【Kafka】Linux下搭建kafka服务,完整学习代码案例
(一)Kafka架构基础
【1】图解kafka是什么?
(1)为什么需要消息队列
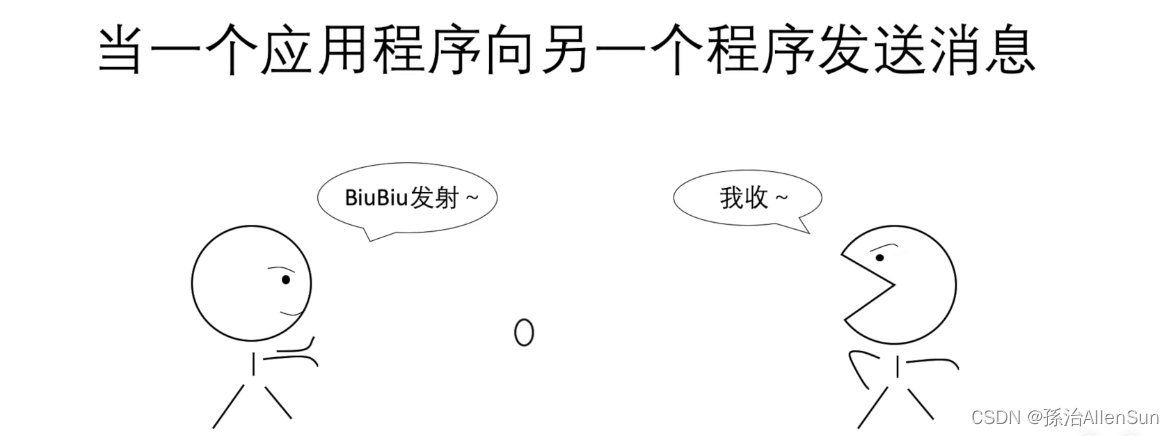
当一个程序向另一个程序发送消息的时候,可以一对一直接发送
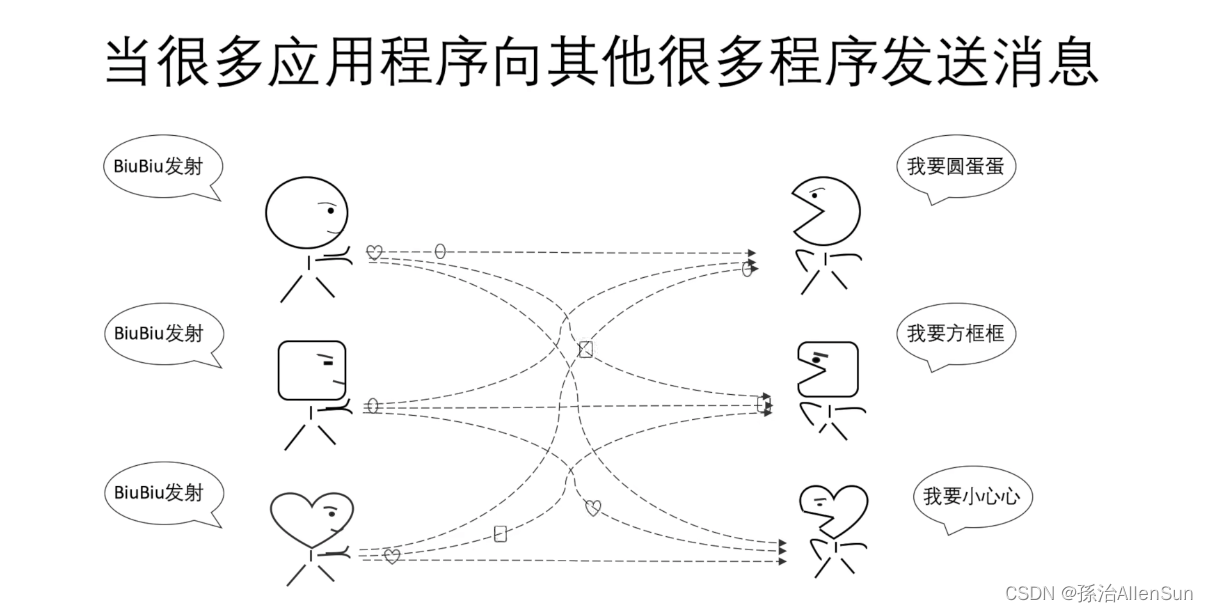
当出现越来越多的程序和通讯链路,可以发现这种模式的缺点
1-团队之间可能进行着重复的工作,会造成资源的浪费
2-当信息过多无法实现及时的同步时,会造成信息的丢失
3-各个程序之间直接通讯,耦合度太高了,可能会牵一发而动全身
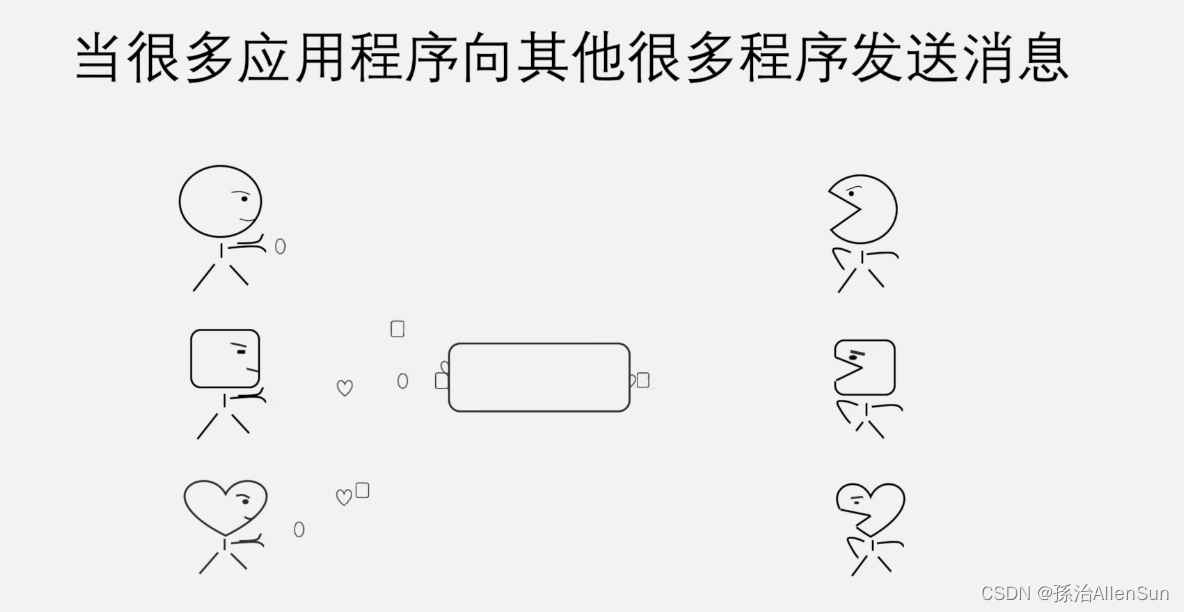
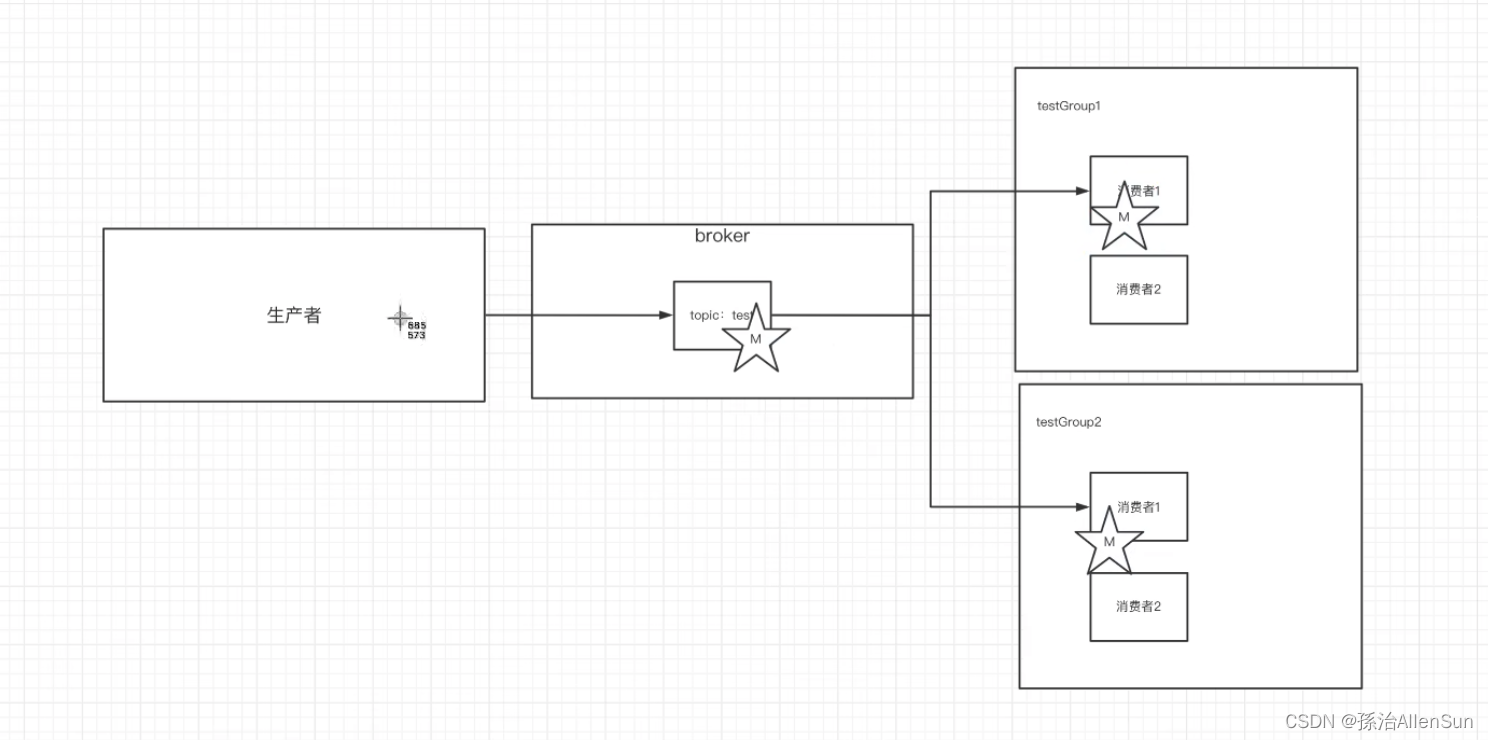
kafka可以接收不同生产者的消息,然后由不同的消费者来订阅这些消息供自己使用
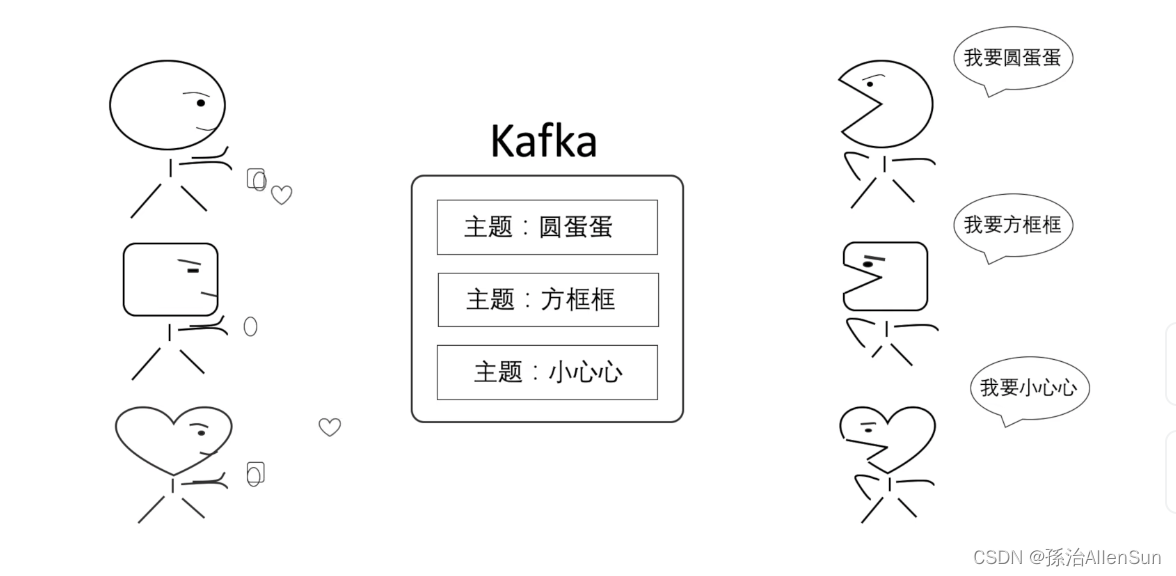
(2)Topic主题
那么消费者怎么能保证自己拿到想要的消息呢?这里就要用到Topic主题
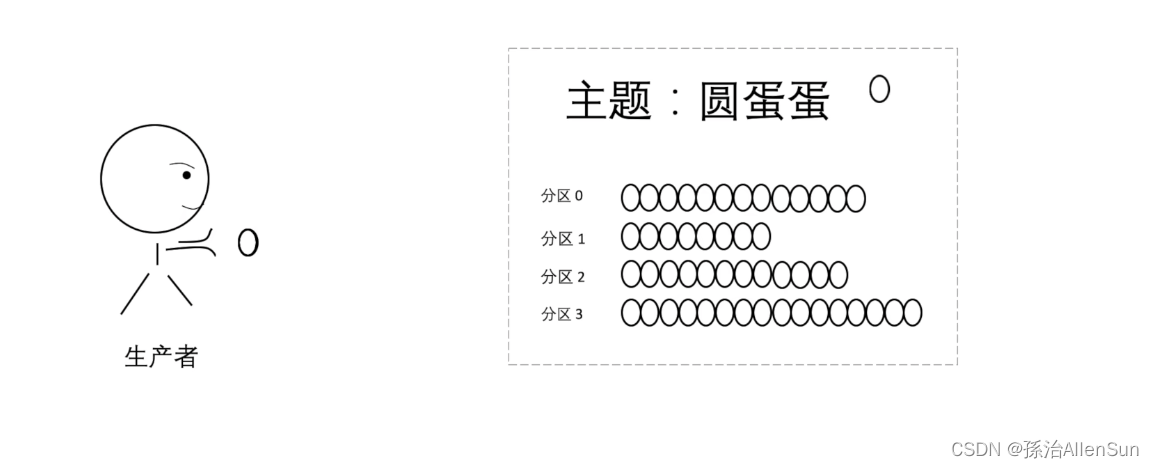
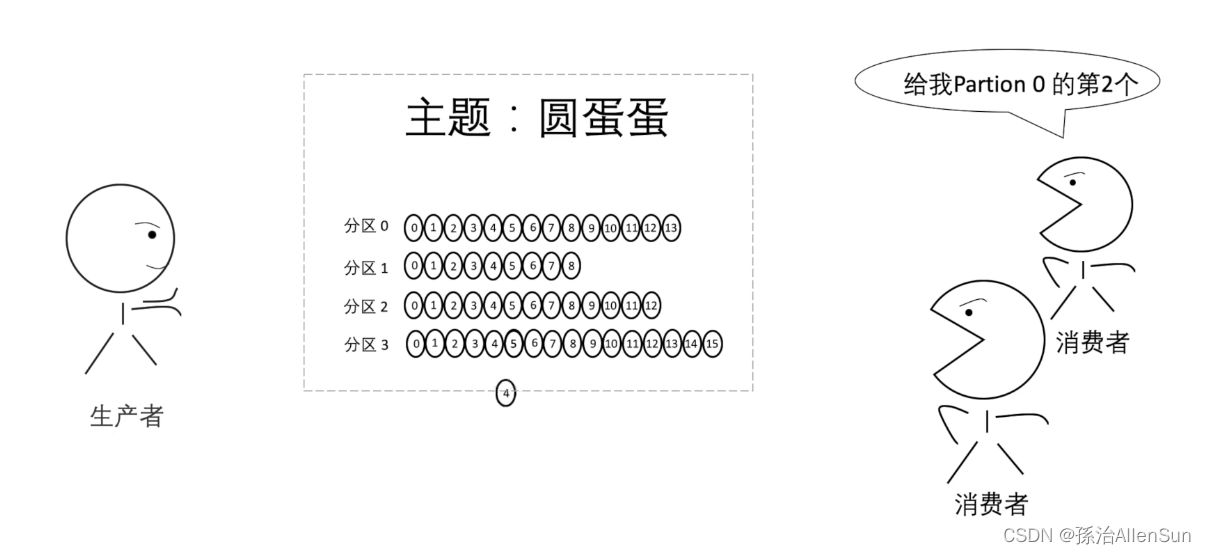
(3)分区
分区概念,一个主题里可能包含多个分区,分区可以分布在不同的服务器上,这样一个主题也就可以分布在多个服务器上了,
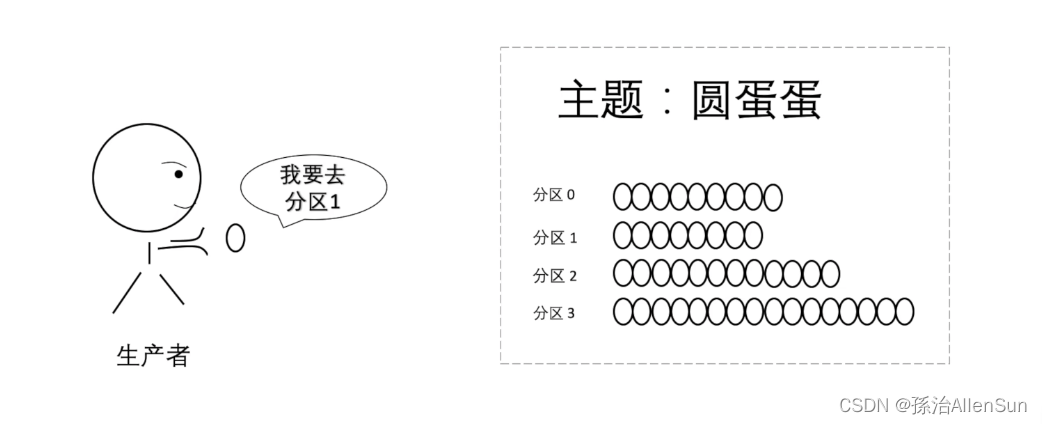
生产者会把消息放入对应主题的对应分区中,生产者怎么知道哪个消息该放入哪个分区呢?分两种情况:
(1)生产者指定了分区
(2)生产者没有指定分区
分区器会根据键key来决定消息的去处
键可以看做是一个标记,每个值都会对应一个标记
分区器可以看做是一个算法,输入值是键,输出值是该去哪个分区
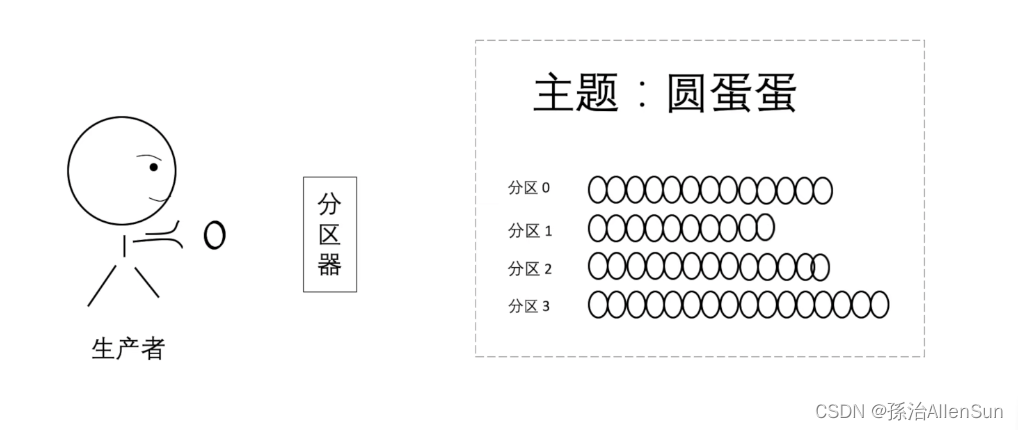
那么一个消息要包含一下这些部分:主题、分区、键、值。这样一个消息才能找到自己对应要去的去处
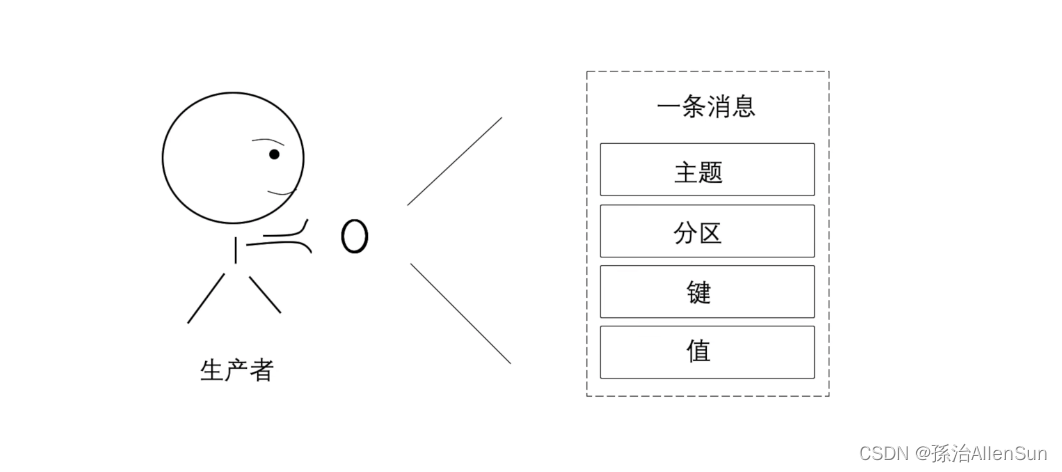
(4)消费者读取数据(偏移量)
那么接下来消费者要怎么读取数据呢?
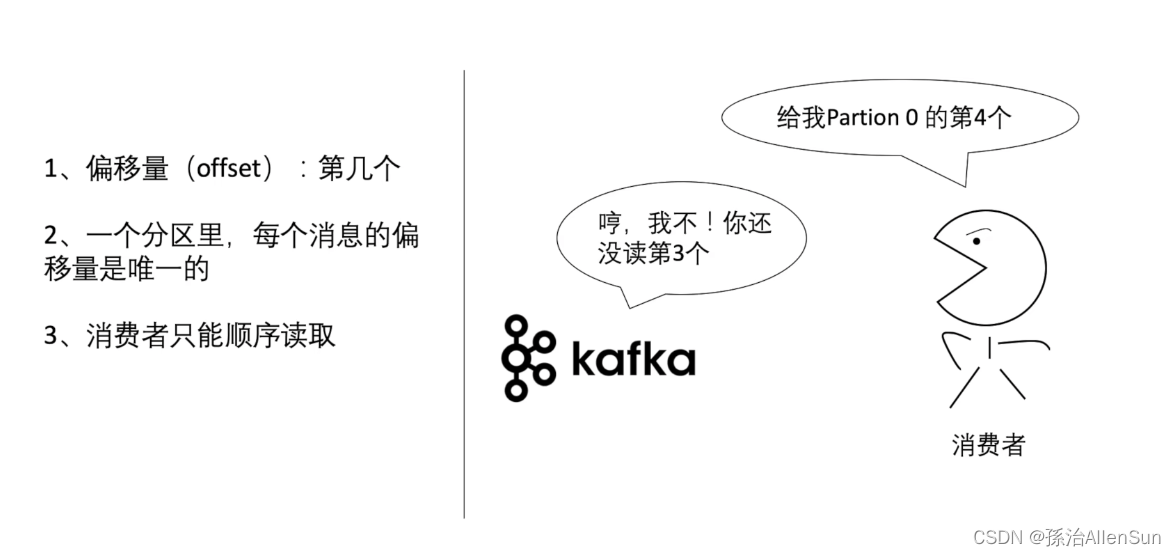
引入一个概念:偏移量(也就是第几个的意思)
偏移量在写入的时候就已经定好了,消费者在读取数据的时候都是根据偏移量来读取数据的
1-偏移量(offset):第几个
2-一个分区里,每个消息的偏移量是唯一的
3-消费者只能顺序读取
(5)kafka集群
上面一个独立的kafka服务器也就是一个broker
一个broker里可以有多个主题,一个主题里又可以有多个分区
broker接收来自生产者的消息,为每个消息设置相应的偏移量,然后把消息保存到磁盘里
broker响应消费者的请求
 多个broker就会组成kafka的集群,保证项目的安全,一个宕机另一个可以补上
多个broker就会组成kafka的集群,保证项目的安全,一个宕机另一个可以补上

【2】kafka的使用场景
(1)日志追踪
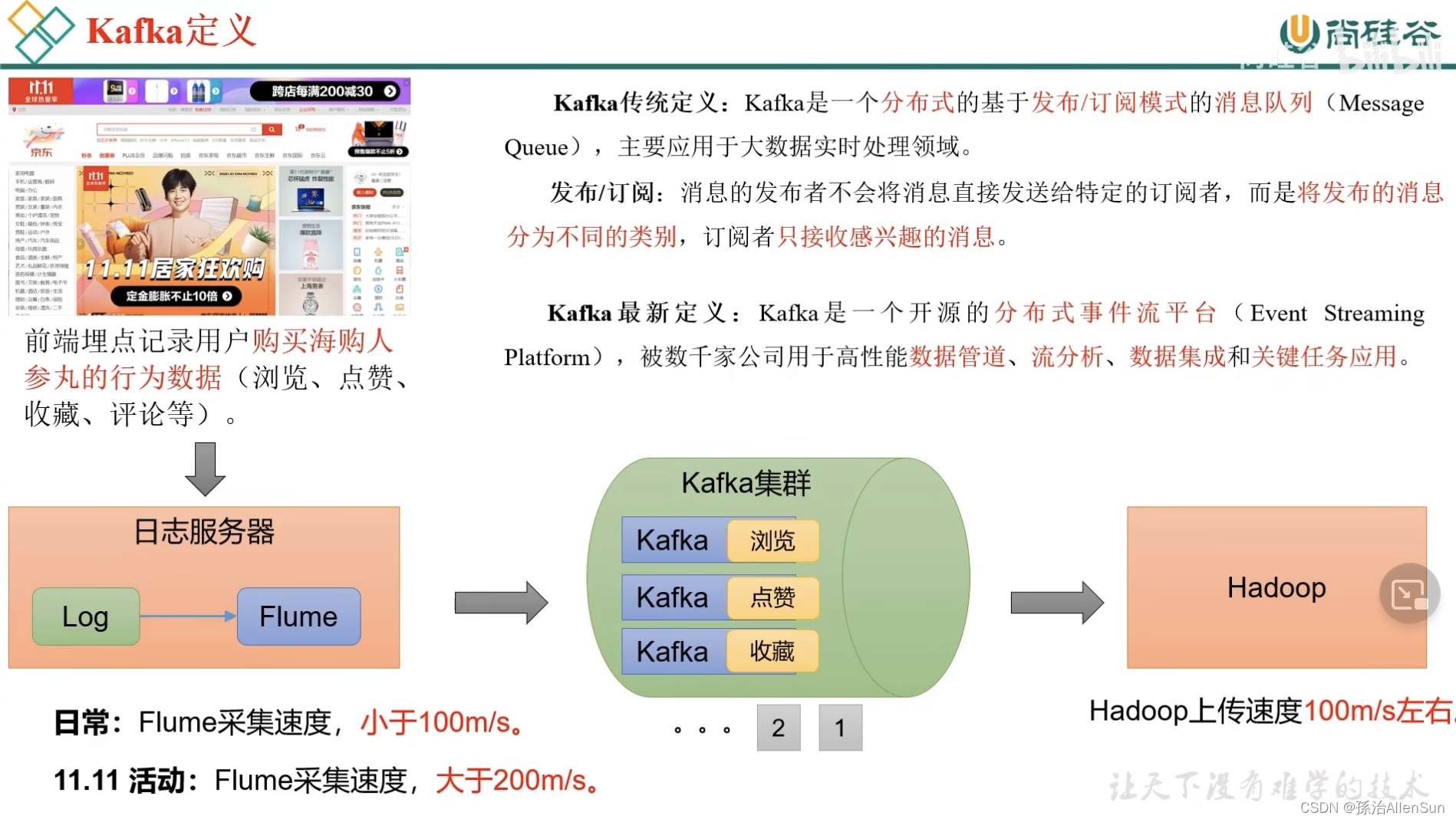
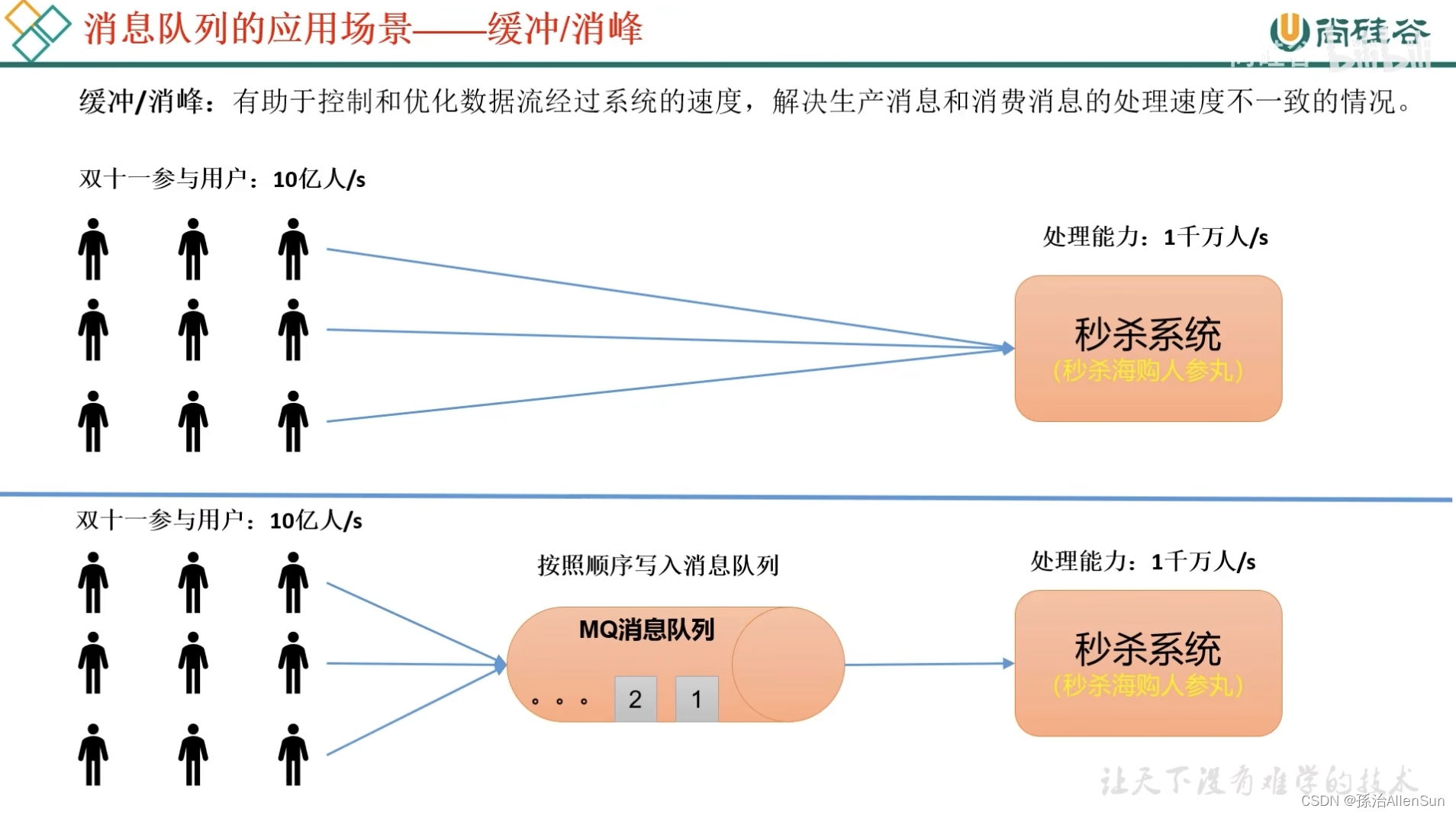
(2)缓冲、削峰
(3)解耦

(4)异步通信

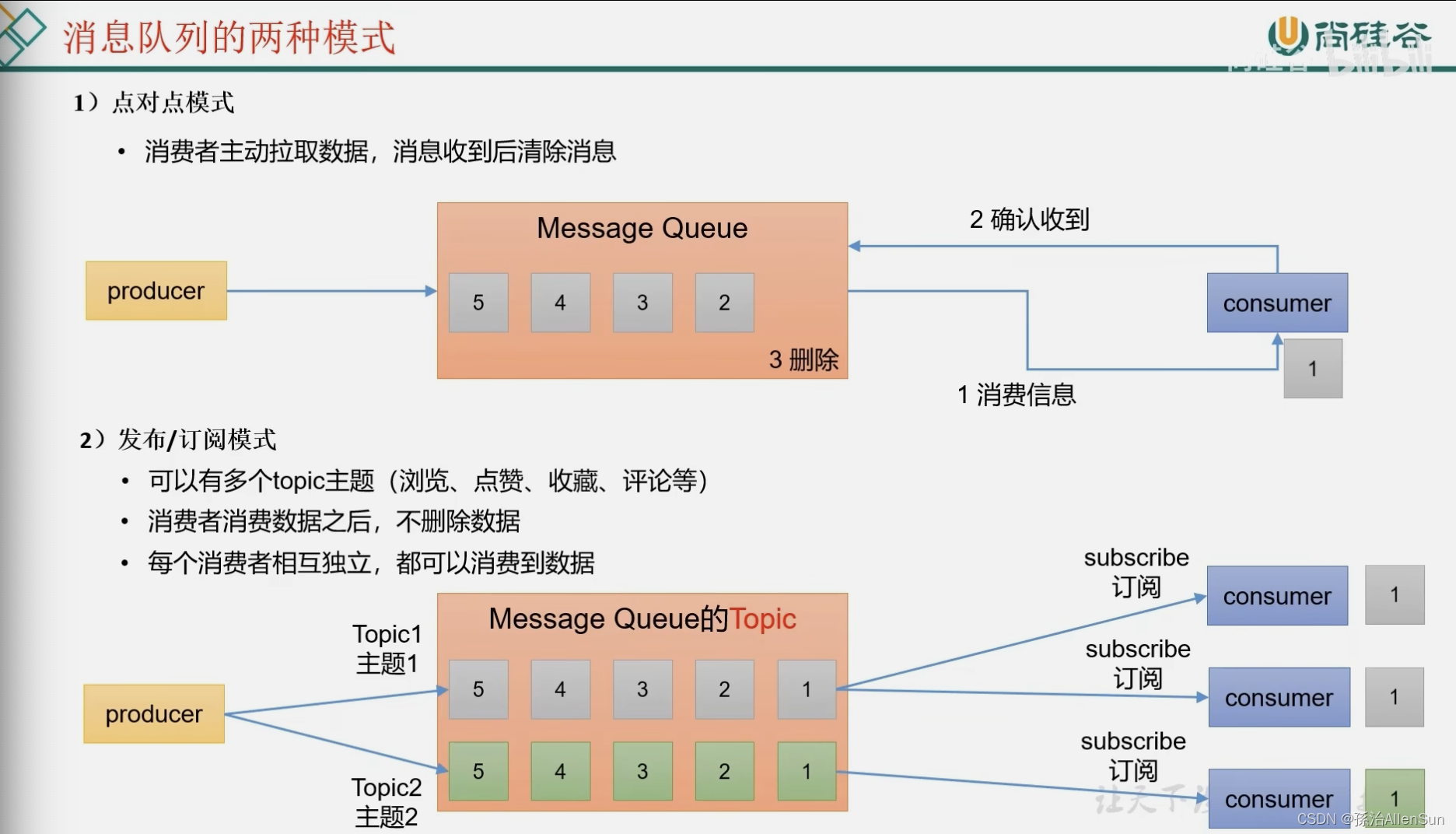
【3】消息队列的两种模式
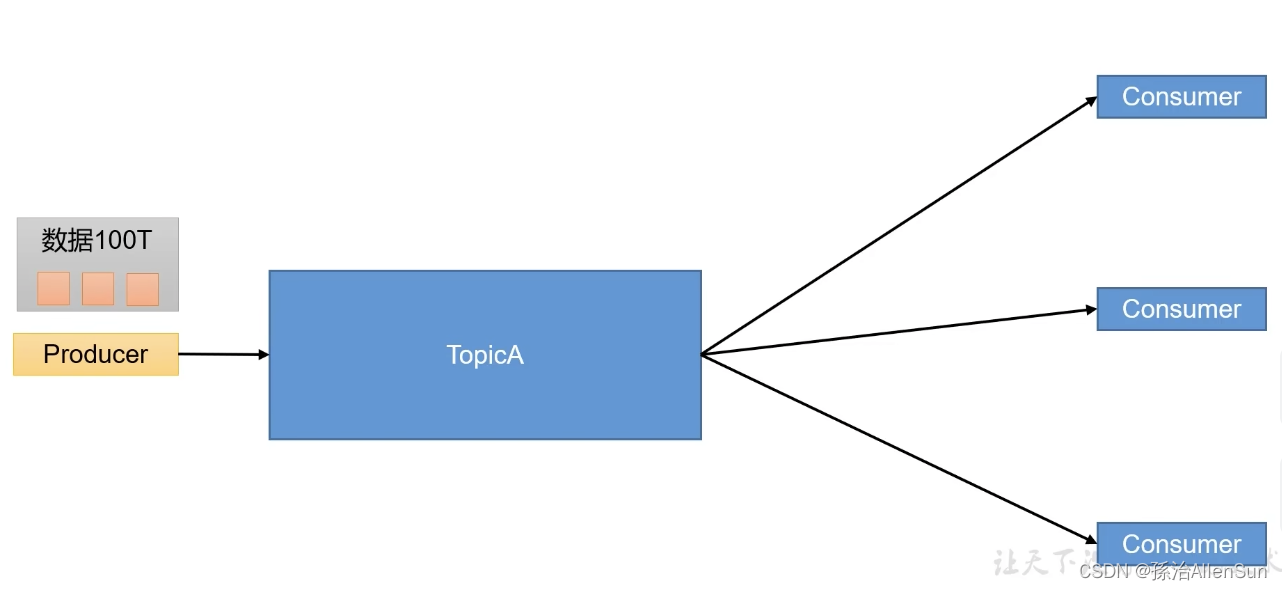
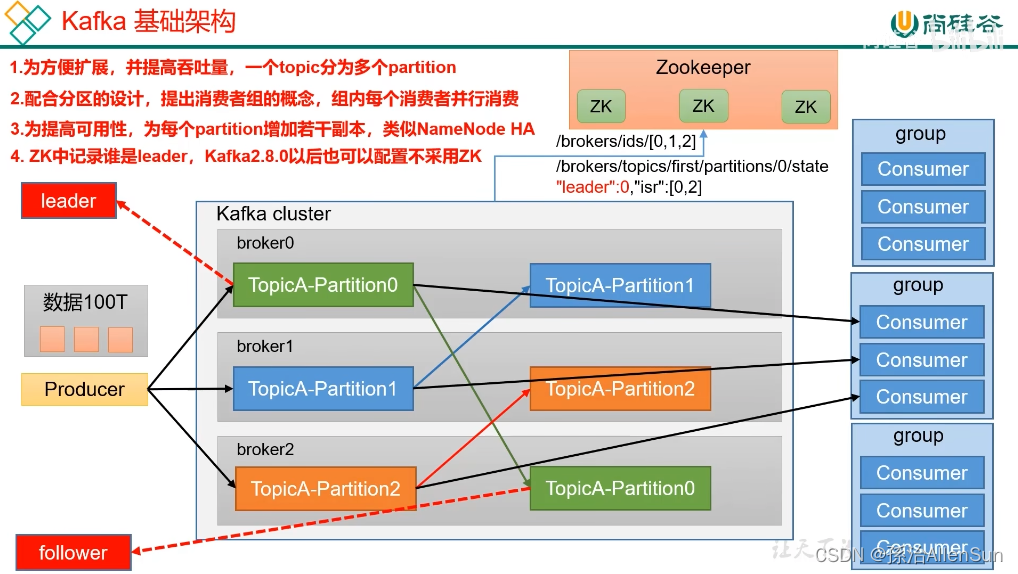
【4】kafka的基础架构
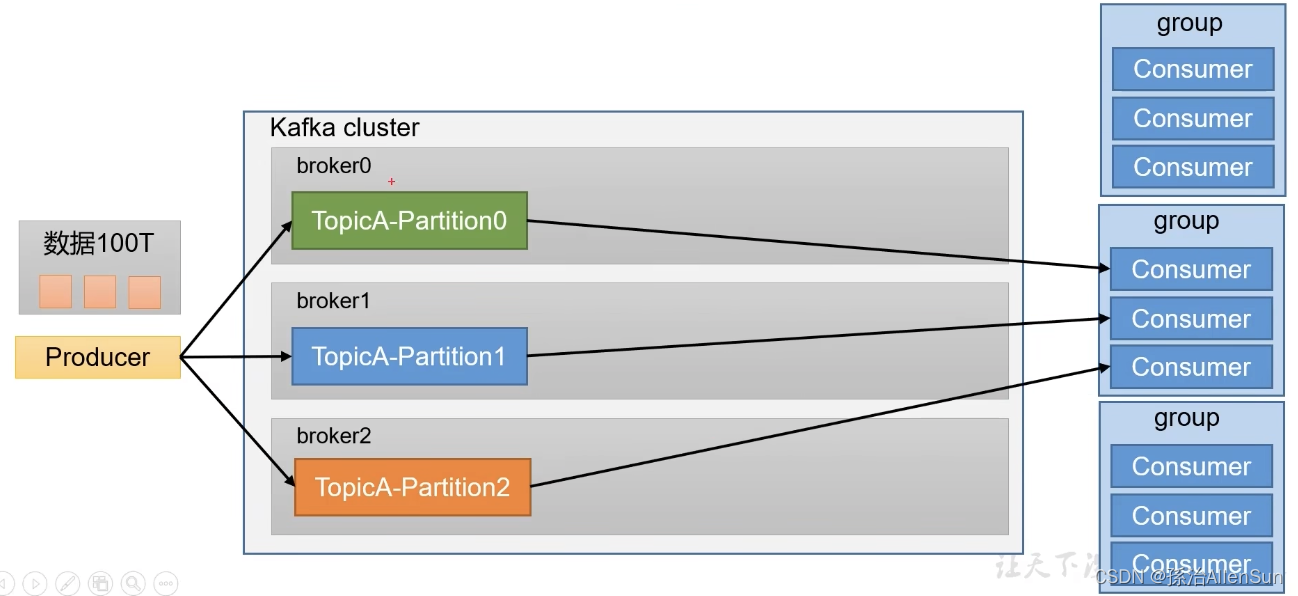
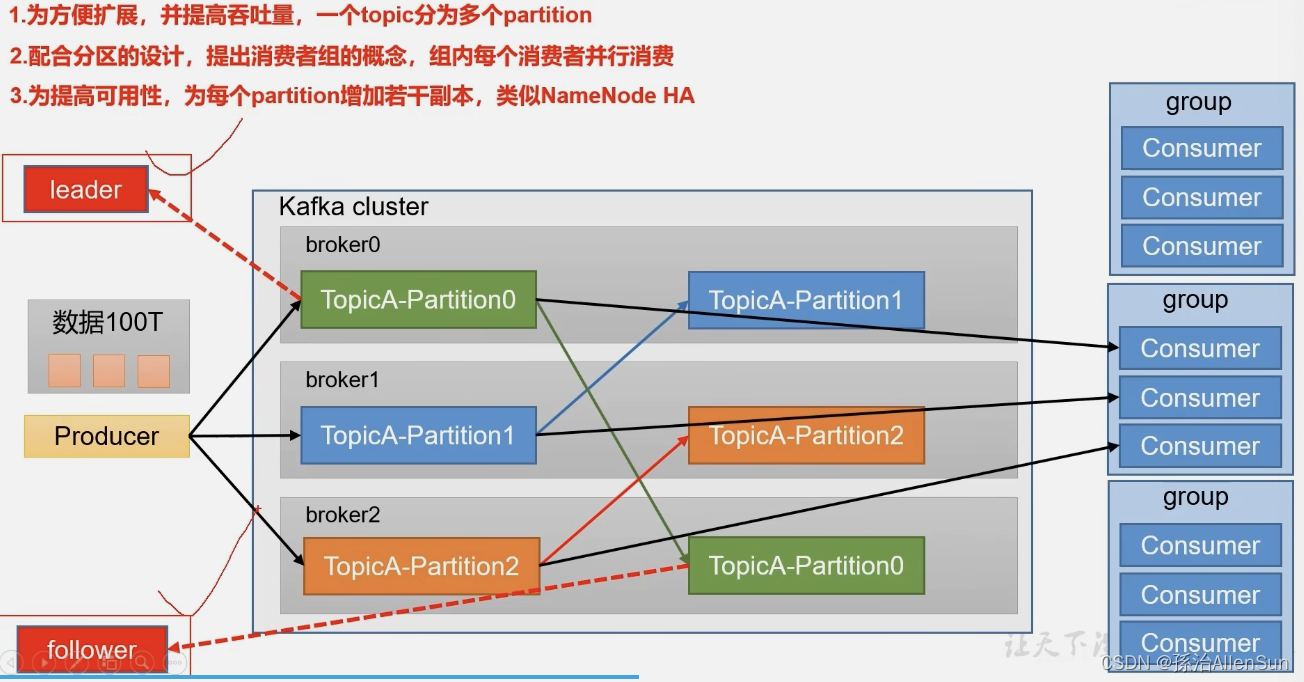
如果是海量数据的话,用单独一台服务器存储的话,压力太大。可以把一个主题切割成几块来处理,在好几台服务器上搭建集群,每个服务器就是一个broker。假如生产者需要往主题A中生产100T数据,那么就在在3台服务器上的主题A各自生产存放33T左右,同一个主题在3台服务器上分成三个不同的分区

消费者引入消费组,消费组中包含多个消费者Consumer,每个消费者消费一个分区的消息,就可以提高消费者消费一个主题消息的能力
其中有一些规则
(1)一个分区的消息数据只能由一个消费组中的一个消费者消费,如果一个分区由两个消费者消费,那么就会不确定哪个消费者,可能会重复消费,不利于管理
如果一个分区挂了呢,那么存在这个分区的33T数据就没了,所以kafka引入了副本来备份数据
1-这些副本是不一样的,分为leader和follower,消费者消费的时候只消费leader,而follower只负责备份的作用,等leader挂了follower才有条件成为新的leader
还有一些信息是存在zookeeper里的,存储的信息就是哪些kafka服务器broker上线了正在工作,还会记录每个broker中哪个是leader分区
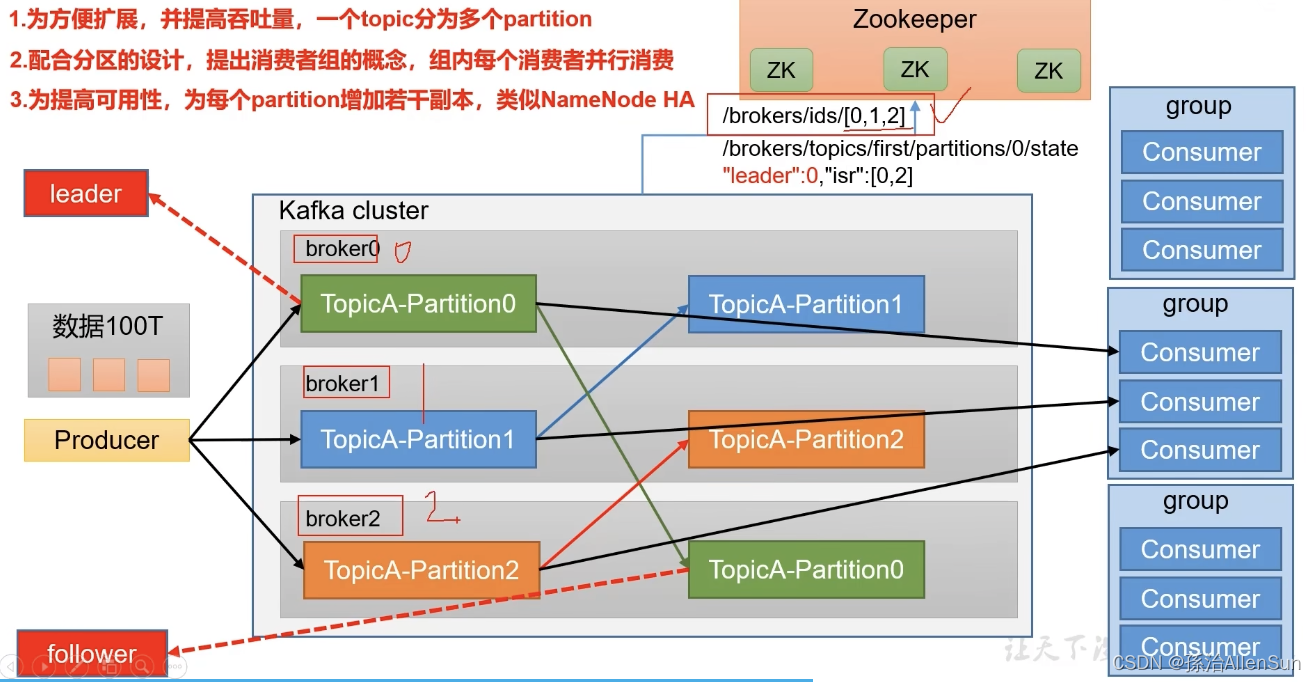
一种是基于zookeeper,一种是不基于
某一个分区当中的数据只能交给一个消费者消费,防止两者冲突,
为了保证分区的可靠性,引入了副本,副本分为leader和follower,生产消费只针对leader,等leader挂了follower才有条件成为新的leader
zookeeper存储上下限信息
(二)Linux安装Kafka
【1】安装流程
(1)安装JDK
教学路径:
查看本地JDK安装是否成功

(2)安装kafka
到官网下载
从mac传输安装包到Linux系统
scp -P 22 /Library/Java/kafka_2.12-3.1.0.tgz root@192.168.19.11:/
root
解压文件
tar -zxvf kafka_2.13-3.2.0.tgz
(3)修改kafka的配置文件:config/server.properties
# 现在不用改,但是后面如果要配置kafka集群的话,要保证每个服务器的broker.id都是不一样的
broker.id=0
# 配置当前主机的地址,默认端口号就是9092
listeners=PLAINTEXT://192.168.19.11:9092
advertised.listeners=PLAINTEXT://192.168.19.11:9092
# 配置日志文件的路径
log.dirs=/root/kafka_2.12-3.1.0/data/kafka-logs
# 连接zookeeper
zookeeper.connect=127.0.0.1:2181
可使用外置或内置Zookeeper,这里使用内置Zookeeper
(4)修改zookeeper的配置文件:config/zookeeper.properties
dataDir=../zkData
dataLogDir=../zkLogs
audit.enable=true
(5)启动kafka
进入bin目录
先启动zookeeper
./zookeeper-server-start.sh -daemon ../config/zookeeper.properties
然后启动kafka
./kafka-server-start.sh -daemon ../config/server.properties &
查看是否启动成功
ps -aux | grep server.properties
ps -aux | grep zookeper.properties

【2】测试实例
(1)概念介绍
(1)概念
 (2)为什么要使用消息队列
(2)为什么要使用消息队列
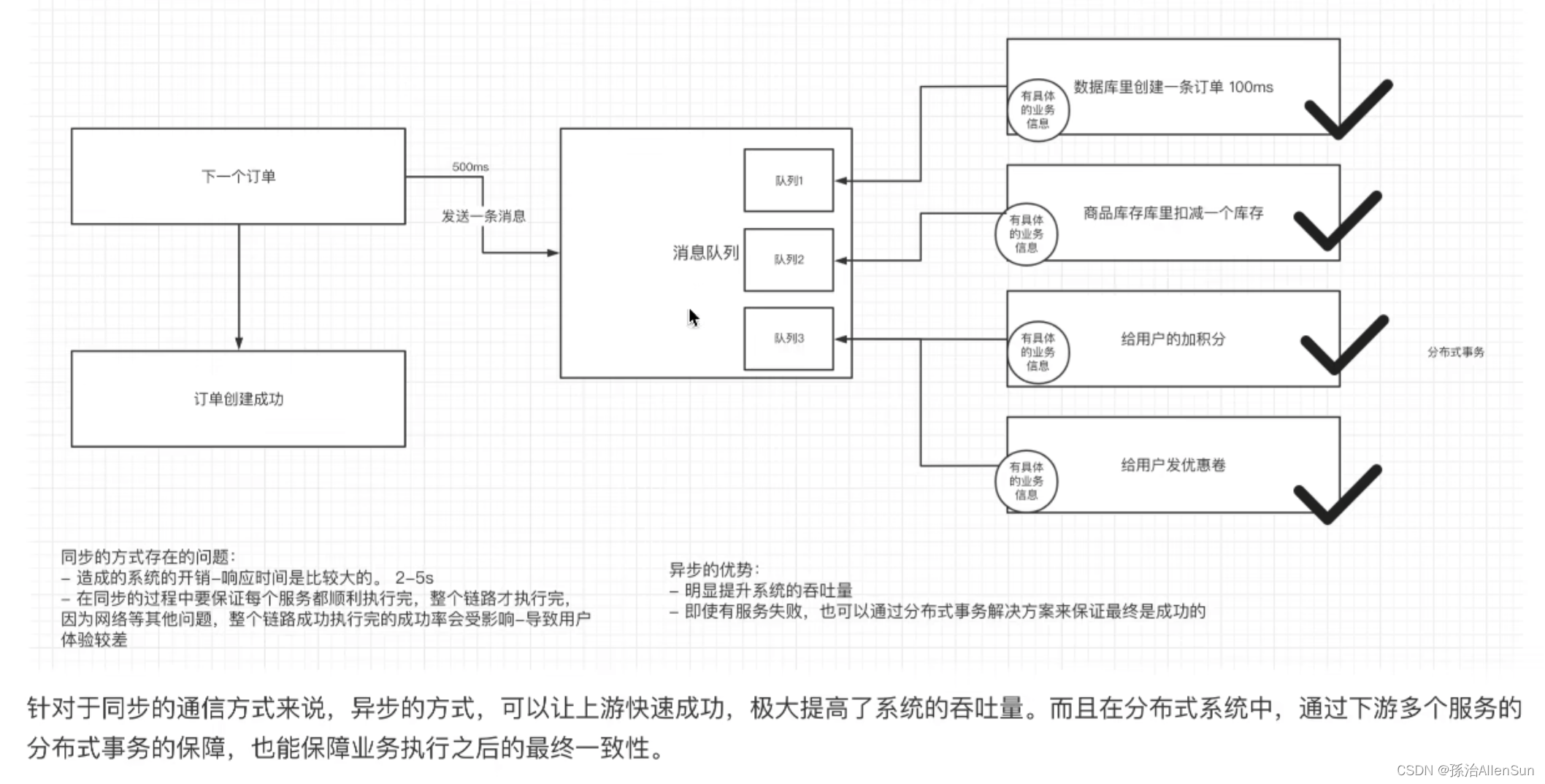
如果使用的是同步的通信方式来解决多个服务之间的通信,则要保证每一步的通信都要畅通,否则就会出错
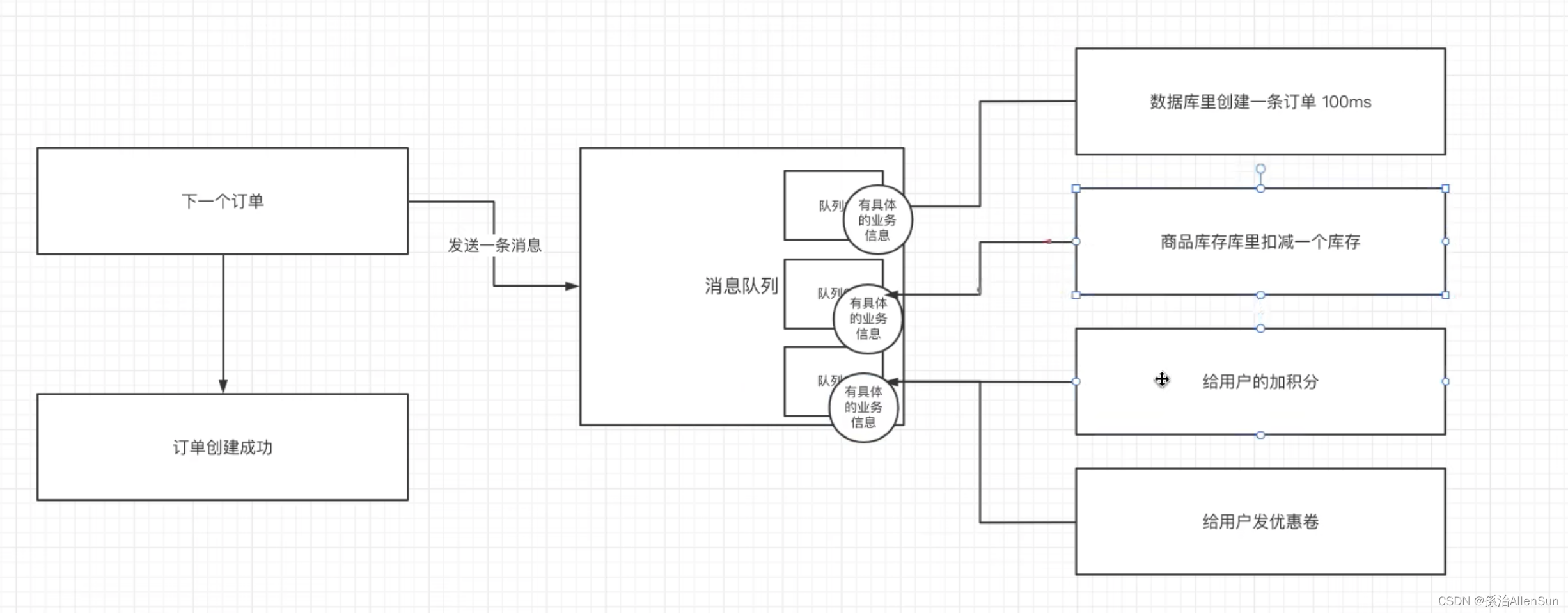
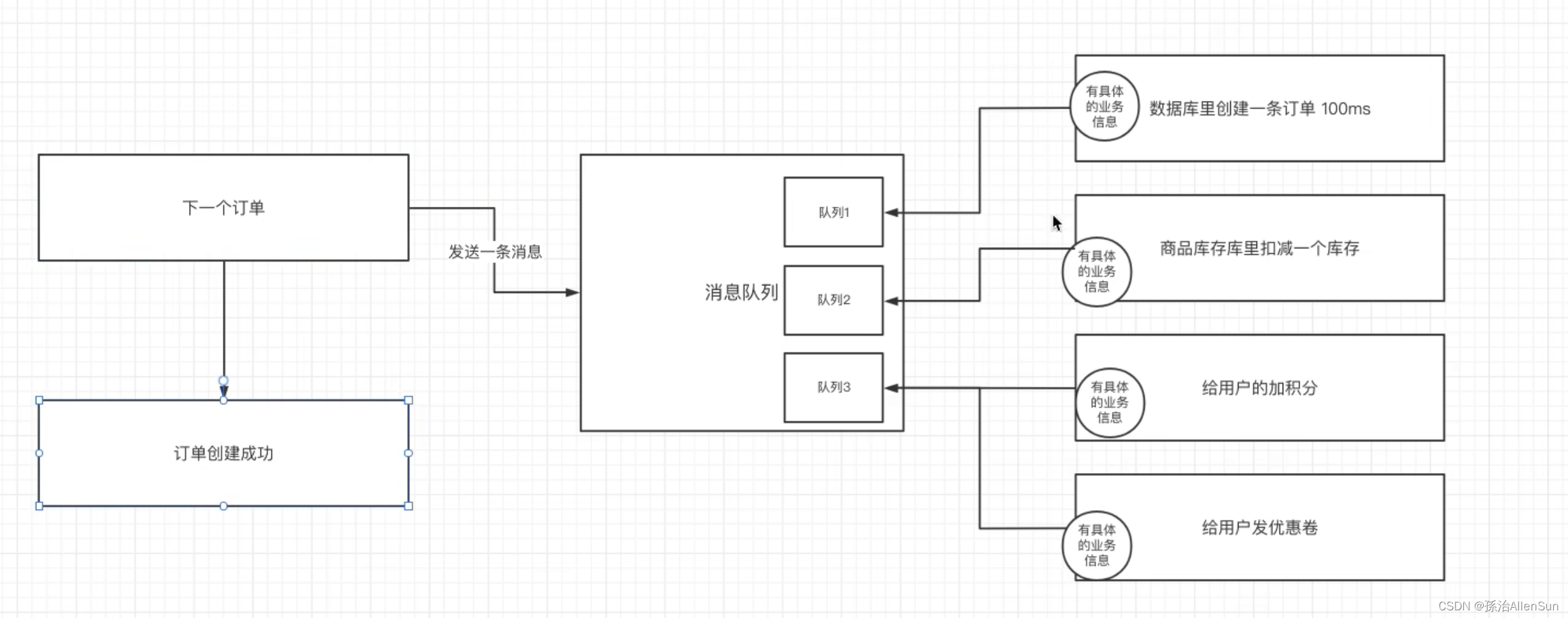
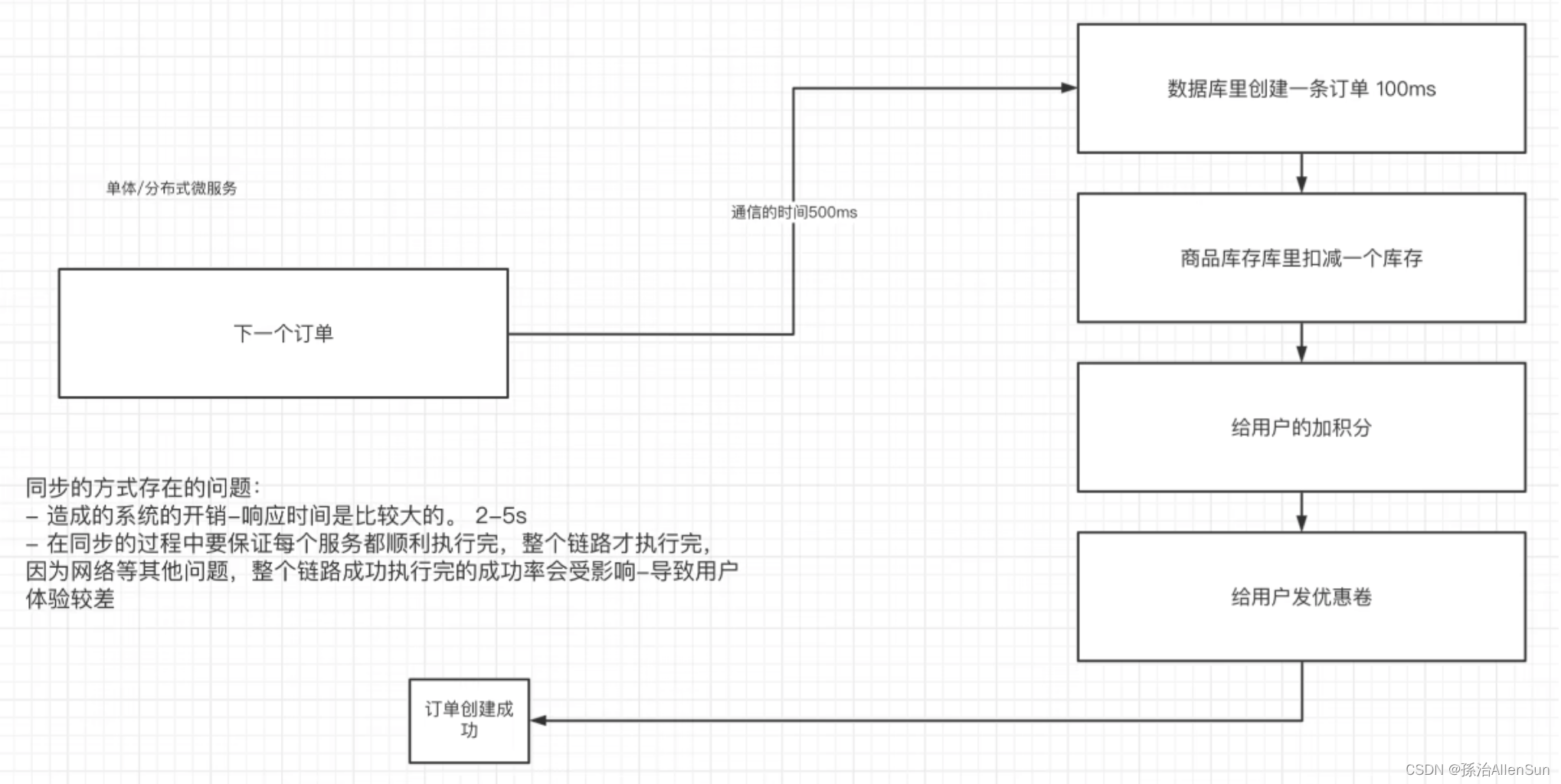 而如果使用异步的通信方式来解决多个服务之间的通信,就可以实现解耦
而如果使用异步的通信方式来解决多个服务之间的通信,就可以实现解耦
(2)创建Topic
创建一个名为javaTopic的主题,分区为2个,副本为1个
./kafka-topics.sh --bootstrap-server 192.168.19.11:9092 --create --topic javaTopic --partitions 2 --replication-factor 1
replication-factor:指定副本数量
partitions:指定分区

(3)查看Topic
./kafka-topics.sh --bootstrap-server 192.168.19.11:9092 --list

(4)删除Topic
./kafka-topics.sh --bootstrap-server 192.168.19.11:9092 --delete -topic testTopic

(5)生产/消费数据
进入bin目录,打开两个终端,分别执行如下命令:
(1)先执行生产者命令(发送消息)
kafka自带了一个producer命令客户端,可以从本地文件中断读取内容,或者我们也可以用命令行直接输入内容,并将这些内容以消息的形式发送到kafka集群中。在默认情况下,每一个行会被当成一个独立的消息。使用kafka的发送消息的客户端,制定发送到的kafka服务器地址和topic
./kafka-console-producer.sh --broker-list 192.168.19.11:9092 --topic javaTopic
(2)输入消息

(3)另一个窗口进入bin目录执行消费者命令
./kafka-console-consumer.sh --bootstrap-server 192.168.19.11:9092 --topic javaTopic
(4)继续在生产者窗口输入内容
 (5)再看消费者窗口
(5)再看消费者窗口
 成功
成功
(三)进一步案例分析
【1】消费者怎么知道从什么位置开始消费
上面我们测试的时候,先在生产者输入到3333,然后才开启了消费者。接着输入4444才被消费者消费到,为什么4444前面的内容没有被消费到呢?
这就引入了“偏移量”
对于consumer,kafka同样也携带了了一个命令行客户端,会将获取到内容在命令中进行输出,默认是消费最新的消息。使用kafka的消费者消息的客户端,从指定kafka服务器的指定topic中消费信息
(1)方式一:从最后一条消息的偏移量+1开始消费
./kafka-console-consumer.sh --bootstrap-server 192.168.19.11:9092 --topic javaTopic
(2)方式二:从头开始消费
./kafka-console-consumer.sh --bootstrap-server 192.168.19.11:9092 --from-beginning --topic javaTopic
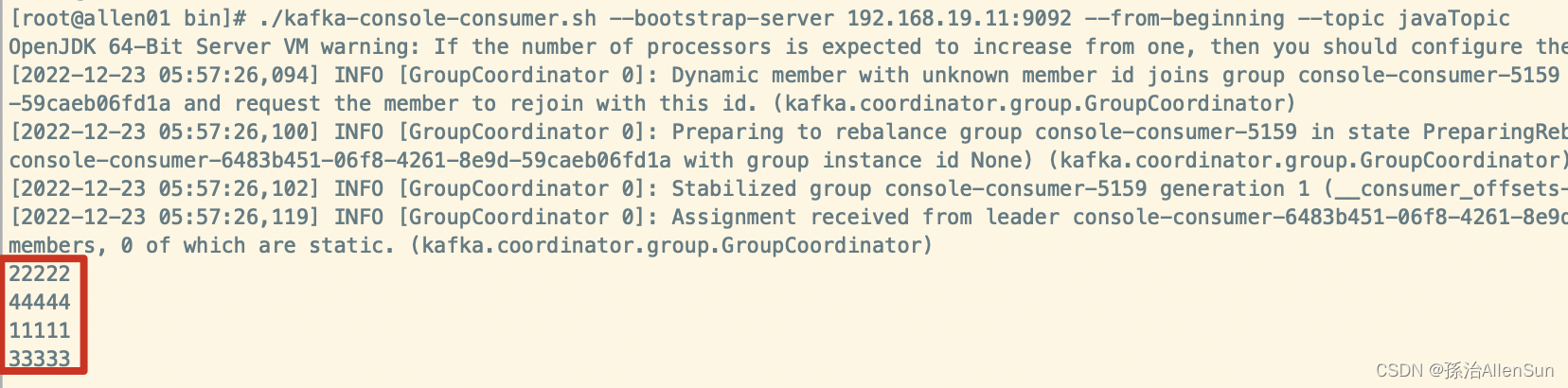
几个注意点:
(1)消息会被存储,生产找把消息发送给broker,broker会把消息保存到本地的日志文件中
(2)消息是顺序存储的,通过offset偏移量来描述消息的有序性
(3)消息是有偏移量的
(4)消费时可以指明偏移量进行消费
进入我们在server.peoperties配置文件中设置的日志路径:kafka_2.12-3.1.0/data/kafka-logs。可以看到下面有50个对应的维护偏移量的文件:
(1)__consumer_offsets-49
1-kafka内部自己创建了__consumer_offsets主题包含了50个分区。这个主题用来存放消费者消费某个主题的偏移量,也就是记录一个消费者已经消费到哪个位置了。
2-会有很多个主题,会有很多个消费者,每个消费者都会往这个文件里放入offset数据,所以这个文件存的信息非常多,创建了50个分区就可以保证存储很大的数据量。通过设置了50个分区,可以提升这个主题的并发性。
3-因为每个消费者都会自己维护着消费的主题的偏移量,也就是说每个消费者会把消费的主题的偏移量自主上报给kafka中的默认主题:consumer_offsets。
(2)信息补充
1-定期把自己消费分区的offset提交给kafka内部:__consumer_offsets,提交过去的时候,key是consumerGroupid+topic+分区号,value就是当前offset的值,kafka会定期清理topic里的消息,最后就保留最新的那条数据。
2-因为__consumer_offsets可能会接收高并发的请求,kafka默认给其分配50个分区(可以通过offsets.topic.num.partitions设置),这样可以通过加机器的方式抗大并发
3-通过如下公式可以选出consumer消费的offset要提交到__consumer_offsets的哪个分区:hash(consumerGroupId)%__consumer_offsets主题的分区数(常见的哈希算法+取模)
 还可以看到有:javaTopic-0、javaTopic-1有我们创建的两个分区,进入分区文件查看:
还可以看到有:javaTopic-0、javaTopic-1有我们创建的两个分区,进入分区文件查看:
(1)0000.index
稀疏索引的原理,使用二分查找法,能更快速的找到数据
(2)0000.log
保存的就是生产者往topic的分区里发送的消息
(3)0000.timeindex
根据时间索引来查找数据
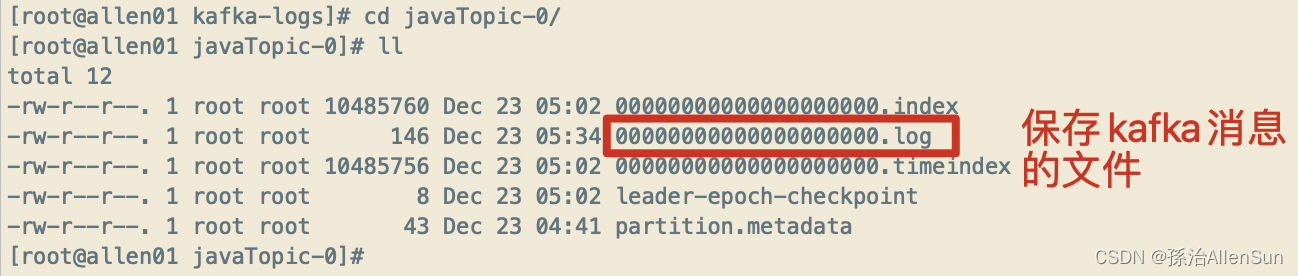
总结流程就是:生产者输入的消息存入javaTopic-0目录下的0000.log文件中,消息有自己的偏移量,消费者在获取消息的时候根据偏移量从这个文件中读取信息,而且只是读取并不会删除消息,所以其他的消费者再来读取的时候依然可以读取到全部的消息。
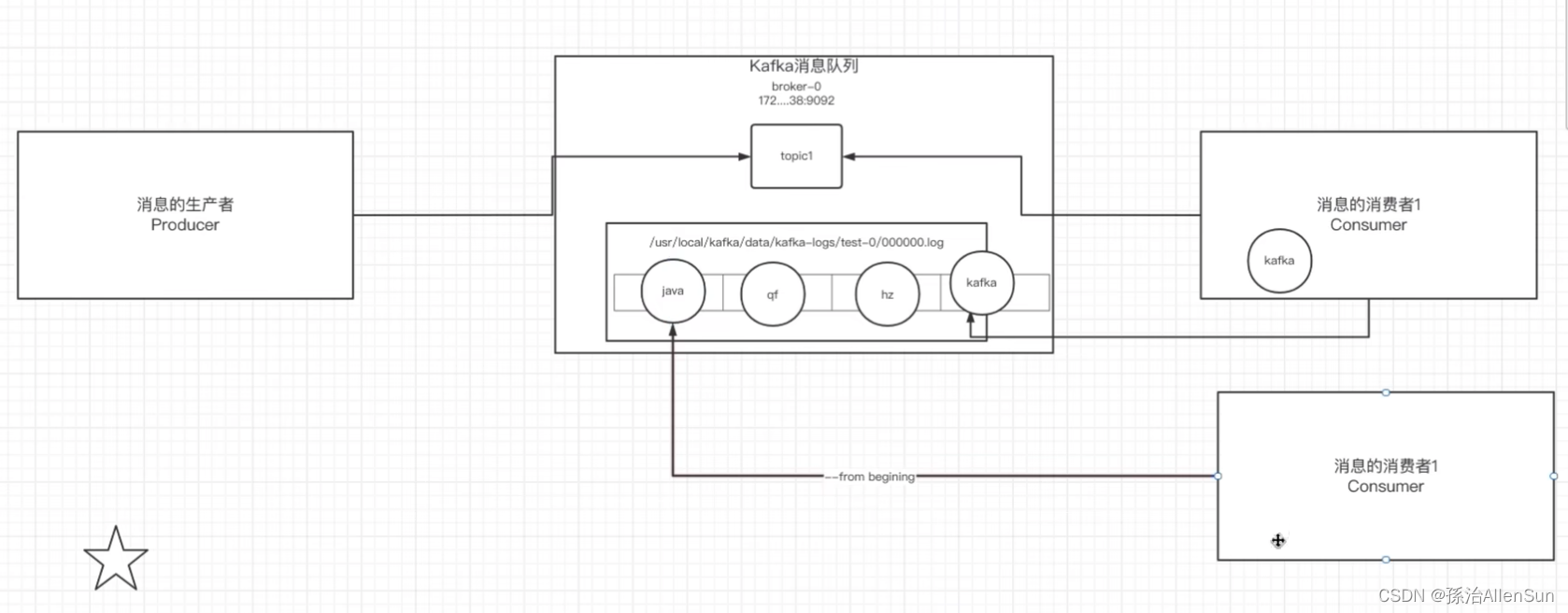
【2】单播消息
在一个kafka的topic中,启动两个消费者,一个生产者,问:生产找发送消息,这条消息是否同时会被两个消费者消费??
(1)开启生产者和一个消费者组里的两个消费者
生产者
./kafka-console-producer.sh --broker-list 192.168.19.11:9092 --topic javaTopic
消费者组
./kafka-console-consumer.sh --bootstrap-server 192.168.19.11:9092 --consumer-property group.id=javaGroup --topic javaTopic
生产者发送了消息
 消费者1收到消息了
消费者1收到消息了
 消费者2没有收到消息
消费者2没有收到消息

接续输入消息
 看到两个消费者轮流获取消息。这里是因为我之前创建Topic的时候指定了2个分区,所以生产的消息被轮流放入到两个分区中去了,而消费组中的两个消费者各自获取一个分区中的消息,所以看起来就是轮流消费了。那么如果是只有一个分区呢?
看到两个消费者轮流获取消息。这里是因为我之前创建Topic的时候指定了2个分区,所以生产的消息被轮流放入到两个分区中去了,而消费组中的两个消费者各自获取一个分区中的消息,所以看起来就是轮流消费了。那么如果是只有一个分区呢?

 如果只有一个分区的话,只有一个消费者可以消费这个分区中的消息,这样可以保证消费的有序性,并且是只有最新加入消费组的哪个消费者可以消费。
如果只有一个分区的话,只有一个消费者可以消费这个分区中的消息,这样可以保证消费的有序性,并且是只有最新加入消费组的哪个消费者可以消费。
总结:如果多个消费者在同一个消费组,那么只有一个消费者可以收到订阅的topic中的消息。换言之,同一个消费组中只能有一个消费者收到一个topic中的消息。
【3】多播消息
开启生产者和两个消费者组里的两个消费者
./kafka-console-consumer.sh --bootstrap-server 192.168.19.11:9092 --consumer-property group.id=javaGroup01 --topic javaTopic
./kafka-console-consumer.sh --bootstrap-server 192.168.19.11:9092 --consumer-property group.id=javaGroup02 --topic javaTopic


可以看到两个不同消费组的消费者都同时获取到了生产者发送的消息
总结:不同消费组订阅同一个topic,那么不同额消费组中只有一个消费者能收到消息。实际上也是多个消费组中的多个消费者收到了同一个消息。
【4】查看消费组和信息
# 查看当前主题下有哪些消费者组
./kafka-consumer-groups.sh --bootstrap-server 192.168.19.11:9092 --list

./kafka-consumer-groups.sh --bootstrap-server 192.168.19.11:9092 --describe --group javaGroup

此时关闭所有消费者,然后生产者接着发送消息,再看一下消费组信息,就能看到LAG量在增加
【5】主题和分区的概念
(1)主题Topic
主题Topic在kafka中是一个逻辑的概念,kafka通过topic把消息进行分类。不同的topic会被订阅该topic的消费者消费。
但是有一个问题,如果说这个topic的消息非常非常多,多到需要几个T来存,因为消息是会被保存到log日志文件中的。为了解决这个文件过大的问题,kafka提出了partition分区的概念
(2)分区Partition
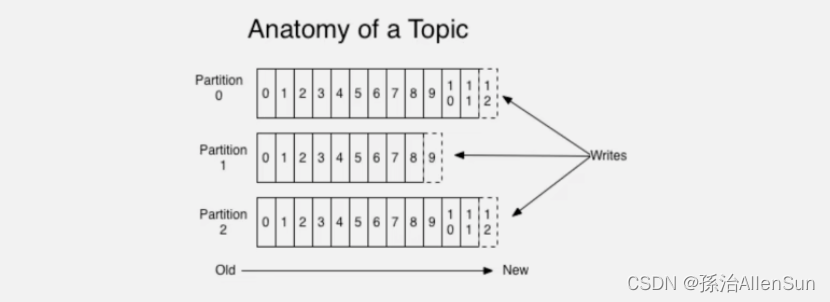
通过partition把一个topic中额消息分区来存储,这样的好处有多个:
1-分区存储可以解决统一存储文件过大的问题
2-提供了读写的吞吐量:读和写可以同时在多个分区中进行
# 这里就创建了两个javaTopic分区
./kafka-topics.sh --bootstrap-server 192.168.19.11:9092 --create --topic javaTopic --partitions 2 --replication-factor 1
# 查看当前主题的信息
./kafka-topics.sh --bootstrap-server 192.168.19.11:9092 -topic testTopic
(四)搭建kafka集群(3个broker)
【1】搭建过程
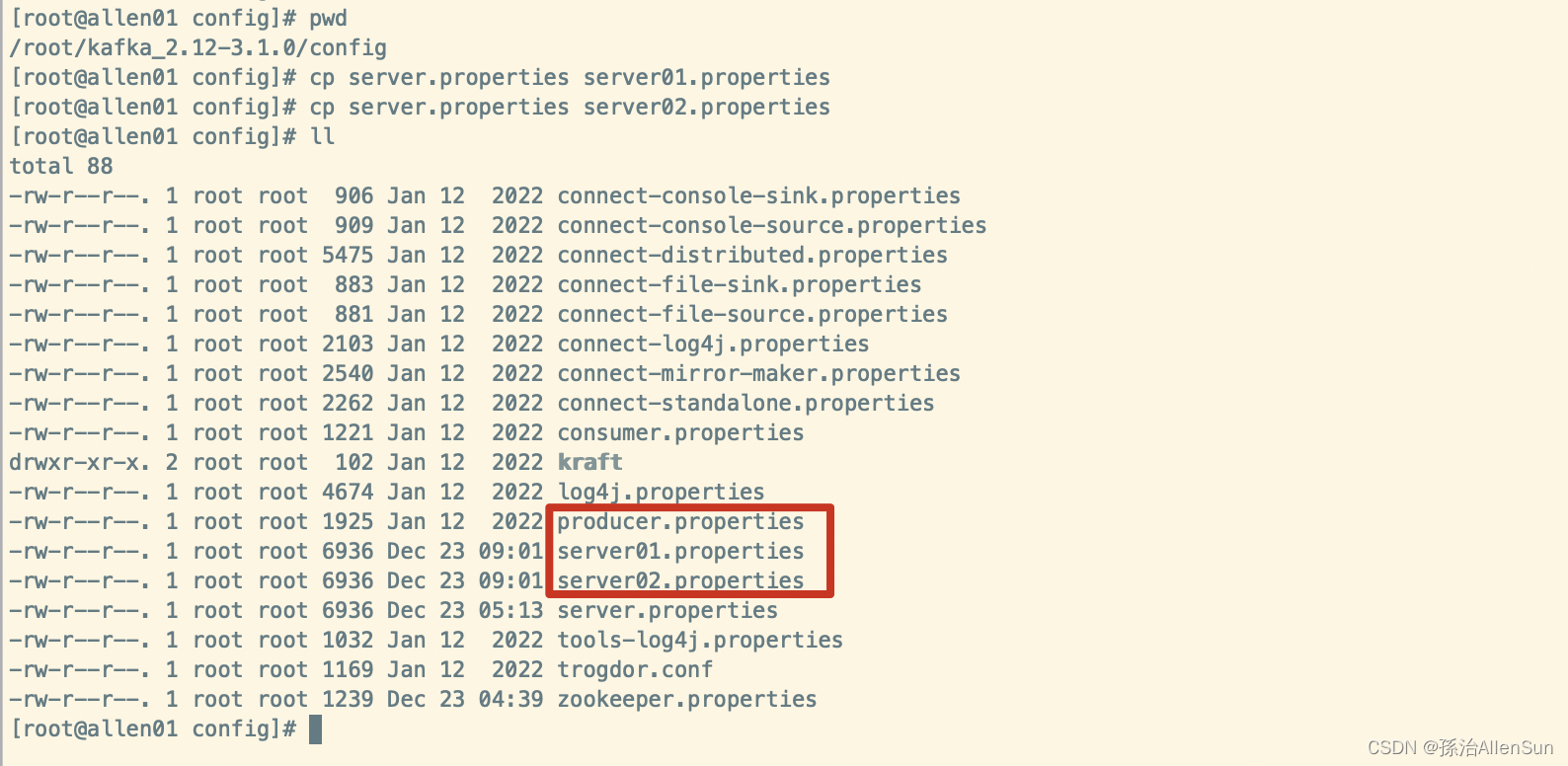
进入config目录下,拷贝两份server.properties
cp server.properties server01.properties
cp server.properties server02.properties
主要修改的内容如下:
(1)server.properties
broker.id=0
listeners=PLAINTEXT://192.168.19.11:9092
advertised.listeners=PLAINTEXT://192.168.19.11:9092
log.dirs=/root/kafka_2.12-3.1.0/data/kafka-logs
(2)server01.properties
broker.id=1
listeners=PLAINTEXT://192.168.19.11:9093
advertised.listeners=PLAINTEXT://192.168.19.11:9093
log.dirs=/root/kafka_2.12-3.1.0/data/kafka-logs-1
(3)server02.properties
broker.id=2
listeners=PLAINTEXT://192.168.19.11:9094
advertised.listeners=PLAINTEXT://192.168.19.11:9094
log.dirs=/root/kafka_2.12-3.1.0/data/kafka-logs-2
使用如下命令来启动3台服务器
./zookeeper-server-start.sh -daemon ../config/zookeeper.properties
./kafka-server-start.sh -daemon ../config/server.properties &
./kafka-server-start.sh -daemon ../config/server01.properties &
./kafka-server-start.sh -daemon ../config/server02.properties &
【2】测试过程
(1)副本的概念
副本就是对分区的备份。在集群中,不同的副本会被部署在不同的broker上,例子:创建1个主题,2个分区,3个副本
./kafka-topics.sh --bootstrap-server 192.168.19.11:9092 --create --topic replicatedTopic --partitions 2 --replication-factor 3
查看主题的详细信息
./kafka-topics.sh --bootstrap-server 192.168.19.11:9092 --describe --topic replicatedTopic
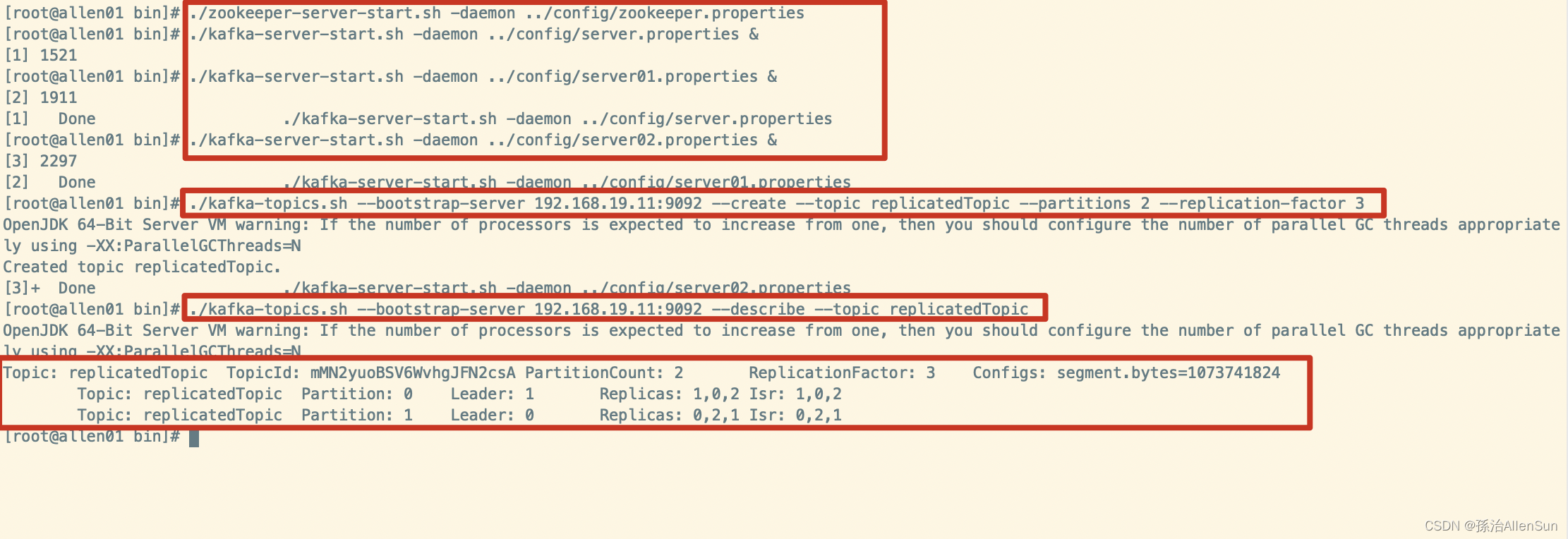 从结果中可以获取的信息:
从结果中可以获取的信息:
(1)replicatedTopic这个主题有两个分区,每个分区有3个副本,分别放在3台服务器上
(2)第一个分区的partition号为0,副本的leader是1号副本,其他副本为follower
(3)第二个分区的partition号为1,副本的leader是0号副本,其他副本为follower
(4)生产者只会给每个分区的leader副本发送消息,也就是只会往一台服务器上发送消息,其他两台服务器上的副本同步leader副本的信息,作为备份。消费者同理,只会消费leader副本的消息
(5)Isr:可以同步的broker节点和已同步的broker节点,存放在Isr集合中,表示当前可以正常参与同步的所有broker节点。如果一个broker上的副本同步的效率特别差的话,这个broker就会被cluster从Isr集合中删除,下次同步的时候就不给它同步了。如果leader副本挂了的话,就会从Isr集合中选取一个follower作为新的leader
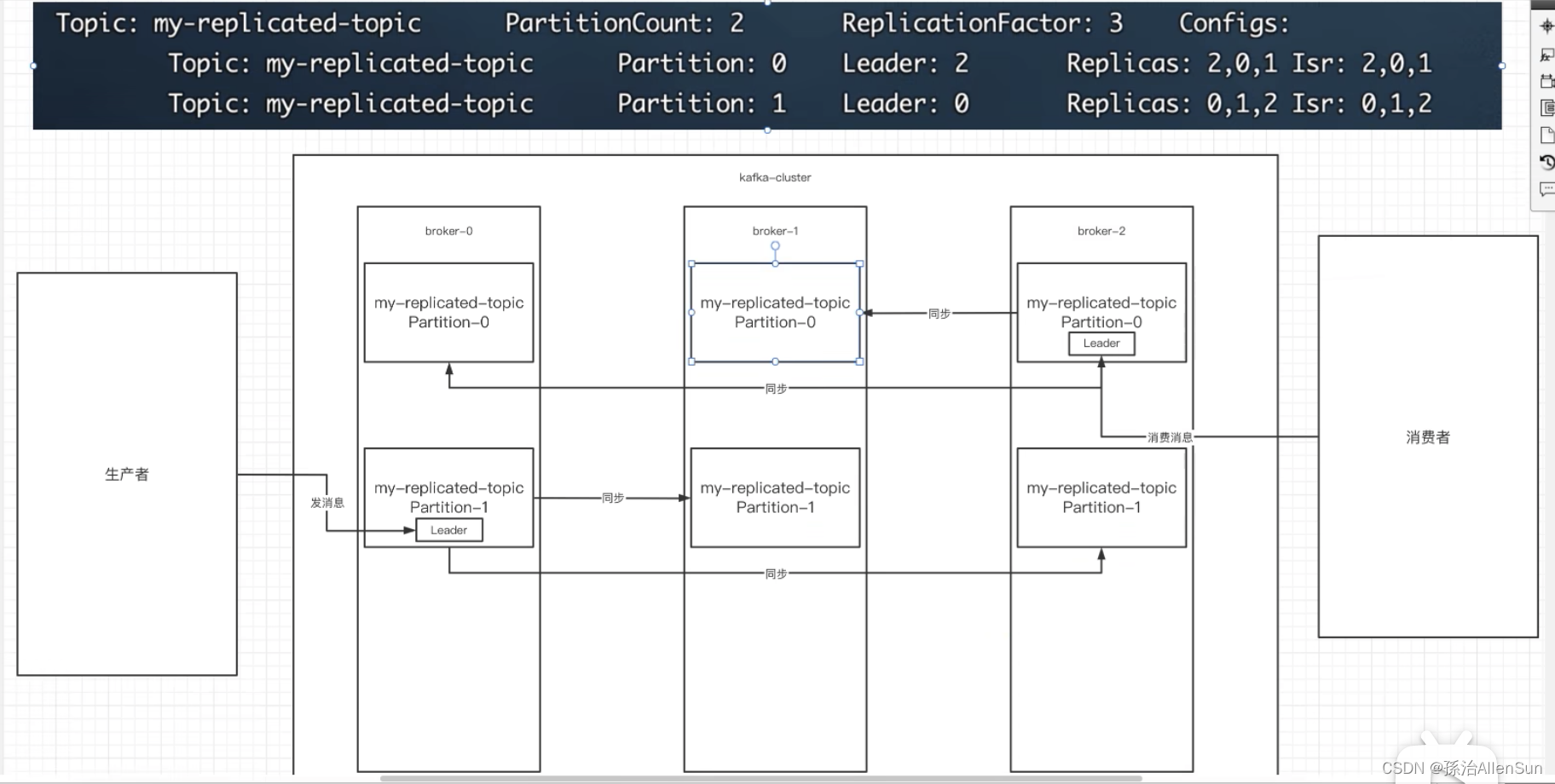
总结就是:1个主题的数据可以拆分放在多个分区中,每个分区可以创建多个副本放在不同的broker



(2)集群消息的生产
./kafka-console-producer.sh --broker-list 192.168.19.11:9092,192.168.19.11:9093,192.168.19.11:9094 --topic replicatedTopic
(3)集群消息的消费
./kafka-console-consumer.sh --bootstrap-server 192.168.19.11:9092,192.168.19.11:9093,192.168.19.11:9094 --from-beginning --topic replicatedTopic
(4)集群消费组的消费
./kafka-console-consumer.sh --bootstrap-server 192.168.19.11:9092,192.168.19.11:9093,192.168.19.11:9094 --from-beginning --consumer-property group.id=replicatedGroup --topic replicatedTopic
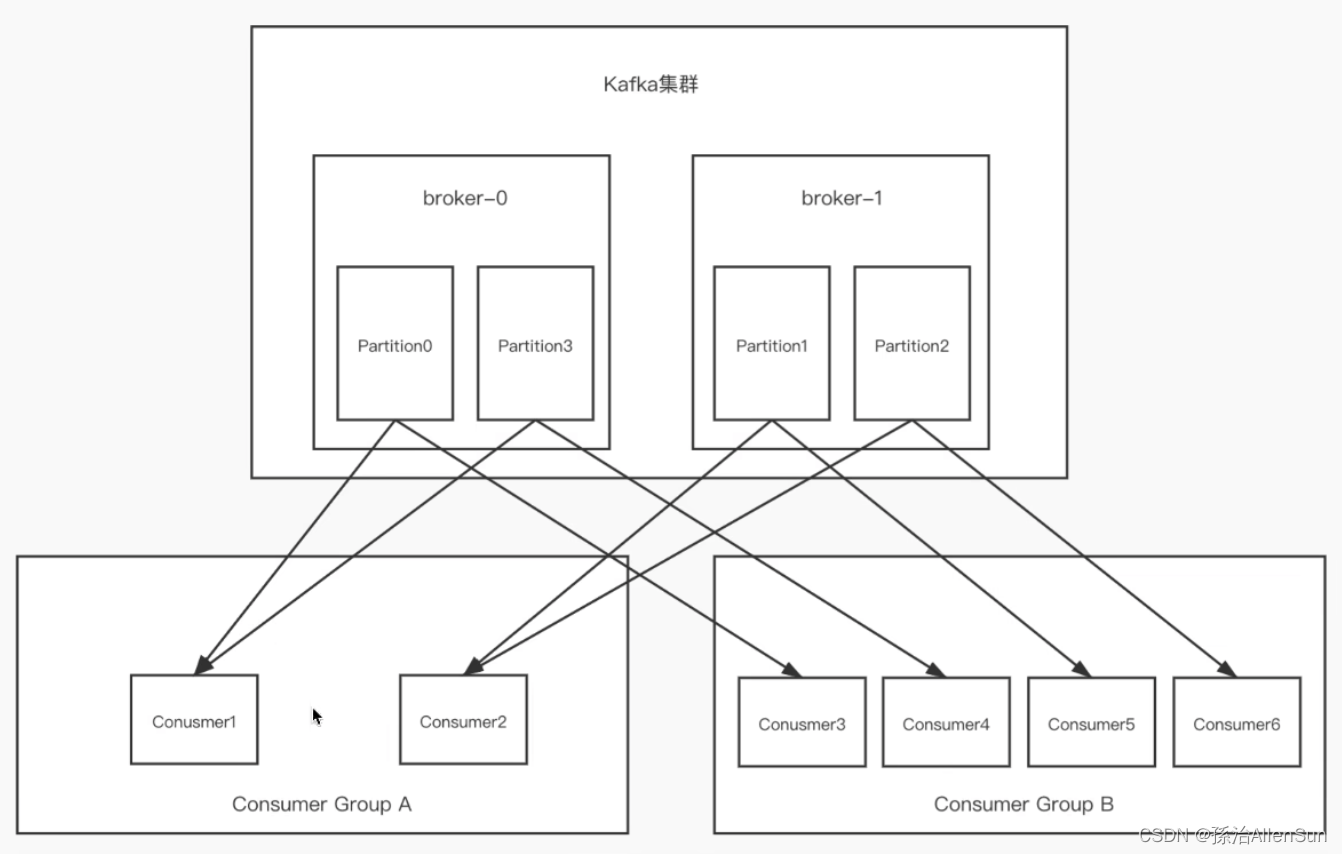
(1)一个副本里的消息只能被一个消费组中的一个消费者消费,这样可以保证消费顺序,不会被其他消费者打乱。那怎么做到消费的总顺序性呢?
(2)一个消费组中的一个消费者可以消费多个副本里的消息,如果一个消费者挂掉了,会触发rebalance机制,其他消费者可以顶上来消费该分区
(3)消费组中的消费者数量不能比一个topic中的partition副本数量多,否则多出来的消费者消费不到信息
(4)kafka只能在partition范围内保证消息消费的局部顺序性,不能在同一个topic中的多个partition中保证总的消费顺序性。