1 Paddle模式简介
jieba中的paddle模式是指使用飞桨(PaddlePaddle)深度学习框架加速分词的一种模式。相对于传统的分词算法,paddle模式采用了深度学习模型,可以获得更高的分词准确度和更快的分词速度。
paddle模式是基于卷积神经网络(Convolutional Neural Network, CNN)实现的。在训练过程中,使用了中文Wikipedia语料库和自动标注语料库,对分词任务进行了有监督的训练。在测试过程中,通过卷积操作将文本转化为特征向量,再经过全连接层和softmax层,最终得到每个字符的概率分布,然后根据概率分布确定分词边界。
2 Paddle模式的准备
2.1 paddlepaddle库的安装
使用paddle模式分词需要先安装paddlepaddle库:
pip install paddlepaddle
如果安装过慢,可以考虑使用国内的镜像源:
1. pip install paddlepaddle -i https://pypi.tuna.tsinghua.edu.cn/simple
安装完成后,对安装情况进行检验:
import paddle.fluid
paddle.fluid.install_check.run_check()
paddle.fluid.install_check.run_check()是飞桨(PaddlePaddle)框架提供的一个安装检测函数。运行这个函数可以检查当前环境是否满足使用飞桨进行深度学习开发的要求。
2.2 安装完整性检查
run_check()函数会检查当前环境中是否安装了必要的依赖库、是否支持GPU加速、是否能够连接到飞桨的服务器等。如果检测结果为成功,则会输出相应的检测信息;否则会输出具体的错误信息,帮助用户排查问题并解决。
当输出结果为:
Running Verify Fluid Program …
Your Paddle Fluid works well on SINGLE GPU or CPU.
Your Paddle Fluid works well on MUTIPLE GPU or CPU.
Your Paddle Fluid is installed successfully! Let’s start deep Learning with Paddle Fluid now

即代表我们安装成功了。
这段检查可能会遇到使用者警告:
UserWarning: Standalone executor is not used for data parallel
warnings.warn(
W0326 13:38:53.591773 13228 fuse_all_reduce_op_pass.cc:79] Find all_reduce operators: 2. To make the speed faster, some all_reduce ops are fused during training, after fusion, the number of all_reduce ops is 1.

这个警告信息是由飞桨(PaddlePaddle)框架在使用数据并行训练时发出的。数据并行是指将大型神经网络模型划分为多个部分,然后在多个计算节点上同时训练,最后将结果进行汇总。在进行数据并行训练时,需要将不同计算节点上的梯度信息进行同步,以保证训练的正确性和收敛性。
这个警告信息实际上包含了两个部分:
UserWarning: Standalone executor is not used for data parallel表示在进行数据并行训练时,不应该使用独立的执行器(Standalone Executor),而应该使用与数据并行训练相兼容的执行器。如果使用了不兼容的执行器,可能会导致训练结果不正确或者出现异常情况。Find all_reduce operators: 2. To make the speed faster, some all_reduce ops are fused during training, after fusion, the number of all_reduce ops is 1.表示在数据并行训练过程中,发现了两个all_reduce算子(用于同步不同计算节点上的梯度信息)。为了提高训练速度,这两个算子会被融合为一个算子,从而减少计算量和通信开销。
在实际的数据并行训练过程中,这个警告信息可以忽略,不会影响训练结果的正确性和收敛性。如果需要进一步了解数据并行训练的细节和优化技巧,可以参考飞桨的相关文档和教程。
3 使用Paddle分词的代码示例
在jieba.cut的分词中,传入use_paddle=True即可开启paddle模式:
import jieba
import paddle
paddle.enable_static()
jieba.enable_paddle()
text = '动嘴就能写代码,GitHub 将 ChatGPT 引入 IDE,重磅发布 Copilot X'seg_1 = jieba.cut(text, cut_all=False)
seg_2 = jieba.cut(text, use_paddle=True)
print('精 确 模 式:', "/".join(seg_1))
print('paddle模式:', "/".join(seg_2))
其中:paddle.enable_static()用于启用静态图模式,在静态图模式下,程序通过预先构建计算图的方式进行计算,可以提高计算效率。
jieba.enable_paddle()用于启用paddle模式。
这段代码的运行结果为:
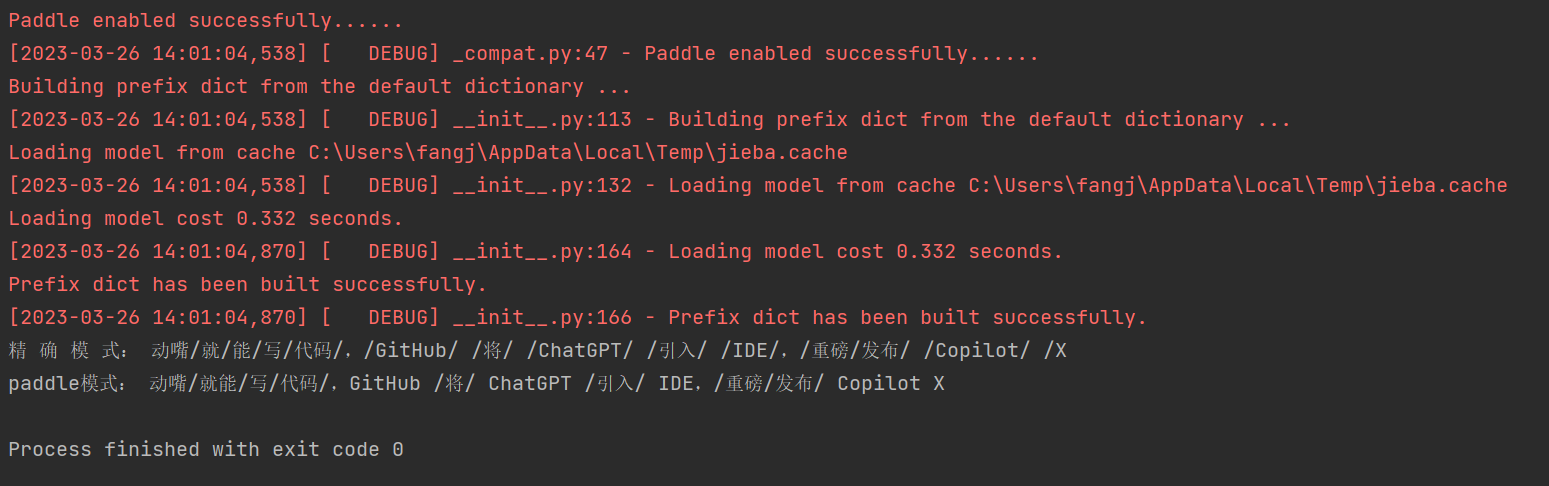
可以看到对于一些生僻词,如Copilot X,飞桨的深度学习模型可以将其分割出来,大家也可以自行尝试来判断两种模型的好坏。
需要注意的是,启用paddle模式需要满足一定的硬件和软件条件支持,例如需要支持AVX指令集的CPU和安装了CUDNN库的GPU。如果启用paddle模式失败,可以尝试使用其他分词模式。同时,在使用paddle模式时,由于需要加载深度学习模型,可能会增加程序的内存占用量。