本文主要介绍使用python调用chatgpt api的方法,并提供一些任务的代码样例,只需更换自己的openai.api_key即可使用。(当然,使用的前提是先学会科学上网)
python调用chatgpt api的方法
1、首先登录到OpenAI API界面,点击右上角的账号弹出的列表中,点击view API keys。
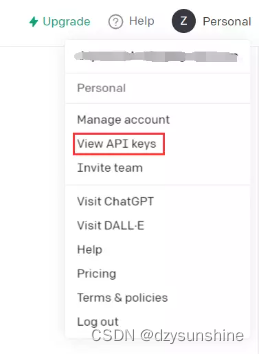
2、跳转界面后,点击Create new secret key,会生成新的key并且复制这个key(这个就是调用api时需要填写的openai key)。如果你已经生成过key并且记录下来就不用添加。
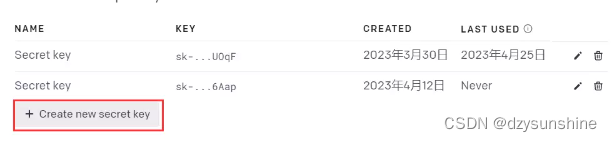
3、查看OpenAI官方文档(Documention)。
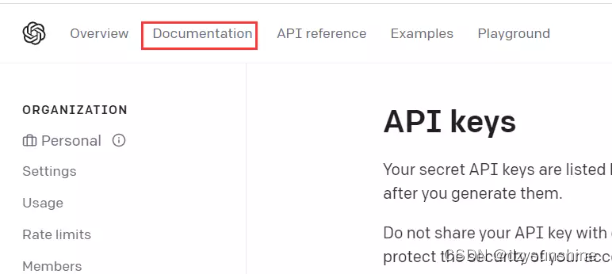
4、点击Chat Completion。
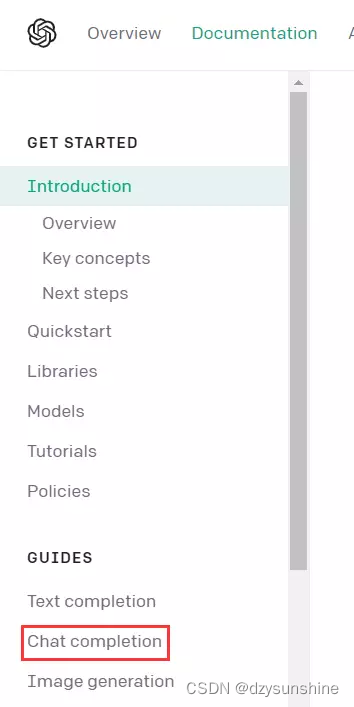
6、参考文档提供的代码进行使用,注意使用前需要先安装openai包。
pip Install openai
运行下面代码(官方提供的代码示例),注意填上前面复制好的api_key。
# Note: you need to be using OpenAI Python v0.27.0 for the code below to work
import openai
openai.api_key = "{前面复制好的key}"
completion = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{
"role": "system", "content": "You are a helpful assistant."},
{
"role": "user", "content": "Who won the world series in 2020?"},
{
"role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020."},
{
"role": "user", "content": "Where was it played?"}
]
)
print(completion.choices[0].message)
可以得到下面输出
{
“content”: “The 2020 World Series was played at Globe Life Field in Arlington, Texas.”,
“role”: “assistant”
}
如果遇到问题:
openai.error.APIConnectionError: Error communicating with OpenAI: HTTPSConnectionPool(host=‘api.openai.com’, port=443)
可参考:https://zhuanlan.zhihu.com/p/611080662?utm_id=0
调整下urllib3为1.25.11版本即可解决。
获取api可以调用的模型
通过以下代码可以获取目前通过api可以调用的模型,并将模型名称写入到 model_list.txt 文件中。
import openai
openai.api_key = "自己的api"
modelList = openai.Model.list()
OUTPUT_FILE = "model_list.txt"
with open(OUTPUT_FILE, "a") as f:
for d in modelList.data:
f.write(d.id)
f.write("\n")
一共有256个模型。
目前,补全任务最常用的是text-davinci-003(如文本生成,翻译等等);对话任务最常用的就是 gpt-3.5-turbo(如多轮对话),最强的GPT-3.5模型(当然现在也已经申请GPT4的接口了),性能优异且成本较低,调用成本只有 text-davinci-003 的 1/10。
各种任务代码示例
文本分类任务
import openai
openai.api_key = "自己的api"
response = openai.Completion.create(
model="text-davinci-003",
prompt="判断一条句话是积极、消极还是中性。\n\n这部电影拍的非常好,是我最喜欢的一部科幻片。\n情感:",
temperature=0,
max_tokens=60,
top_p=1,
frequency_penalty=0.5,
presence_penalty=0
)
print(response['choices'][0]['text'])

参数解读:
max_tokens:生成文本的最大 token 数。所有模型都只能处理一定长度的文本(例如 4096 个 token),因此输入的模板长度加上 max_tokens 不能超过这个限制。
temperature:采样温度,值介于 0 到 2 之间。较高的值(例如 0.8)会使得输出更随机,较小的值(例如 0.2)则会使得输出更确定。该参数与 top_p 通常只建议修改其中一个。
top_p:一种替代温度采样的方法,称为核采样 (nucleus sampling),只考虑具有 top_p 概率质量的 token 的结果。例如设为 0.1 就只考虑构成前 10% 概率质量的 token。该参数与 temperature 通常只建议修改其中一个。
presence_penalty:值介于 -2.0 到 2.0 之间。正值会根据是否已经出现在文本中来惩罚新生成的 token,从而鼓励模型生成新的内容,避免出现大段重复。
frequency_penalty:值介于 -2.0 到 2.0 之间。正值会根据新生成 token 在文本中的频率对其进行惩罚,从而降低模型逐字重复同一行的可能性。
文本生成(补全)任务
import openai
openai.api_key = "自己的api"
response = openai.Completion.create(
model="text-davinci-003",
prompt="新开张的服装店专注于夏季裙子,请为这家服装店写一条广告:",
temperature=0.4,
max_tokens=512,
top_p=1,
frequency_penalty=0,
presence_penalty=0
)
print(response['choices'][0]['text'])

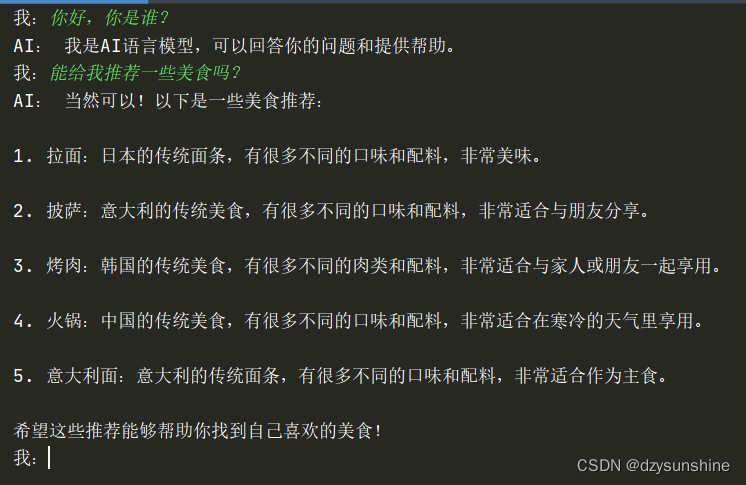
多轮对话任务
import openai
openai.api_key = "自己的api"
def chat():
my_messages=[]
while True:
my_input=input('我:')
my_messages.append({
"role": "user", "content": my_input})
if not my_input:
return
completion = openai.ChatCompletion.create(
model="gpt-3.5-turbo-0301",
messages=my_messages,
temperature=0.2
)
response = completion.choices[0].message["content"]
print("AI:",response)
my_messages.append({
"role":"assistant","content":response})
chat()
机器翻译任务
import openai
openai.api_key = "自己的api"
response = openai.Completion.create(
model="text-davinci-003",
prompt="将下面这句话翻译为英语、法语和日语:\n\n今天天气真不错,你想和我一起出去玩吗?\n\n",
temperature=0.3,
max_tokens=256,
top_p=1,
frequency_penalty=0,
presence_penalty=0
)
print(response['choices'][0]['text'])

文本摘要任务
import openai
openai.api_key = "自己的api"
response = openai.Completion.create(
model="text-davinci-003",
prompt="为下面的文本生成摘要:\n\n在现代社会,人们越来越注重健康生活方式的建立和维护。健康的饮食和运动可以提高人体免疫力,减少各类疾病的发生。此外,心理健康也是一个重要的方面,良好的心理状态可以促进身体健康,降低患病和残疾的风险,改善生活质量。在工作和学习压力较大的现代社会,人们需要学会有效的自我管理和调节,保持愉悦的心态。此外,社会互动和支持网络也是心理健康的重要组成部分,人们应该积极参加社会活动,融入社会大家庭。综上所述,始终保持健康的生活方式和心理状态,才能真正地拥有幸福和成功。",
temperature=0.7,
max_tokens=120,
top_p=1,
frequency_penalty=0,
presence_penalty=0
)
print(response['choices'][0]['text'])

信息抽取任务
import openai
openai.api_key = "自己的api"
response = openai.Completion.create(
model="text-davinci-003",
prompt="从下面的文本中抽取关键词:\n\n在现代社会,人们越来越注重健康生活方式的建立和维护。健康的饮食和运动可以提高人体免疫力,减少各类疾病的发生。此外,心理健康也是一个重要的方面,良好的心理状态可以促进身体健康,降低患病和残疾的风险,改善生活质量。在工作和学习压力较大的现代社会,人们需要学会有效的自我管理和调节,保持愉悦的心态。此外,社会互动和支持网络也是心理健康的重要组成部分,人们应该积极参加社会活动,融入社会大家庭。综上所述,始终保持健康的生活方式和心理状态,才能真正地拥有幸福和成功。",
temperature=0,
max_tokens=60,
top_p=1,
frequency_penalty=0.5,
presence_penalty=0
)
print(response['choices'][0]['text'])

当然,通过调用api可以做除上面所举例子之外的更多其他任务,只需要注意两点,一点是设定比较明确的prompt,让模型明白你要做的具体任务是什么,另一点是适当地调整参数,使得模型生成的答案尽可能满足你的要求。