二、
1、PyStringObject与 PyString_Type
PyStringObject是变长对象中的不可变对象。当创建了一个PyStringObject对象之后,该对象内部维护的字符串就不能再被改变了。这一点特性使得 PyStringObject 对象能作为 PyDictObject 的键值,但同时也使得一些字符串操作的效率大大降低,比如多个字符串的连接操作。
[stringobject.h]
typedef struct {
PyObject_VAR_HEAD
long ob_shash;
int ob_sstate;
char ob_sval[1];
} PyStringObject;ob_sval是存放实际字符串的数组,数组长度是ob_size+1,因为里面存放的是原生C字符串,需要一个额外的结束符。但是注意,申请的时候令数组长度为1,实际上是为了要数组的首地址当做指针来用,ob_sval 作为首地址,在字符串申请函数中,申请的是一段长度为ob_size+1个字节的内存,而且必须满足 ob_sval[ob_size] = "\0‟。

PyStringObject 中的 ob_shash 变量其作用是缓存该对象的 HASH 值,这样可以避免每一次都重新计算该字符串对象的 HASH 值。如果一个 PyStringObject对象还没有被计算过 HASH 值,那么 ob_shash 的初始值是-1。PyStringObject 对象的 ob_sstate 变量该对象是否被 Intern 的标志。
PyString_Type:
PyTypeObject PyString_Type = {
PyVarObject_HEAD_INIT(&PyType_Type, 0)
"str",
PyStringObject_SIZE,
...
string_str, /* tp_str*/ //tp_str 指向string_str 函数
&string_as_number, /* tp_as_number */
&string_as_sequence, /* tp_as_sequence */
&string_as_mapping, /* tp_as_mapping */
(hashfunc)string_hash,
string_methods,
....
string_new, //实例化对象方法 /* tp_new */
PyObject_Del, /* tp_free */
};如图,tp_itemsize被设置为sizeof(char),对于python中任意变长对象,tp_itemsize这个域必须设置,它指明了由变长对象保存的元素的单位长度,tp_itemsize和ob_size共同决定了还需要额外申请的内存大小。
需要注意的是,字符串类型对象的tp_as_number,tp_as_sequence,tp_as_mapping,三个域都被设置了。这表示PyStringObject对数值操作,序列操作和映射操作都支持。
2、PyStringObject对象创建
PyObject *PyString_FromString(const char *str)
{
register size_t size;
register PyStringObject *op;
assert(str != NULL);
【1】:判断字符串长度
size = strlen(str);
if (size > PY_SSIZE_T_MAX - sizeof(PyStringObject)) {
PyErr_SetString(PyExc_OverflowError,
"string is too long for a Python string");
return NULL;
}
【2】:处理null string
if (size == 0 && (op = nullstring) != NULL) {
#ifdef COUNT_ALLOCS
null_strings++;
#endif
Py_INCREF(op);
return (PyObject *)op;
}
【3】:处理单字符,从缓存池中获取
if (size == 1 && (op = characters[*str & UCHAR_MAX]) != NULL) {
#ifdef COUNT_ALLOCS
one_strings++;
#endif
Py_INCREF(op);
return (PyObject *)op;
}
【4】:创建新的PyStringObject对象,并初始化
/* Inline PyObject_NewVar */
op = (PyStringObject *)PyObject_MALLOC(sizeof(PyStringObject) + size);
if (op == NULL)
return PyErr_NoMemory();
PyObject_INIT_VAR(op, &PyString_Type, size);
op->ob_shash = -1;
op->ob_sstate = SSTATE_NOT_INTERNED;
Py_MEMCPY(op->ob_sval, str, size+1);
.........
return (PyObject *) op;
}【1】判断字符串长度,字符串长度如果过长,将不会创建并返回空。win32 平台下,该值是2147483647。
【2】第一次在一个空字符串基础上创建一个PyStringObject,由于nullstring指针被初始化为NULL,所以python会为这个空字符串建立一个PyStringObject对象,将这个PyStringObject通过intern机制进行共享,然后nullstring指向这个被共享的对象。
【4】申请内存,还为字符串数组内的元素申请额外内存,然后将hash值设为-1,将intern标志设置为SSTATE_NOT_INTERNED。最后将str指向的字符串数组拷贝到PyStringObject所维护的空间中。如“Python”PyStringObject对象在内存中的状态:
3、 Intern机制
intern机制的目的是:对于被intern之后的对象,在python运行期间,系统中只有唯一一个与之相对应的PyStringObject对象。当判断两个PyStringObject对象是否相同时,如果他们都被intern了,那么只需要简单检查他们对应的PyObject*是否相同即可。这个机制既节省空间,又简化了PyStringObject对象的比较。
当对一个 PyStringObject对象进行intern处理时,首先在interned这个dict中检查是否有满足条件(b中维护的字符串与a相同)的对象b,如果存在,那么指向a的PyObject指针指向b,而a的引用计数-1,b的引用计数+1.
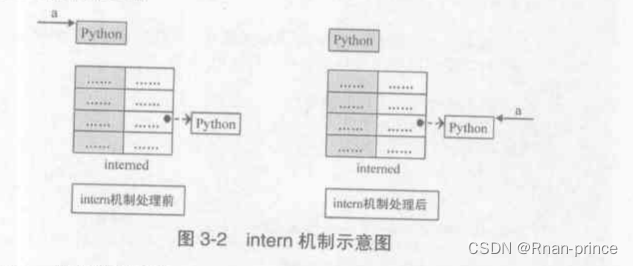
对于被intern机制处理过的PyStringObject对象,python采用特殊的计数机制。在将一个PyStringObject对象a的PyObject作为key和value添加到interned中,此时a的引用计数进行了两次+1,由于设计者规定interned中的a指针不能被视为有效引用,所以在代码【3】处a的计数器-2,否则删除a是永远不可能的。
4、字符缓冲池
python为整数准备了整数对象池,python为字符类型也准备了字符缓冲池。python设计者为PyStringObject设计了一个对象池characters。
首先对创建的字符对象进行intern操作,再将intern的结果缓存到字符缓冲池characters中。如下图演示缓存一个字符对应的PyStringObject对象的过程:
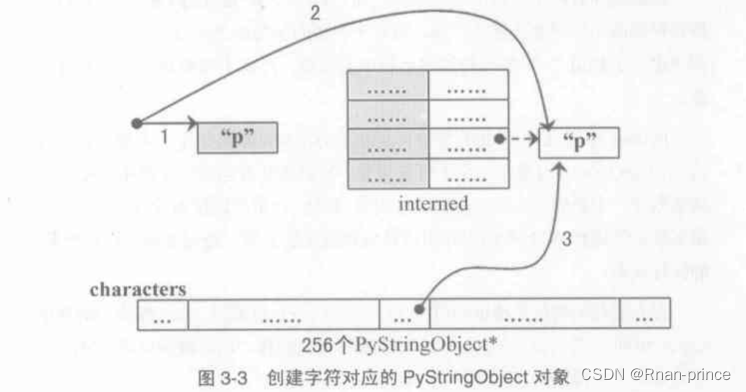
- 创建PyStringObject对象p ;
- 对p进行intern操作;
- 将p缓存到字符缓冲池中
5、PyStringObject 效率问题
python中可以通过+进行字符串拼接,但是性能及其低下,由于PyStringObject是不可变对象,这意味着在拼接时必须新建一个PyStringObject对象。这样如果连接N个PyStringObject对象,需要N-1次内存的申请工作,这无疑严重影响python的执行效率。
static PyObject *
string_join(PyStringObject *self, PyObject *orig)
{
char *sep = PyString_AS_STRING(self);
const Py_ssize_t seplen = PyString_GET_SIZE(self);
PyObject *res = NULL;
char *p;
Py_ssize_t seqlen = 0;
size_t sz = 0;
Py_ssize_t i;
PyObject *seq, *item;
seq = PySequence_Fast(orig, "");
.....
【1】遍历list中每个字符串,累加获取所有字符串长度
for (i = 0; i < seqlen; i++) {
const size_t old_sz = sz;
item = PySequence_Fast_GET_ITEM(seq, i);
sz += PyString_GET_SIZE(item);
if (i != 0)
sz += seplen;
}
创建长度为sz的PyStringObject对象
res = PyString_FromStringAndSize((char*)NULL, sz);
if (res == NULL) {
Py_DECREF(seq);
return NULL;
}
将list中的字符串拷贝到新建的PyStringObject对象中
p = PyString_AS_STRING(res);
for (i = 0; i < seqlen; ++i) {
size_t n;
item = PySequence_Fast_GET_ITEM(seq, i);
n = PyString_GET_SIZE(item);
Py_MEMCPY(p, PyString_AS_STRING(item), n);
p += n;
if (i < seqlen - 1) {
Py_MEMCPY(p, sep, seplen);
p += seplen;
}
}
Py_DECREF(seq);
return res;
}执行join操作时,会先统计list中有多少个PyStringObject对象,并统计这里PyStringObject所维护的字符串总长度,然后申请内存,将list中的所有PyStringObject对象维护的字符串拷贝到新开辟的内存空间中。N个PyStringObject对象拼接join只需申请一次内存,比+操作节约了N-2次操作,效率的提升非常明显。
————————————————
参考:
- Python源码剖析(陈孺)