map阶段处理的数据如何传递给reduce阶段,是MapReduce框架中最关键的一个流程,这个流程就叫shuffle。
shuffle: 洗牌、发牌——(核心机制:数据分区,排序,合并)。
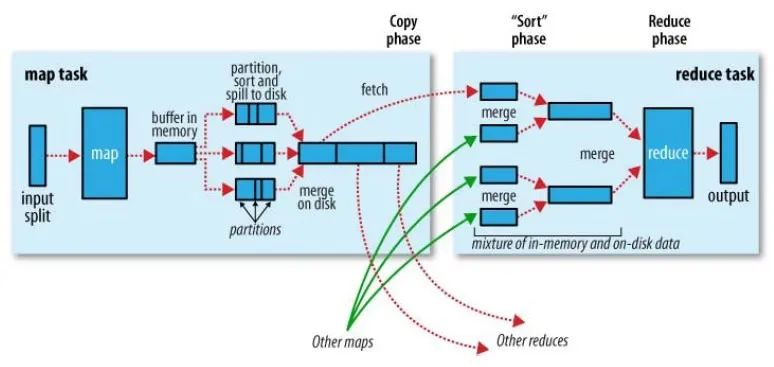
shuffle是Mapreduce的核心,它分布在Mapreduce的map阶段和reduce阶段。一般把从Map产生输出开始到Reduce取得数据作为输入之前的过程称作shuffle。
1).Collect阶段:将MapTask的结果输出到默认大小为100M的环形缓冲区,保存的是key/value,Partition分区信息等。
2).Spill阶段:当内存中的数据量达到一定的阀值的时候,就会将数据写入本地磁盘,在将数据写入磁盘之前需要对数据进行一次排序的操作,如果配置了combiner,还会将有相同分区号和key的数据进行排序。
3).Merge阶段:把所有溢出的临时文件进行一次合并操作,以确保一个MapTask最终只产生一个中间数据文件。
4).Copy阶段:ReduceTask启动Fetcher线程到已经完成MapTask的节点上复制一份属于自己的数据,这些数据默认会保存在内存的缓冲区中,当内存的缓冲区达到一定的阀值的时候,就会将数据写到磁盘之上。
5).Merge阶段:在ReduceTask远程复制数据的同时,会在后台开启两个线程对内存到本地的数据文件进行合并操作。
6).Sort阶段:在对数据进行合并的同时,会进行排序操作,由于MapTask阶段已经对数据进行了局部的排序,ReduceTask只需保证Copy的数据的最终整体有效性即可。
Shuffle中的缓冲区大小会影响到mapreduce程序的执行效率,原则上说,缓冲区越大,磁盘io的次数越少,执行速度就越快
shuffle机制视频详解-P46
详细优化方式
1)Map阶段:
(1)增大环形缓冲区大小。由100m扩大到200m
(2)增大环形缓冲区溢写的比例。由80%扩大到90%
(3)减少对溢写文件的merge次数。(10个文件,一次20个merge)
(4)不影响实际业务的前提下,采用Combiner提前合并,减少 I/O。
2)Reduce阶段:
(1)合理设置Map和Reduce数:两个都不能设置太少,也不能设置太多。太少,会导致Task等待,延长处理时间;太多,会导致 Map、Reduce任务间竞争资源,造成处理超时等错误。
(2)设置Map、Reduce共存:调整slowstart.completedmaps参数,使Map运行到一定程度后,Reduce也开始运行,减少Reduce的等待时间。
(3)规避使用Reduce,因为Reduce在用于连接数据集的时候将会产生大量的网络消耗。
(4)增加每个Reduce去Map中拿数据的并行数;
(5)集群性能可以的前提下,增大Reduce端存储数据内存的大小。
3)IO传输:
采用数据压缩的方式,减少网络IO的的时间。安装Snappy和LZOP压缩编码器。
压缩:
(1)map输入端主要考虑数据量大小和切片,支持切片的有Bzip2、LZO。注意:LZO要想支持切片必须创建索引;
(2)map输出端主要考虑速度,速度快的snappy、LZO;
(3)reduce输出端主要看具体需求,例如作为下一个mr输入需要考虑切片,永久保存考虑压缩率比较大的gzip。
4)整体:
(1)NodeManager默认内存8G,需要根据服务器实际配置灵活调整,例如128G内存,配置为100G内存左右,yarn.nodemanager.resource.memory-mb。
(2)单任务默认内存8G,需要根据该任务的数据量灵活调整,例如128m数据,配置1G内存,yarn.scheduler.maximum-allocation-mb。
(3)mapreduce.map.memory.mb:控制分配给MapTask内存上限,如果超过会kill掉进程(报:Container is running beyond physical memory limits. Current usage:565MB of512MB physical memory used;Killing Container)。默认内存大小为1G,如果数据量是128m,正常不需要调整内存;如果数据量大于128m,可以增加MapTask内存,最大可以增加到4-5g。
(4)mapreduce.reduce.memory.mb:控制分配给ReduceTask内存上限。默认内存大小为1G,如果数据量是128m,正常不需要调整内存;如果数据量大于128m,可以增加ReduceTask内存大小为4-5g。
(5)mapreduce.map.java.opts:控制MapTask堆内存大小。(如果内存不够,报:java.lang.OutOfMemoryError)
(6)mapreduce.reduce.java.opts:控制ReduceTask堆内存大小。(如果内存不够,报:java.lang.OutOfMemoryError)
(7)可以增加MapTask的CPU核数,增加ReduceTask的CPU核数
(8)增加每个Container的CPU核数和内存大小
(9)在hdfs-site.xml文件中配置多目录
(10)NameNode有一个工作线程池,用来处理不同DataNode的并发心跳以及客户端并发的元数据操作。dfs.namenode.handler.count=20 * log2(Cluster Size),比如集群规模为10台时,此参数设置为60。