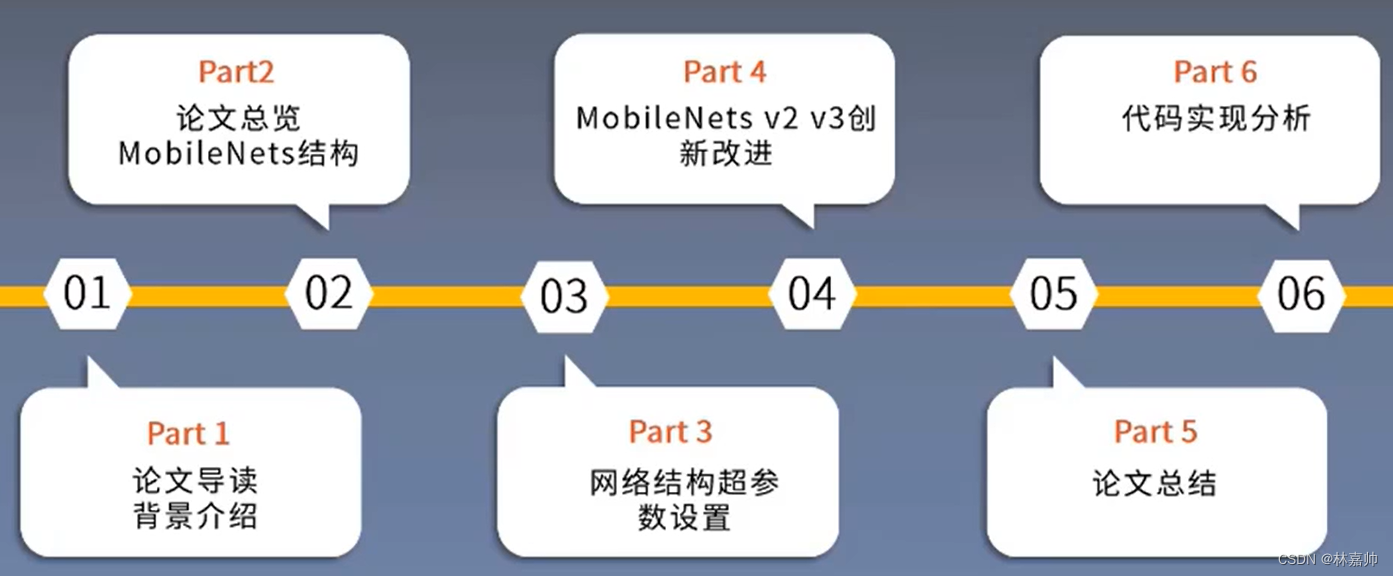
MobileNet目录
参考文献:MobileNets: Efficient ConvolutionalNeural Networks for Mobile Vision Applications
作者:Andrew G. Howard, Menglong Zhu, et al
单位:Google
发表会议及时间:CVPR 2017
前言
1. 前期知识储备
- 卷积操作: 掌握CNNs具体卷积过程,熟悉卷积核的参数意义
- ResNet: 了解残差网络基本结构,残差块的构成
- 激活函数: 了解激活函数的意义和优缺点
2. 学习目标
- 熟悉深度可分离卷积过程,体会其优势
- 掌握MobileNet构建方式,了解超参数概
- 了解后续版本创新点
- 代码复现MobileNet结构
研究背景
《动机》
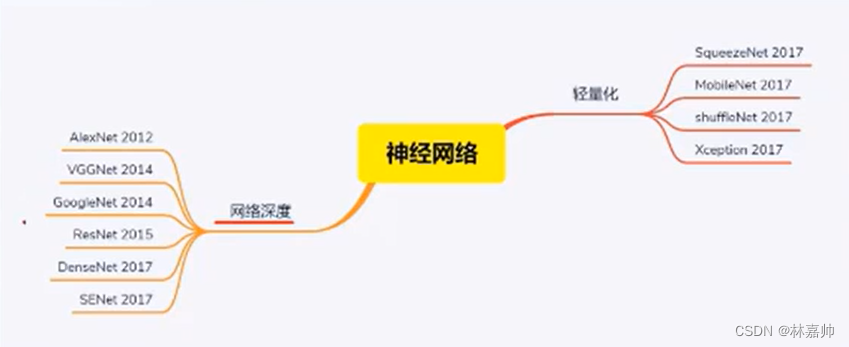
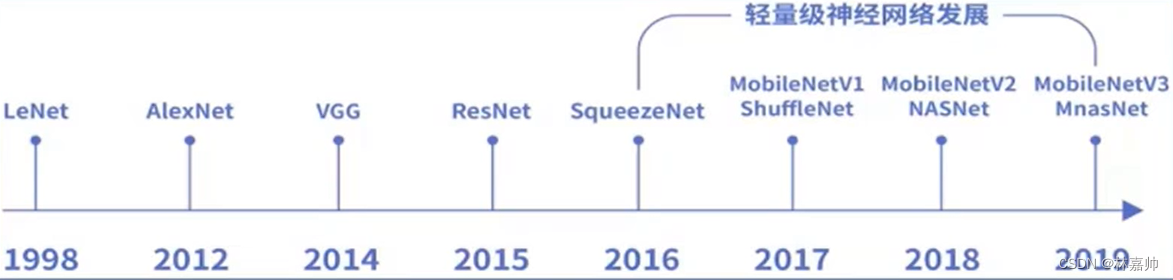
- 自AlexNet以来,神经网络倾向于更深更复杂的网络结构,但不一定在时间和内存大小上高效
- 实际应用环境中,需要在有限的算力下实时计算
《现有方法》
- 模型压缩:在已经训练好的模型上进行压缩,使得网络携带更少的网络参数
- 直接训练一个小型网络:从改变网络结构出发,设计出更高效的网络计算方式,从而使网络参数减少的同时,不损失网络的性能。
《本文方法》
- 提出了一类新型网络架构,根据应用需求与资源限制(延迟,大小),构建相匹配的小型网络
- MobileNets主要致力于优化延迟,但也可以产生小型网络
- MobileNets主要基于深度可分离卷积(depthwise separable convolutions)构成,通过设置两个超参数,实现准确率和延时性之间的平衡
研究成果
在ImageNet数据集上,在参数量减少了三十多倍的条件下,准确率与VGG16相近,只相差了0.9%(Table 8)
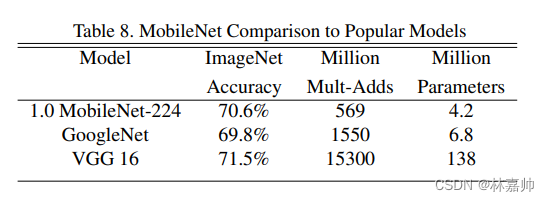
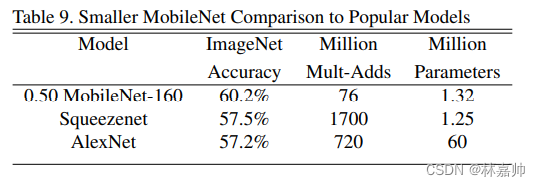
在更小结构的MobileNet中,在参数量减少了四十多倍的条件下,性能超越了Alexnet,top-1 accuracy达到60.24%,体现了本文方法的高效性。
MobileNet实现了速度与准确率的高效平衡(Table 9)
《MobileNet意义》
- 以MobileNet为代表的网络,可以在移动终端实现众多的应用,包括目标检测,目标分类,人脸属性识别和人脸识别等,使移动终端、嵌入式设备运行神经网络模型成为可能
- MobileNet拥有更小的体积,更少的计算量,更高的精度。在轻量级神经网络中拥有极大的优势
- 作为谷歌推出的开源框架,该论文引用超3700次,并推出后续v2,v3版本,推动了轻量级网络的进一步发展。
论文结构
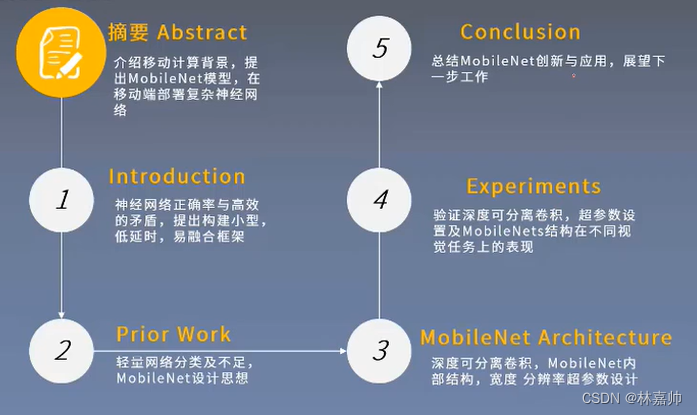

摘要
- 提出了针对移动和嵌入式视觉应用的高效神经网络MobileNets
- 以深度可分离卷积为主体构建网络结构
- 引入两个全局超参数实现准确率与延时性平衡
- 详实的实验验证了MobileNets的高效性
论文精读
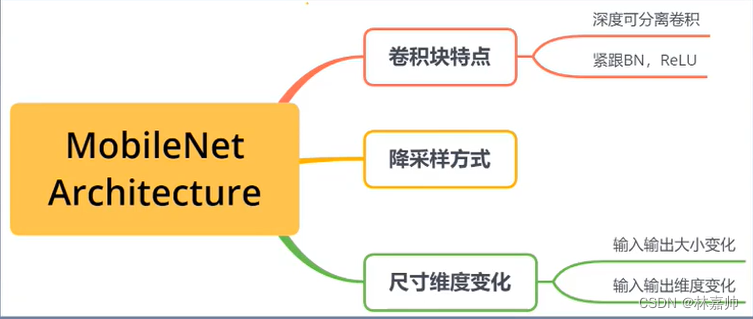
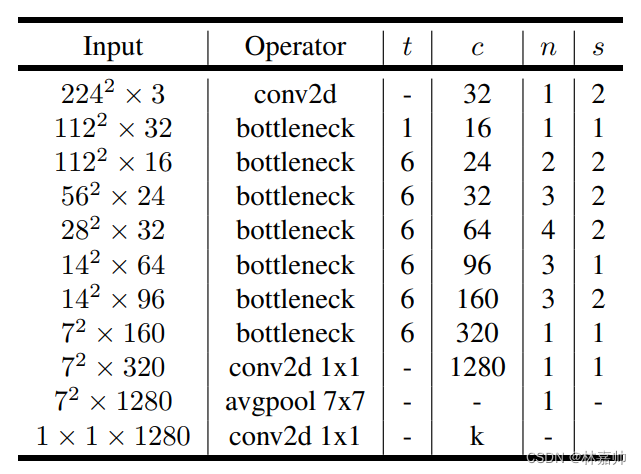
1. MobileNet Architecture
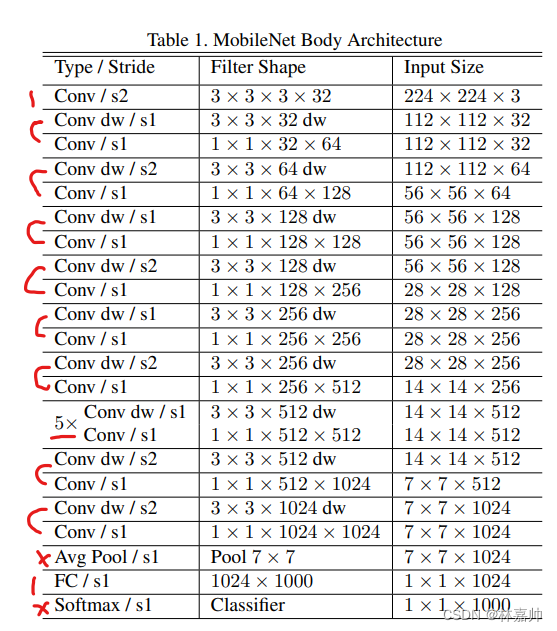
Conv:标准卷积
s2:卷积步长stride为2
s1:卷积步长stride为1
Filter Shape:3×3×3×32(Filter大小为3×3;使用的是彩色图像所以输入特征深度为3;32个卷积核)
AvgPool:平均池化
FC:全连接层
将深度卷积和点卷积看做两层,共28层
1.1 卷积块特点
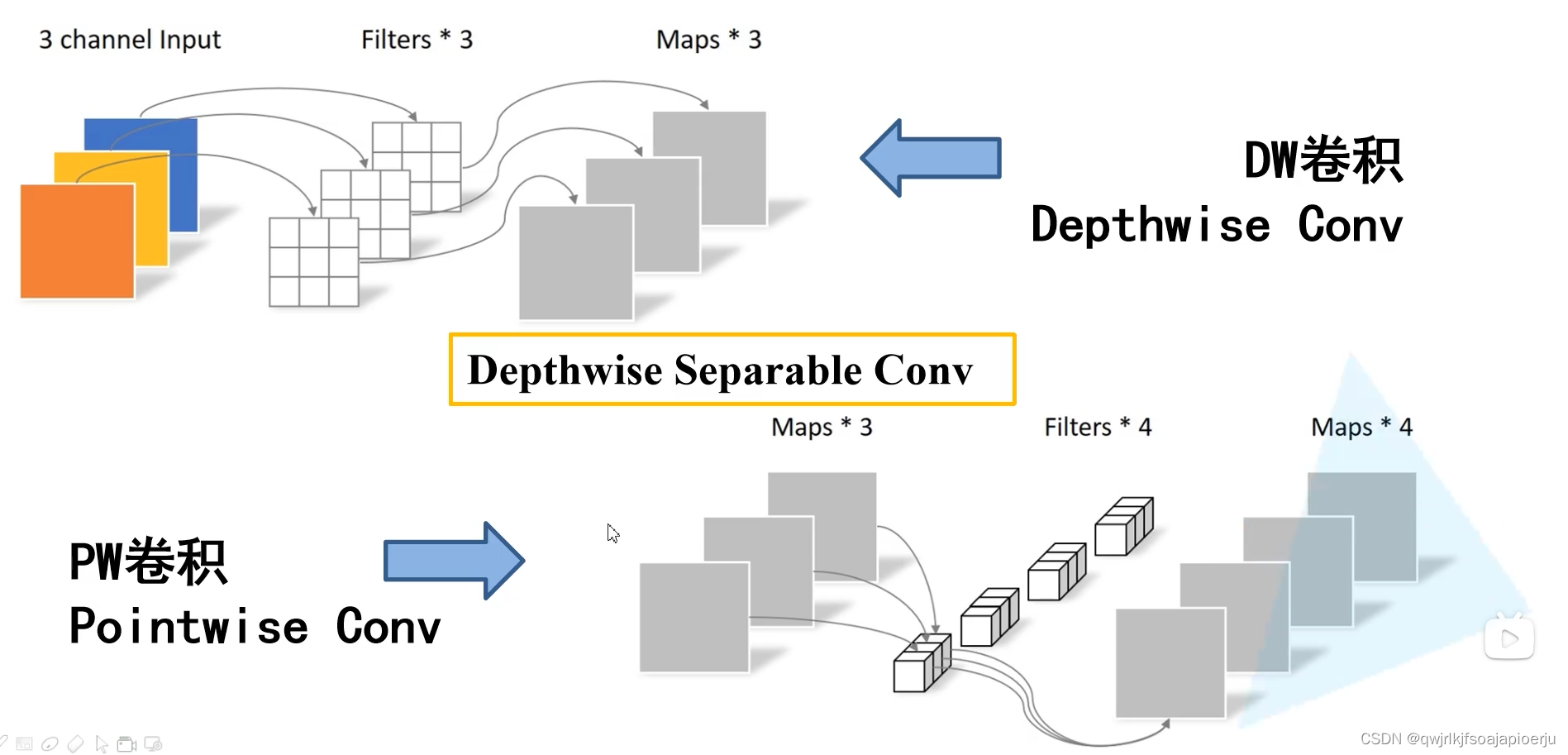
1.引入深度可分离卷积,将普通卷积替换为深度卷积和点卷积
2.除第一个卷积层和最后全连接层之外,所有卷积层后都有BN & ReLU相连

BN包含下面四个步骤
- 求平均值
- 求方差
- 归一化
- 加入宽度β 和分辨率γ 两个超参数

池化是一个非常有效的降低下采样的一个方式,但本文并不是
降采样方式
- 通过设计卷积步长stride完成降采样操作
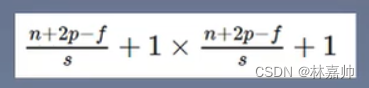

1.2 深度可分离卷积
《标准卷积》
- 输入特征矩阵channel = kernel channel
- 输出特征矩阵channel = kernnel 个数
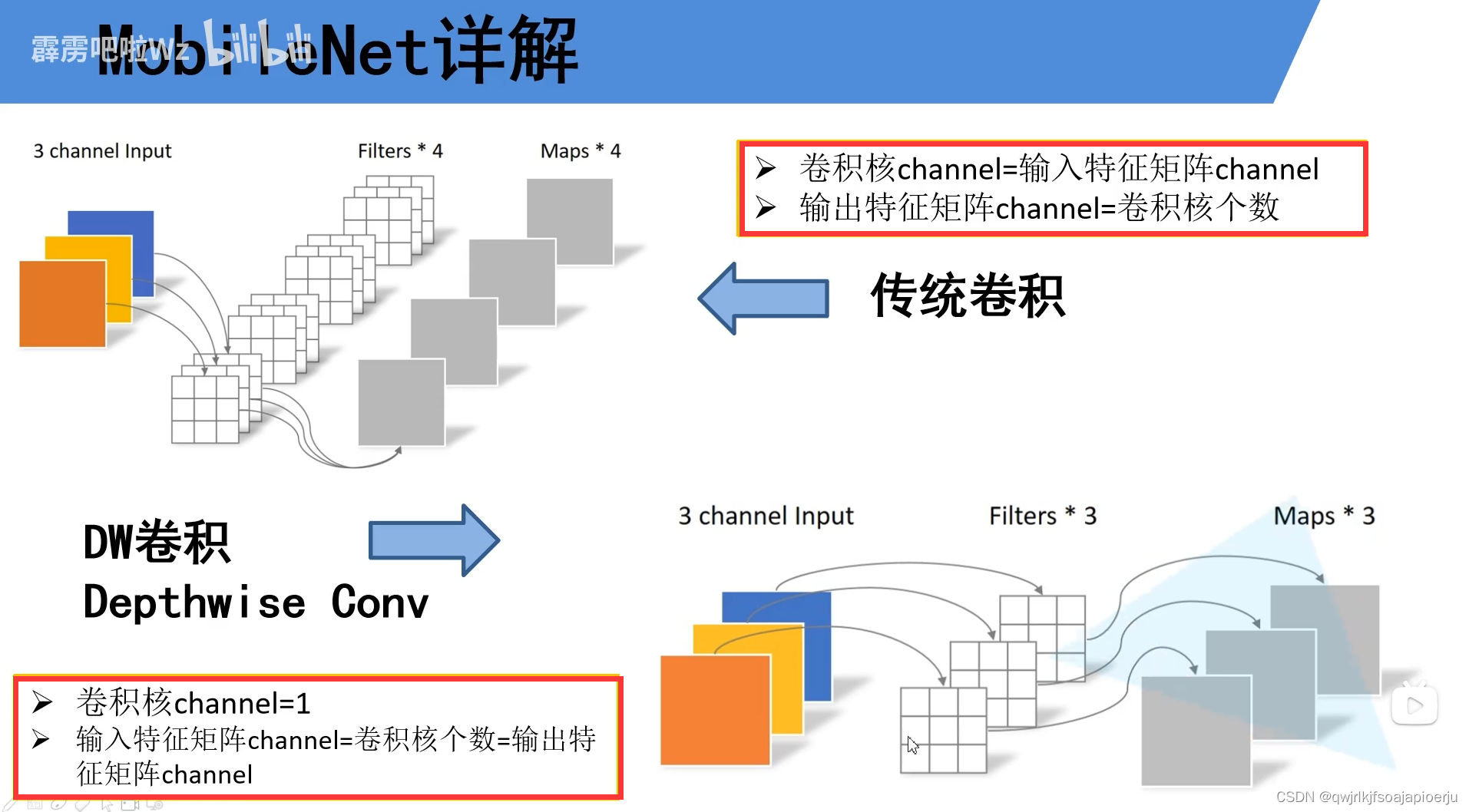
channel:翻译为深度
经过DW卷积之后,特征矩阵的深度是不变的
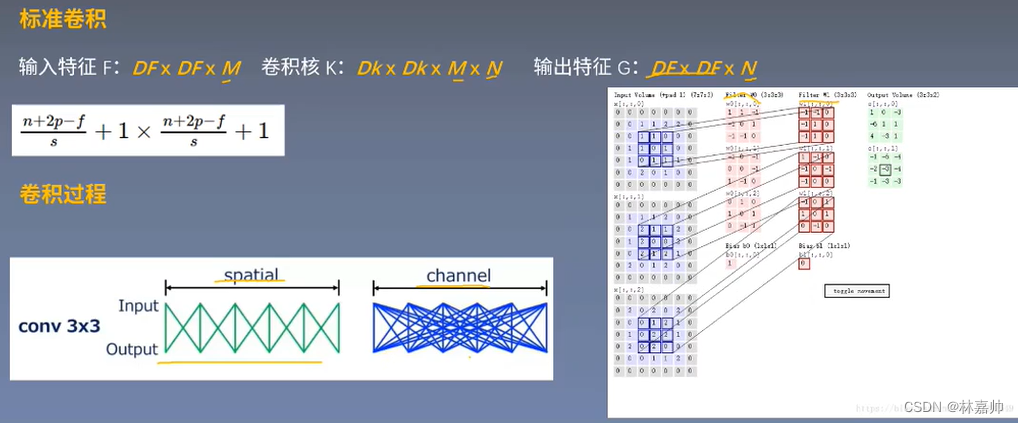
CNN的卷积核通道数 = 卷积输入层的通道数
CNN的卷积输出层通道数(深度)= 卷积核的个数
输入特征F:DF×DF×M(DF是大小;M是通道数)
卷积核K:Dk×Dk×M×N(M是通道数;一共有N个卷积核)
输出特征G:DF×DF×N(通道数:N)
在空间上: 每次连接都是卷积核与输入特征的特定区域进行稀疏连接
在通道上: 输出特征的每一个像素值都是通道与通道之间密集连接的结果
《深度可分离卷积》
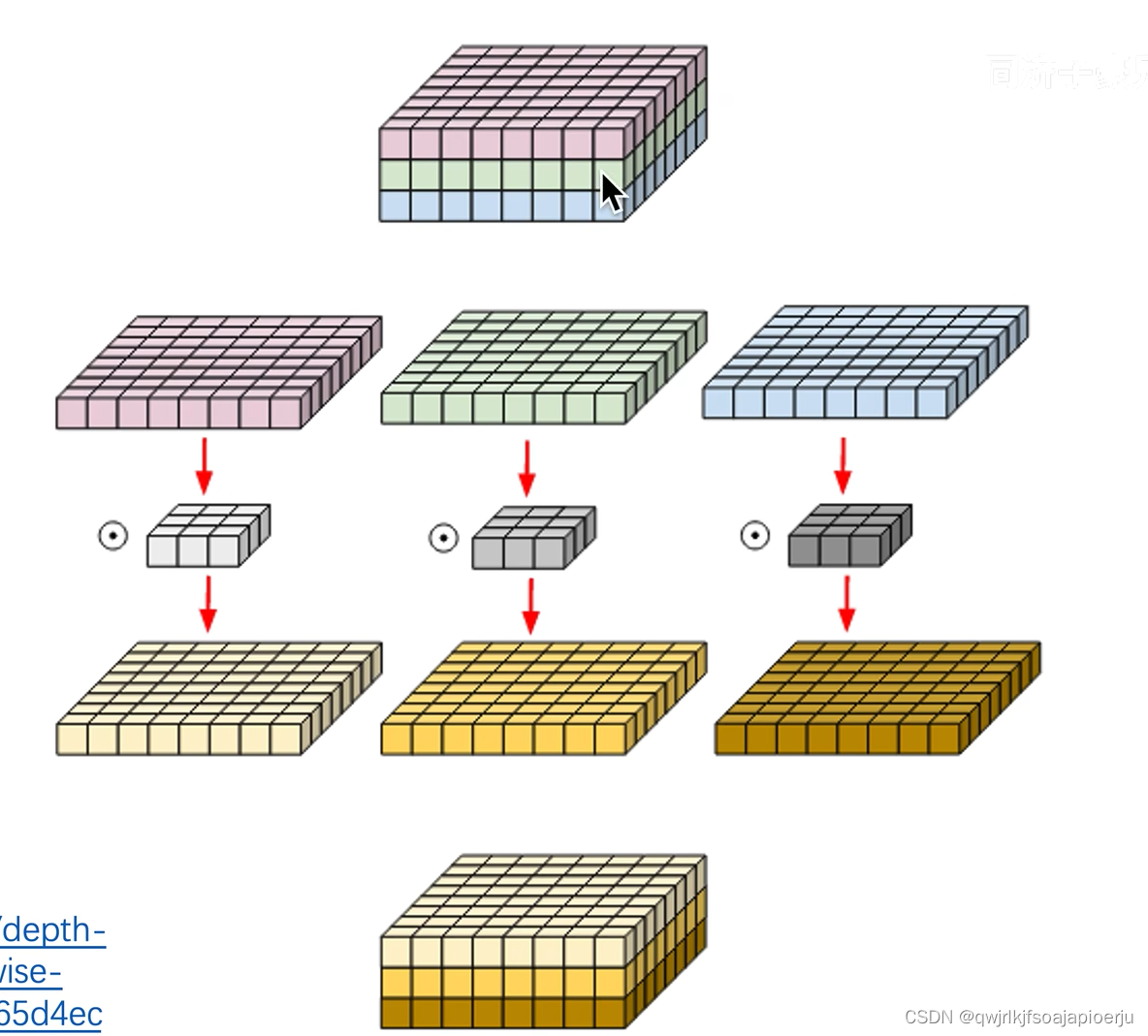
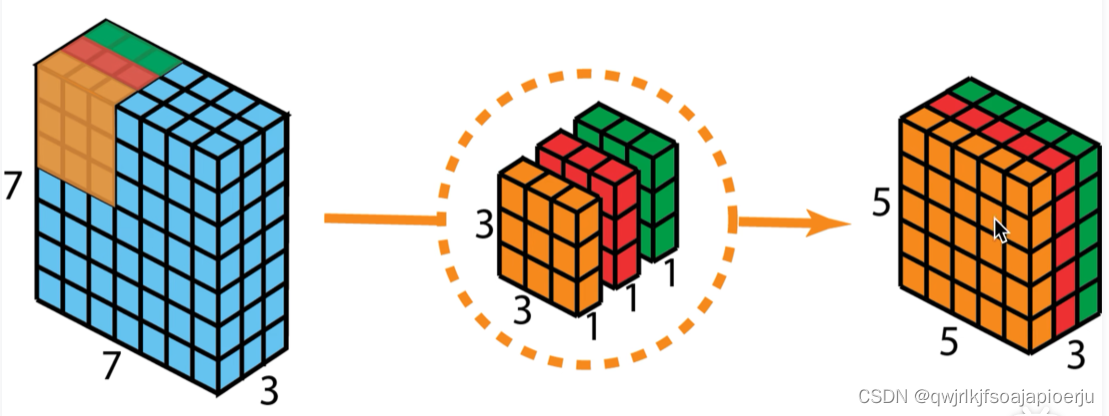
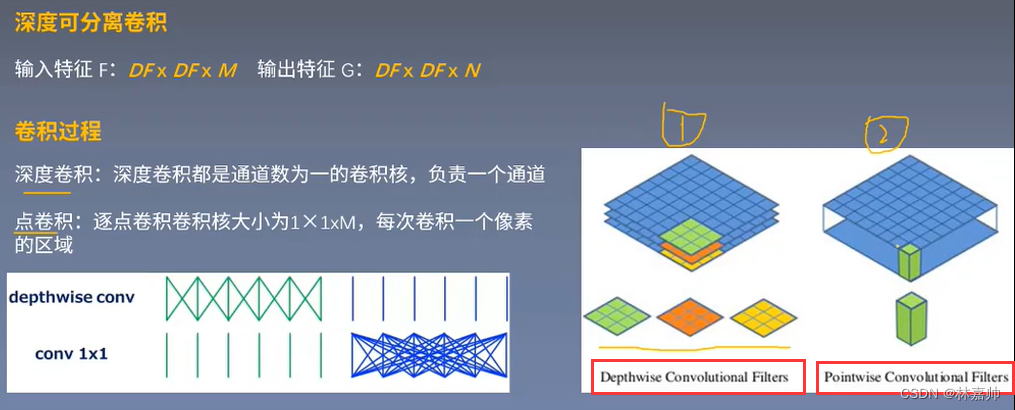
输入特征F:DF×DF×M
输出特征G:DF×DF×N(通道数:N)
第一步:探索空间中的关系
第二步:用1×1的卷积将空间之间的关系在通道之间打通,联系起来
- 3通道需要有3个卷积核对应(分别有红橙黄3个)
- 深度卷积只是在空间上进行了探索,但很多特征在通道之间是有丰富联系的,故引入点卷积
- 深度卷积: 是空间上的信息提取或信息保存
- 点卷积: 是一个普通的1×1的深度卷积,特殊点在于其大小。(一般都是3×3和5×5的,而点卷积是1×1的)
- 每次卷积都是1个像素点,在空间上是一对一的关系
1.3 两者对比

标准卷积公式
- K:是卷积核;ij是像素的位置;m是卷积核的通道数;n是有n个卷积核
- F:是卷积时对应的特征;(k+i-1,l+j-1)是正在卷积的位置,m是第几个通道
- 对应位置相乘再累加之后,就是输出结果
- 算力:一个像素点的运算量是D_KD_KM,一共像素点的数量有DF×DF×N
深度可分离卷积公式
- 没有m通道数的影响,因为在深度卷积中不考虑通道之间的联系,都是单通道
- 在训练之后,DW部分的卷积核容易废掉,因为卷积核大部分参数都为0,即DW卷积核是没起作用
运算量之比: N(输出的通道数)和K(卷积核的size)越大,比值就越大,相对于标准卷积来说算力减少就越多
2. MobileNet超参数
2.1 宽度超参数
- 为了构造更小型,更实时的网络模型满足实际应用需求
- 引入宽度超参数 α 统一规范每层的特征输入输出维度,α∈(0,1],常设为1,0.75,0.5,0.25
作用的区域为特征的通道数- input channel:M—>αM
- output channel:N—>αN
算力消耗约减少为 α² 倍

2.2 分辨率超参数
为了继续减少算力消耗
引入分辨率超参数 ρ 统一规范特征表示的分辨率大小,ρ∈(0,1] 通常跟随输入图像分辨率间接得到
Feature size: DF × DF —>ρ DF× ρ DF
算力消耗减少为原来的 ρ²

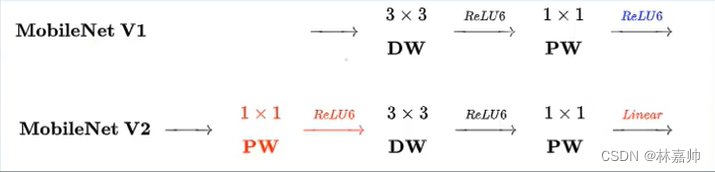
3. MobileNet V2
参考文献:MobileNetV2: Inverted Residuals and Linear Bottlenecks (2018)
3.1 线性瓶颈层(Linear Bottleneck)
- 线性瓶颈层(Linear Bottleneck): 在高维空间上,诸如ReLU这种激活函数能有效增加特征的非线性表达,但是仅限于在高维空间中,如果维度降低,在低维空间,再加入ReLU则会破坏特征。
- 在MobileNets v2中提出了Linear Bottlenecks结构,也就是在执行了降维的卷积层后面,不再加入类似ReLU等的激活函数进行非线性转化,这样做的目的也是尽可能的不造成信息丢失,瓶颈层加入非线性结构确实会伤害性能表现(原论文中Section 6 有证明)。

- 均采用PW (Point-wise)+DW (Depth-wise)的卷积方式提取特征
- V2版本在DW卷积之前新加入一个PW卷积,能动态改变特征通道
- V2去掉了第二个PW的激活函数,最大程度保留有效特征
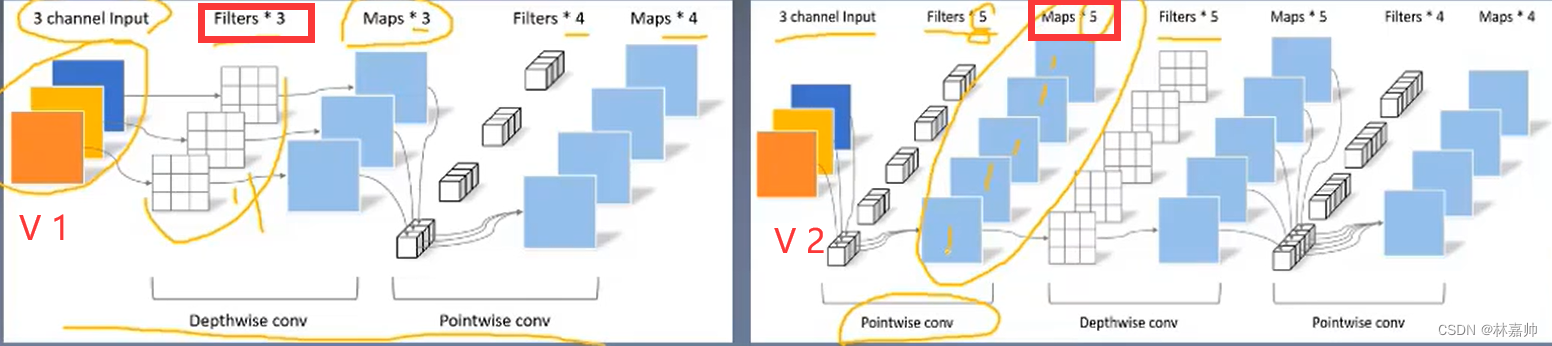
- Filters*3的为V 1版本。
- Filters*5的为V 2版本,蕴含信息更加丰富,可以提取更丰富的特征
3.2 逆残差结构(Inverted residuals)
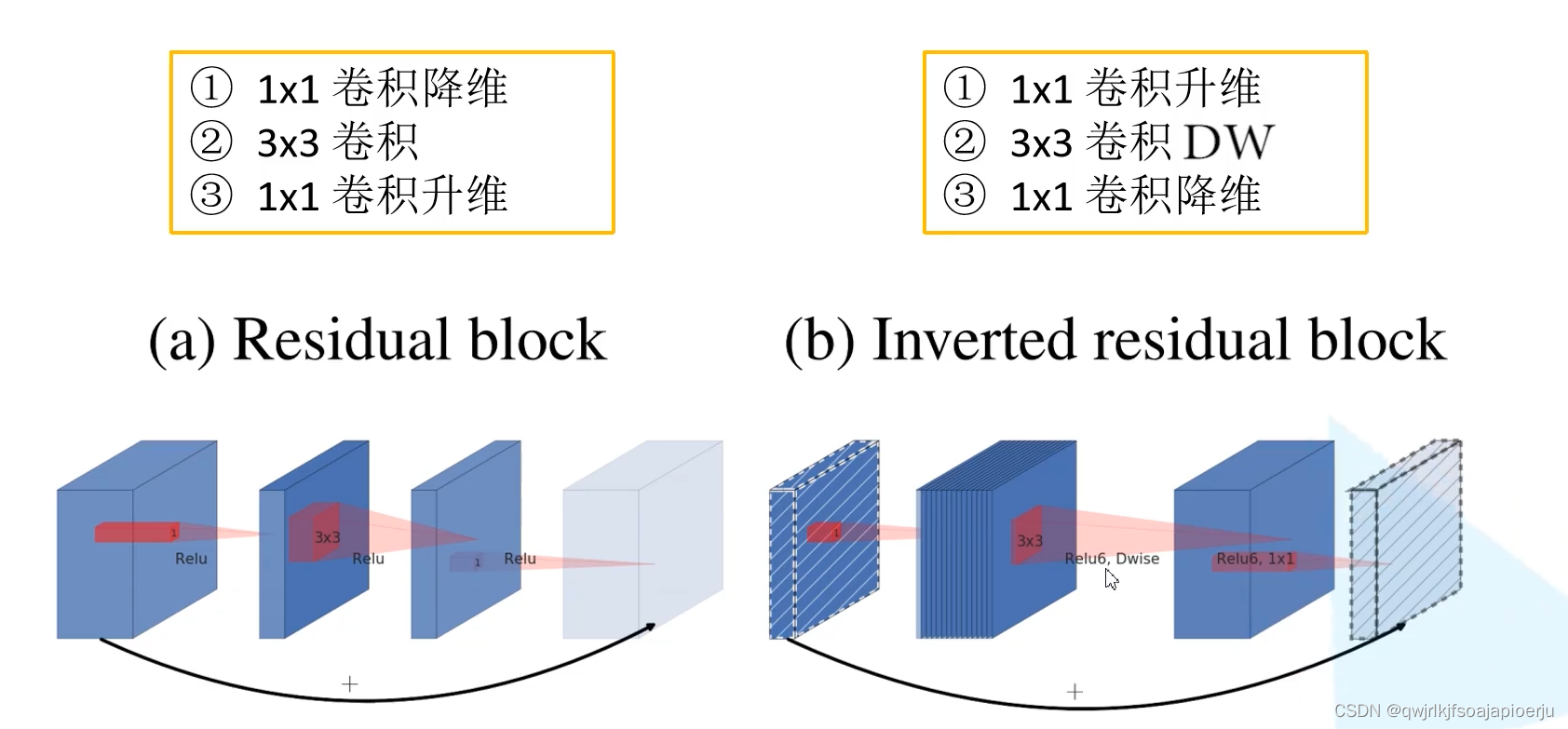
逆残差结构(Inverted residuals): 在ResNet中,为了构建更深的网络提出了ResNet的另一种形式,bottleneck,结构如下所示,一个bottleneck由一个1x1卷积(降维),3x3卷积和1xl卷积(升维)构成。在MobileNet中,Depthwise Conv卷积的层数是输入通道,本身就比较少,如果跟残差网络中的bottleneck一样,先压缩,后卷积提取,可得到的特征就太少了。采取了一种逆向的方法,先升维,卷积,再降维。
相同点
- 借鉴 ResNet,都采用了1x1->3x3->1x1的模式
- 借鉴ResNet,同样使用Shortcut 短路连接将输出与输入相加
不同点
- ResNet利用标准卷积提取特征,V2利用深度卷积(DW)提取特征
- ResNet先降维、卷积、再升维,而V2则是先升维、卷积、再降维
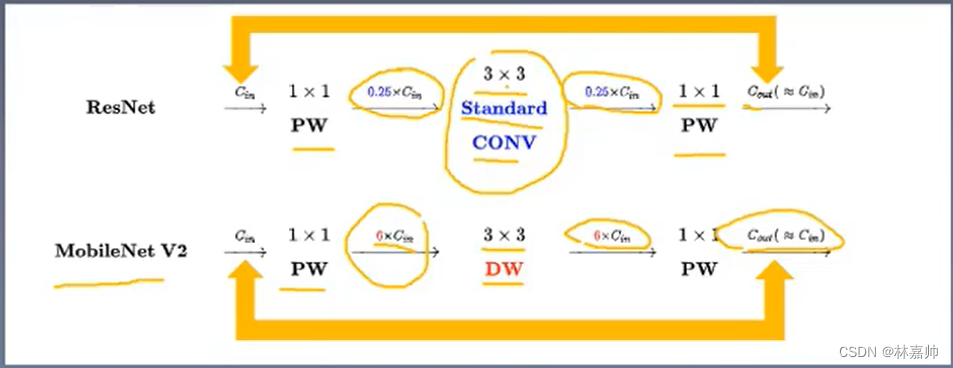
3.3 MobileNet V2 网络结构
另外,借鉴ResNet中的shortcut连接:防止梯度消失,加速网络收敛
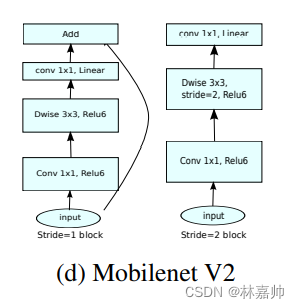
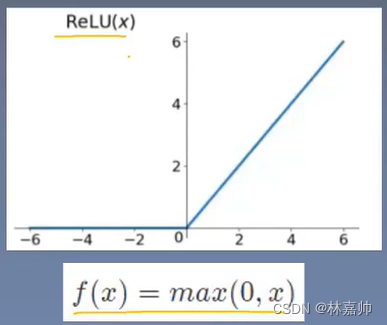
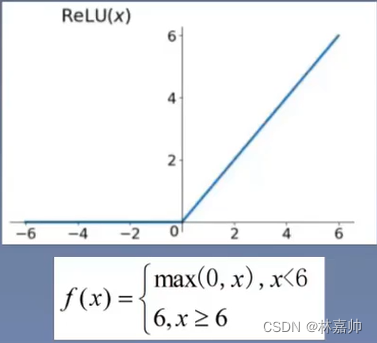
3.4 ReLU 6 函数
ReLU函数
ReLU6 函数
ReLU6对移动端很友好, 如果激活值很大,分布就会在以一个非常大的范围,会造成精度的损失,移动端也无法精确描述这种大范围的表示
4. MobileNet V3
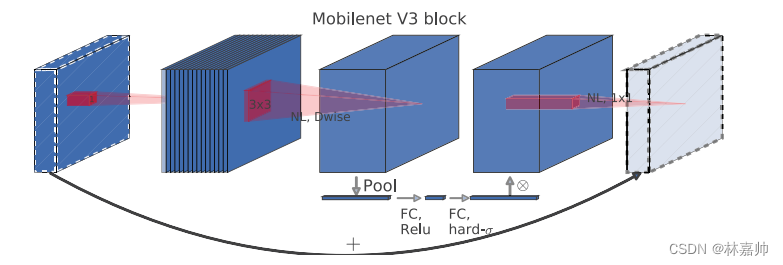
- 更新Block(bneck):
- 加入SE模块(通道的注意力机制模块 )
- 更新了激活函数
- 使用NAS搜索参数(Neural Architecture Search)
- 减少第一个卷积层的卷积核个数(32->16)
- 精简Last Stage
- 重新设计激活函数(因为太耗时)
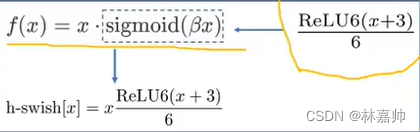
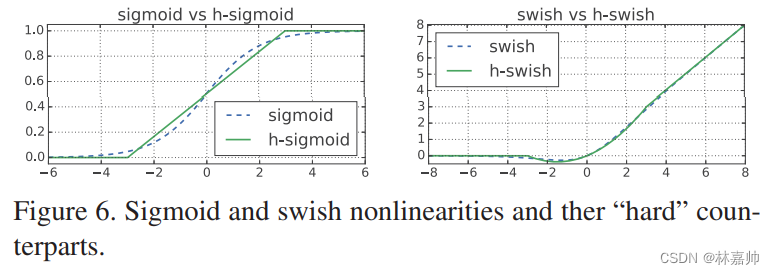
4.1 新的激活函数h-swish
sigmoid激活函数消耗计算资源
- 新的激活函数(h-swish):h-swish是基于swish激活函数的改进,所以先了解一下swish,swish具备无上界有下界、平滑、非单调的特性。并且Swish在深层模型上的效果优于ReLU
4.2 引入SENet
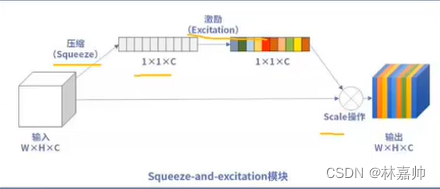
- SENet是一个轻量级注意力机制网络,通过压缩激励给不同层不同的权重
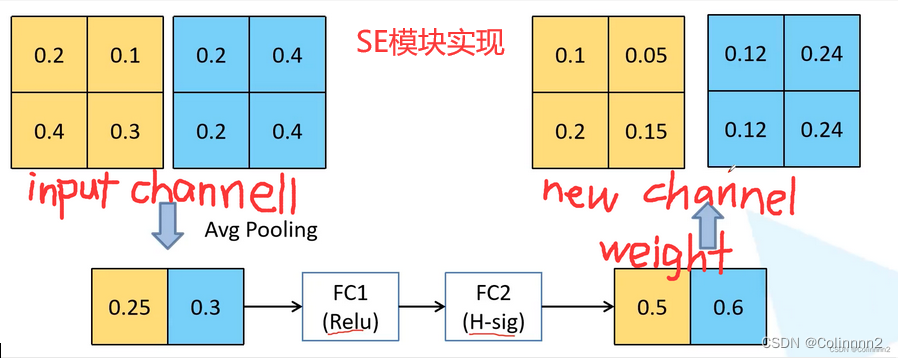
- 压缩Squeeze: 顺着空间维度进行特征的压缩,将二维的特征通道变成一个实数
- 激励Excitatiion: 类似循环网络中门的机制,通过一个参数w为每一个特征通道生成权重(不同的颜色);权重大的表明特征重要,需要保留
- Scale: 不同通道的实数乘到原先的特征中,输出的权重可以看作是经过特征选择后的每个特征通道的重要性。可以区分不同通道的重要性
- SENet描述
5. MobileNet V2和V3 的对比
MobileNet V3的特点
使用MobileNetV1的深度可分离卷积
使用MobileNetV2线性瓶颈层和逆残差结构
使用基于squeeze and excitation结构的注意力模型
网络结构
MobileNetV2模型中反转残差结构和变量利用1×1卷积,以便于拓展到高维的特征空间,虽然对于提取丰富特征进行预测十分重要,但却额外增加计算开销与延时。为了在保留高维特征的前提下减小延时,将平均池化前的层移除并用1*1卷积来计算特征

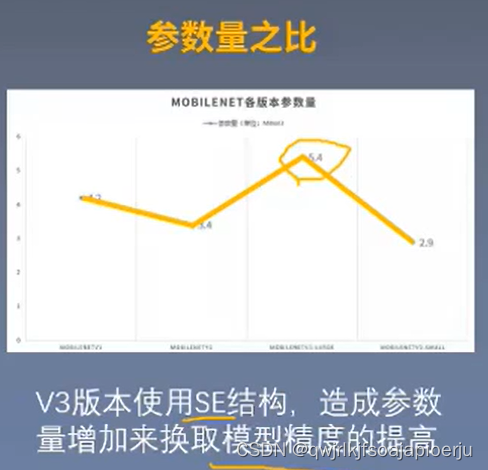
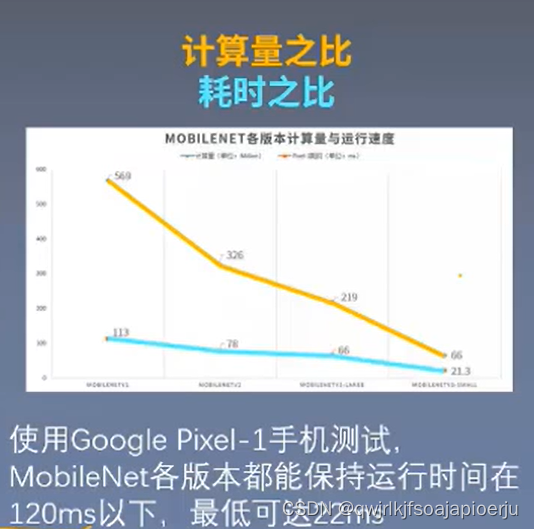
MobileNet comparison
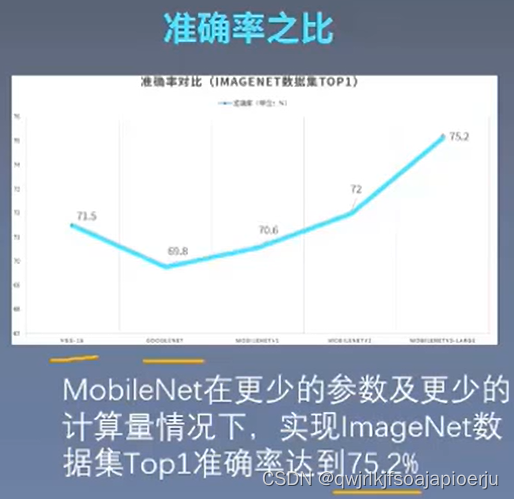
6. 实验的结果和分析
实验角度
- 深度可分离卷积对比
- 超参数设置
- 实际视觉应用
- 深度可分离卷积有效性实验
在ImageNet数据集上,在算力消耗降低8倍,参数量减少将近7倍的情况下,准确率只比标准卷积相差1%,实现了速度与准确率的良好平衡

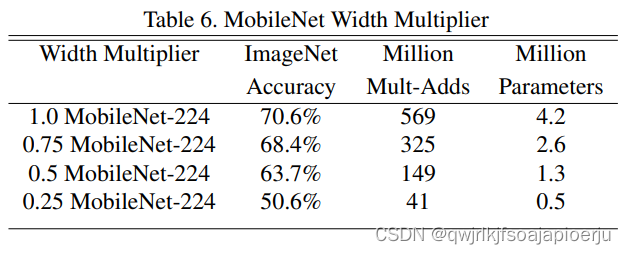
- MobileNet超参数有效性实验
通过设置宽度参数α分别为1,0.75,0.5,0.25,验尺寸的平衡。0.25时下降比较明显,是因为相对原来的结构,0.25有点过于小,信息丢失严重。
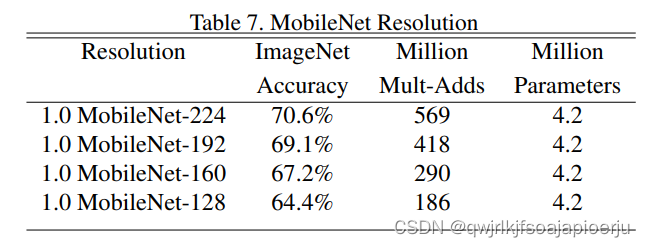
在基于上述宽度参数设置的基础上,设置分辨率为224,192,160,128,准确率在缓慢下降,相比而言,算力损失下降的非常快。
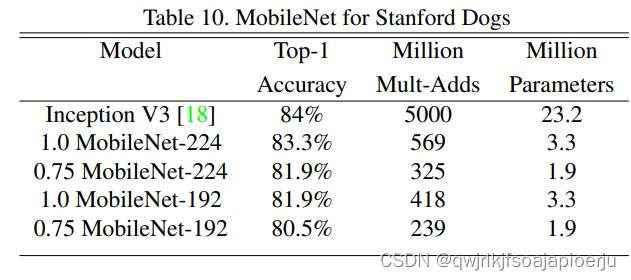
- 实际视觉应用实验
细粒度识别: 利用323/9网络上收集的噪声数据进行预训练,然后用Stanford Dog数据集进行微调,实验结果表明,在极大程度减少了算力消耗和参员量的情况下,MobileNet准确率率逼近了SOTA
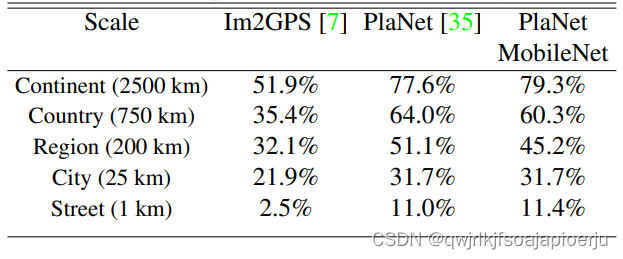
大规模地理定位: 原始的PlaNet有52million的算力消耗和5.74billion的参数量,MobileNet中只有13million和0.58million,且在某些尺度上,MobileNet超越了SOTA
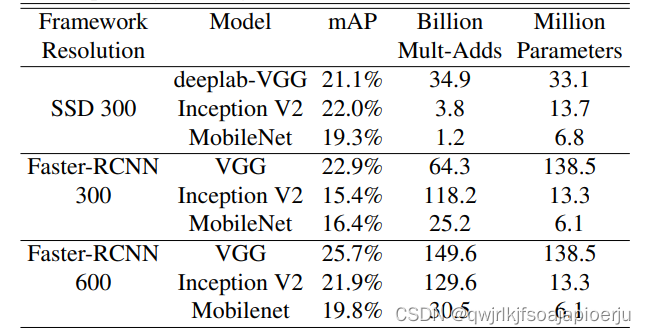
目标检测: 以SSD和Faster-RCNN为framework,构建不同目标检测框架
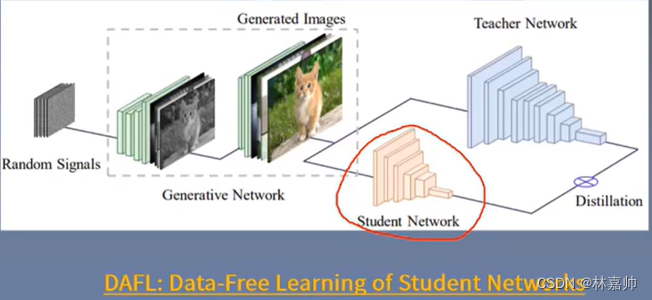
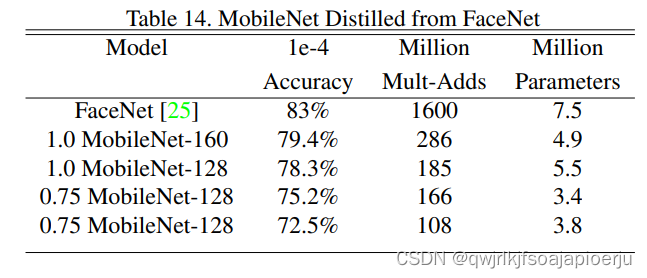
面部识别: 基于FaceNet蒸馏一个MobileNet模型
7. 论文总结
- A.关键点
- 移动计算需求
- 引入深度可分离卷积
- B.创新点
- 算法模型基础:日臻成熟的卷积神经网络
- 引入宽度和分辨率超参数
- 构建轻量级网络MobileNet结构,实现准确率,速度,大小的平衡
- C.启发点
- 移动计算的需求
- 轻量级网络的设计方向
- 卷积方式的创新
- 如何评估轻量级网络的效果
8. 代码结构
- 数据处理
- 模型统计
- 模型评估
1. 数据处理
1. 数据预处理模块(transforms)
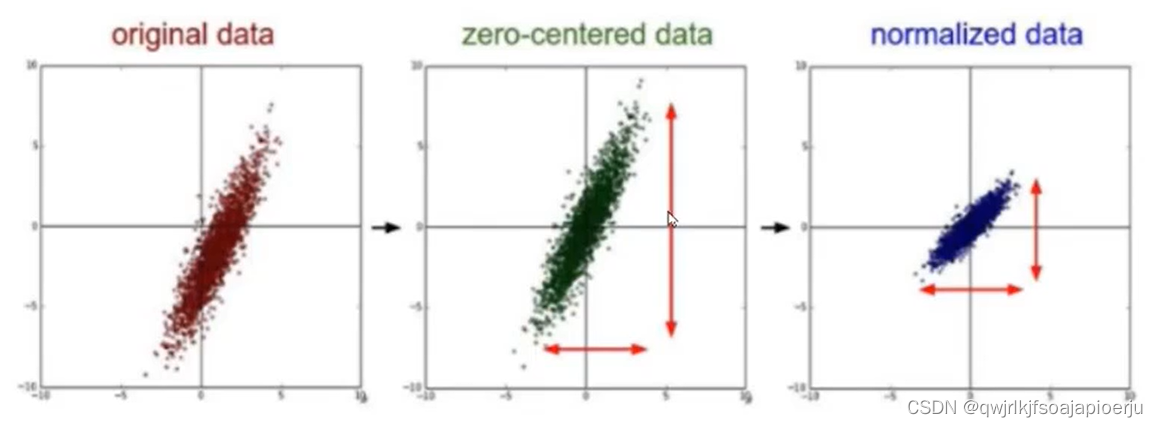
- 数据规范化处理(Normalization)
- 公式:(x-mean) /std(mean:均值,表示图像的平均水平;std:标准差,表示离散程度)
- 作用:保证所有图像具有相似分布,在训练时更加容易收敛,训练更快更好
- 数值范围:[0,1]
- zero-centered:只减去均值
- Randomcrop(size,padding:随机裁剪,根据跟定size,随机裁剪
- RandomHorizontalFlip():以0.5的概率随机水平翻
- ToTensor():转化为pytorch接受的tensor格式(所有预处理必须的)
compose:相当于一个容器这3个操作囊括起来
2. Pytorch数据加载模块(datasets)
- 训练集:验证集划分为(9:1)
- shuffle:顺序打乱
- SubsetRandomSampler():无放回的按照给定样本采样
9. 模型设计
1. 深度卷积
- 一个卷积核对应输入特征一个通道
- 每组对应一个通道的特殊分组卷积
- 深度卷积块包括深度卷积,BN层,ReLU层
2. 点卷积
- 卷积核size为1x1的标准卷积
- 点卷积块包括点卷积,BN层,ReLU层
3. MobileNet网络结构
- 28层网络结构
- 针对大图像和小图像,设置两组MobileNets结构,步长stride不同
10. 模型评估
1.损失函数:
nn.CrossEntropyLoss()交叉嫡损失函数
Softmax-log-NLL Loss
2. 模型评估
- max()返回tensor中所有元素的最大值及索引
- view_as()转换为相同格式
- eq()统计相等个数