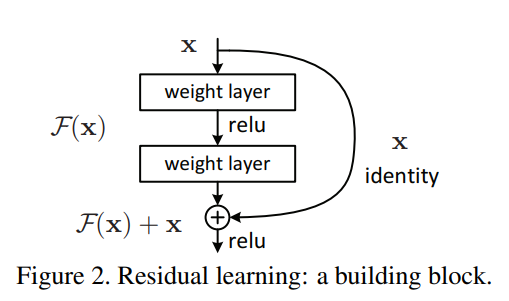
其意义在于推动了网络往更深的层次发展,首次成功训练出成百上千层的网络;
重点概念
一、上述结构称为什么?起到什么作用?
参考文章:https://zhuanlan.zhihu.com/p/80226180
上图中的结构称为残差结构(Residual learning)
加深网络层会出现什么问题?
1、容易产生梯度消失或者梯度爆炸(可以被BN层和正则化加入解决)
2、网络退化问题:网络的表现随层数的增加逐渐饱和,然后迅速下降(网络优化困难)
残差结构也就是一个网络恒等映射的过程,具体公式如下:
F ( x ) = W 2 ∗ R e L U ( W 1 ∗ x ) F(x) = W2*ReLU(W1*x) F(x)=W2∗ReLU(W1∗x)
H ( x ) = F ( x ) + x = W 2 ∗ R e L U ( W 1 ∗ x ) + x H(x) = F(x) + x = W2*ReLU(W1*x) + x H(x)=F(x)+x=W2∗ReLU(W1∗x)+x
当F(x)为0时,H(x)= x,因此实现了网络的恒等映射;
作用:
1、有利于梯度传播,使得梯度不会出现消失或者爆炸,网络能堆叠到上千层;
2、引入了跳连结构,起到了引用上层信息的作用,也有一种集成学习的概念在其中;
当然,为了减少计算量,还引入之前提高的1x1卷积进行升降维:
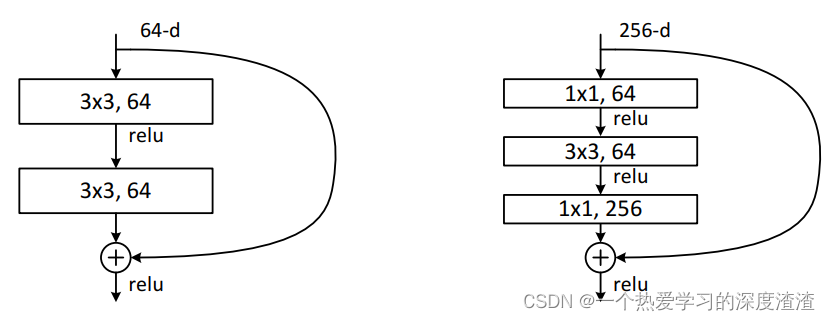
六、ResNeXt
主要思想:基于ResNet网络,引入了Inception中聚合变换的概念;
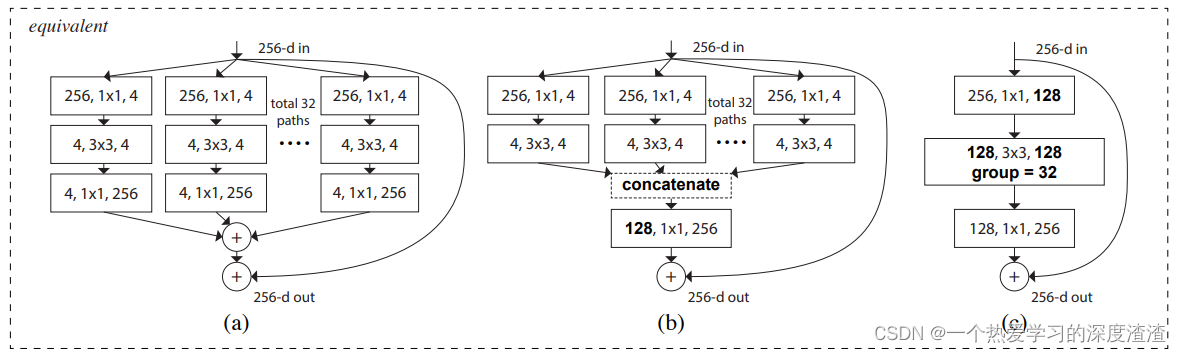
重点概念
一、分组卷积是什么?有什么作用?
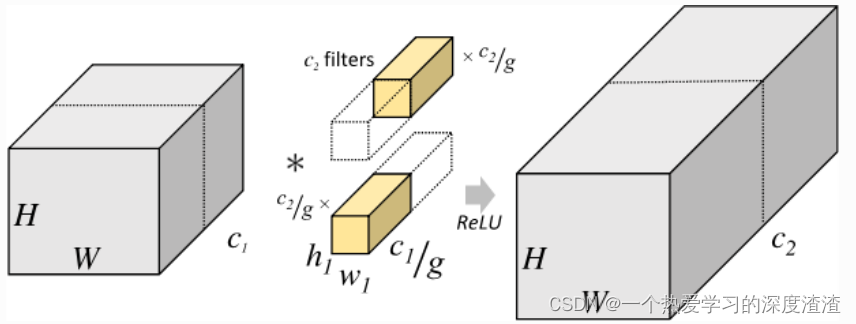
如上图的结构,就是分组卷积的结构,这个思想是源于AlexNet中将卷积拆分到两个GPU上这个思想;
实现策略:将输入的特征图分成C组,每组内部进行正常卷积,然后按通道拼接得到输出特征图;
作用:
1、使用更少的参数得到相同的特征图;
2、让网络学习到更不同的特征,获取更丰富的信息;
注意:分组卷积虽然和深度可分离卷积相似,但并不相同,之后再进行介绍;
七、DenseNet
意义:对卷积网络中的short path和feature resuse再思考,达到更好的效果;
整个DenseNet网络分成三个部分,也就是头部卷积、Dense Block堆叠,全连接输出分类概率;
头部卷积也就是用卷积加池化的操作来控制输出维度,本次主要讲解Dense这个结构;

重点概念
一、什么是稠密连接?有什么优势?
DenseNet中最重要的结构如上面图展示的,称之为稠密连接;
主要是在一个Block中,每一层输入都来自于它前面所有层的特征图,每一层的输出均会直接连接到它后面所有层的输入;
作用:
1、用较少参数获得更多特征,减少了参数量,DenseNet仅仅用了ResNet1/3的参数就达到了相近的准确率;
2、低级特征复用,特征更加丰富;
3、更强的梯度流动,跳连结构更多,梯度更容易向前传播;
注意:
稠密连接实际上在小数据上起到正则化的作用,有一种说法是稠密连接更适合小数据集;
缺点:
DenseNet的训练极其消耗存储资源,因为需要保留大量的特征图用于反向传播计算;
二、特征融合中add和concat的区别是什么?哪种更好?
add:特征图的值进行相加,通道数不变;
concat:是指特征图拼接,通道数增加;
个人理解:实际上二者的不同在于add是两个特征图相加,存在损失信息的风险,concat是特征图拼接,保留所有原始信息,所以用concat方式会比较好,但add需要的内存和参数会小于concat;
八、SENet
意义:最早将注意力机制引入卷积神经网络,并且该机制是一种即插即用的模块;
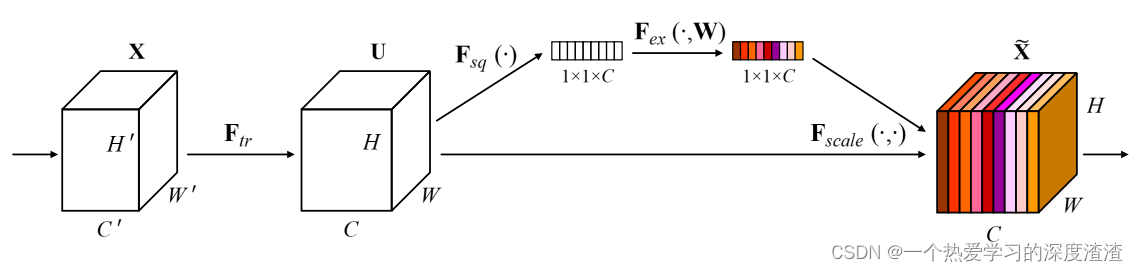
上图就是该网络中最重要的模块结构——SE block,体现了压缩和融合的过程;
重点概念
一、注意力机制核心思想是什么?
注意力机制可以理解为,设计一些网络输出层权重值,利用权重值与特征图进行计算,实现特征图的变换,使得模型加强关注区域的特征值;
二、SE—block结构的原理,怎么实现注意力机制的?
从上面图可知,SE—block主要分成三部分:Squeeze、Excitation、Scale;
Squeeze:通过全局平均池化(GAP)压缩特征图至向量形式(1x1xC);
Excitation:两个全连接层对特征向量进行映射变换,最后通过一个sigmoid限制范围到[0, 1];
Scale:将得到的权重向量与原始每个通道进行相乘得到加权后的特征图;
总结:
上述就是这里注意力机制实现的方法,当然注意力机制不仅可以作用于通道,也可以作用于HxW,注意力机制的一些前沿应用还有用于VIT中,感兴趣可以了解下Attation的发展及应用;
最后
至此也将CV—Baseline中基础的模型整理了一遍,但仅仅是从网络的一些特点进行总结的,一些细小的trick在本篇中并未进行说明,感兴趣的可以看看论文;
当然,了解模型的原理并不算掌握模型,代码实现也是关键的一步,希望每一个模块及结构都可以用熟悉的框架实现一遍,特别是对官方给出的开源代码,原理+代码都熟练后才能算是真正的掌握;
