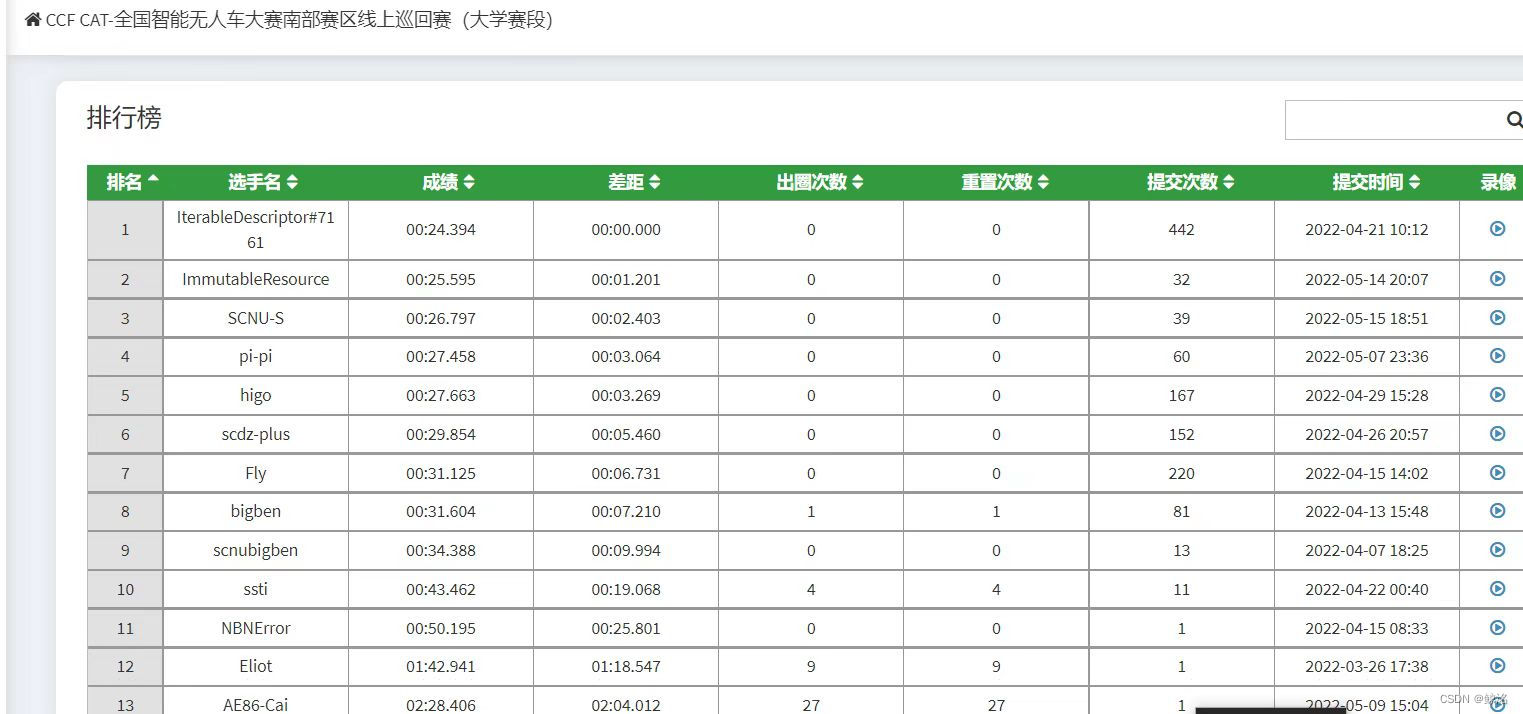
从以第三名的成绩从南部赛区的线上巡回赛晋级,来到全国线上巡回决赛,这一次的赛道为summit 2022(如下图)战队名为SCNU-S

对于这一个全新的赛道,首要目的是确定可用的奖励函数,就是选出不同策略的奖励函数(比如走中线策略,切线策略,又或者是针对这个赛道进行人为的路段速度控制。),并将这些奖励函数代入。
其中,训练的过程分为两步
第一步.筛选出初始迭代模板
动作空间从一个小的范围(比如从0.8-1.4开始)先让小车训练一个初始时间(我一般会训练30-60min足够,再多容易过拟合而降低起始速度)去适应赛道,并且通过观察分析曲线中红线的趋势来判断该奖励函数是否适用,一般会有两种情况,并将合适的模型作为初始迭代模板来进行下一步的迭代训练。
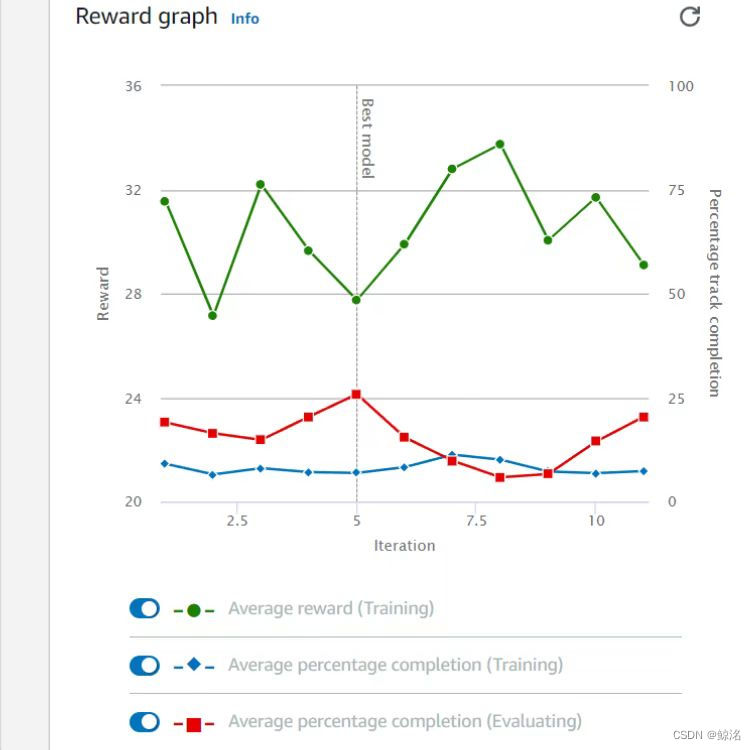
第一种:红线来回震荡,无明显上升趋势,且低于60,(如下,红线并不会随着训练时间的增加而上升,而是不稳定的震荡且不超过25)
这一种情况代表这个函数基本上不适用。增长训练时间并不会带来更好的完成的(即红线)
返回上一步并更换奖励函数
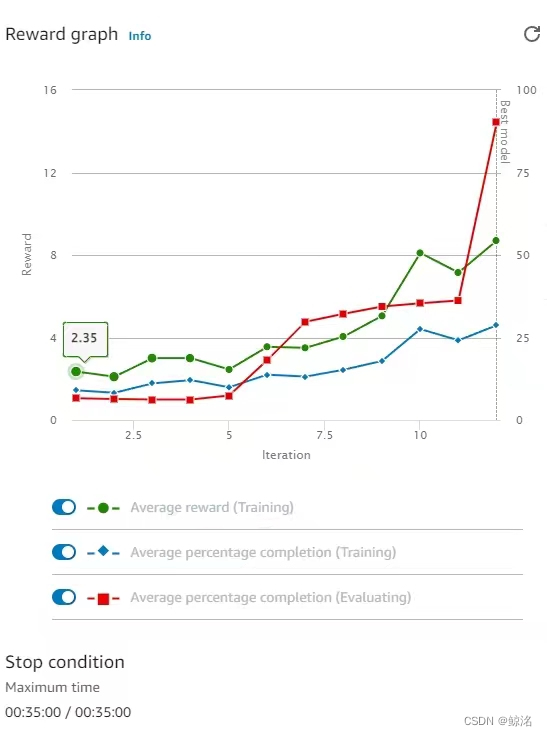
第二种,在训练结束时红线飙升,基本到达70以上甚至100。(如下图)此类代表该奖励函数具有较好的通用性或者适用于该赛道,前往下一个步骤进行训练。
第二步.模型逐步迭代探索
在这一步中,因为智能学习的不确定性,我们首先要知道两种人工智能中的探索,并从不确定性中抓住可控的确定性,从而得到我们想要的模型。
1.广度优先探索策略:可以理解为平行方向上(即兄弟节点上)的探索。
在训练无人车中具体为相同函数参数下的不同克隆。如果变量只是动作空间中的速度,我从速度范围1.2-2.4想迭代到1.2-2.8,中间可以有很多种方式,例如,1.分两次迭代,最大速度从2.4到2.6再到2.8。2.分为四次迭代,最大速度从2.4到2.5到2.6到2.7到2.8。他们得到的两种结果速度范围均为1.2-2.8,这两个结果可以互称为兄弟节点。但是因为过程的不同,可能会导致两个模型的赛道完成度(红线)和单圈速度有较大区别。
举一个自己训练中的例子,如上所述,想把最大速度从2.4迭代到2.8,当我分两次迭代时,发现由于跨度过大,小车没有充足时间慢慢适应速度的改变,导致红线从2.4的90掉到了2.8的40,自然得到的模型因为完成度过低而淘汰。(红线最高100,可以理解为赛道完成百分比)。而我分四次迭代时,由于有充足时间让小车适应,红线几乎没有变化,单圈速度也是在逐步提升。
2.深度优先探索策略:可以理解为对速度范围极限(父子节点)的探索。
具体表现为通过舍弃较高的红线(但是有个最低底线比如60,低于60就返回父节点),从而去尝试最大和最小速度范围的极限值,即平衡完成度(红线)和速度,以得到该模型的最好成绩。
举例,我在测试最小速度时,发现最小速度大于1.5时红线就骤降,加长训练时间也一样,这样就可以让我知道最小速度范围不要超过1.5,转而去测试最大速度。
而我们在模型的迭代中应该将两种策略结合起来,并用深度和广度优先策略,从而得到模型的最好成绩。
结果
在2022summit赛道中,用现有函数训练的模型单圈最快10.128s,训练时间共计70h,速度范围最终为1.4-2.8,最快三圈30.8s
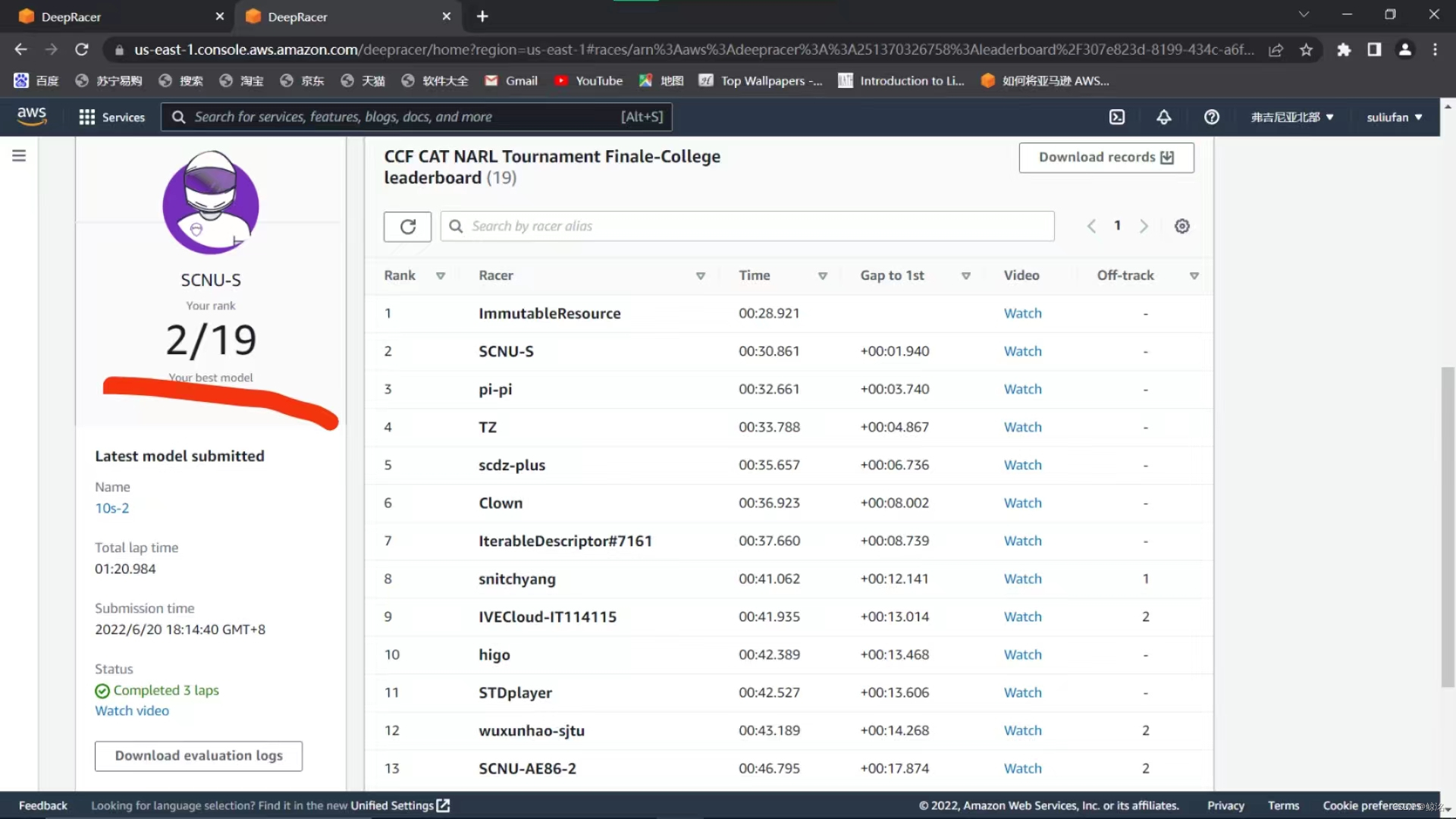
以全国第二的成绩晋级国赛!!
国赛将会是2018的线下赛道,详情请看我下一篇文章
顺便在等待国赛的期间免费收到了aws平台每月公开赛的前10%奖励(具体看上一篇文章),
ps:aws deepracer专属的防滑袜在线下赛道挺实用的。
