@article{gao2021rethink,
title={Rethink Dilated Convolution for Real-time Semantic Segmentation},
author={Gao, Roland},
journal={arXiv preprint arXiv:2111.09957},
year={2021}
}
废话不多说,开局一张图看性能

摘要
语义分割的最新进展通常采用经过ImageNet预训练的backbone,配合一个特殊的上下文模块,以快速增加感受野。虽然模型的分割精度得到了一定的提升,但大部分的计算量由并未带来足够大感受野的backbone产生。
最近的一些研究解决了这个问题,通过快速降低backbone中的分辨率,同时有一个或多个具有高分辨率的并行分支。本文采用了一种不同的方法,设计了一个受ResNeXt启发的Block结构,该结构使用2个具有不同的膨胀率的并行3×3卷积层,扩大感受野的同时保留局部信息。在backbone中重复这个Block结构,不需要在它之后附加任何特殊的上下文模块。此外,本文提出了一种轻量级解码器,它可以比常见的解码器更好地恢复局部信息。
为了证明方法的有效性,RegSeg在Cityscapes和CamVid数据集上取得了最好的结果。使用混合精度的T4GPU,RegSeg以30FPS/秒的速度在Cityscapes测试集上达到了78.3mIOU,在CamVid测试集上以70FPS/秒的速度达到了80.9 mIOU,且都没有经过ImageNet预训练。
本文贡献
本文的贡献如下:
1. 提出了一种新的 dilated block 结构“D Block”,它可以在保持局部细节的同时轻松地增加Backbone的感受野。通过在RegSeg的Backbone中重复D Block,可以轻松控制感受野无需额外的计算;
2. 介绍了一种轻量级解码器,它的性能优于常见的方案;
3. 进行了大量的实验来证明方法的有效性。RegSeg在Cityscapes测试集上实现了78.3 mIOU,同时达到30帧/秒,在CamVid测试集上实现了80.9 mIOU,速度70帧/秒,两者都没有经过ImageNet预训练。在Cityscapes测试集上,RegSeg比SFNet(DF2)的最佳结果高出0.5%。在相同的训练设置下,RegSeg在Cityscapes上的表现比DDRNet-23表现好0.5%。
相关工作
网络设计
在ImageNet上训练的模型在一般的网络设计中起着重要的作用,它们的改进往往会迁移到其他领域,如语义分割。通过使用随机搜索进行大量的实验和分析趋势以减少搜索空间,RegNet对ResNeXt的架构进行了许多改进。它们提供了各种模型,并且在相当的训练设置下,这些模型优于EfficientNet。EfficientNet v2是EfficientNet的改进版本,在更高的分辨率下使用常规卷积而不是深度可分离卷积实现训练更快的目的。本文从RegNet中获得灵感,通过调整它们的块结构来进行语义分割。
语义分割
全卷积网络(FCNs)在分割任务中击败了传统方法。DeepLabv3在ImageNet预训练的Backbone中使用空洞卷积,将输出stride减少到16或8,而不是通常的32,并通过提出空洞空间金字塔池模块(ASPP)来增加感受野,该模块并行地应用了不同扩张率的卷积层分支。PSPNet提出了金字塔池模块(PPM),该模块通过首先应用平均池化得到不同分辨率的特征图,然后将特征图输入不同大小卷积层的并行分支。本文提出了与ASPP结构相似的dilated block(D块),并将其作为我们的主干的构建块,而不是在末端附加。
DeepLabv3+建立在DeepLabv3之上,通过在输出stride为4处添加两个3×3卷积设计了一个简单的解码器,以提高边缘的分割质量。HRNetV2在backbone中保持不同分辨率的并行分支,最好的分支输出stride为4。
实时语义分割
MobilenetV3使用轻量级解码器LRASPP来适应ImageNet模型进行快速语义分割。BiSeNetV1和BiSeNetV2在backbone中有两个分支(空间路径和上下文路径),并在最后合并,在没有ImageNet预训练的情况下获得良好的性能。SFNet提出了Flow Alignment Module (FAM),比双线性插值更好地恢复低分辨率特征。STDC通过删除空间路径和设计一个更好的backbone来重新考虑BiSeNet体系结构。HarDNet通过使用主要使用3×3卷积和几乎不使用1×1卷积,减少了GPU内存消耗。DDRNet-23使用两个分支,它们之间有多个双边融合,并附加一个新的上下文模块称为Deep Aggregation Pyramid Pooling Module(DAPPM)。DDRNet-23是一项尚未经过同行评审的并行工作。DDRNet-23是目前最先进的实时Cityscapes 语义分割技术,本文也证明了在相同的训练设置下RegSeg优于DDRNet-23。
网络
Field-of-view
本文感兴趣的是通过卷积获得模型的感受野(FOV)。例如,两个3×3卷积的组合在kernel大小和stride上等于5×5卷积,简单地说感受野是5。更一般地,卷积组成的感受野可以像FCN中描述的那样迭代计算。假设到当前的卷积组成在kernel大小和stride上是相等的(kernel=3x3,stride=s),用一个kernel为 k’× k’ 和stride为s’的卷积组成它。更新k和s:
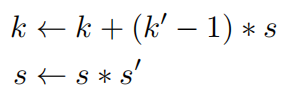
k是Field-of-View的最终值。
有两种方法可以有效地增加感受野。一种是在早期用stride为2的卷积或平均池化进行下采样。另一种方法是使用空洞卷积,扩张率为r的3x3卷积在感受野上等于kernel大小为2r+1的卷积。但是,为了不在权值之间留下任何空洞,需要k/s>=r,其中k和s是使用上文所述的组合来计算的。这作为r的上界,在实际中选择的膨胀率要低得多。
感受野与输入图像大小之间的关系对模型的精度影响很大。例如,如果在ImageNet上使用ResNet架构,输入图像大小为224x224,在全局平均池化之前查看特征图,至少需要224*2-1= 447的感受野才能看到完整的图像。同样,对于图像大小为1024x2048的Cityscapes,对于输出的左上角像素,需要感受野为2047才能看到输入图像的左下角像素,需要感受野为4095才能看到输入图像的右下角像素。
Dilated block
Dilated Block(D Block)受到了RegNet中Y Block的启发,也称为SE-ResNeXt Block。Y Block和新的D Block都使用了组卷积。假设输入通道=输出通道= w对于Y Block和D Block中的3 × 3卷积始终成立。组卷积有一个属性叫做组宽g,g整除w。在前向传播期间,w个输入通道被分为w/g组,输出最终被重新拼接为w个通道。
由于每组都有一个卷积,可以对不同的组应用不同的扩张率来提取多尺度特征。例如,可以一半的组扩张率为1,另一半扩张率为10。这是D Block的关键。图3a显示了Y Block。图3b显示了D Block。当d1=d2=1时,D Block与Y Block相等。在第4.4节中的实验表明4个不同膨胀率分支的D Block并不比有2个分支的D Block效果好。

图4为stride=2时的D Block。与ResNet D-variant类似,当Block的stride=2时,在shortcut分支上应用2×2平均池化。BatchNorm和ReLU紧跟每个卷积之后,但求和运算之后使用ReLUs之前不用,使用的SE reduction ratio为1/4。

深度学习框架支持组卷积,每个组卷积应用相同的扩张率。由于D Block对不同的组使用不同的扩张率,所以必须手动分离输入,应用卷积,然后拼接。这里使用(d1,d2)表示D Block的扩张率。表一证明了手动分离、拼接、使用空洞卷积影响速度。因此,YBlock比DBlock略快一些,即使它们具有相同的FLOP复杂度和参数计数。但在实践中使用D Block的扩张率为(1,1),扩张率相同,不需要手动分离和拼接。(我有话说:那不就完全是Y Block了吗)

结构描述:Backbone是通过重复D Block构建的,样式类似于RegNet。Backbone以一个32的通道3×3卷积为起点,stride为2。在1/4分辨率有一个48通道的D Block,在1/8分辨率有3个128通道的D Block, 在1/16分辨率有13个256通道的D Block,在1/16分辨率结束位置有1个320通道的D Block。对于所有的D Block g=16,并没有下采样为1/32。在分辨率为1/16时,对13个stride=1的block增加了扩张率:1个(1,1)、1个(1,2)、4个(1,4)、7个(1,14)。作为简写,这里将扩张率表示为(1,1) + (1,2) + 4∗(1,4)+7∗(1,14)。对于所有其他Block使用的扩张率为(1,1),等同于Y Block,除了2×2平均池化时,步幅=2。以类似于EfficientNetV2的格式,在表2中显示了RegSeg的Backbone。为最后13个Block选择正确的扩张率是很重要的,在第4.4节中对扩张率进行了实验。

Decoder
解码器的工作是恢复丢失在Backbone中的局部细节。与DeepLabv3+类似,使用[k × k,c]表示具有C个输出通道的k × k卷积。
结构描述:将backbone的最后1/4、1/8和1/16的特征映射作为解码器的输入。将[1x1, 128]应用于1/16、[1x1, 128] 应用于1/8、[1x1, 8] 应用于1/4。向上采样1/16(2倍),将它与1/8相加,然后再应用一个[3x3, 64]的卷积。再次向上采样,连接1/4,并在最终的[1x1,19]卷积之前应用一个[3x3,64]卷积。除了最后一个卷积之外,所有卷积后面都跟着BatchNorm和ReLU。解码器如图5所示。这个简单的解码器比许多现有的具有类似延迟的解码器性能更好。作者也试验了不同的解码器结构设计。

实验
Ablation studies


Comparison on CamVid & Cityscapes
Extra data:预训练数据集

