文章目录
系列文章
机器学习算法 01 —— K-近邻算法(数据集划分、归一化、标准化)
机器学习算法 02 —— 线性回归算法(正规方程、梯度下降、模型保存)
机器学习算法 03 —— 逻辑回归算法(精确率和召回率、ROC曲线和AUC指标、过采样和欠采样)
机器学习算法 04 —— 决策树(ID3、C4.5、CART,剪枝,特征提取,回归决策树)
机器学习算法 05 —— 集成学习(Bagging、随机森林、Boosting、AdaBost、GBDT)
机器学习算法 06 —— 聚类算法(k-means、算法优化、特征降维、主成分分析PCA)
机器学习算法 07 —— 朴素贝叶斯算法(拉普拉斯平滑系数、商品评论情感分析案例)
机器学习算法 08 —— 支持向量机SVM算法(核函数、手写数字识别案例)
机器学习算法 09 —— EM算法(马尔科夫算法HMM前置学习,EM用硬币案例进行说明)

机器学习算法 10 —— HMM模型(马尔科夫链、前向后向算法、维特比算法解码、hmmlearn)
支持向量机SVM算法
学习目标:
- 了解什么是SVM算法
- 掌握SVM算法的原理
- 知道SVM算法的损失函数
- 知道SVM算法的核函数
- 了解SVM算法在回归问题中的使⽤
- 应⽤SVM算法实现⼿写数字识别器
1 SVM算法简介
1.1 引入
案例来源:http://bytesizebio.net/2014/02/05/support-vector-machines-explained-well/
视频演示:https://www.youtube.com/watch?v=3liCbRZPrZA
桌上有两种颜色的球,我们需要用一根棍子将它们区分开,并且要求之后添加球也能继续适用。

显而易见,我们可以这样放!

接着,我们继续添加球,但似乎有一个红球被分错了类。

此时我们可以把棍子变得更粗,稍微改变下角度,让棍子的两边有更大的空隙(最大间隙)。

这样即使再放更多的球,这跟棍子依然是一个比较好的分界线。

如果我们加大难度,变成下面这样的情况后该如何分类呢?

我们将这个二维图像转换到三维,用力在桌上一拍!这时,我们可以用一张纸去分类!

但我们试图用二维的视角去看这个划分的纸,那就是一条曲线。

上面这些东西在学术上是另一种说法:
- 球 —— 数据 [data]
- 棍子 —— 分类器 [classifier]
- 最大间隙 —— 最优化 [optimization]
- 拍桌子 —— 核方法 [kernelling]
- 纸 —— 超平面 [hyperplane]
1.2 算法定义
SVM(supported vector machine,⽀持向量机):找到⼀个超平⾯使样本分成两类,并且间隔最⼤。
SVM能够执⾏线性或⾮线性分类、回归,甚⾄是异常值检测任务。它是机器学习领域最受欢迎的模型之⼀,特别适⽤于中⼩型复杂数据集的分类。

超平⾯最⼤间隔
下面左图显示了三种可能的线性分类器的决策边界,虚线代表的模型表现⾮常糟糕,甚⾄都⽆法正确实现分类。
其余两个模型(红线和紫线)在训练集上表现比较完美,但是它们的决策边界与实例过于接近,导致在⾯对新实例时,表现可能不会太好。
而下面右图中的实线代表不仅分离了两个类别,且尽可能远离最近的训练实例。

硬间隔
在上⾯我们使⽤超平⾯进⾏分割数据的过程中,如果我们严格地让所有实例都不在最⼤间隔之间,只位于正确的⼀边,这就是硬间隔分类。
硬间隔分类有两个问题:⾸先,它只在数据是线性可分离的时候才有效;其次,它对异常值⾮常敏感。
例如,下面这两幅图,它们是鸢尾花数据。左图有一个绿点在蓝点中间,无法找出硬间隔;右图虽然找出一个硬间隔,但间隔太窄无法无法有效泛化。

软间隔
为了避免硬间隔的问题,软间隔应运而生。软间隔的⽬标是尽可能在保持最⼤间隔宽阔和限制间隔违例(即限制位于最⼤间隔之外,甚⾄在错误的⼀边的实例数量)之间找到良好的平衡。
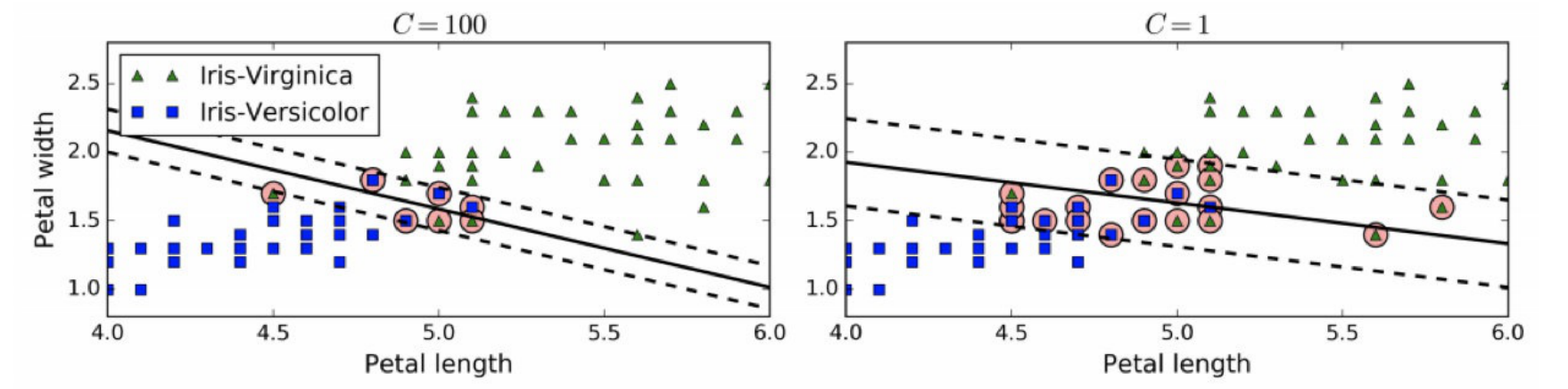
在Scikit-Learn的SVM类中,可以通过超参数C来控制这个平衡:C值越⼩则间隔越宽,但是间隔违例也会越多。
上图显示了在⼀个⾮线性可分离数据集上,两个软间隔SVM分类器各⾃的决策边界和间隔。
左边使⽤了⾼C值,分类器的错误样本(间隔违例)较少,但是间隔也较⼩。右边使⽤了低C值,间隔⼤了很多,但是位于间隔上的实例也更多。
看起来第⼆个分类器的泛化效果更好,因为⼤多数间隔违例实际上都位于决策边界正确的⼀边,所以即便是在该训练集上,它做出的错误预测也会更少。
2 SVM算法原理
2.1 线性可分支持向量机
假设特征空间上的一个线性可分离训练集为:
T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x N , y N ) } x i ∈ R n , y i ∈ { + 1 , − 1 } , i = 1 , 2 , . . . N T= \lbrace (x_1,y_1),(x_2,y_2),...,(x_N,y_N) \rbrace \\ x_i \in R^n,y_i \in \lbrace +1, -1 \rbrace,i=1,2,...N T={
(x1,y1),(x2,y2),...,(xN,yN)}xi∈Rn,yi∈{
+1,−1},i=1,2,...N
其中 ( x i , y i ) (x_i,y_i) (xi,yi)称为样本点, x i x_i xi是第i个样本, y i y_i yi为 x i x_i xi的标记【 y i = 1 时 , x i 为 正 例 ; y i = − 1 时 , x i 为 负 例 y_i=1时,x_i为正例;y_i=-1时,x_i为负例 yi=1时,xi为正例;yi=−1时,xi为负例】
为什么标记要为+1、-1呢?
其实没有太多原理,只是一个标记,我们也可以用其他数字来标记,但为了方便后面计算 y i y j = y i ∗ y j \frac{y_i}{y_j}=y_i*y_j yjyi=yi∗yj,取+1、-1比较好。
给出了上面的线性可分离训练数据集,我们可以通过间隔最大化得到分离超平面: y ( x ) = w T Φ ( x ) + b y(x)=w^T \Phi(x)+b y(x)=wTΦ(x)+b
相应的分类决策函数为: f ( x ) = s i g n ( w T Φ ( x ) + b ) f(x)=sign(w^T\Phi(x)+b) f(x)=sign(wTΦ(x)+b),这个决策函数就被称为线性可分支持向量机。
这里说明下 Φ ( x ) \Phi(x) Φ(x),前面我们引入SVM时举例了一个“拍桌子”的行为,能将二维的球“拍”到三维中的核函数就是 Φ ( x ) \Phi(x) Φ(x),它的作用就是将 x x x投影到更高维度。
例如我们看到的特征有2个, x 1 x_1 x1和 x 2 x_2 x2,它们组成了一个线性函数 w 1 x 1 + w 2 x 2 w_1x_1+w_2x_2 w1x1+w2x2
可能这两个特征并不能很好地描述数据,于是我们进行维度转化,变成 w 1 x 1 + w 2 x 2 + w 3 x 1 x 2 + w 4 x 1 2 + w 5 x 2 2 w_1x_1+w_2x_2+w_3x_1x_2+w_4x_1^2+w_5x_2^2 w1x1+w2x2+w3x1x2+w4x12+w5x22
于是我们就多了三个特征,而这个就是笼统地描述x的映射。
最简单直接的就是 Φ ( x ) = x \Phi(x)=x Φ(x)=x
上面这个表达式就也就是一个超平面 y ( x ) y(x) y(x),本质上其实就是让我们求出一组参数 ( w , b ) (w,b) (w,b),使其构建的超平面函数能最优地分离两个集合。
例如下面这幅图就是一个超平面(硬间隔):

从这幅图可以看出, w w w其实是一个法向量(两条虚线上的点垂直到实线上距离最近),而b决定超平面和原点的距离。
再例如下面这幅图(软间隔):阴影部分是⼀个“过渡带”,“过渡带”的边界是集合中离超平⾯最近的样本点落在的地⽅。

2.2 SVM计算过程与算法步骤(有点难,我也没理解透,建议跳过)
推导目标函数
我们知道了支持向量机是什么,现在我们要去寻找一个最优的超平面,再次之前我们需要建立一个目标函数。
再来看看超平面表达式: y ( x ) = w T Φ ( x ) + b y(x)=w^T\Phi(x)+b y(x)=wTΦ(x)+b,为了方便,我们设 Φ ( x ) = x \Phi(x)=x Φ(x)=x。
在样本空间中,划分超平面可以通过如下线性方程来描述: w T x + b = 0 w^Tx+b=0 wTx+b=0
- w = ( w 1 , w 2 , . . . , w d ) w=(w_1,w_2,...,w_d) w=(w1,w2,...,wd)为法向量,决定了超平面的方向
- b是位移项,决定了超平面和原点之间的距离
- 显然,划分超平面可以被法向量 w w w和位移项b确定,我们把其记为 ( w , b ) (w,b) (w,b)
因此,样本空间中任意点x到超平面 ( w , b ) (w,b) (w,b)的距离可以写为: γ = ∣ w T x + b ∣ ∣ ∣ w ∣ ∣ \gamma = \frac{|w^Tx+b|}{||w||} γ=∣∣w∣∣∣wTx+b∣
假设超平面 ( w , b ) (w,b) (w,b)能将训练样本正确分类,那么对于 ( x i , y i ) ∈ D (x_i,y_i) \in D (xi,yi)∈D
- 若 y i = + 1 y_i=+1 yi=+1,则有 w T x i + b > 0 w^Tx_i+b>0 wTxi+b>0
- 若 y i = − 1 y_i=-1 yi=−1,则有 w T x i + b < 0 w^Tx_i+b<0 wTxi+b<0
令
{ w T x i + b ≥ + 1 y i = + 1 w T x i + b ≤ − 1 y i = − 1 \begin{cases} w^Tx_i+b \ge +1 & y_i=+1\\ w^Tx_i+b \leq-1 & y_i=-1 \end{cases} {
wTxi+b≥+1wTxi+b≤−1yi=+1yi=−1
如下图所示,距离超平面最近的几个训练样本点使上式成立等号成立,它们被称为“支持向量”。
两个异类支持向量到超平面的距离之和为 γ = 2 ∣ ∣ w ∣ ∣ \gamma=\frac{2}{||w||} γ=∣∣w∣∣2,它被称为间隔。

想要找到最大间隔的划分超平面,就需要找到到满足下式中约束的参数 w w w和 b b b,使得 γ \gamma γ最大。
{ w T x i + b ≥ + 1 y i = + 1 w T x i + b ≤ − 1 y i = − 1 \begin{cases} w^Tx_i+b \ge +1 & y_i=+1\\ w^Tx_i+b \leq-1 & y_i=-1 \end{cases} {
wTxi+b≥+1wTxi+b≤−1yi=+1yi=−1
即
有 m a x ( w , b ) = 2 ∣ ∣ w ∣ ∣ 使 得 y i ( w T x i + b ) ≥ 1 , i = 1 , 2 , . . . , m 有max_{(w,b)}=\frac{2}{||w||}\\ 使得 \ \ \ y_i(w^Tx_i+b) \ge 1,i=1,2,...,m 有max(w,b)=∣∣w∣∣2使得 yi(wTxi+b)≥1,i=1,2,...,m
显然,为了最大化间隔,也就是需要最大化 1 ∣ ∣ w ∣ ∣ \frac{1}{||w||} ∣∣w∣∣1,这等价于最小化 ∣ ∣ w ∣ ∣ 2 ||w||^2 ∣∣w∣∣2,于是上式可以重写为:
有 m i n ( w , b ) = 1 2 ∣ ∣ w ∣ ∣ 2 使 得 y i = ( w T x + b ) ≥ 1 , i = 1 , 2 , . . . m 有min_{(w,b)}=\frac{1}{2}||w||^2 \\ 使得 y_i=(w^Tx+b) \ge 1,i=1,2,...m 有min(w,b)=21∣∣w∣∣2使得yi=(wTx+b)≥1,i=1,2,...m
这就是支持向量机的基本型。
目标函数求解
拉格朗日乘数法
到了这一步,终于把目标函数给建立起来了,接下来就是求目标函数的最优值。由于目标函数带有一个约束条件,所以我们可以用拉格朗日乘数法求解。【没错,就是高数里面的那个】
什么是拉格朗日乘数法呢?
拉格朗日乘数法(Lagrange multipliers)是一种寻找多元函数在一组约束下的极值的方法,这种方法可以将d个变量和k个约束条件的最优化问题转化为具有d+k个变量的无约束优化问题。【了解它作用就好,不必深究】
想要深入了解,可以看下面拉格朗日乘数法例子
以包含⼀个变量⼀个约束的简单优化问题为例,我们的⽬标函数是 f ( x ) = x 2 + 4 x − 1 f(x) = x^2 + 4x − 1 f(x)=x2+4x−1,讨论两种约束条件g(x):
在满⾜ x ≤ − 1 x\le−1 x≤−1约束条件下求⽬标函数的最⼩值;
在满⾜ x ≥ − 1 x\ge−1 x≥−1约束条件下求⽬标函数的最⼩值。

我们可以直观的从图中得到,
对于约束 1) 使⽬标值f(x)最⼩的最优解是x=−2;
对于约束 2) 使⽬标值f(x)最⼩的最优解是x=−1。
下面我们用拉格朗日乘数法求解。
当没有约束的时候,我们可以直接令⽬标函数的导数为0,求最优值。
可现在有约束,那怎么边考虑约束边求⽬标函数最优值呢?
- 最直观的办法是把约束放进⽬标函数⾥,由于本例中只有⼀个约束,所以引⼊⼀个朗格朗⽇乘⼦λ,构造⼀个新的函数,拉格朗⽇函数 h ( x ) = f ( x ) + λ g ( x ) h(x) = f(x) + \lambda g(x) h(x)=f(x)+λg(x)
该拉格朗⽇函数h(x)最优解可能在g(x)<0区域中,或者在边界g(x)=0上,下⾯具体分析这两种情况,
- 当g(x)<0时,也就是最优解在g(x)<0区域中, 对应约束1) x≤−1的情况。此时约束对求⽬标函数最⼩值不起作⽤,等价于λ=0,直接通过条件 ∇ f ( x ∗ ) = 0 \nabla f(x_*)=0 ∇f(x∗)=0,得拉格朗⽇函数h(x)最优解x=−2。
- 当g(x)=0时,也就是最优解在边界g(x)=0上,对应约束1) x≥−1的情况。此时不等式约束转换为等式约束,也就是在λ>0、约束起作⽤的情况下,通过求 ∇ f ( x ∗ ) + λ ∇ g ( x ∗ ) = 0 \nabla f(x_*)+\lambda \nabla g(x_*)=0 ∇f(x∗)+λ∇g(x∗)=0,得拉格朗⽇函数h(x)最优解x=−1。
所以整合这两种情况,必须满⾜λg(x)=0
因此约束g(x)最⼩化f(x)的优化问题,可通过引⼊拉格朗⽇因⼦转化为在如下约束下,最⼩化拉格朗⽇函数h(x),
{ g ( x ) ≤ 0 λ ≥ 0 λ g ( x ) ≥ 0 \begin{cases} g(x) \le 0 \\ \lambda \ge 0 \\ \lambda g(x) \ge 0 \end{cases} ⎩⎪⎨⎪⎧g(x)≤0λ≥0λg(x)≥0
上述约束条件称为KKT条件,该KKT条件可扩展到多个等式约束和不等式约束的优化问题。
经过拉格朗日乘数法,我们可以把目标函数转换为:
L ( w , b , α ) = 1 2 ∣ ∣ w ∣ ∣ w − ∑ i = 1 n α i ( y i ( w T ⋅ Φ ( x i ) + b ) − 1 ) L(w,b,\alpha)=\frac{1}{2}||w||^w - \sum\limits_{i=1}^n \alpha_i(y_i(w^T \cdot \Phi(x_i)+b)-1) L(w,b,α)=21∣∣w∣∣w−i=1∑nαi(yi(wT⋅Φ(xi)+b)−1)
其中,要想获得极小值,令上式后半部分为0:
$$
- \sum\limits_{i=1}^n \alpha_i(y_i(w^T \cdot \Phi(x_i)+b)-1) = 0
$$
到了这一步,目标函数还是不能开始求解,现在我们的问题是极小值极大值问题,
对偶问题
我们要将其转换为对偶问题,变成极大极小值问题,从 min max L ( w , b , α ) \min \max L(w,b,\alpha) minmaxL(w,b,α)变为 max α min ( w , b ) L ( w , b , α ) \max_{\alpha}\min_{(w,b)}L(w,b,\alpha) maxαmin(w,b)L(w,b,α)
参考资料:https://wenku.baidu.com/view/7bf945361b37f111f18583d049649b6649d70975.html
整体流程确定
我们⽤数学表达式来说明上⾯的过程:
1、首先是求 m i n w , b = L ( w , b , α ) min_{w,b}=L(w,b,\alpha) minw,b=L(w,b,α)的极大值,即
m a x α ∑ i = 1 n α i − 1 2 ∑ i = 1 n ∑ j = 1 n α i α j y i y j ( Φ ( x i ) Φ ( x j ) ) s . t . ∑ i = 1 n α i y i = 0 α i ≥ 0 , i = 1 , 2 , . . . n max_{\alpha} \sum\limits_{i=1}^n \alpha_i - \frac{1}{2}\sum\limits_{i=1}^n \sum\limits_{j=1}^n \alpha_i \alpha_j y_i y_j (\Phi(x_i) \Phi(x_j)) \\ s.t. \sum\limits_{i=1}^n \alpha_i y_i =0\\ \alpha_i \ge 0,i=1,2,...n maxαi=1∑nαi−21i=1∑nj=1∑nαiαjyiyj(Φ(xi)Φ(xj))s.t.i=1∑nαiyi=0αi≥0,i=1,2,...n
注意有两个约束条件
对目标函数添加符号,转换成求极小值:
m i n α 1 2 ∑ i = 1 n ∑ j = 1 n α i α j y i y j ( Φ ( x i ) Φ ( x j ) ) − ∑ i = 1 n α i s . t . ∑ i = 1 n α i y i = 0 α i ≥ 0 , i = 1 , 2 , . . . n min_{\alpha} \frac{1}{2}\sum\limits_{i=1}^n \sum\limits_{j=1}^n \alpha_i \alpha_j y_i y_j (\Phi(x_i) \Phi(x_j)) - \sum\limits_{i=1}^n \alpha_i \\ s.t. \sum\limits_{i=1}^n \alpha_i y_i=0\\ \alpha_i \ge 0,i=1,2,...n minα21i=1∑nj=1∑nαiαjyiyj(Φ(xi)Φ(xj))−i=1∑nαis.t.i=1∑nαiyi=0αi≥0,i=1,2,...n
2、计算上面式子的极值求出 α ∗ \alpha^* α∗
3、将 α ∗ \alpha^* α∗带入,计算 w , b w,b w,b
w ∗ = ∑ i = 1 N α i ∗ y i Φ ( x i ) b ∗ = y i − ∑ i = 1 α i ∗ y i ( Φ ( x i ) Φ ( x j ) ) w^*=\sum\limits_{i=1}^N \alpha^*_i y_i \Phi(x_i) \\ b^*=y_i-\sum\limits_{i=1}\alpha_i^*y_i(\Phi(x_i)\Phi(x_j)) w∗=i=1∑Nαi∗yiΦ(xi)b∗=yi−i=1∑αi∗yi(Φ(xi)Φ(xj))
4、求得超平面: w ∗ Φ ( x ) + b ∗ = 0 w^*\Phi(x)+b^*=0 w∗Φ(x)+b∗=0
5、求得分类决策函数: f ( x ) = s i g n ( w ∗ Φ ( x ) + b ∗ ) f(x)=sign(w^*\Phi(x)+b^*) f(x)=sign(w∗Φ(x)+b∗)
3 SVM的损失函数
这一节我们只需要了解SVM的损失函数,知道SVM中的Hinge损失函数。
在SVM中,我们主要讨论三种损失函数:

绿⾊:0/1损失
-
当正例的点落在y=0这个超平⾯的下边(上面右图),说明是分类正确,⽆论距离超平⾯所远多近,误差都是0.
-
当这个正例的样本点落在y=0的上⽅的时候(上面右图),说明分类错误,⽆论距离多远多近,误差都为1.
-
对应的图像就是上面左图中绿⾊线。 【注意左图的x轴坐标】
蓝⾊:SVM Hinge损失函数
-
当⼀个正例的点落在y=1的直线上(上面右图),距离超平⾯⻓度1,那么1-ξ=1,ξ=0,也就是说误差为0;
-
当它落在距离超平⾯0.5的地⽅,1-ξ=0.5,ξ=0.5,也就是说误差为0.5;
-
当它落在y=0上的时候,距离为0,1-ξ=0,ξ=1,误差为1;
-
当这个点落在了y=0的上⽅,被误分到了负例中,距离算出来应该是负的,⽐如-0.5,那么1-ξ=-0.5,ξ=-1.5.误差为1.5.
-
以此类推,画在⼆维坐标上就是上面左图中蓝⾊那根线了。
红⾊:Logistic损失函数
-
损失函数的公式为: l n ( 1 + e − y i ) ln(1 + e^{−y_i}) ln(1+e−yi)
-
当 y i = 0 y_i = 0 yi=0时,损失等于 l n 2 ln2 ln2,但通常我们会给这个损失函数除以 l n 2 ln2 ln2
-
这样当 y i = 0 y_i = 0 yi=0时,损失为1,即损失函数过(0,1)点
-
即上面左图中的红⾊线。
4 SVM的核方法
【SVM + 核函数】 具有极⼤威⼒,核函数并不是SVM特有的,核函数可以和其他算法也进⾏结合,只是核函数与SVM结合的优势⾮常⼤。
4.1 什么是核函数
核函数,是将原始输⼊空间映射到新的特征空间,从⽽,使得原本线性不可分的样本可能在核空间可分。

-
假设X是输⼊空间,
-
H是特征空间,
-
存在⼀个映射ϕ使得X中的点x能够计算得到H空间中的点h,
-
对于所有的X中的点都成⽴: h = ϕ ( x ) h=\phi(x) h=ϕ(x)
-
若x,z是X空间中的点,函数k(x,z)满⾜下述条件,那么都成⽴,则称k为核函数,⽽ Φ \Phi Φ为映射函数: k ( x , z ) = ϕ ( x ) ⋅ ϕ ( x ) k(x,z)=\phi(x)\cdot\phi(x) k(x,z)=ϕ(x)⋅ϕ(x)
举个例子
下⾯这张图位于第⼀、⼆象限内。我们关注红⾊的⻔,以及“北京四合院”这⼏个字和下⾯的紫⾊的字⺟。
我们把红⾊的⻔上的点看成是“+”数据,字⺟上的点看成是“-”数据,它们的横、纵坐标是两个特征。显然,在这个⼆维空间内,“+”“-”两类数据不是线性可分的。

核函数的作⽤就是⼀个从低维空间到⾼维空间的映射,⽽这个映射可以把低维空间中线性不可分的两类点变成线性可分的。
下面就是用核函数映射后的图片,绿⾊的平⾯可以完美地分割红⾊和紫⾊,两类数据在三维空间中变成线性可分的了。三维中的这个判决边界,再映射回⼆维空间中就变成了⼀条双曲线,它不是线性的。
[外链图片转存中…(img-AhWxe6Y0-1650266340229)]
在这里插入图片描述
{kind=link}
(前后轴为x轴,左右轴为y轴,上下轴为z轴)
4.2 常见核函数

多项核中,d=1时,退化为线性核;
⾼斯核亦称为RBF核。
线性核和多项式核:
-
这两种核的作⽤也是⾸先在属性空间中找到⼀些点,把这些点当做基本点,而核函数的作⽤就是找与该点距离和⻆度满⾜某种关系的样本点。
-
当样本点与该点的夹⻆近乎垂直时,两个样本的欧式⻓度必须⾮常⻓才能保证满⾜线性核函数⼤于0;⽽当样本点与基本点的⽅向相同时,⻓度就不必很⻓;⽽当⽅向相反时,核函数值就是负的,被判为反类。即,它在空间上划分出⼀个梭形,按照梭形来进⾏正反类划分。
RBF核:
-
⾼斯核函数就是在属性空间中找到⼀些点,这些点可以是也可以不是样本点,把这些点当做基本点,以这些基本点为圆⼼向外扩展,扩展半径即为带宽,即可划分数据。
-
换句话说,在属性空间中找到⼀些超圆,⽤这些超圆来判定正反类。
**Sigmoid核: **
-
同样地是定义⼀些基本点,
-
核函数就是将线性核函数经过⼀个tanh函数进⾏处理,把值域限制在了-1到1上。
总之,核函数都是在定义距离,⼤于该距离,判为正,⼩于该距离,判为负。⾄于选择哪⼀种核函数,要根据具体的样本分布情况来确定。
⼀般有如下指导规则:
1) 如果特征的数量很⼤,甚⾄和样本数量差不多时,往往线性可分,这时选⽤LR或者线性核Linear;
2) 如果特征的数量很⼩,样本数量正常,不算多也不算少,这时选⽤RBF核;
3) 如果特征的数量很⼩,⽽样本的数量很⼤,这时⼿动添加⼀些特征,使得线性可分,然后选⽤LR或者线性核Linear;
4) 多项式核⼀般很少使⽤,效率不⾼,结果也不优于RBF;
5) Linear核参数少,速度快;RBF核参数多,分类结果⾮常依赖于参数,需要交叉验证或⽹格搜索最佳参数,⽐较耗时;
6)应⽤最⼴的应该就是RBF核,⽆论是⼩样本还是⼤样本,⾼维还是低维等情况,RBF核函数均适⽤。
5 SVM回归
前面提到过的都是用SVM进行分类,其实SVM也可以回归。
SVM回归是让尽可能多的实例位于预测线上(下图的实线),同时限制间隔违例(也就是不在预测线距上的实例)。
间隔由超参数 ϵ \epsilon ϵ控制, ϵ \epsilon ϵ越大,间隔越大。

6 SVM算法API介绍
6.1 SVM算法API综述
-
SVM⽅法既可以⽤于分类(⼆或者多分类),也可⽤于回归和异常值检测。
-
SVM具有良好的鲁棒性,对未知数据拥有很强的泛化能⼒,特别是在数据量较少的情况下,相较其他传统机器学习算法具有更优的性能。
使⽤SVM作为模型时,通常采⽤如下流程:
-
对样本数据进⾏归⼀化
-
应⽤核函数对样本进⾏映射(最常采⽤的核函数是RBF和Linear,在样本线性可分时,Linear效果要⽐RBF好)
-
⽤交叉验证、网格搜索对超参数进⾏优选
-
⽤最优参数训练得到模型
-
测试
sklearn中⽀持向量分类主要有三种⽅法:SVC、NuSVC、LinearSVC,扩展为三个⽀持向量回归⽅法:SVR、NuSVR、LinearSVR。
-
SVC和NuSVC⽅法基本⼀致,唯⼀区别就是损失函数的度量⽅式不同,NuSVC中是nu参数,而SVC中是C参数;
-
LinearSVC是实现线性核函数的⽀持向量分类,没有kernel参数。
6.2 SVC
sklearn.svm.SVC(C=1.0, kernel='rbf', degree=3,coef0=0.0,random_state=None)
C:
⽤来控制损失函数的惩罚系数,类似于线性回归中的正则化系数。
C越⼤,相当于惩罚松弛变量,希望松弛变量接近0,即对误分类的惩罚增⼤,趋向于对训练集全分对的情况,这样会出现训练集测试时准确率很⾼,但泛化能⼒弱,容易导致过拟合。
C值⼩,对误分类的惩罚减⼩,容错能⼒增强,泛化能⼒较强,但也可能⽋拟合。
kernel:
算法采⽤的核函数类型,核函数是⽤来将⾮线性问题转化为线性问题的⼀种⽅法。参数选择有高数核函数“RBF”、线性核函数“Linear”、多项式核函数“Poly”、 “Sigmoid”或者⾃定义⼀个核函数。 默认的是"RBF"。
degree:
当指定kernel为’Poly’时,表示选择的多项式的最⾼次数,默认为三次多项式; 若指定kernel不是’poly’,则忽略,即该参数只对’poly’有⽤。多项式核函数是将低维的输⼊空间映射到⾼维的特征空间。
coef0: 核函数常数值(y=kx+b中的b值),只有‘poly’和‘sigmoid’核函数有,默认值是0。
6.3 NuSVC
sklearn.svm.NuSVC(nu=0.5)
nu: 训练误差部分的上限和⽀持向量部分的下限,取值在(0,1)之间,默认是0.5
6.4 LinearSVC
sklearn.svm.LinearSVC(penalty='l2', loss='squared_hinge', dual=True, C=1.0)
penalty:正则化参数, L1和L2两种参数可选,仅LinearSVC有。
loss:损失函数,
-
有hinge和squared_hinge两种可选,前者⼜称L1损失,后者称为L2损失,默认是squared_hinge,
-
其中hinge是SVM的标准损失,squared_hinge是hinge的平⽅
dual:是否转化为对偶问题求解,默认是True。
C:惩罚系数, ⽤来控制损失函数的惩罚系数,类似于线性回归中的正则化系数
7 案例:数字识别器
7.1 案例背景介绍

MNIST是计算机视觉上的“hello world”数据集,⾃1999年发布以来,这⼀经典的⼿写图像数据集已成为分类算法基准测试的基础。随着新的机器学习技术的出现,MNIST仍然是研究⼈员和学习者的可靠资源。
本次案例中,我们的⽬标是从数万个⼿写图像的数据集中正确识别数字。
数据集下载:https://download.csdn.net/download/qq_39763246/21528323
7.2 数据介绍
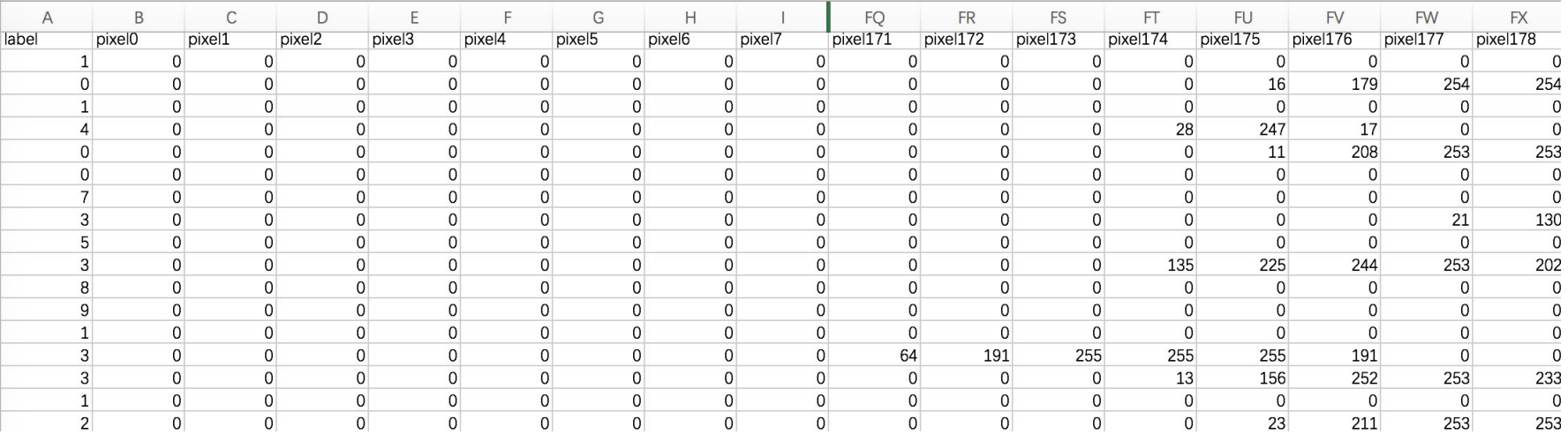
数据⽂件train.csv和test.csv包含从0到9的⼿绘数字的灰度图像。 每个图像的⾼度为28个像素,宽度为28个像素,总共为784个像素。
每个像素具有与其相关联的单个像素值,指示该像素的亮度或暗度,较⾼的数字意味着较暗。该像素值是0到255之间的整数,包括0和255。
训练数据集(train.csv)有785列。第⼀列称为“标签”,是⽤户绘制的数字。其余列包含关联图像的像素值。
训练集中的每个像素列都具有像pixelX这样的名称,其中X是0到783之间的整数,包括0和783。为了在图像上定位该像素,假设我们已经将X分解为X = i * 28 + j,其中i和j是0到27之间的整数,包括0和27。然后,pixelX位于28 x 28矩阵的第i⾏和第j列上(索引为零)。
例如,pixel31表示从左边开始的第四列中的像素,以及从顶部开始的第⼆⾏,如下所示。
在视觉上,如果我们省略“像素”前缀,像素组成图像如下:
000 001 002 003 ... 026 027
028 029 030 031 ... 054 055
056 057 058 059 ... 082 083
| | | | ...... | |
728 729 730 731 ... 754 755
756 757 758 759 ... 782 783
测试数据集(test.csv)与训练集相同,只是它不包含“标签”列。
7.3 案例实现
确定最优参数
获取数据
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.decomposition import PCA
from sklearn import svm
import time
# 1. 获取数据
train = pd.read_csv('./data/digit/digit_train.csv')
# 1.1 确定特征值和目标值。即把训练集中图像列和标签列分开
train_label = train.iloc[:,0] # 目标值
train_image = train.iloc[:,1:] # 特征值

可以调用下面方法来查看具体的数字
# 1.2 查看手写的数字
def to_plot(n):
# iloc[n,:]取出某个label后,用values取出其值,用reshape将其转为28x28格式
num = train_image.iloc[n,:].values.reshape(28,28)
# imshow是用来显示灰度图像的
plt.imshow(num)
plt.axis("off")
plt.show()
to_plot(1) # 第1个手写数字是0,从上面label里也能看出来

# 2. 数据基本处理
# 2.1 对数据进行归一化处理。可以从train_image.values里发现,大部分数据都是0或者255,归一后范围就限制到[0, 1]
train_image = train_image.values / 255
# 2.2 把目标值转为一维格式。train_label之前是包含了行索引的,用values取出值
train_label = train_label.values
# 2.3 数据集分割
x_train, x_test, y_train, y_test = train_test_split(train_image, train_label, test_size=0.2, random_state=0)

定义调优函数
# 3. 特征降维和模型训练
# 这里定义一个函数,来寻找最优的n_components
def n_components_analysis(n, x_train, y_train, x_test, y_test):
# 记录开始时间
start = time.time()
# PCA降维实现
pca = PCA(n_components=n)
print("特征降维,传递的参数:{}".format(n))
pca.fit(x_train) # 这是在训练前先进行标准化、归一化,来获取一些必要参数
x_train_pca = pca.transform(x_train) # 测试集和训练集用同样的参数,所以刚刚fit()都是x_train
x_test_pca = pca.transform(x_test)
# 机器学习 - SVC
print("开始使用svc进行训练")
ss = svm.SVC()
ss.fit(x_train_pca, y_train)
# 获取准确率
accuracy = ss.score(x_test_pca, y_test)
# 记录结束时间
end = time.time()
print("准确率:{}, 花费时间:{}, 保留的特征:{}".format(accuracy, int(end-start), pca.n_components_))
return accuracy
# 传递多个参数,寻找合理的n_components
n_s = np.linspace(0.70, 0.85, num=5) # n从0.70到0.85,共取5个
accuracy = [] # 记录每一次准确率
for n in n_s:
result = n_components_analysis(n, x_train, y_train, x_test, y_test)
accuracy.append(result)

# 将准确率可视化
plt.plot(n_s, np.array(accuracy), 'r')
plt.show()

结果预测
# 现在我们确定了最优参数,就开始真正的预测吧~
# 1. 获取数据
# 1.1 读取训练集,确定特征值和目标值
train = pd.read_csv('./data/digit/digit_train.csv')
train_label = train.iloc[:, 0] # 目标值
train_image = train.iloc[:, 1:] # 特征值
# 1.2 读取测试集
test = pd.read_csv('./data/digit/digit_test.csv')
# 2. 数据基本处理
# 2.1 对数据进行归一化处理。
train_image = train_image.values / 255
# 2.2 把目标值转为一维格式。
train_label = train_label.values
# 2.3 数据集分割 - 此时不需要分割了,整个train都是训练集,测试集是test
x_train = train_image
y_train = train_label
x_test = test
# 3. 特征工程 - 特征降维 PCA
pca = PCA(n_components=0.82)
x_train_pca = pca.fit_transform(x_train)
x_test_pca = pca.transform(x_test)
print("特征降维 - 保留的特征{}".format(x_test_pca.shape[1])) # 也可以用pca.n_components_来查看
# 4. 机器学习 - SVC
ss = svm.SVC()
ss.fit(x_train_pca, y_train)
# 5. 预测值
y_pre = ss.predict(x_test_pca)
print("预测值:\n", y_pre)

8 SVM总结
SVM是⼀种⼆类分类模型,但也可以用于多分类,它的基本模型是在特征空间中寻找间隔最⼤化的分离超平⾯的线性分类器。
1)当训练样本线性可分时,通过硬间隔最⼤化,学习⼀个线性分类器,即线性可分⽀持向量机;
2)当训练数据近似线性可分时,引⼊松弛变量,通过软间隔最⼤化,学习⼀个线性分类器,即线性⽀持向量机;
3)当训练数据线性不可分时,通过使⽤核方法及软间隔最⼤化,学习⾮线性⽀持向量机。
SVM优点:
-
在⾼维空间中⾮常⾼效;
-
即使在数据维度⽐样本数量⼤的情况下仍然有效;
-
在决策函数(称为⽀持向量)中使⽤训练集的⼦集,因此它也是⾼效利⽤内存的;
-
通⽤性:不同的核函数与特定的决策函数⼀⼀对应;
SVM缺点:
-
如果特征数量⽐样本数量⼤得多,在选择核函数时要避免过拟合;
-
对缺失数据敏感;
-
对于核函数的⾼维映射解释⼒不强,例如我们把3维特征通过核方法转换到9维,显然9维是我们不好理解的。