以下代码可以用于以下场景:
- 在Web开发中,获取网页中的Title内容,以用于页面SEO。
- 在数据挖掘和分析中,获取包含Title信息的HTML页面,以进行进一步的文本处理和分析。
- 在一些需要从HTML源代码中获取元数据的应用中,例如爬虫程序、自动化测试等。
- 在开发中,可以使用该代码作为一个小工具来提取HTML页面中的Title信息,以便于后续的开发工作。
- 该代码也可以作为Python和wxPython的教学资源,供初学者参考学习。
D:\spiderdocs\youtubetitlespider.py
源代码:
import wx
import re
import pyperclip
class TitleFrame(wx.Frame):
def __init__(self):
wx.Frame.__init__(self, None, title="Title Extractor", size=(400, 200))
# 创建面板
panel = wx.Panel(self)
# 创建文本框
self.text_ctrl = wx.TextCtrl(panel, pos=(5, 5), size=(385, 30))
# 创建“生成”按钮
generate_button = wx.Button(panel, label='生成', pos=(5, 40))
generate_button.Bind(wx.EVT_BUTTON, self.generate_title)
# 创建文本框
self.result_text_ctrl = wx.TextCtrl(panel, pos=(5, 80), size=(385, 30), style=wx.TE_READONLY)
# 创建“复制”按钮
copy_button = wx.Button(panel, label='复制', pos=(5, 120))
copy_button.Bind(wx.EVT_BUTTON, self.copy_to_clipboard)
def generate_title(self, event):
# 获取输入的源字符串
source_string = self.text_ctrl.GetValue()
# 使用正则表达式查找title的内容
match = re.search(r'title=\"(.*?)\"', source_string)
# 检查是否找到
if match:
title = match.group(1)
self.result_text_ctrl.SetValue(title)
else:
self.result_text_ctrl.SetValue("未找到title内容")
def copy_to_clipboard(self, event):
# 获取文本框中的内容
title = self.result_text_ctrl.GetValue()
# 将内容复制到剪贴板中
pyperclip.copy(title)
if __name__ == '__main__':
app = wx.App()
frame = TitleFrame()
frame.Show()
app.MainLoop()源代码解释:
import wx、import re、import pyperclip分别导入wxPython、正则表达式和剪贴板操作的模块。class TitleFrame(wx.Frame):定义了一个名为TitleFrame的类,继承自wx.Frame类,该类表示整个程序的主窗口。def __init__(self):是TitleFrame类的构造函数,创建了主框架、面板、文本框、按钮等各个组件,并将它们按照一定的布局放置在主面板上。generate_title方法是“生成”按钮的回调函数,其中使用self.text_ctrl.GetValue()获取输入的源字符串,然后使用正则表达式re.search(r'title=\"(.*?)\"', source_string)在源字符串中查找符合规则的title内容,并将结果存储在变量match中。如果找到了title内容,则使用match.group(1)获取匹配到的内容,并将其设置为结果文本框的值,否则在结果文本框中显示“未找到title内容”。copy_to_clipboard方法是“复制”按钮的回调函数,其中使用self.result_text_ctrl.GetValue()获取结果文本框中的值,并使用pyperclip.copy()将其复制到剪贴板中。if __name__ == '__main__':是Python的内置语法,表示这段代码只有在作为主程序运行时才会执行。在这里,创建了一个wx.App对象和一个TitleFrame对象,并调用MainLoop()方法来启动应用程序的事件循环,即等待用户的交互事件。- 整个代码实现了一个基于wxPython和正则表达式的小工具,可以从HTML源代码中提取Title信息,并将结果复制到剪贴板中。程序界面简单直观,操作方便。
用法:
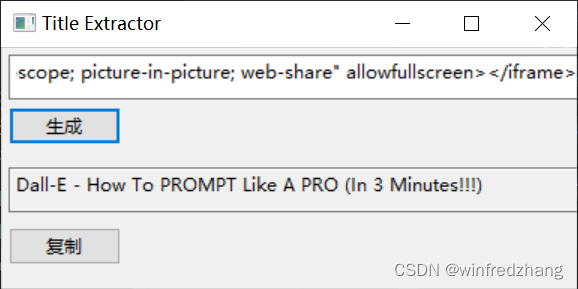
使用这个小工具非常简单,具体步骤如下:
- 运行Python程序,程序界面会弹出一个窗口。
- 在窗口中的文本框中输入需要提取Title信息的HTML页面源代码,可以从浏览器中查看页面源代码并复制粘贴到文本框中。
- 点击“生成”按钮,在结果文本框中会显示提取到的Title信息。
- 如果未能找到Title信息,则在结果文本框中会显示“未找到title内容”。
- 如果需要将提取到的Title信息复制到剪贴板中,可以点击“复制”按钮,程序会自动将其复制到剪贴板中,可以在其他应用程序中粘贴使用。