目录
(4)linux 和 windows等其他操作系统的线程对比

(2)解释 pthread_create 创建线程的返回值pthread_t
(1)pthread_ detach(pthread_ self()); 新线程自我分离。
(2)pthread_ detach(tid1);主线程分离新线程
一.linux下的线程
1.linux下的线程概念
(1)教材上粗略的 线程 定义
1.在进程内部运行的执行流(线程在进程的虚拟地址空间中运行)
2.线程比进程力度更细调度成本更低
3.线程是CPU调度的基本单位
(2)线程的引入
fork之后,父子是共享代码的
可以通过if else判断,让父子进程执行不同的代码块——>引出不同的执行流,可以做到进行对特定资源的划分
(3)线程真正定义 以及 示意图
线程(执行流)是系统调度的基本单位!linux下没有真正的线程,Linux的线程是用进程模拟的,他叫做 轻量级进程。线程执行力度比进程更细,调度成本更低(进程切换时不需要切换页表,电地址空间等,只需要切换线程的上下文数据),因为他执行的是进程的一部分,访问的是进程的一部分资源,使用进程的一部分数据
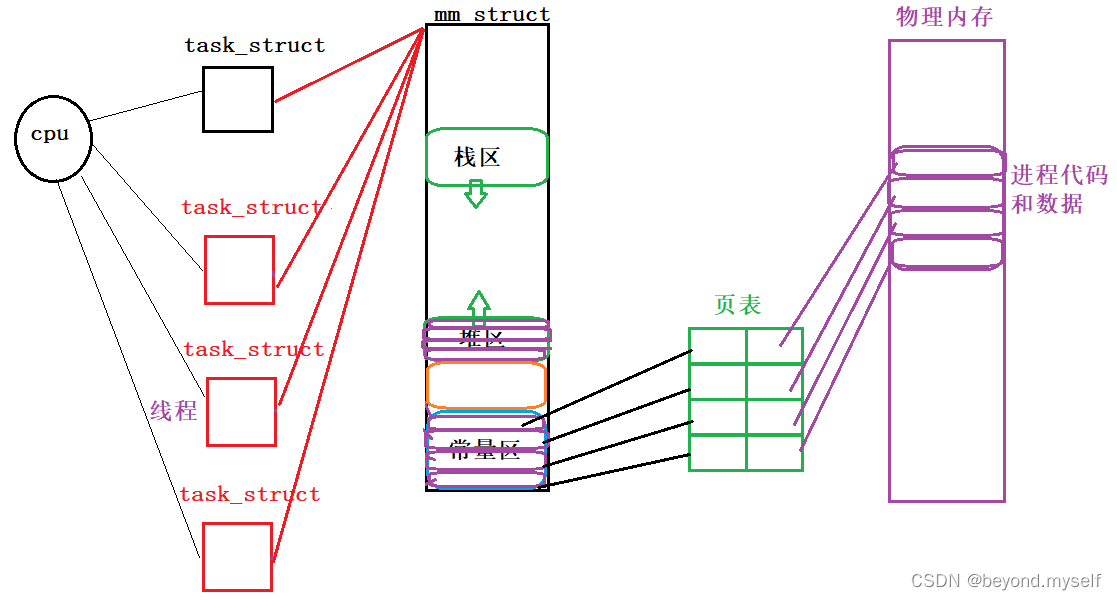
(4)linux 和 windows等其他操作系统的线程对比
Linux下认为:
进程和线程在概念上没有区别,他们都叫做执行流。
Linux的线程是用进程模拟的(实际上用进程的PCB模拟的)
linux下的tcb就是pcb,因为他们的逻辑结构是一样的
其他操作系统(例如windows)认为:
进程和线程在执行流层面是不一样的,新增了TCB这个结构体,会导致维护成本变高
线程:进程=n:1 进程——PCB;线程——TCB(thread control block)
现在CPU看到的所有的task_ struct都是一个执行流(线程)
(5)LWP
LWP——light wait process:轻量级进程。LWP=PID的执行流是主线程,俗称进程
详细概念:LWP是轻量级进程,在Linux下进程是资源分配的基本单位,线程是cpu调度的基本单位,而线程使用进程pcb描述实现,并且同一个进程中的所有pcb共用同一个虚拟地址空间,因此相较于传统进程更加的轻量化
(6)轻量级进程ID与进程ID之间的区别
因为Linux下的轻量级进程是一个pcb,每个轻量级进程都有一个自己的轻量级进程ID(pcb中的pid),而同一个程序中的轻量级进程组成线程组,拥有一个共同的线程组ID
2.重新定义进程
曾经:进程——内核数据结构+进程对应的代码和数据
现在:进程——内核视角:承担分配系统资源的基本实体 (进程的基座属性),即:向系统申请资源的基本单位!
内部只有一个执行流 task_struct 的进程——单执行流进程
内部有多个执行流 task_struct 的进程——多执行流进程
线程(执行流)是调度的基本单位!
下面紫色框起来的进程PCB,虚拟内存,页表,内存中的数据和代码,这一组资源的集合叫做一个进程。
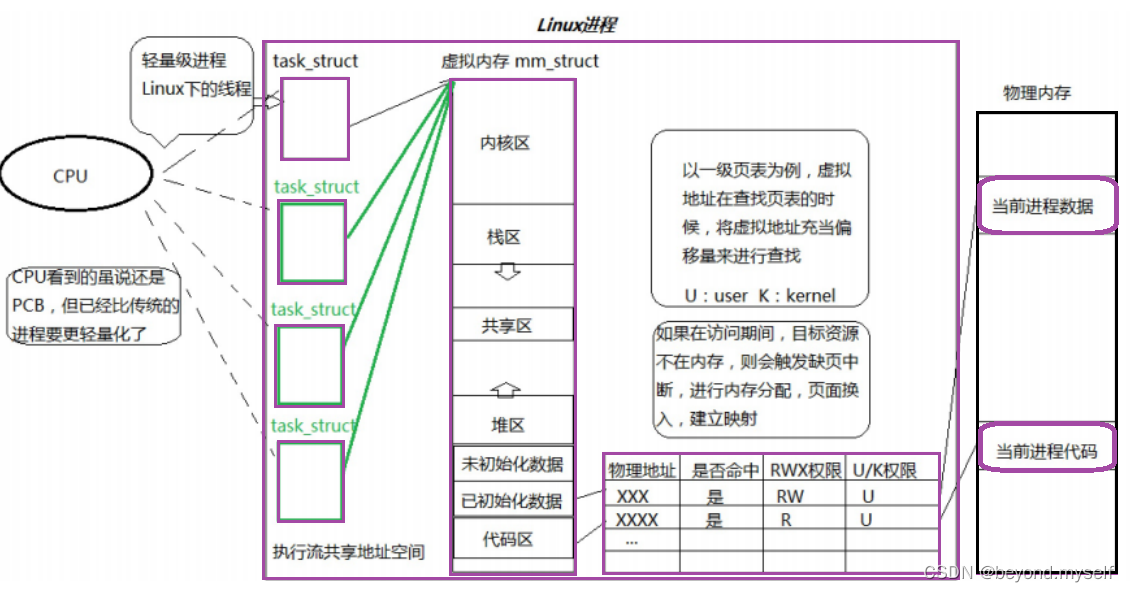
轻量级进程解释:
task_ struct <= 传统的进程PCB,如果是单执行流的进程(只有一个task_ struct时),task_ struct = 传统的进程PCB;多执行流的进程task_ struct < 传统的进程PCB
(1)线程的优点
使用多线程可以更加充分利用cpu资源,使任务处理效率更高,进而提高程序响应,即:耗时的操作使用线程,提高应用程序响应
对于多核心cpu来说,每个核心都有一套独立的寄存器用于进行程序处理,因此可以同时将多个执行流的信息加载到不同核心上并行运行,充分利用cpu资源提高处理效率,即:多CPU系统中,使用线程提高CPU利用率,CPU线程调度程序中的不同线程来共同执行整个程序,并非让CPU线程独立执行程序
(2)线程的缺点
(3)线程异常
(4)线程用途
3.线程和进程的共享/私有资源
4.进程和线程的关系
①在linux 中进程比线程安全的原因是每个进程有独立的虚拟地址空间,每个进程有自己独有的数据,具有独立性,不会数据共享这个说法是错误的,太过宽泛与片面
②多进程之间的数据共享比多线程编程复杂。线程之间的通信简单(共享地址空间和页表信息,因此传参以及全局数据都可以实现通信),而不同进程之间的通信更为复杂,通常需要调用内核(系统调用)实现
③多线程的创建,切换,销毁速度快于多进程。因为线程之间共享了进程中的大部分资源,因此共享的数据不需要重新创建或销毁,因此消耗上低于进程,反之也就是速度快于进程
④对于大量的计算优先使用多线程。大量的计算使用多进程和多线程都可以实现并行/并发处理,而线程的资源消耗小于多进程,而稳定相较多进程有所不如,因此还要看具体更加细致的需求场景
⑤“一个进程至少有一个线程”正确,但是“一个程序至少有一个进程”是错的,因为程序是静态的,不涉及进程,进程是程序运行时的实体,是一次程序的运行
⑥线程自己不拥有系统资源。因为 进程是资源的分配单位,所以线程并不拥有系统资源,而是共享使用进程的资源,进程的资源由系统进行分配
⑦任何一个线程都可以创建或撤销另一个线程。
| 对比维度 |
多进程 |
多线程 |
总结 |
| 数据共享、同步 |
数据共享复杂,需要用IPC;数据是分开的,同步简单 |
因为共享进程数据,数据共享简单,但也是因为这个原因导致同步复杂 |
各有优势 |
| 内存、CPU |
占用内存多,切换复杂,CPU利用率低 |
占用内存少,切换简单,CPU利用率高 |
线程占优 |
| 创建销毁、切换 |
创建销毁、切换复杂,速度慢 |
创建销毁、切换简单,速度很快 |
线程占优 |
| 编程、调试 |
编程简单,调试简单 |
编程复杂,调试复杂 |
进程占优 |
| 可靠性 |
进程间不会互相影响 |
一个线程挂掉将导致整个进程挂掉 |
进程占优 |
| 分布式 |
适应于多核、多机分布式;如果一台机器不够,扩展到多台机器比较简单 |
适应于多核分布式 |
进程占优 |

二.页表理解——虚拟到物理地址之间的转化
1.页表理解
虚拟地址在被转化的过程中,不是直接转化的
虚拟地址是32位的:32bit 分成 10+10+12
0101 0101 00 0100 0111 11 0000 1110 0101
XXXX XXXX xx yyyy yyyy yy zzzz zzzz zzzz
虚拟地址的前10位在一级页表——页目录中找对应的二级页表;找到对应的二级页表后,中间10位在二级页表中找对应的page的起始地址(物理内存);找到对应的page的起始地址后,后12位作为偏移量在物理内存中的一个page(4KB)中找对应数据的地址,因为后12位有2^12=4096字节=4KB,正好物理内存管理单位是一个page,一个page是4KB,则后12位正好可以覆盖一个page的所有的地址。找到地址后CPU读取物理内存的数据

2.页表的好处
(1)进程虚拟地址管理和内存管理,通过页表+page进行解耦
(2)节省空间:分页机制+按需创建页表
页表也要占据内存,页表分离了,可以实现页表的按需创建,比如页目录的第3个地址从来没使用过,就可以不创建对应的二级目录,需要时再创建。一个页表大小是2^32/2^12=2^20字节(页目录和二级页表)
虚拟地址到物理地址的转化——硬件MMU做的,软(页表)硬(MMu)件结合的方式
三.线程的接口
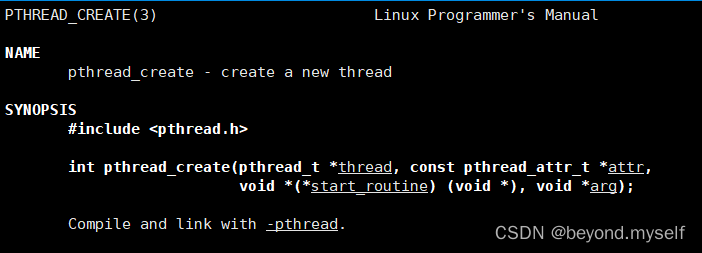
1.pthread_create 创建线程
pthread_create是一个库函数,功能是在用户态创建一个用户线程,而这个线程的运行调度是基于一个轻量级进程LWP实现的。
创建一个新线程的接口,不是系统接口,是linux带的 原生线程库,所以他是第三方库函数,需要在makefile中链接此库,g++ -o $@ $^ -lpthread -std=c++11
int pthread_create(pthread_t *thread, const pthread_attr_t *attr, void *(*start_routine) (void *), void *arg); (pthread_t 就是unsigned long int)
thread:输出型参数,线程id。attr:线程属性,现在不考虑,设成nullptr。start_routine:线程执行时的回调函数(该线程要执行的函数方法)。arg:通过这个参数传递线程的属性—现在可以传的属性:“要创建的线程的名称”,arg会传给start_routine函数的形参
返回值:成功返回0;失败返回错误码errno
例如:int n = pthread_create(&tid, nullptr, startRoutine, (void *)"thread1"); 新线程会从startRoutine函数进入执行,主线程会拿到n继续执行下面的代码
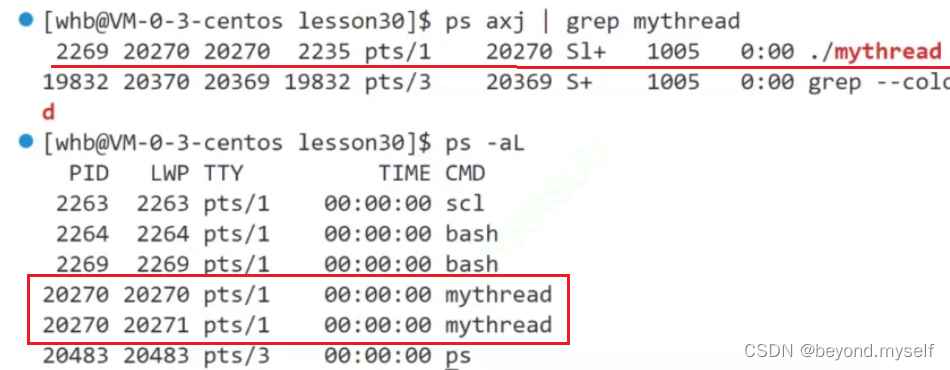
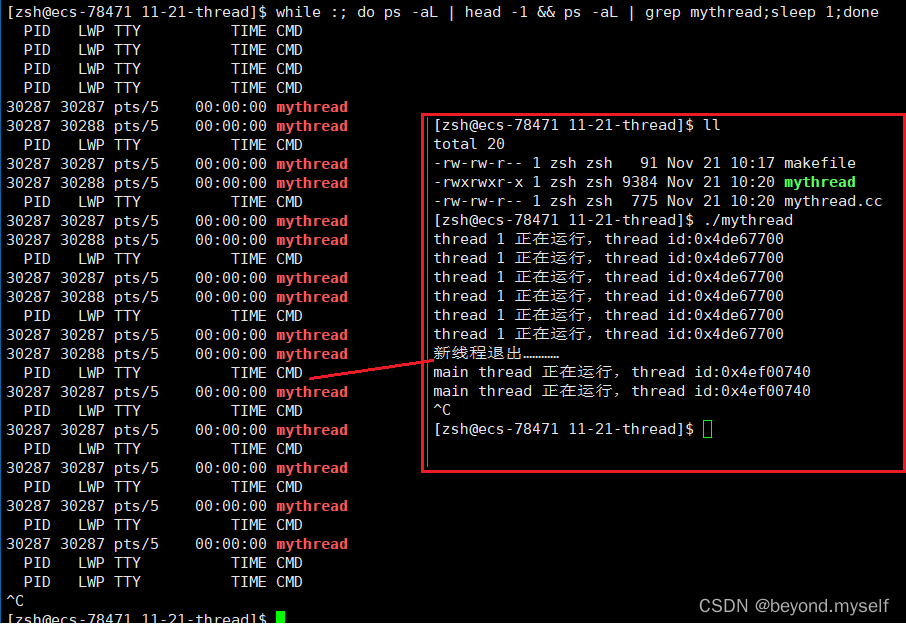
ps -aL (all light)查看所有的轻量级进程
LWP——light wait process:LWP就是轻量级进程,描述的是一个进程中的一个pcb
makefile:
mythread:mythread.cc
g++ -o $@ $^ -lpthread -std=c++11
.PHONY:clean
clean:
rm -f mythreadmythread.cc
return 退出演示
#include<cstdio>
#include<unistd.h>
#include<pthread.h>
#include<iostream>
using namespace std;
void printTid(const char* name,const pthread_t &tid)//引用
{
printf("%s 正在运行,thread id:0x%x\n",name,tid);
}
void* startRoutine(void* args)
{
const char* name=static_cast<const char*>(args);
int cnt=5;
while(true)
{
printTid(name,pthread_self());
sleep(1);
if(!(cnt--))
break;
}
cout<<"新线程退出…………"<<endl;
return nullptr;
}
int main()
{
pthread_t tid;
int n=pthread_create(&tid,nullptr,startRoutine,(void*)"thread 1");
sleep(10);
pthread_join(tid,nullptr);
while(true)
{
printTid("main thread",pthread_self());
sleep(1);
}
return 0;
}
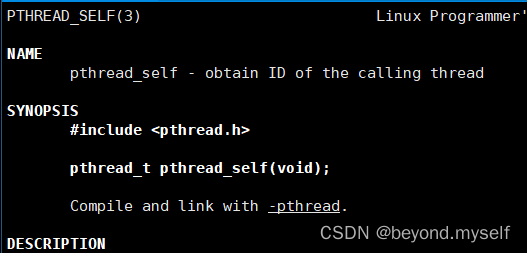
2.pthread_self
man 3 pthread_selfpthread_t pthread_self(void);
线程获取自己的线程id
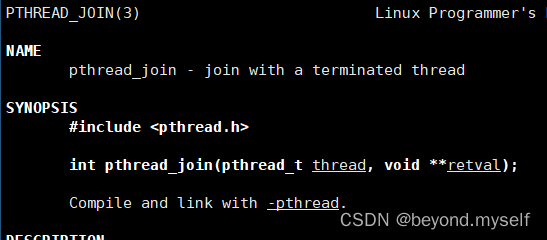
3.thread_join
man 3 pthread_joinint pthread_join(pthread_t thread, void **retval); thread:线程id。retval:输出型参数,线程退出的退出码。(join 不需要退出信号)
线程退出的时候,一般必须要进行join等待,如果不进行join,就会造成类似于进程那样的内存泄露问题。(即:作用是:释放线程资源——前提是线程退出了。并获取线程对应的退出码)
成功返回0;错误返回错误码
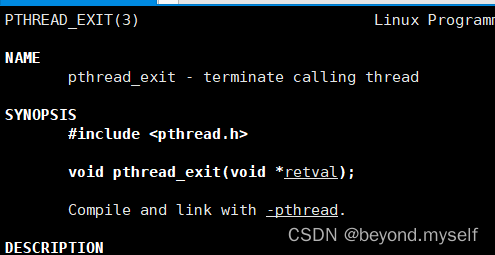
4.pthread_exit
终止线程。线程终止--只考虑正常终止
(1)pthread_exit 对比 exit
exit(1):代表退出进程,任何一个 主/新线程调用exit,都表示整个进程退出。pthread_exit()仅仅是代表退出线程。
(2)线程退出有3种:
1. 线程退出的方式,return —— return (void*)111;
2. 线程退出的方式,pthread_exit —— pthread_exit((void*)1111);
3. 线程退出的方式:线程取消请求,pthread_cancel —— pthread_ cancel(tid);
void pthread_exit(void *retval); retval:线程退出码
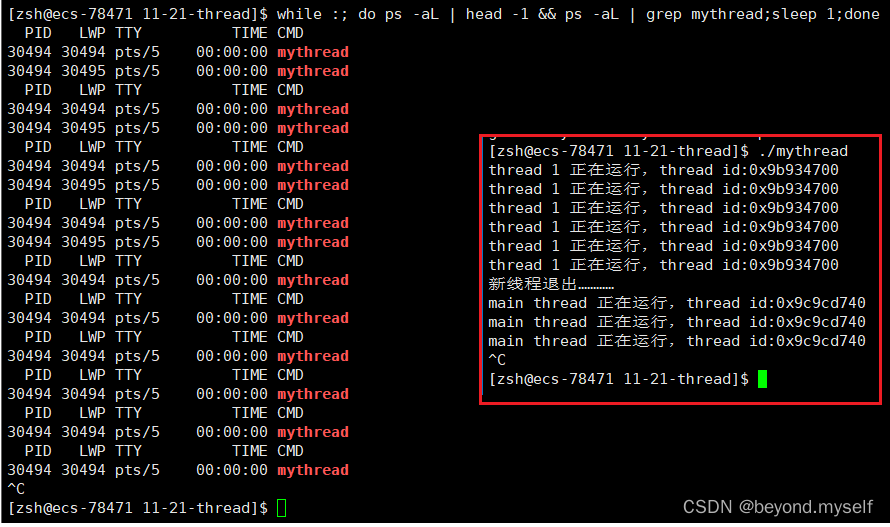
pthread_exit 退出演示
#include<cstdio>
#include<unistd.h>
#include<pthread.h>
#include<iostream>
using namespace std;
void printTid(const char* name,const pthread_t &tid)//引用
{
printf("%s 正在运行,thread id:0x%x\n",name,tid);
}
void* startRoutine(void* args)
{
const char* name=static_cast<const char*>(args);
int cnt=5;
while(true)
{
printTid(name,pthread_self());
sleep(1);
if(!(cnt--))
break;
}
cout<<"新线程退出…………"<<endl;
//return nullptr;
pthread_exit((void*)1111);
}
int main()
{
pthread_t tid;
int n=pthread_create(&tid,nullptr,startRoutine,(void*)"thread 1");
sleep(10);
pthread_join(tid,nullptr);
while(true)
{
printTid("main thread",pthread_self());
sleep(1);
}
return 0;
}
5.pthread_cancel
取消一个线程
int pthread_cancel(pthread_t thread); thread:线程id
线程退出的方式,给线程发送取消请求, 如果线程是被取消的,退出结果是:-1

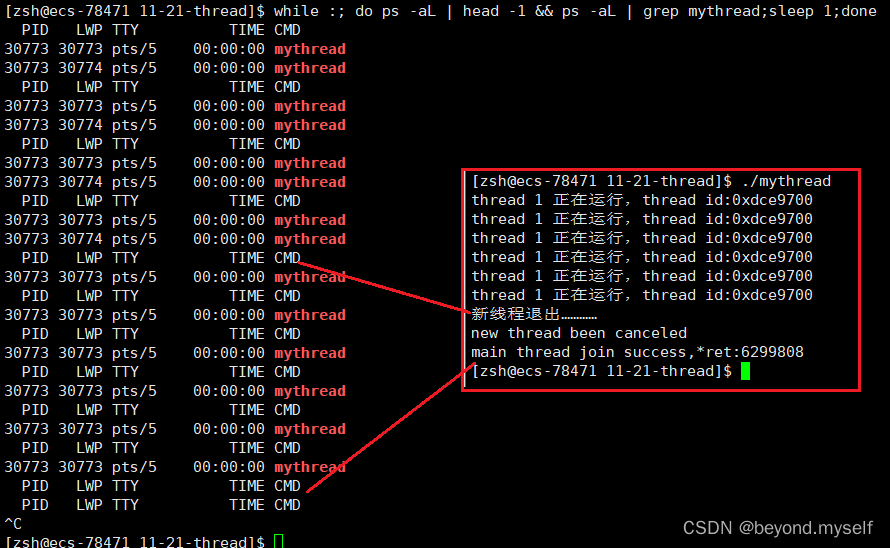
pthread_ cancel(tid); 退出
#include<cstdio>
#include<unistd.h>
#include<pthread.h>
#include<iostream>
using namespace std;
void printTid(const char* name,const pthread_t &tid)//引用
{
printf("%s 正在运行,thread id:0x%x\n",name,tid);
}
void* startRoutine(void* args)
{
const char* name=static_cast<const char*>(args);
int cnt=5;
while(true)
{
printTid(name,pthread_self());
sleep(1);
if(!(cnt--))
break;
}
cout<<"新线程退出…………"<<endl;
//return nullptr;
//pthread_exit((void*)1111);
}
int main()
{
pthread_t tid;
int n=pthread_create(&tid,nullptr,startRoutine,(void*)"thread 1");
sleep(10);
pthread_cancel(tid);
(void)n;
cout<<"new thread been canceled"<<endl;
void* ret=nullptr; //void* -> 64 -> 8byte ->空间
pthread_join(tid,&ret); //void **retval是 一个输出型参数
cout<<"main thread join success,*ret:"<<(long long)ret<<endl;
sleep(3);
return 0;
}
四.用户级线程概念
据操作系统内核是否对线程可感知,可以把线程分为内核线程和用户线程。用户级线程由应用程序所支持的线程实现, 内核意识不到用户级线程的实现。内核级线程又称为内核(系统)支持的线程。
1.线程异常了怎么办?—线程健壮性问题
线程异常了——>整个进程整体异常退出。 线程异常==进程异常
线程会影响其他线程的运行一新线程会影响主线程main thread 一健壮性/鲁棒性 较低,
2.理解 pthread_ t
是一个地址
1.线程是一个独立的执行流
2.线程一定会在自己的运行过程中,产生临时数据(调用函数,定义局部变量等)在新线程中修改全局变量后,新线程和主线程都能看到被修改后的结果
3.线程一定需要有自己的独立的栈结构
3.线程栈
(1)代码区有三类代码
我们使用的线程库,用户级线程库,库的名字叫pthread
代码区有三类代码:
①你自己写的代码。
②库的接口代码。(例如动态库libpthread. so会写入内存,通过页表映射到进程的共享区,代码区的库接口代码通过跳转到共享区执行完库中的代码,然后再跳转回代码区继续执行)
③系统接口代码。(通过身份切换 用户—>内核 执行代码)
所有的代码执行,都是在进程的地址空间当中进行执行的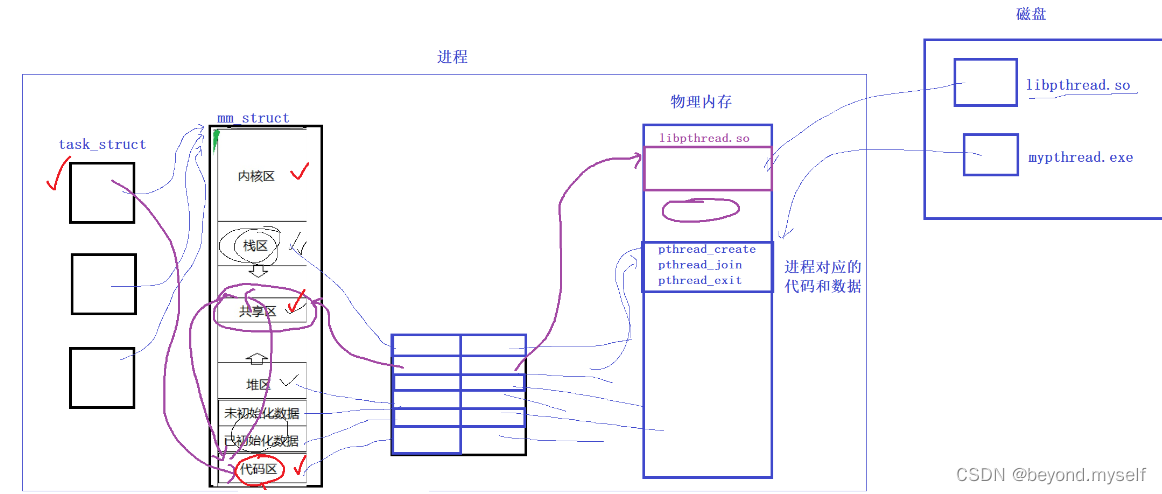
(2)解释 pthread_create 创建线程的返回值pthread_t
用户要用线程,但是OS没有线程的概念,libpthread. so线程库起承上启下的作用。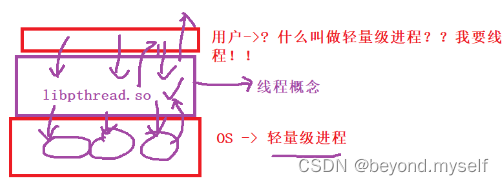
共享区内:
线程的全部实现,并没有全部体现在OS内,而是OS提供执行流,具体的线程结构由库来进行管理。库可以创建多个线程->库也要管理线程->管理:先描述,在组织
struct thread_ info
{
pthread_ t tidh .
void *stack; //私有栈
……
}
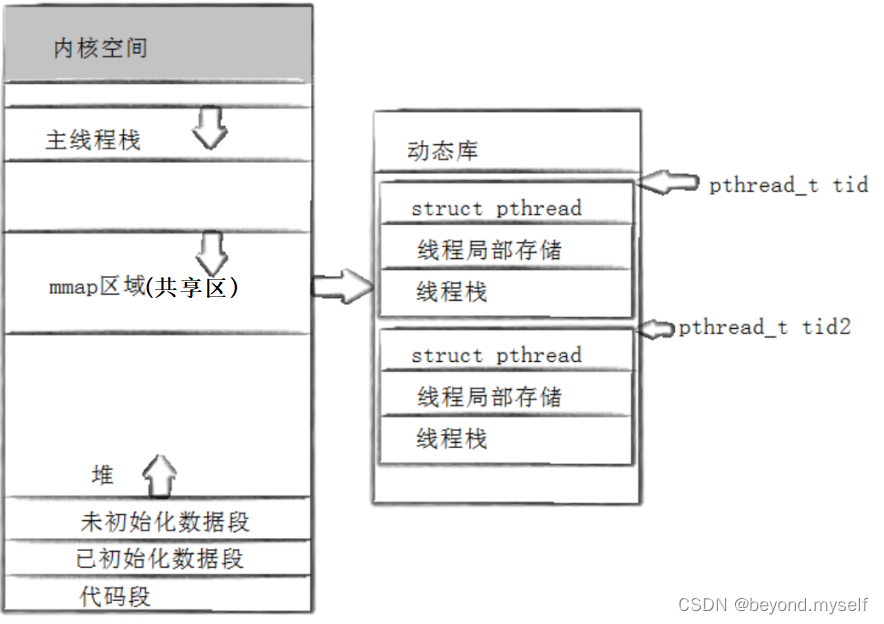
libpthread. so线程库映射进共享区中。创建线程时,线程库中也会创建一个 结构体struct thread_ info叫做 线程控制块, 线程控制块内部是描述线程的信息,内部有一个指针指向mm_struct用户空间的一块空间——线程栈。创建线程成功后,返回一个pthread_t类型的地址,pthread_t类型的地址保存着我们共享区中对应的用户级线程的线程控制块的起始地址!
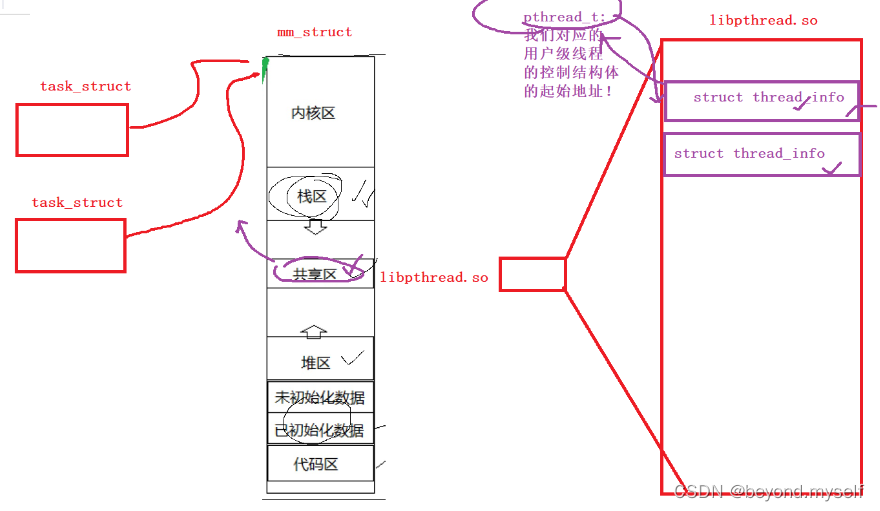
结论:主线程的独立栈结构,用的就是地址空间中的栈区;新线程用的栈结构,用的是库中提供的栈结构(这个线程栈是库维护的,空间还是用户共享区提供的)
Linux中,线程库用户级线程库,和内核的LWP是1:1(LWP(类比PID)——light wait process:轻量级进程编号。LWP=PID的执行流是主线程,俗称进程)
(3)线程局部存储
线程库中的结构体struct thread_ info,内部是描述线程的信息,struct thread_ info中还有一个叫做线程局部存储的区域。作用:可以把全局变量私有化
正常情况全局变量是多个线程可以同时修改的:
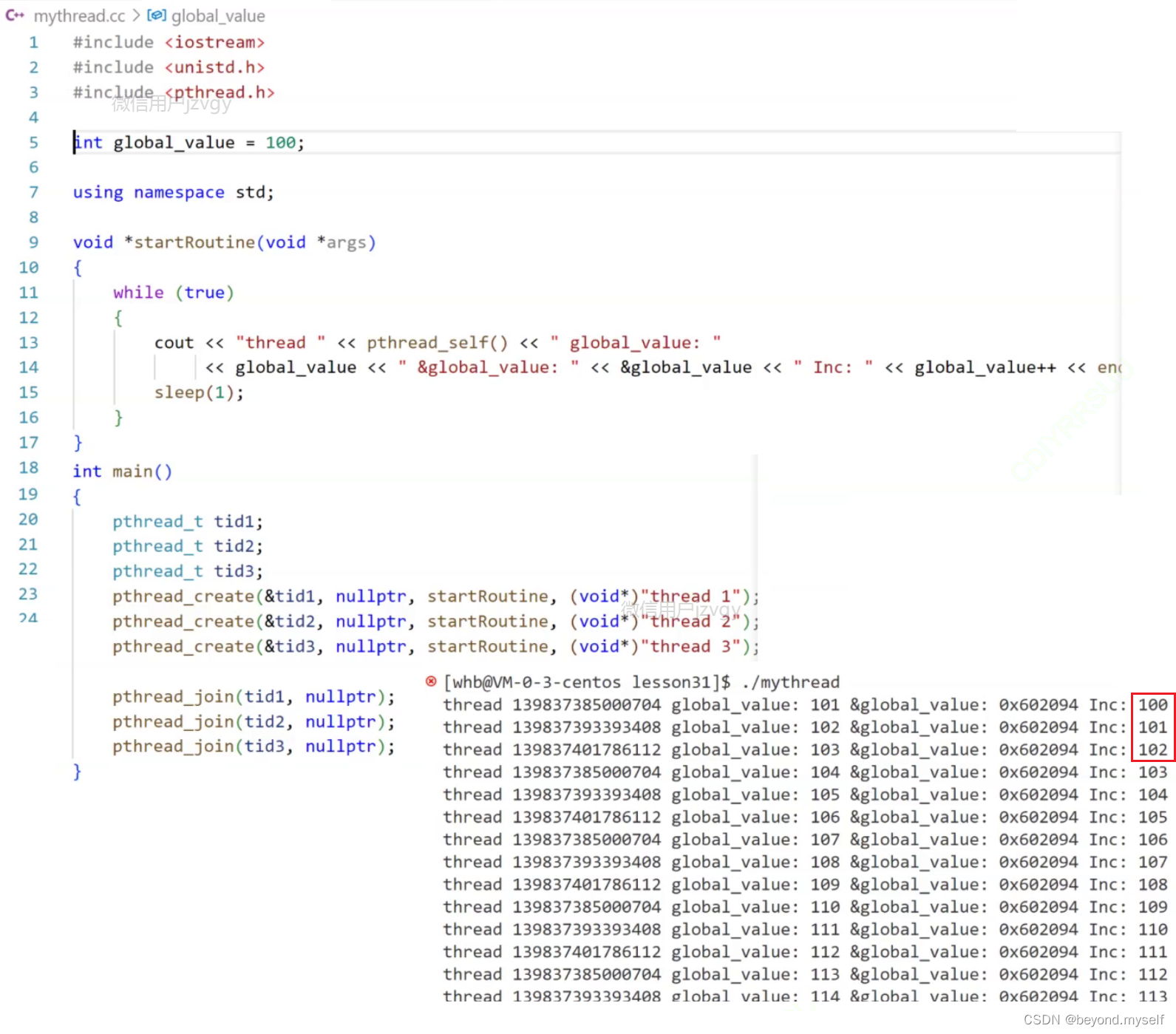
加上__thread,把全局变量拷贝给每个进程各一份,使全局变量私有化,各自修改自己的全局变量
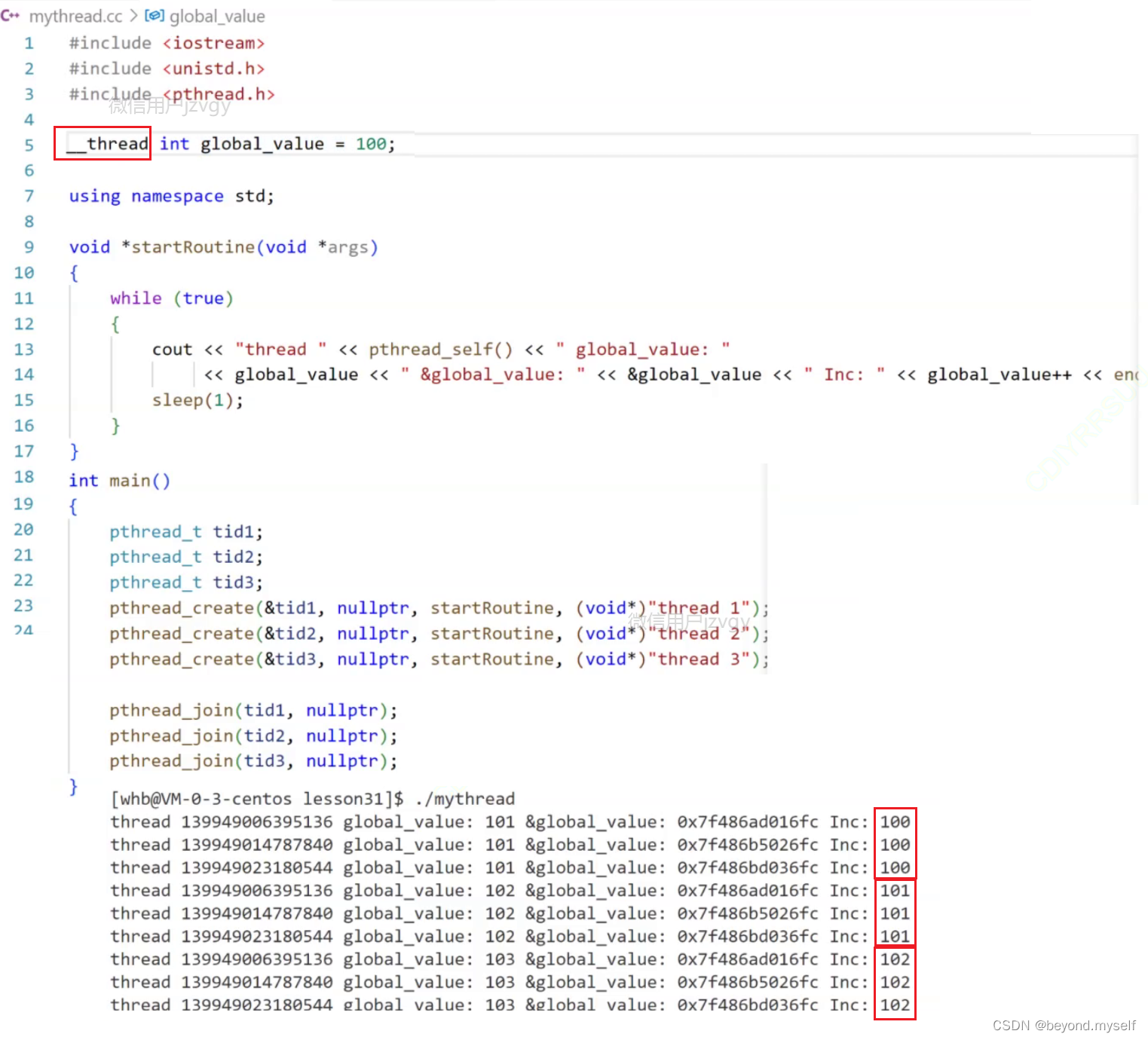
五.分离线程
1.概念

2.示例
(1)pthread_ detach(pthread_ self()); 新线程自我分离。
如果没有sleep(1),就会出现新线程一直循环的情况。因为有可能主线程先执行 int n = pthread_ join(tid1, nullptr); 此时新线程还没有pthread_ detach分离,则主线程会一直阻塞在pthread_ join这里,不会返回。
当有sleep(1)时,新线程会先pthread_ detach自我分离。主线程后执行 int n = pthread_ join(tid1, nullptr); 此时新线程已经pthread_ detach分离,则主线程会直接pthread_ join返回错误码,证明了一个线程如果分离了就不能再join

(2)pthread_ detach(tid1);主线程分离新线程
建议主线程分离新线程,因为这样主线程一定是先分离了新线程,再pthread_ join。
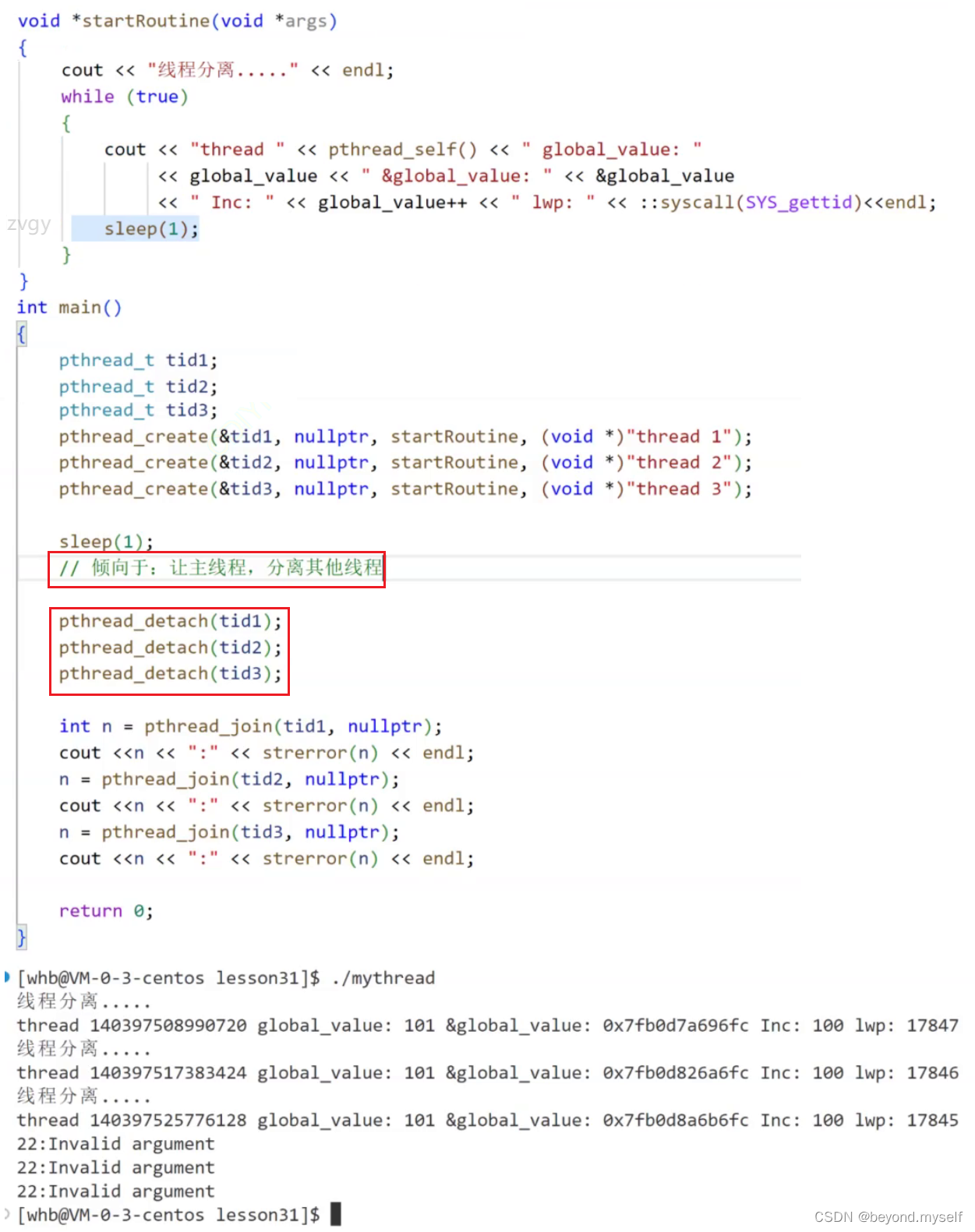
3.线程分离可以理解为线程退出的第四种方式
(1)线程分离分为立即分离,延后分离,要保证线程还活着。线程分离意味着,我们不在关心这个线程的死活。线程分离可以理解为线程退出的第四种方式——延后退出
(2)主线程的退出,并不会导致进程退出,也不会影响其他线程的运行。进程中的所有线程退出了,进程才会退出。—— 一般我们分离线程,对应的main thread不要退出(常驻内存的进程)