目录:导读
前言
Selenium4自动化测试:https://www.bilibili.com/video/BV1MS4y1W79K/
误报成功和误报失败
误报成功也是测试结果成功的一种情况,即使实际情况并非如此。反之亦然,误报失败是测试失败一种情况,即使一切都按预期进行,测试结果也会报告脚本执行过程中出现错误。误报对自动化测试一直是最大的挑战,当然Selenium也不例外。
当通过Selenium脚本运行成百上千的测试用例时,可能会遇到一些不稳定的测试,这些测试显示误报。如果长时间不处理,可能会导致整个自动化测试项目失去价值,从而使测试人员的自动化测试脚本沦为“废物”。
测试脚本的稳定性无疑是Selenium自动化中最常见的挑战之一。目前通用的解决办法依然缺少,但从过往工作经验来看,测试左移,独立测试环境,统计脚本误报率等等从流程上来解决这个难题是一个不错的思路。
等待网页加载JavaScript
现在很多网站包含需要JS异步加载Web元素,例如基于用户选择的下拉列表。则Selenium脚本在运行时可能会在这些Web元素时突然失效。发生这种情况是因为WebDriver没有处理网页完全加载所花费的时间。
为了处理页面加载的Selenium自动化中的异步加载的问题,需要使WebDriver等到该页面的完整JavaScript加载完成之后再进行操作。
在任何网页上执行测试之前,应确保该网页(尤其是带有很多JavaScript代码的网页)的加载已完成。可以使用readyState属性,该属性描述文档/网页的加载状态。document.readyState状态为complete表示页面/文档的解析已完成。
''' 在此示例中,pytest框架与Selenium一起使用 '''
import pytest
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.keys import Keys
from time import sleep
from contextlib import contextmanager
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support.expected_conditions import staleness_of
@pytest.fixture(params=["chrome"],scope="class")
def driver_init(request):
if request.param == "chrome":
web_driver = webdriver.Chrome()
request.cls.driver = web_driver
yield
web_driver.close()
@pytest.mark.usefixtures("driver_init")
class BasicTest:
pass
class Test_URL(BasicTest):
def test_open_url(self):
self.driver.get("https://www.*****.com/")
print(self.driver.title)
sleep(5)
def wait_for_page_load(self, timeout=30):
old_page = self.driver.find_element_by_id('owl-example')
yield
WebDriverWait(self.driver, timeout).until(
staleness_of(old_page)
)
def test_click_operation(self):
# 等待10秒钟的超时时间,然后执行CLICK操作
with self.wait_for_page_load(timeout=10):
self.driver.find_element_by_link_text('FREE SIGN UP').click()
print(self.driver.execute_script("return document.readyState"))
处理动态内容
越来越多的网站使用了动态的内容。测试具有静态内容的网站对Selenium自动化来说相对轻松。在当今时代,大多数网站所包含的内容可能因一个访客而异。这意味着内容本质上是动态的(基于AJAX的应用程序)。
例如,电子商务网站可以根据用户登录的位置加载不同的产品、内容可能会有所不同,具体取决于用户从特定下拉菜单中选择的内容。由于新内容的加载需要时间,因此仅在加载完成后才触发测试非常重要。
由于网页上的元素以不同的时间间隔加载,因此如果DOM中尚不存在某个元素,则可能会出现错误。这就是为什么处理动态内容一直是Selenium自动化中最常见的挑战之一的原因。
解决此问题的一个简单解决方案是使线程休眠几秒钟,这可能会提供足够的时间来加载内容。但是,这不是一个好习惯,因为,无论是否发生必需的事件,线程都会休眠那么长的时间。
# 并不完美的方案
from selenium import webdriver
import time
from time import sleep
driver = webdriver.Firefox()
driver.get("https://www.*****.com")
# 睡眠10秒,无论是否存在元素
time.sleep(10)
# 资源释放
driver.close()
使用Selenium WebDriver动态内容处理此挑战的更好方法是使用隐式等待或显式等待,这取决于各自的需求。
显式等待处理动态内容
使用显式等待,可以使Selenium WebDriver停止执行并等待直到满足特定条件。如果希望设置条件以等待到确切的时间段,则可以将它与thread.sleep()函数一起使用。有多种方法可以实现显式等待,带有ExpectedCondition的WebDriver是最受欢迎的选项。
from selenium import webdriver
from time import sleep
from selenium.common.exceptions import NoSuchElementException
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.support.ui import WebDriverWait
driver = webdriver.Firefox()
driver.get("https://www.*****.com")
try:
myElem_1 = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.CLASS_NAME, 'home-btn')))
print("Element 1 found")
myElem_2 = WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.CLASS_NAME, 'login')))
print("Element 2 found")
myElem_2.click()
sleep(10)
#异常处理
except TimeoutException:
print("No element found")
sleep(10)
driver.close()
在上面的示例中,对受测URL内容进行了两次搜索。第一次搜索是通过CLASS_NAME将元素定位到元素home-btn的最长持续时间为10秒。
第二个搜索是可点击元素登录,最长持续时间为10秒。如果存在clickable元素,则执行click()操作。在两种情况下,都将WebDriverWait与ExpectedCondition一起使用。WebDriverWait触发ExpectedCondition的默认限制为500毫秒,直到收到成功的响应。
隐式等待处理动态内容
隐式等待通知WebDriver在特定时间段内轮询DOM,以获取页面上Web元素的存在。默认超时为0秒。隐式等待需要一次性设置,如果配置正确,它将在Selenium WebDriver对象的生存周期内可用。
from selenium import webdriver
import time
from time import sleep
from selenium.common.exceptions import NoSuchElementException
from selenium.webdriver.support import expected_conditions as EC
from builtins import str
driver = webdriver.Firefox()
driver.get("https://www.*****.com")
driver.implicitly_wait(60)
curr_time = time.time()
try:
curr_element = driver.find_element_by_class_name("home-btn")
except:
print("元素不存在!")
print("耗时 " + str(int(time.time()-curr_time))+'-secs')
driver.close()
切换浏览器窗口
多窗口测试无疑是Selenium自动化中的常见挑战之一。一种理想的情况是单击按钮会打开一个弹出窗口,该弹出窗口成为子窗口。
一旦有关子窗口上的活动的活动完成,则应将控件移交给父级或者上一级窗口。这可以通过使用switch_to.window()方法(其中window_handle作为输入参数传递)来实现。
用户单击链接后,将打开一个新的弹出窗口,该窗口将称为子窗口。switch_to.window方法用于切换回父窗口。可以使用driver.switch_to.window(window-handle-id)或driver.switch_to.default_content()切换到父窗口。
import unittest
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from time import sleep
class test_switch_windows(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Firefox()
def test_open_pop_up_window(self):
driver = self.driver
driver.get("http://www.****.com/html/codes/html_popup_window_code.cfm")
title1 = driver.title
print(title1)
#获取当前窗口的窗口句柄
parent_window = driver.window_handles[0]
print(parent_window)
#弹出式窗口是iframe
driver.switch_to.frame(driver.find_element_by_name('result1'))
driver.find_element_by_link_text('show_iframe').click()
#获取子窗口的句柄
child_window = driver.window_handles[1]
#父窗口将在后台
#子窗口来到前台
driver.switch_to.window(child_window)
title2 = driver.title
print(title2)
print(child_window)
#断言主窗口和子窗口标题不匹配
self.assertNotEqual(parent_window , child_window)
sleep(5)
def tearDown(self):
self.driver.close()
if __name__ == "__main__":
unittest.main()
无法自动化一切
100%自动化是一个吹牛的命题。众所周知的是,并非所有测试方案都可以自动化,因为有些测试需要手动干预。需要确定团队在自动化测试上相对于手动测试应花费的精力的优先级。
尽管Selenium框架具有一些功能,可以通过这些功能来截取屏幕截图,记录视频(测试的整体执行情况)以及可视化测试的其他方面,但是将这些功能与可扩展的基于云的跨浏览器测试平台一起使用可能会具有很大的价值。
生成测试报告
任何测试活动的主要目的是发现BUG并改善整体产品。在跟踪正在执行的测试,生成的输出和测试结果方面,报告可以发挥主要作用。尽管有可以与pytest和Selenium一起使用的模块,例如pytest_html(对于Python),但是测试报告中的信息可能并不十分详尽。
Selenium可以使用不同类型的编程语言(例如Java,C#、.Net等)的类似模块/包,但是这些语言仍然存在相同的问题。收集测试报告是Selenium自动化中的关键挑战之一。
很多基于Selenium的第三方云测平台,还有很多公司机遇Selenium开发的自己的报告框架提取,一般来说从以下几个方面丰富报告信息:
检索构建信息,例如构建测试状态,单个测试状态,测试运行时间,错误和测试日志;
通过命令获取屏幕截图;
浏览器环境的详细信息;
| 下面是我整理的2023年最全的软件测试工程师学习知识架构体系图 |
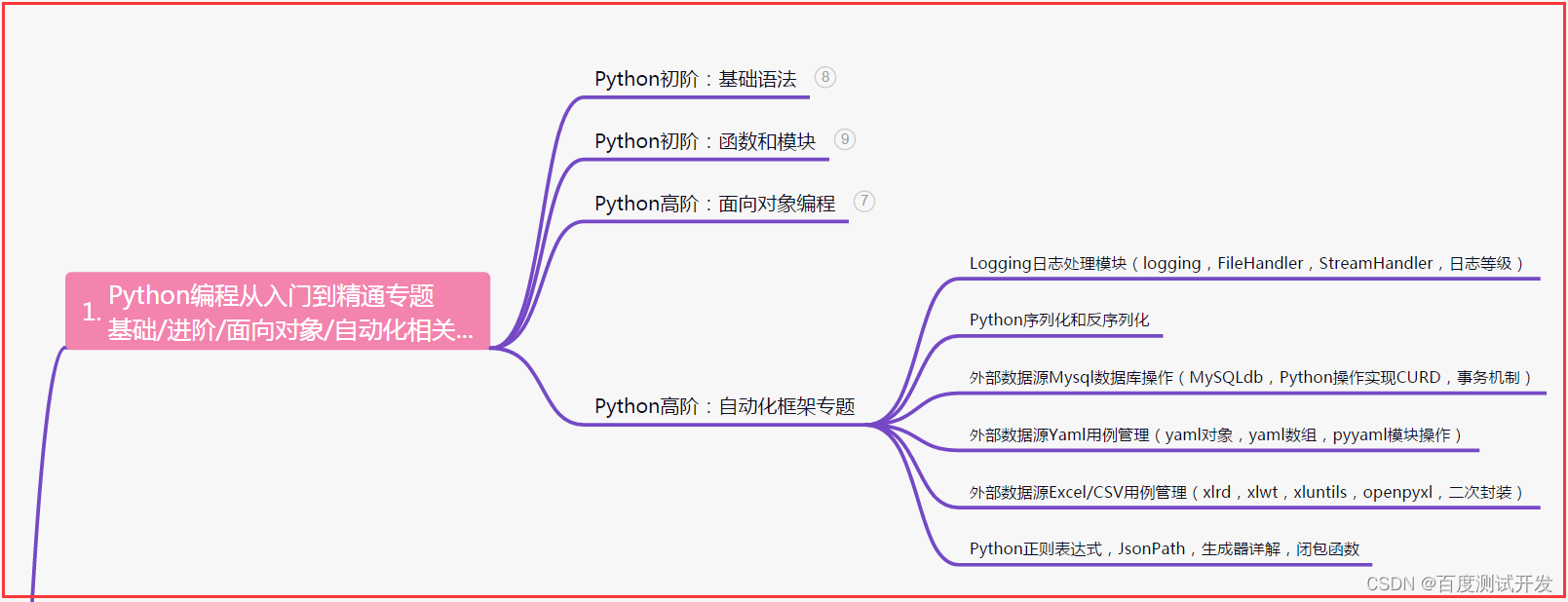
一、Python编程入门到精通
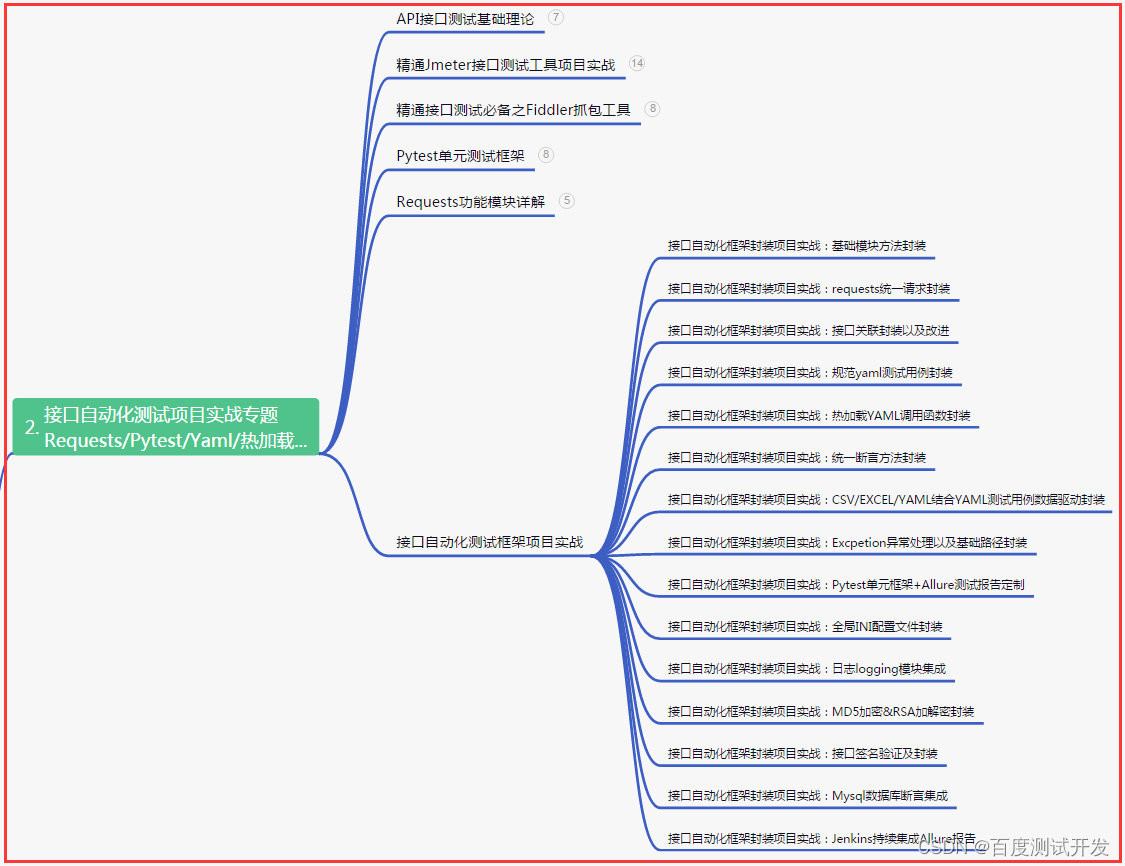
二、接口自动化项目实战
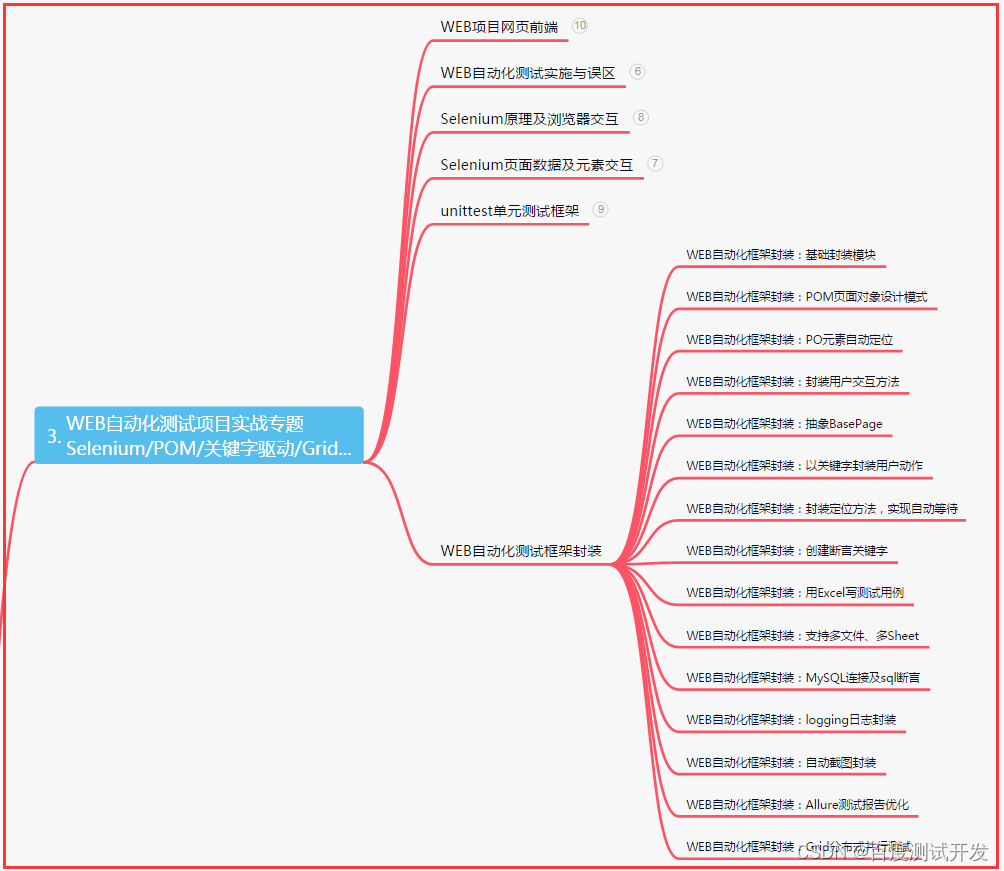
三、Web自动化项目实战
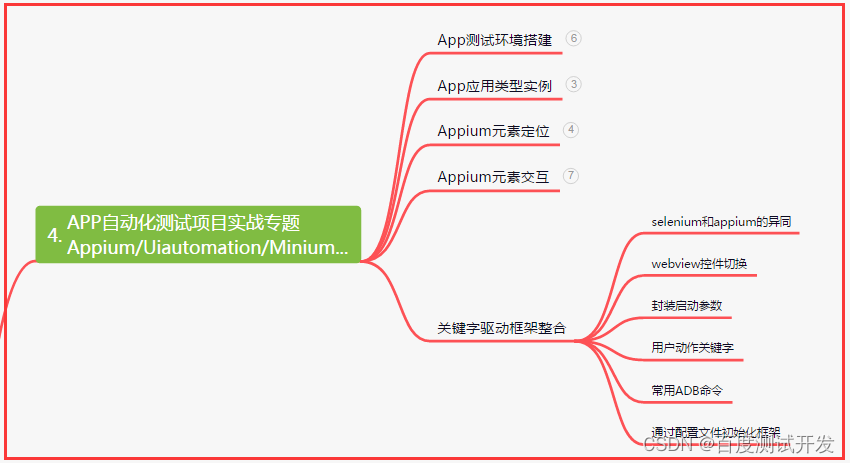
四、App自动化项目实战
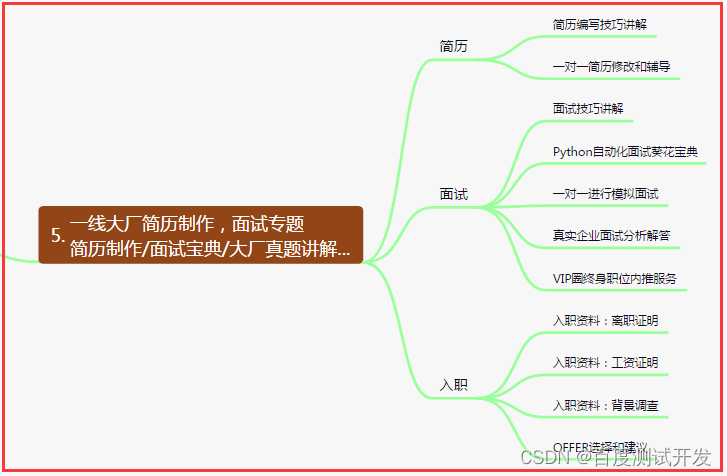
五、一线大厂简历
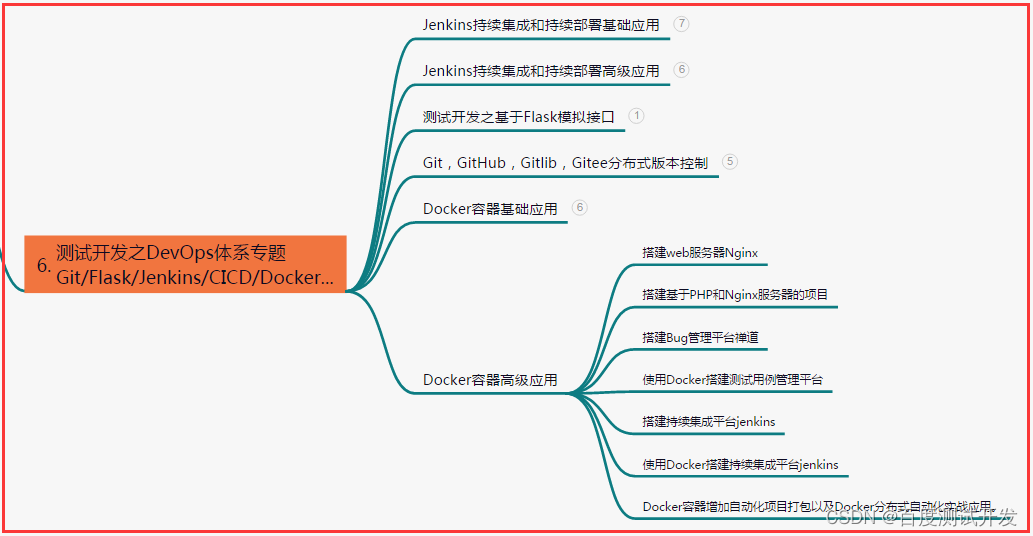
六、测试开发DevOps体系
七、常用自动化测试工具

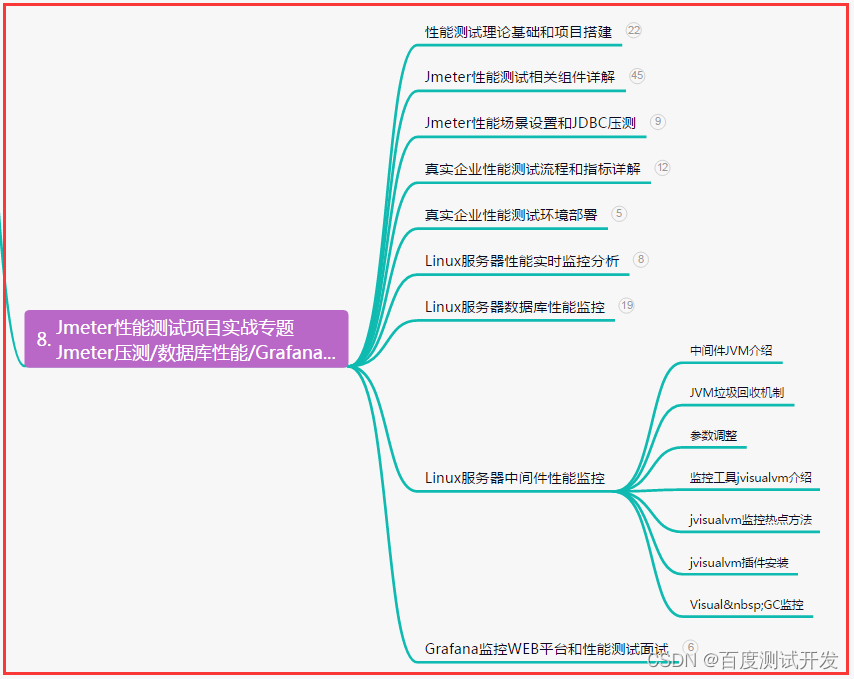
八、JMeter性能测试
九、总结(尾部小惊喜)
只有拼尽全力,才能体会到成功的喜悦;只有不断奋斗,才能迎来更美好的未来;只要你坚定自己的信念,勇往直前,就能战胜一切困难,实现自己的理想。
只要你有梦想,就一定要去追逐它;只要你肯努力,就一定能够实现它。在追逐梦想的过程中会遇到挫折和困难,但只要坚持不懈,勇往直前,终将收获成功和成就感。加油!
只要你能坚持不懈地努力奋斗,就一定能够实现自己的梦想。无论遇到多少困难和挫折,都要不屈不挠地前进,因为成功就在前方等待着你。相信自己,勇往直前!