训练及预测要求
目标检测训练建议采用6G及以上显卡训练,单个目标检测模块运行检测需2G显存,多模块或多流程则需2G以上显存,推荐使用GTX1660Ti、GTX1080、GTX1080Ti、RTX2080、RTX2080Ti显卡
目标检测预测图像要求分辨率宽高大于64像素,若小于软件会报错。
目标宽高分辨率较小者占图片宽高分辨率较大者比例建议大于1.31%。
预测图像分辨率需保持一致,否则VM软件会对资源进行重新申请导致耗时严重增加。
使用vM深度学习模块需要配合IMVS-VM-7100加密狗使用
目录
模型训练
以管理员运行

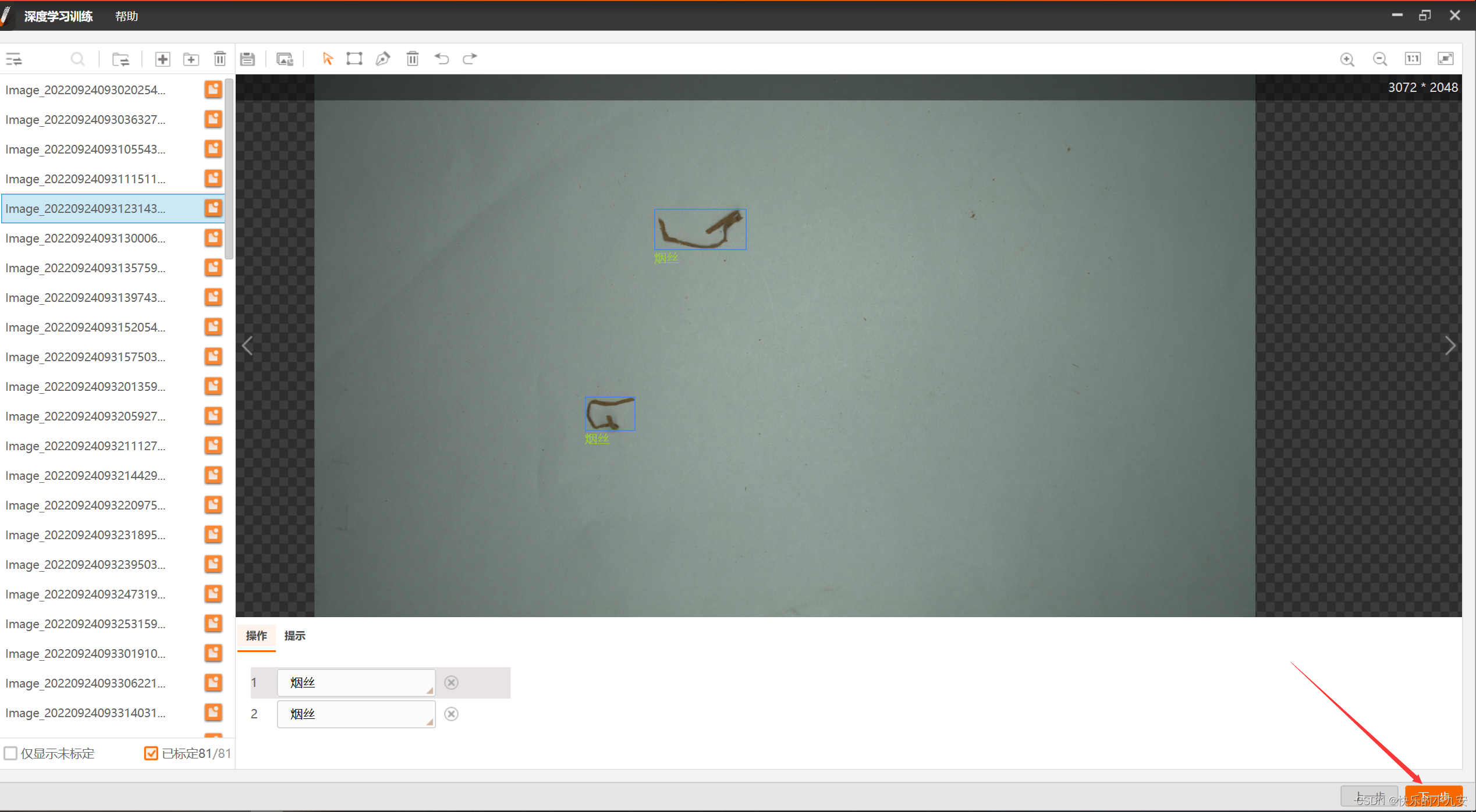
新建训练集 你要训练模型的文件目录 右上角为框选区域
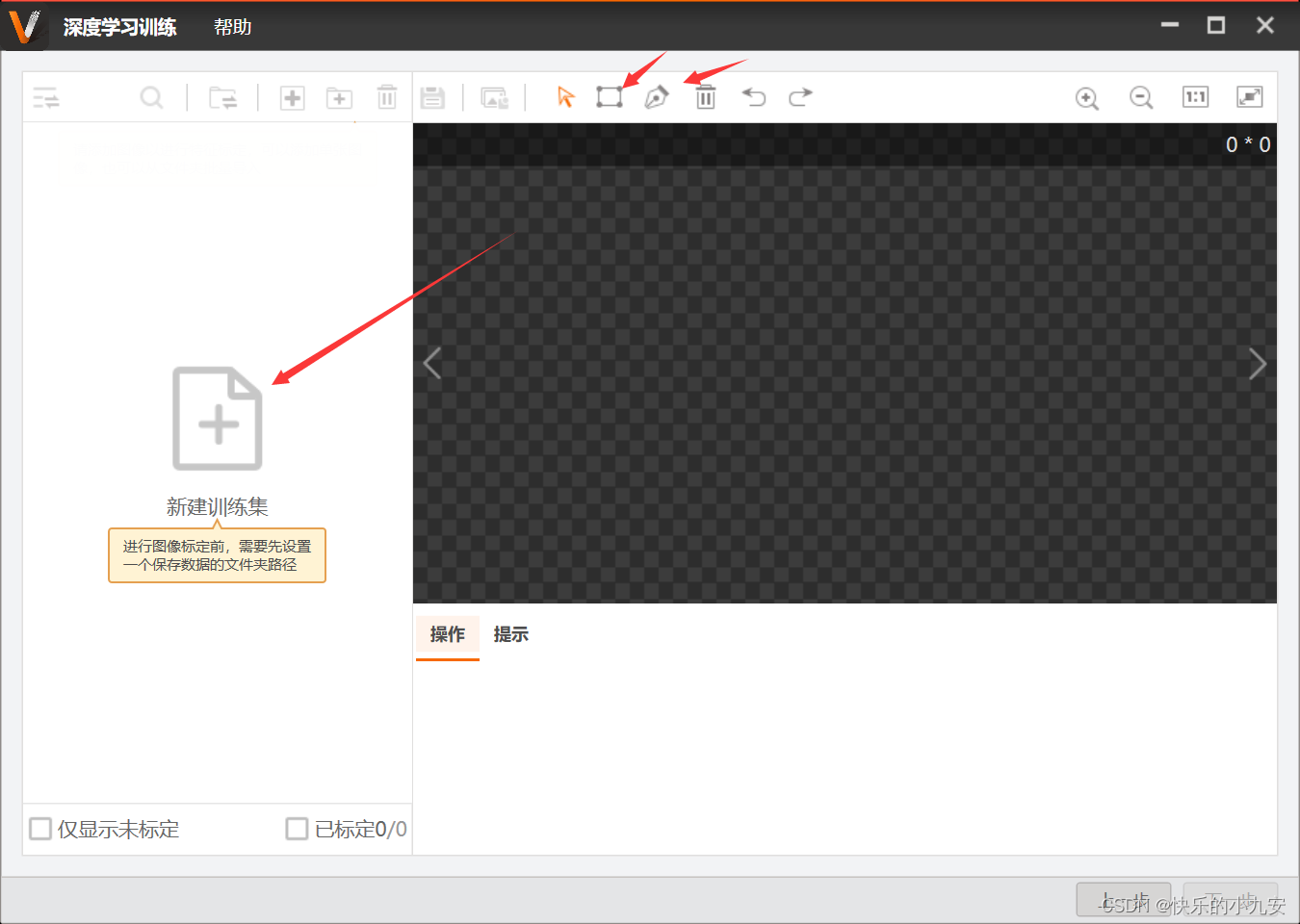
矩形框为矩形可以随意改变大小 钢笔形状为多变形掩模 左键为确定该步 右键删除 上步 双击左键为保存结束框选
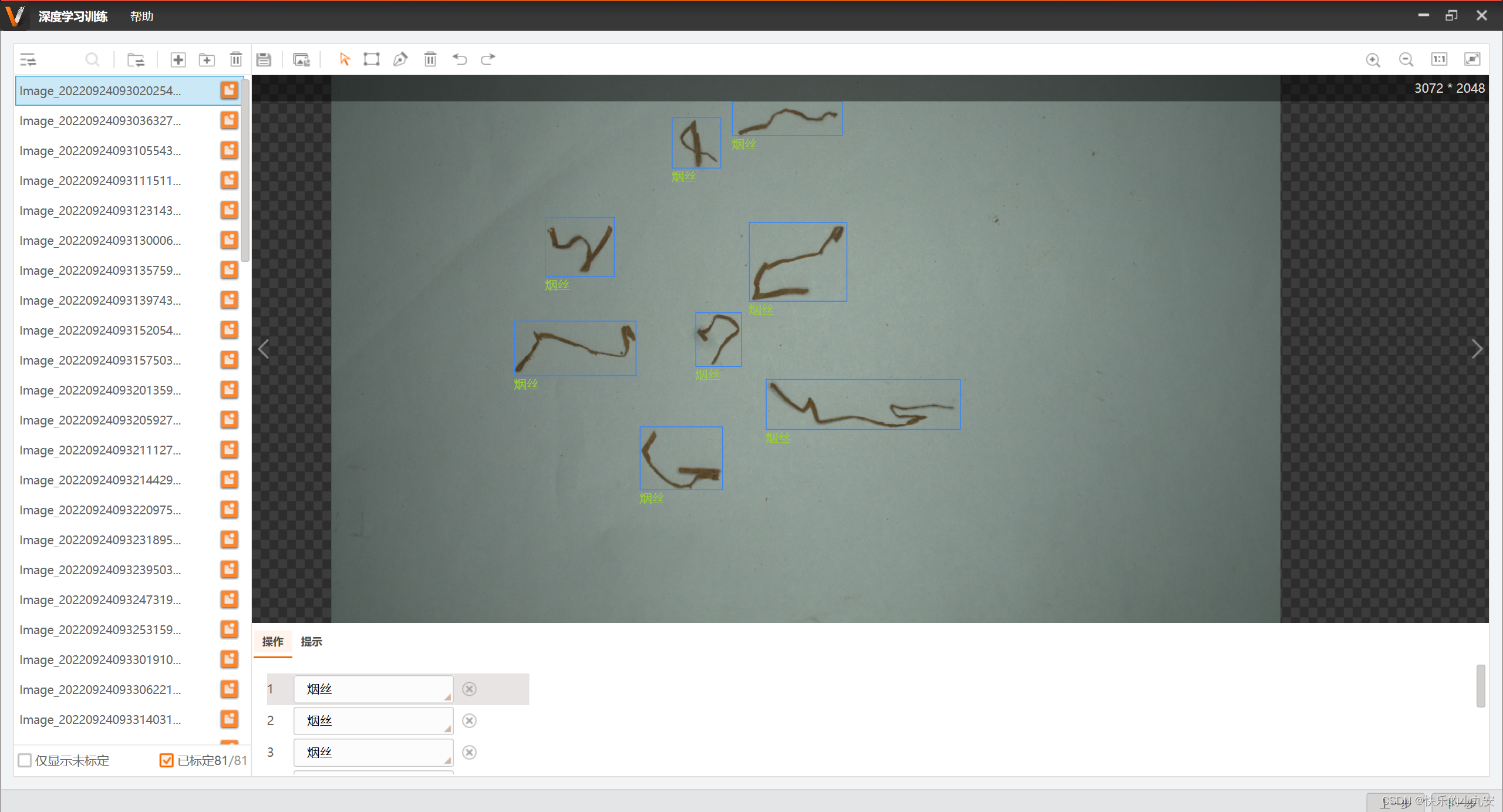
左下角为已经标注 和 未标注 选择未标注开始打标签 框选完成下方会出现123....你选择标签名字

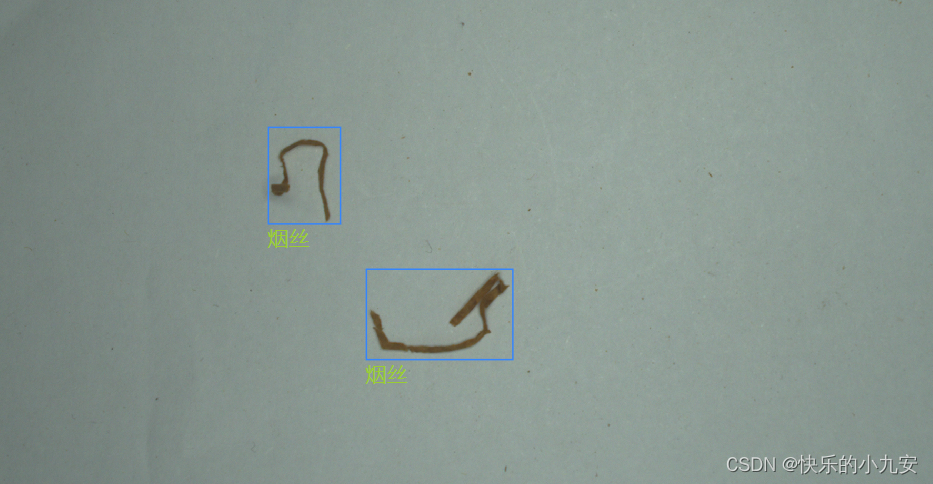

图像集图片全部标注完成 点击下一步
参数设置
本地训练:需要安装独立显卡
云服务器训练:将训练图片上传服务器,无需独显
本地服务器训练需搭建本地训练服眼务器才使用
迭代轮次:算法内部称为Epoch,一轮就是将所有训练样本训练一次的过程。增大迭代伦次可以增加训练的迭代次数。参数根据图片数量设置。30张设置700轮。100张设置500轮。500张设置200轮。1000张设置150轮。5000张设置100轮。10000张设置60轮。100000张设置50轮。若训练过程中曲线任有明显的下降趋势,可以暂停训练增大迭代伦次。
基础学习率:更新参数时前进的步长。一般按默认值1设置,不需改动。Patch大小:训练过程中,输入神经网络的图像尺寸。有大中小可供选择,对应的缩放分辨率为608,416,288。目标占图片比例小则推荐选择大patch,占比大则可选择中或小patch。为了保证效果建议选择大Patch。
模型能力:处理复杂图片的能力,有普通和高精度两种模式选择。普通训练、检测速度更快,消耗的显存资源更小。高精度检测效果更加精确,但资源消耗大。小目标、精度要求高推荐使用高精度模式,大目标、精度要求较低推荐使用普通模式。为了保证效果建议选择高精度
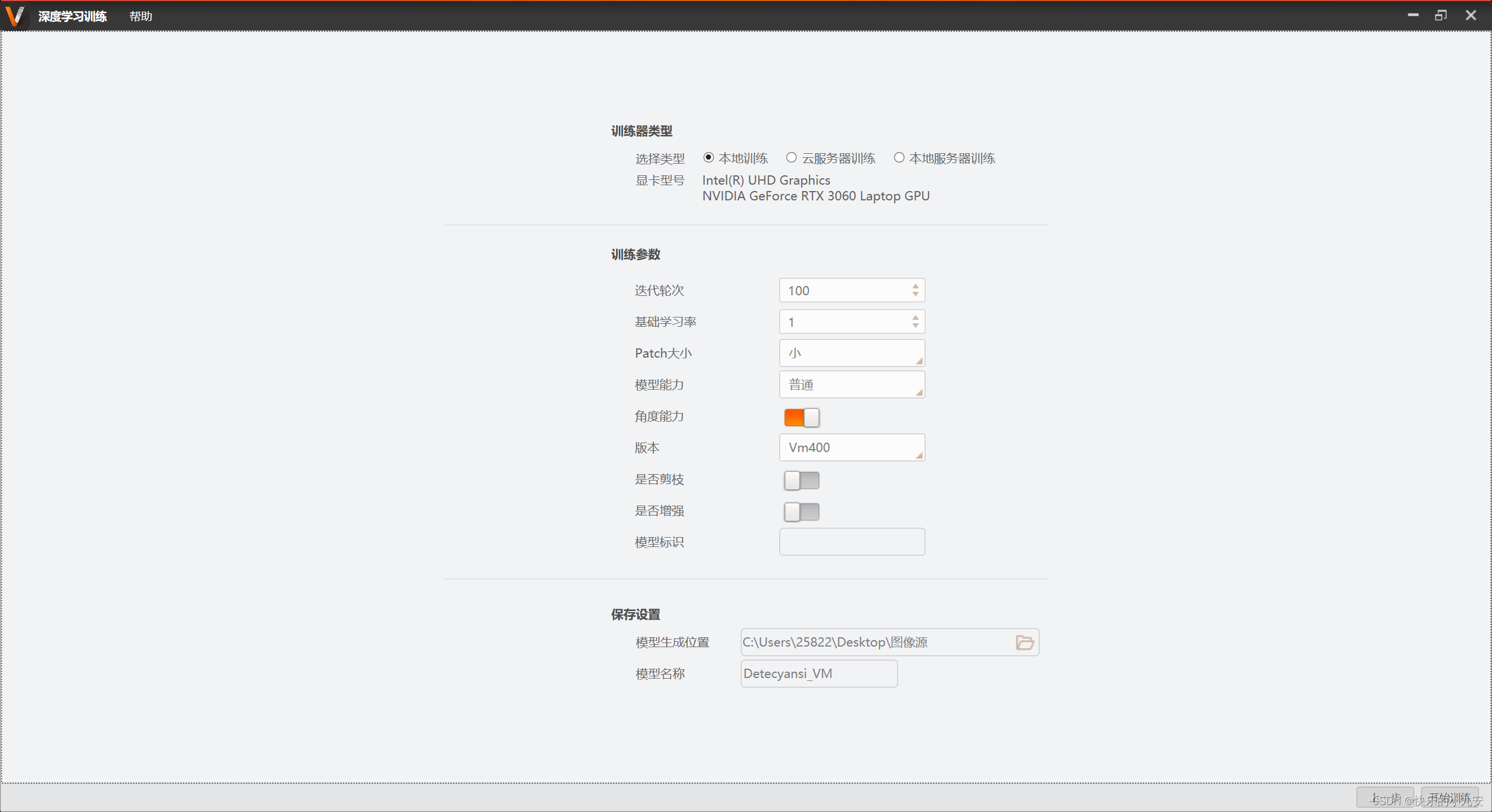
其中 vm400支持-360~+360 低于版本只支持-90~+90

模型标识即你选择的版本 自己能看懂即可
下载目录 即模型.bin文件要保存的地方
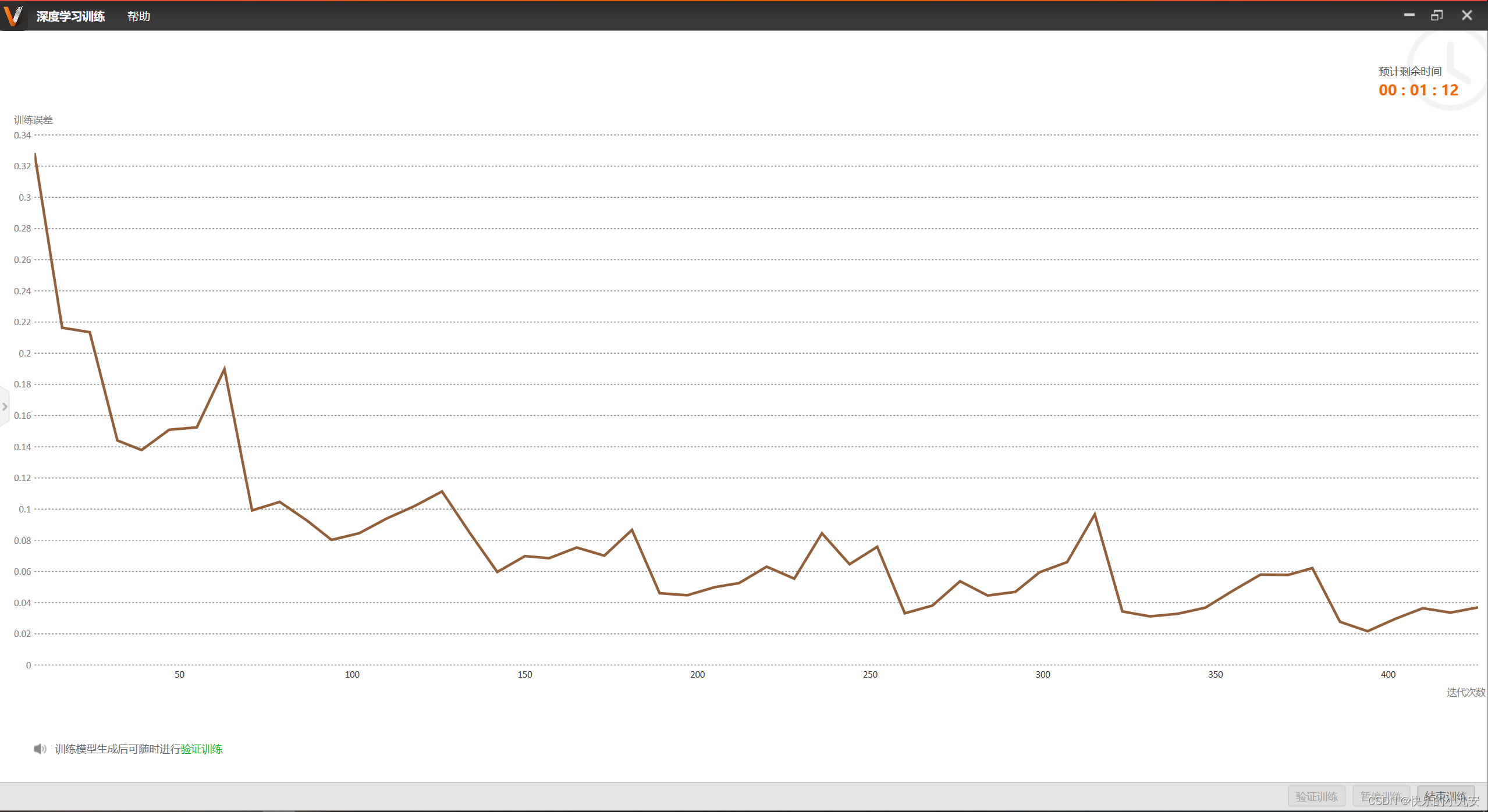

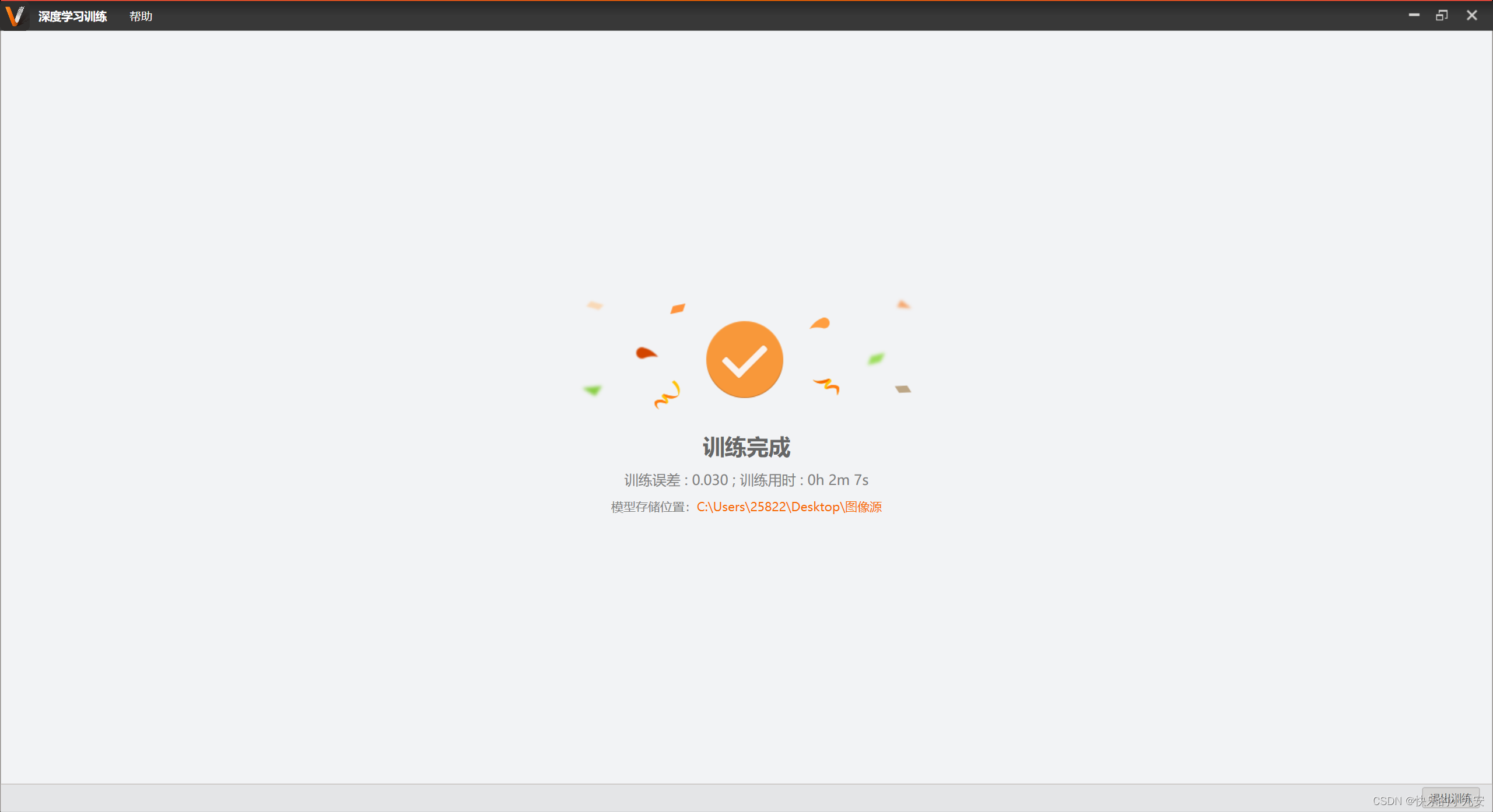
训练完成 可以看见保存路径出现三个模型 分别是:VM模型、SC.mmodel文件、SC模型
Xxxx_SC.bin-----SC7000相机模型(只能在SC7000中使用
Xxxx_SC.model -----SC平台训练模型中间文件_(无法在VM和相机中使用)
Xxxx_SC_VM.bin -----VM模型(只能在VM中使用)
VisionMaster使用.bin文件
打开深度学习版本VisionMaster
(VisionMaster_Patch是深度学习的安装包,安装完该Patch包后,VisionMaster才可以正常使用深度学习的模块)

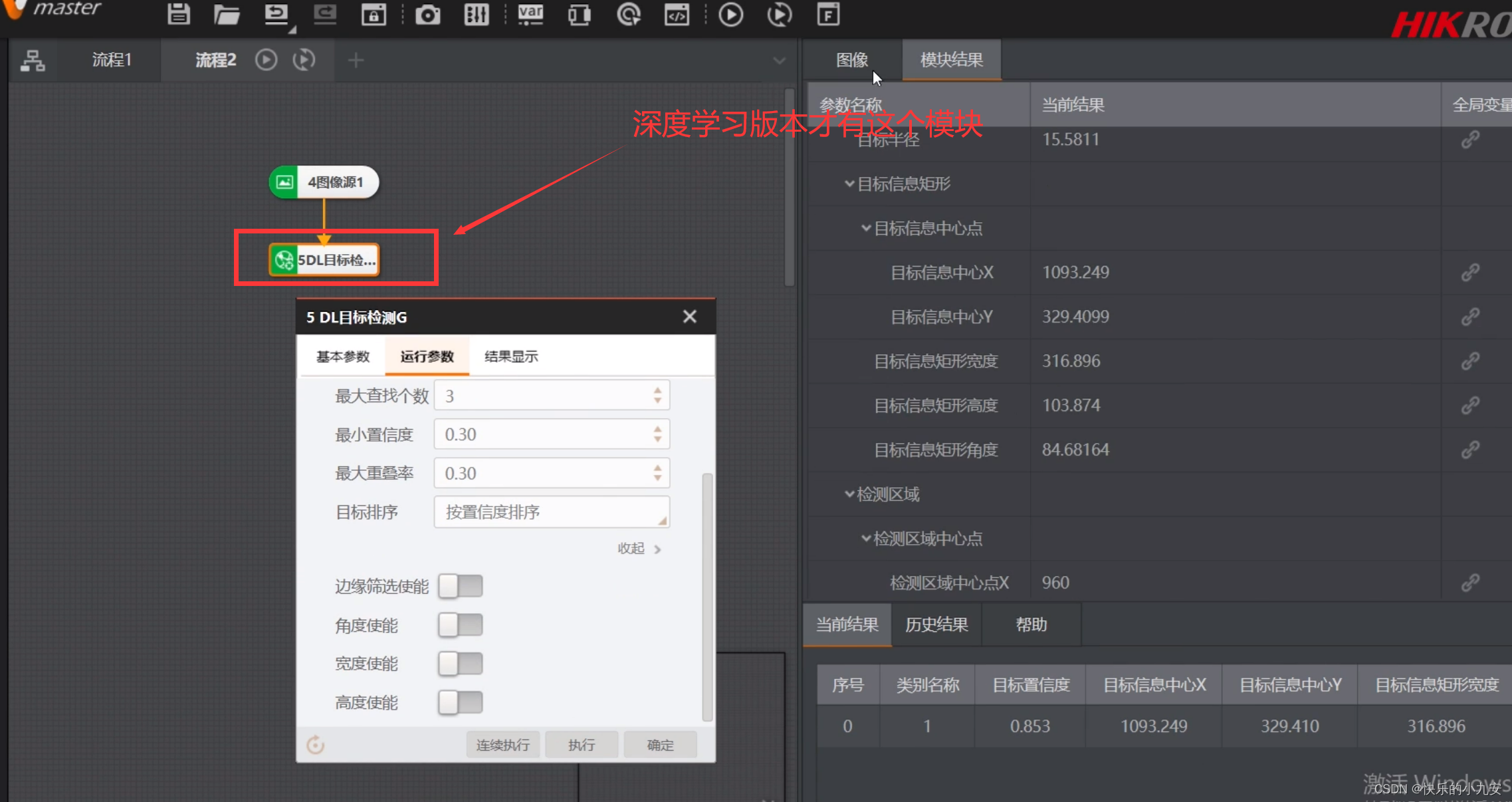
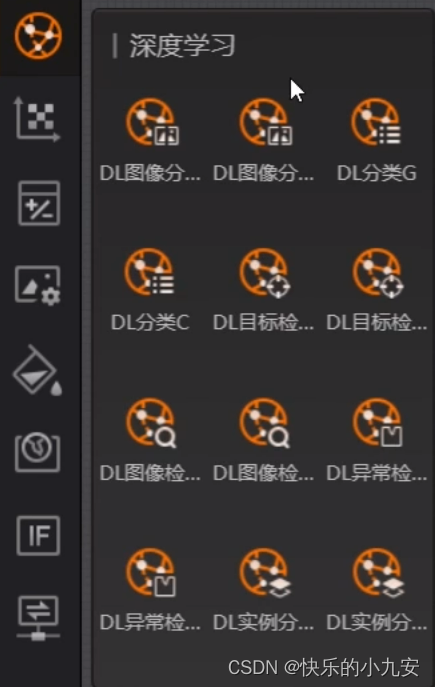
G代表gpu C代表cpu
选择刚刚训练好的.bin模型文件

最后检测的即可
通讯
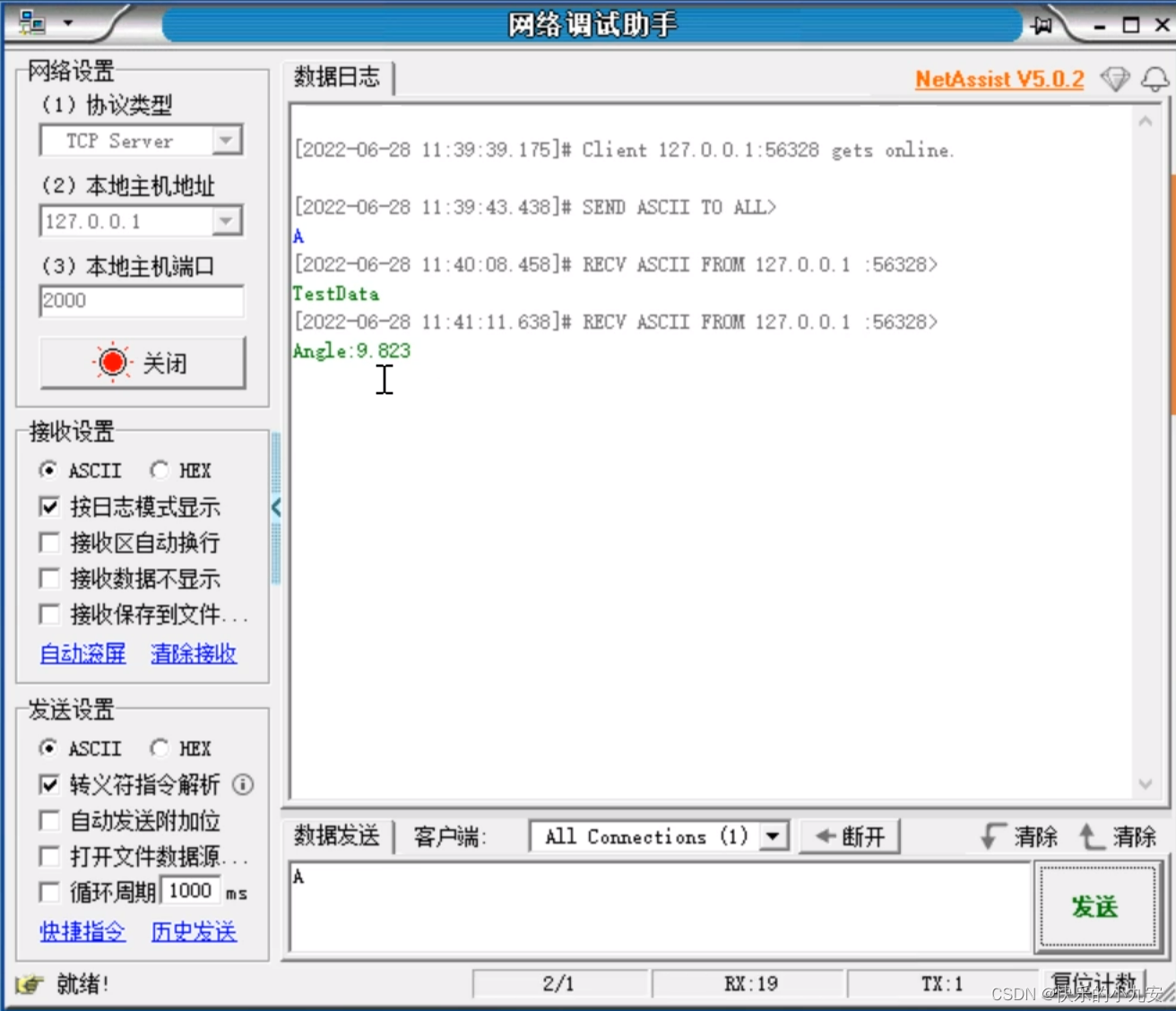
得到的数据可以通过TCP通讯发送数据
先将数据参数进行格式化
点击通讯管理
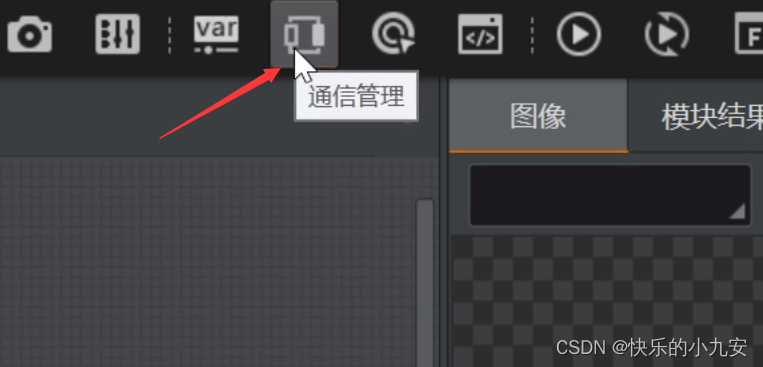
选择通讯协议
去网上下载网络调试助手

打开

输入对应的ip 和开放的端口号

点击发送