一.流程控制
1.if判断
基本语法:
if [ 条件判断式 ]
then
程序
elif [ 条件判断式 ]
then
程序
else
程序
fi
注意事项:
- ①[ 条件判断式 ],中括号和条件判断式之间必须有空格
- ②if 后要有空格
例如,现在写一个if.sh脚本文件
#!/bin/bash
if [ $1 -eq 1 ]
then
echo "CSDN @ 终究还是散了"
elif [ $1 -eq 2 ]
then
echo "博客园 @ 挽留岁月挽留你"
fi
2.case语句
基本语法:
case $变量名 in
"值 1")
如果变量的值等于值 1,则执行程序 1
;;
"值 2")
如果变量的值等于值 2,则执行程序 2
;;
…省略其他分支…
*)
如果变量的值都不是以上的值,则执行此程序
;;
esac
注意事项:
- (1)case 行尾必须为单词“in”,每一个模式匹配必须以右括号“)”结束。
- (2)双分号“;;”表示命令序列结束,相当于C语言中的 break。
- (3)最后的“*)”表示默认模式,相当于 C语言中的 default。
例如,现在写一个case.sh文件:
#!/bin.bash
case $1 in
"1")
echo "CSDN@终究还是散了"
;;
"2")
echo "博客园@挽留岁月挽留你"
;;
*)
echo "CSDN666"
esac
3.for循环
基本语法1:
for (( 初始值;循环控制条件;变量变化 ))
do
程序
done
例如:
#!/bin/bash
sum=0
for((i=0;i<=100;i++))
do
sum=$[$sum+$i]
done
echo $sum
基本语法2:
for 变量 in 值 1 值 2 值 3…
do
程序
done
例如:
#!/bin/bash
#输出每个变量
for i in CSDN IOT KUST
do
echo "I love $i"
done
4.while循环
基本语法:
while [ 条件判断式 ]
do
程序
done
例如:
#!/bin/bash
i=0
sum=0
while (( i < 5 ))
do
echo $i
i=$((i+1))
done
5.演示
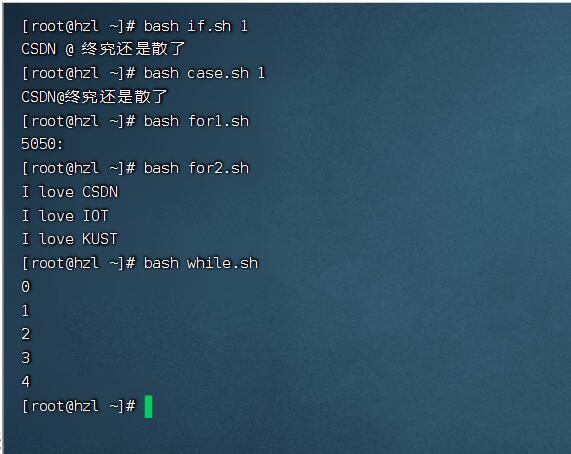
二.函数
1.basename
作用:取路径里的文件名
语法:basename string [suffix]
其中,string 表示要获取文件名的路径字符串,可以是绝对路径或相对路径;suffix 则是一个可选参数,表示要去除的后缀部分。如果 string 不包含目录分隔符,则命令返回整个路径,否则返回最后一个目录分隔符之后的部分作为文件名。
以下是一些 basename() 函数的示例:
$ basename /var/www/html/index.php
index.php
$ basename uploads/images/avatar.jpg .jpg
avatar
2.dirname
语法:dirname 文件绝对路径
作用:从给定的包含绝对路径的文件名中去除文件名(非目录的部分),然后返回剩下的路径(目录的部分)
其中,string 表示要获取目录部分的文件路径字符串,可以是绝对路径或相对路径。命令返回 string 中最后一个斜杠 / 之前的部分作为目录名。
以下是 dirname 命令的示例:
$ dirname /var/www/html/index.php
/var/www/html
$ dirname uploads/images/avatar.jpg
uploads/images
3.自定义函数
基本语法:
[ function ] funname[()]
{
Action;
[return int;]
}
- (1)必须在调用函数地方之前,先声明函数,shell 脚本是逐行运行。不会像其它语言一
样先编译。 - (2)函数返回值,只能通过$?系统变量获得,可以显示加:return 返回,如果不加,将
以最后一条命令运行结果,作为返回值。return 后跟数值 n(0-255)
下面是一个自定义函数的例子:
#!/bin/bash
function sum()
{
s=0
s=$[$1+$2]
echo "$s"
}
read -p "Please input the number1: " n1;
read -p "Please input the number2: " n2;
sum $n1 $n2;
计算两个输入参数的和。
三.正则表达式
正则表达式使用单个字符串来描述、匹配一系列符合某个语法规则的字符串。在很多文
本编辑器里,正则表达式通常被用来检索、替换那些符合某个模式的文本。在 Linux 中,grep,
sed,awk 等文本处理工具都支持通过正则表达式进行模式匹配。
1.常规匹配
常规匹配我们之前就接触过,比如在 grep命令 中我们使用grep命令和管道符| 进行匹配搜索,就是常规匹配的方法。
2.匹配字符
以下是常见的 POSIX 正则表达式特殊字符和元字符的列表:
.:表示匹配任意一个字符。*:表示匹配前面的字符 0 次或多次。+:表示匹配前面的字符 1 次或多次。?:表示匹配前面的字符 0 次或 1 次。|:表示匹配两个或多个规则之一。[ ]:表示匹配一个字符集合中的任意一个字符。\:用于转义后面的字符。^:表示匹配输入字符串的开始位置。$:表示匹配输入字符串的结束位置。
以下是 POSIX 正则表达式中一些特殊字符和元字符的举例:
.:表示匹配任意一个字符。例如,a.c可以匹配 “abc”、“adc”、“aec” 等等,其中.可以匹配任意一个字符。*:表示匹配前面的字符 0 次或多次。例如,a*b可以匹配 “ab”、“aab”、“aaab” 等等,其中*匹配前面的字符a零个或多个。+:表示匹配前面的字符 1 次或多次。例如,a+b可以匹配 “ab”、“aab”、“aaab” 等等,其中+匹配前面的字符a至少一次。?:表示匹配前面的字符 0 次或 1 次。例如,a?b可以匹配 “ab” 和 “b”,其中?匹配前面的字符a零次或一次。|:表示匹配两个或多个规则之一。例如,apple|banana可以匹配 “apple” 或 “banana” 中的任意一个。[ ]:表示匹配一个字符集合中的任意一个字符。例如,[aeiou]可以匹配所有的元音字母,即 a、e、i、o、u 中的任意一个。\:用于转义后面的字符。例如,\.可以匹配字符串中的点号 “.”,其中 “” 将 “.” 转义为普通字符。^:表示匹配输入字符串的开始位置。例如,^abc可以匹配以 “abc” 开始的字符串。$:表示匹配输入字符串的结束位置。例如,abc$可以匹配以 “abc” 结尾的字符串。
需要注意的是,在使用正则表达式时,应该根据实际情况选用合适的正则表达式引擎和匹配模式,以获得最佳的性能和匹配结果。
我们这里只掌握基础常规的正则表达式即可。
四.文本处理工具
1.cut
在shell中,cut命令用于从文本文件或标准输入中剪切指定字段。它通常与其他命令一起使用,例如grep和sort。
cut命令的基本语法如下:
cut [OPTIONS] [FILE]
其中,OPTIONS是用于指定需要剪切的字段、定界符等选项的参数,FILE是输入文件的名称或者表示标准输入的破折号“-”。
以下是一些常用的cut命令选项:
- -c:按字符位置剪切字段。
- -f:按字段分隔符剪切字段。
- -d:指定字段分隔符,默认为制表符。
- –complement:剪切除指定字段以外的所有字段。
例如,要将文件file.txt中每行的第2个和第4个字符提取出来,可以使用如下命令:
cut -c 2,4 file.txt
如果要将文件file.txt中以冒号作为字段分隔符的第2个和第3个字段提取出来,可以使用如下命令:
cut -d : -f 2,3 file.txt
选取系统 PATH 变量值,第 2 个“:”开始后的所有路径:
echo $PATH
/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/home/atguigu/.local/bin:/
home/atguigu/bin
echo $PATH | cut -d ":" -f 3-
/usr/local/sbin:/usr/sbin:/home/atguigu/.local/bin:/home/atguigu/bin
注意,cut命令只能处理文本文件,不能用于二进制文件或其他非文本文件。
2.awk
awk是一种用于处理文本文件的强大命令行工具。它可以根据一定的规则(通常是一个模式和一个动作组合)从输入文本中抽取数据或进行操作,并将结果输出到标准输出或文件中。
awk命令的最基本形式如下:
awk 'pattern {action}' filename
其中,pattern表示需要匹配的模式,可以是正则表达式或字符串;action表示当模式匹配时要执行的动作,可以是任意有效的awk命令;filename表示要处理的文件名,也可以用管道符“|”将另一个命令的输出作为awk的输入。
-
选项“-F”指定字段分隔符,默认是空格或制表符。例如,“-F:”表示以冒号为字段分隔符。
-
选项“-v”用于定义变量值。例如,“-v x=10”表示定义变量x的值为10。
-
pattern:表示 awk 在数据中查找的内容,就是匹配模式(正则表达式)
-
action:在找到匹配内容时所执行的一系列命令
搜索 passwd 文件以 root 关键字开头的所有行,并输出该行的第 7 列:
awk -F : '/^root/{print $7}' passwd
匹配模式通常是正则表达式,而正则表达式必须用 / 括起来,以指示中间内容为正则表达式。
只显示/etc/passwd 的第一列和第七列,以逗号分割,且在所有行前面添加列名 user,
shell 在最后一行添加"CSDN,/bin/csdn"
awk -F : 'BEGIN{print "user, shell"} {print $1","$7}
END{print "CSDN,/bin/csdn"}' passwd
注意:BEGIN 在所有数据读取行之前执行;END 在所有数据执行之后执行。这个例子里面没有匹配模式。
awk的内置变量:
| 变量 | 说明 |
|---|---|
| FILENAME | 文件名 |
| NR | 已读的记录数(行号) |
| NF | 浏览记录的域 的个数(切割后,列的个数) |
统计 passwd 文件名,每行的行号,每行的列数:
awk -F : '{print "filename:" FILENAME ",linenum:"NR ",col:"NF}' passwd
五.综合应用:归档文件
实际生产应用中,往往需要对重要数据进行归档备份。
需求:实现一个每天对指定目录归档备份的脚本,输入一个目录名称(末尾不带/),将目录下所有文件按天归档保存,并将归档日期附加在归档文件名上,放在/root/archive 下。
这里用到了归档命令:tar,后面可以加上-c 选项表示归档,加上-z 选项表示同时进行压缩,得到的文件后缀名为.tar.gz。
以下是一个示例shell脚本实现:
bashCopy Code#!/bin/bash
# 获取输入的目录名
directory=$1
# 格式化当前日期,例如:20230501
date=$(date +%Y%m%d)
# 如果目录不存在则退出脚本
if [ ! -d $directory ]; then
echo "目录不存在"
exit 1
fi
# 将目录下的所有文件按天归档保存到/root/archive目录下
tar -czvf /root/archive/"$directory"_"$date".tar.gz $directory/*
echo "归档完成"
使用方法:
- 将以上代码复制到一个名为
backup.sh的文件中,并将其放置在可执行路径下。 - 在终端中进入想要备份的目录所在的路径。
- 运行
backup.sh 目录名称命令即可进行备份。
备注:以上实现方式并不完整或者不够健壮,还需要根据具体需求进行修改和优化。
六.说明
新星计划:Linux运维@刘晨阳导师创作打卡5!