使用正则表达式删除代码注释
最近在处理数据集,需要将代码里面的所有注释都删除,这就需要用到正则表达式来进行去除了。下面挂上我处理代码注释的代码。
python代码注释有以下四种情况:
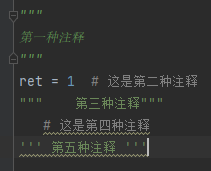
我们对文件的处理方式是按行读取并操作。
第一种就是"“独占一行,两个”"“之间行全部为注释块,这种我们使用标记”"“所在行号的方式来进行删除。具体来说:用正则式——{ [ ]*”""}匹配到""“独占一行,就将该行号压入栈中,处理完整个文件之后再每次连续出栈两个元素,将两个元素及之间的行根据行号进行删除。
第二种注释是位于代码后方的单行注释,这种注释利用re.split(r’#.’,i)[0]方法进行删除注释内容。
第三种注释是函数说明类的注释”"“注释”"",这种只占用一行,我们同样匹配"""进行删除。
第四种情况就是单行#位于前面,值得注意就是有可能有空格。
第五种注释与第一种处理方式一样
import re
def file_analysis(old_file_lines, six_quotes, hashtap):
"""标记需要删除的注释的行号,并存入列表"""
i = 0
for line in old_file_lines:
# 符号 # 独占一行
if re.match(r"(^\s)*#.*", line):
hashtap.append(i)
# 函数说明的 """xxxxx""" 或 '''xxxxx '''之类
if re.match(r"([ ]*\"\"\"[^\"]*\"\"\")|([ ]*\'\'\'.*\'\'\')", line):
hashtap.append(i)
else:
# 符号 """ 独占一行
if re.match(r"([ ]*\"\"\")|([ ]*\'\'\')", line):
six_quotes.append(i)
i += 1
# 将两个"""行号之间所有的行添加到 # 号列表中
while six_quotes != []:
# 从列表中移出最后两个元素
a = six_quotes.pop()
b = six_quotes.pop()
temp = b
while temp <= a:
hashtap.append(temp)
temp += 1
# 返回 # 号列表, 记返回需要删除的所有注释的 行号 集合
return hashtap
# 输入文件为一个str
def main(old_file):
""" 主函数"""
old_file_lines = old_file.splitlines()
# 处理文件并得到需要删除的注释的行号集合
six_quotes, hashtap = list(), list()
# 此时返回值 hashtap列表中,不仅仅包含#,还有"""、'''的行号
hashtap = file_analysis(old_file_lines, six_quotes, hashtap)
# 去重并排序,得到所有注释行号的列表
comment_list = sorted(set(hashtap))
# 创建与源文件总行号相同的列表 0,1,2,3...
new_file_list = list(i for i in range(len(old_file_lines)))
# 删除注释的行号,留下无注释的行号 的列表集合
for i in comment_list:
new_file_list.remove(i)
# 创建存储(无注释)新文件内容的列表
new_file_lines = list()
for i in new_file_list:
temp = old_file_lines[i]
new_file_lines.append(temp)
inum = 0
for i in new_file_lines:
# 注释跟代码在同一行的删除注释,保留代码
if re.match(r'.*#.*', i):
temp = re.split(r'#.*', i)
new_file_lines[inum] = temp[0]
inum = inum+1
return new_file_lines