目标网站:https://tianqi.2345.com/china.htm
任务:
- 明确城市 上海闵行区, 获取当天的天气数据
- 明确城市,获取该城市未来7天的数据
- 通过输入城市,告知该城市当天的天气数据
获取当天的天气数据
"""
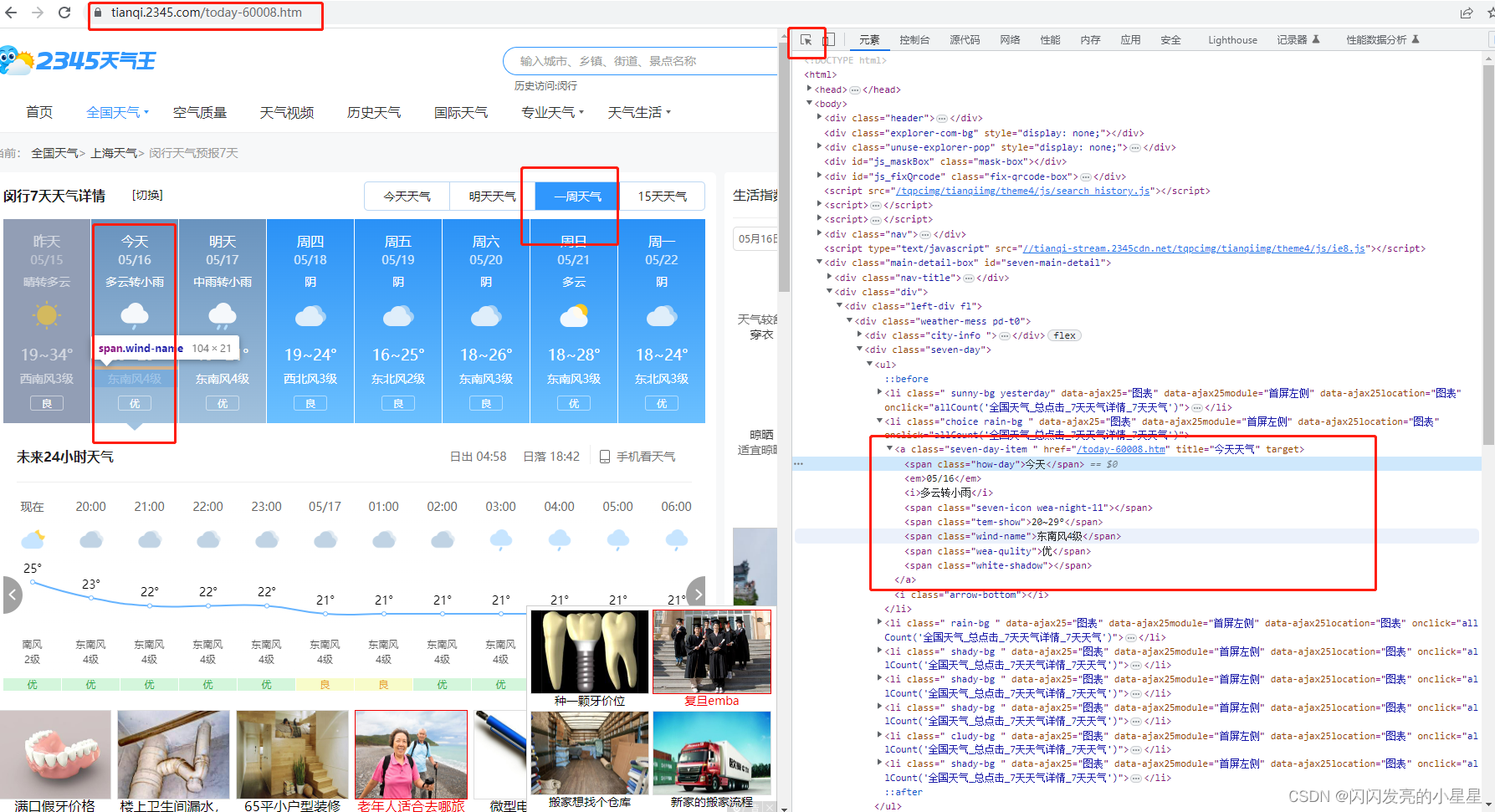
1. 获取上海市闵行区今天的天气
"""
import requests
from bs4 import BeautifulSoup
import datetime
# 1. 获取url 和 header
url = 'https://tianqi.2345.com/today-60008.htm'
header = {
'user-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36'}
response = requests.get(url=url,headers=header) # 成功,则 resonse = 200
response.encoding = 'uft-8'
bs = BeautifulSoup(response.text, 'html.parser')#这里我们用html.parser解析器
a = bs.find_all('a', href="/today-60008.htm", title="今天天气")#查找对应元素
print(a)
weather_today=a[0].text.split()
print(weather_today)
out:
[<a class="seven-day-item" href="/today-60008.htm" target="" title="今天天气">
<span class="how-day">今天</span>
<em>05/16</em>
<i>多云转小雨</i>
<span class="seven-icon wea-night-11"></span>
<span class="tem-show">20~29°</span>
<span class="wind-name">东南风4级</span>
<span class="wea-qulity">优</span>
<span class="white-shadow"></span> </a>]
['今天', '05/16', '多云转小雨', '20~29°', '东南风4级', '优']
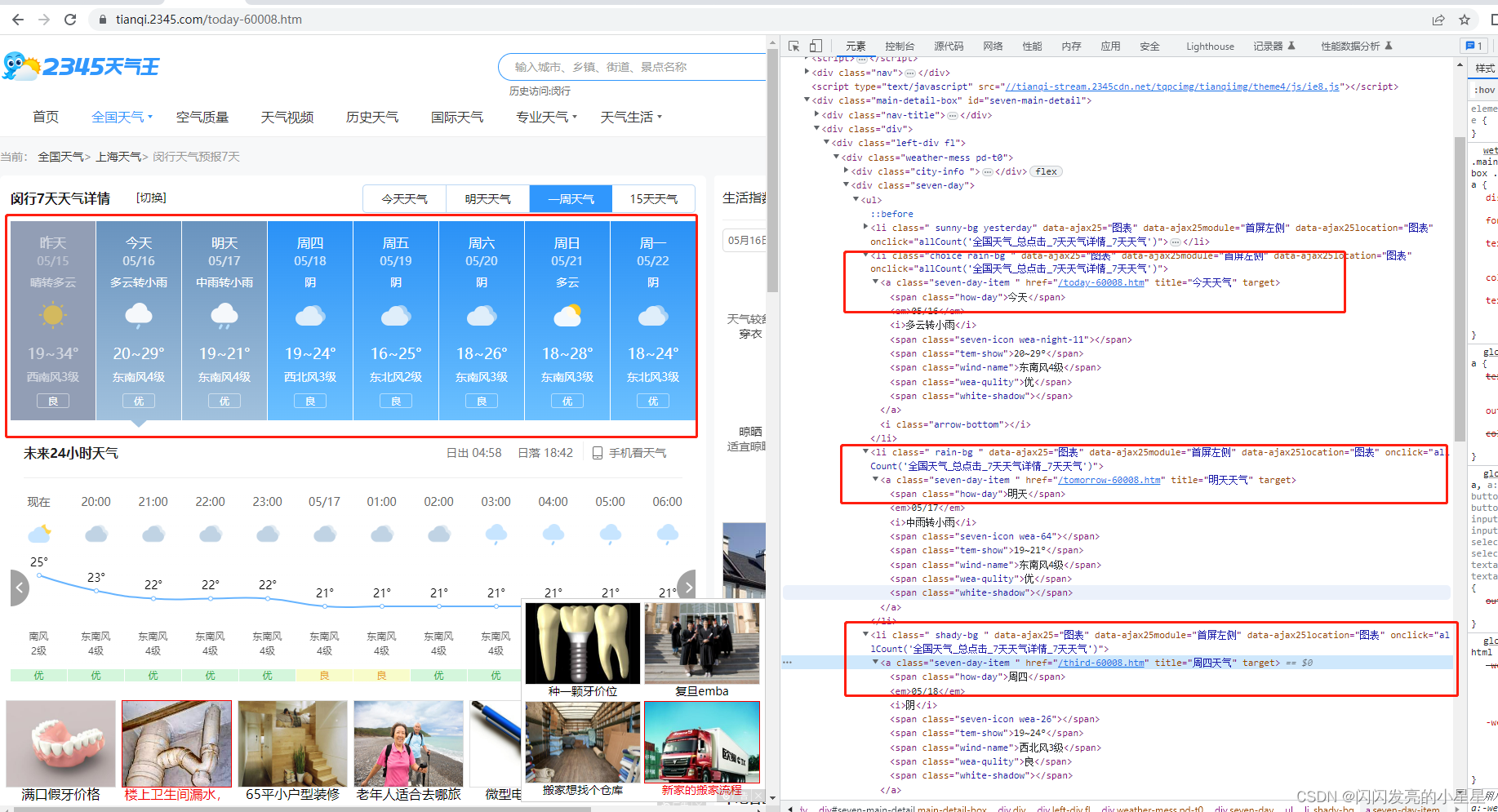
获取未来7天的数据
# -*- coding: UTF-8 -*-
"""
@Author :Xoey
@Time : 2023/5/16
"""
# 导库
import requests
from bs4 import BeautifulSoup
import datetime
import pandas as pd
url = "https://tianqi.2345.com/today-59289.htm"
header = {
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; Media Center PC 6.0; InfoPath.2; MS-RTC LM 8'
}
response = requests.get(url=url, headers=header)#增加headers参数,简单伪装UA
response.encoding = "utf-8"
bs = BeautifulSoup(response.text, 'html.parser')#这里我们用html.parser解析器
weekday = ["周一天气","周二天气","周三天气","周四天气","周五天气","周六天气","周日天气"]
href = ["/today-59289.htm", "/tomorrow-59289.htm",
"/third-59289.htm", "/fourth-59289.htm", "/fifth-59289.htm", "/sixth-59289.htm", "/seventh-59289.htm"]
weekday[int(datetime.datetime.now().weekday())]='今天天气'
weekday[int(datetime.datetime.now().weekday())+1]='明天天气' # 与网页上的星期参数对应上
print(weekday)
w=[]
day=[] # 周几
data=[] # 日期
wea=[] # 天气情况
tem=[] #温度
wind = [] # 风
quality=[] # 空气质量
n = int(datetime.datetime.now().weekday()) # 今天是星期几
for i in range(int(len(href))):
w= bs.find_all('a', href=href[i], title=weekday[int((n+i)%7)])#查找对应元素,ps:3数值不定
#print(w)
w = w[0].text.split()
day.append(w[0])
data.append(w[1])
wea.append(w[2])
tem.append(w[3])
wind.append(w[4])
quality.append(w[5])
datas=pd.DataFrame({
'日期':data,'星期':day,'温度':tem,'天气':wea,'风向':wind,'空气质量':quality})
datas.to_csv('7天天气数据.csv',encoding='utf-8')
print(datas)
out:
['周一天气', '今天天气', '明天天气', '周四天气', '周五天气', '周六天气', '周日天气']
日期 星期 温度 天气 风向 空气质量
0 05/16 今天 24~29° 雾转多云 东南风3级 优
1 05/17 明天 25~30° 雷阵雨转阵雨 南风3级 良
2 05/18 周四 26~31° 雷阵雨转阵雨 西南风2级 良
3 05/19 周五 25~31° 阵雨转阴 西南风2级 良
4 05/20 周六 25~31° 多云 南风3级 良
5 05/21 周日 26~32° 多云 南风3级 优
6 05/22 周一 25~32° 多云 南风3级 优
输入城市,输出该城市今日的天气数据
import requests
from bs4 import BeautifulSoup
import datetime
timecity = input("请设置地点,省份+市+地区,如广东,东莞\n")
timecity = timecity.split(',')
#向主网发送请求
url = "https://tianqi.2345.com/china.htm"
header = {
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; Media Center PC 6.0; InfoPath.2; MS-RTC LM 8'
}
def Re():
global bs
response = requests.get(url=url, headers=header)
response.encoding = "utf-8"
bs = BeautifulSoup(response.text, 'html.parser')
Re()
weathercity1 = bs.find_all('a', title=timecity[0]+"天气")
url = "https://tianqi.2345.com/"+weathercity1[0].get("href") # 通过get("href")获取子网页的地址,跳转到下一页
Re()
weathercity2 = bs.find_all('a', title=timecity[1]+"天气")
weathercity2 = weathercity2[0].get("href").split("/")
del(weathercity2[:2])
url = "https://tianqi.2345.com/today-"+weathercity2[0] # 这是7天的数据url,通过观察页面url的规律,总结url的形式。
header = {
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; Media Center PC 6.0; InfoPath.2; MS-RTC LM 8'
}
Re()
weekday = ["周一天气", "周二天气", "周三天气", "周四天气", "周五天气", "周六天气", "周日天气"]
weekday[int(datetime.datetime.now().weekday())] = "今天天气"
try:
weekday[int(datetime.datetime.now().weekday())+1] = "明天天气"
except IndexError:
weekday[0] = "明天天气"
href = ["/today-"+weathercity2[0], "/tomorrow-"+weathercity2[0],
"/third-"+weathercity2[0], "/fourth-"+weathercity2[0], "/fifth-"+weathercity2[0], "/sixth-"+weathercity2[0], "/seventh-"+weathercity2[0]]
a = input("哪一天的天气,如:今天天气\n")
b = weekday.index(a)
c = weekday.index("今天天气")#y以此天为标准
Weather = bs.find_all('a', href=href[b-c], title=a)
Weather = ' '.join(Weather[0].text.split())
print(Weather)
out:
请设置地点,省份+市+地区,如广东,东莞
江苏,南京
哪一天的天气,如:今天天气
今天天气
今天 05/16 多云转雷阵雨 22~31° 南风2级 良
关键:通过get(“href”)获得下一个目标页的url。
参考:
爬虫实例八:爬取天气预报数据,并实现数据可视化
python:爬虫爬取中国天气网
使用python爬取天气信息(包括历史天气数据)