大数据:spark新特性,shuffle,
2022找工作是学历、能力和运气的超强结合体,遇到寒冬,大厂不招人,可能很多算法学生都得去找开发,测开
测开的话,你就得学数据库,sql,oracle,尤其sql要学,当然,像很多金融企业、安全机构啥的,他们必须要用oracle数据库
这oracle比sql安全,强大多了,所以你需要学习,最重要的,你要是考网络警察公务员,这玩意你不会就别去报名了,耽误时间!
与此同时,既然要考网警之数据分析应用岗,那必然要考数据挖掘基础知识,今天开始咱们就对数据挖掘方面的东西好生讲讲 最最最重要的就是大数据,什么行测和面试都是小问题,最难最最重要的就是大数据技术相关的知识笔试
大数据:spark新特性



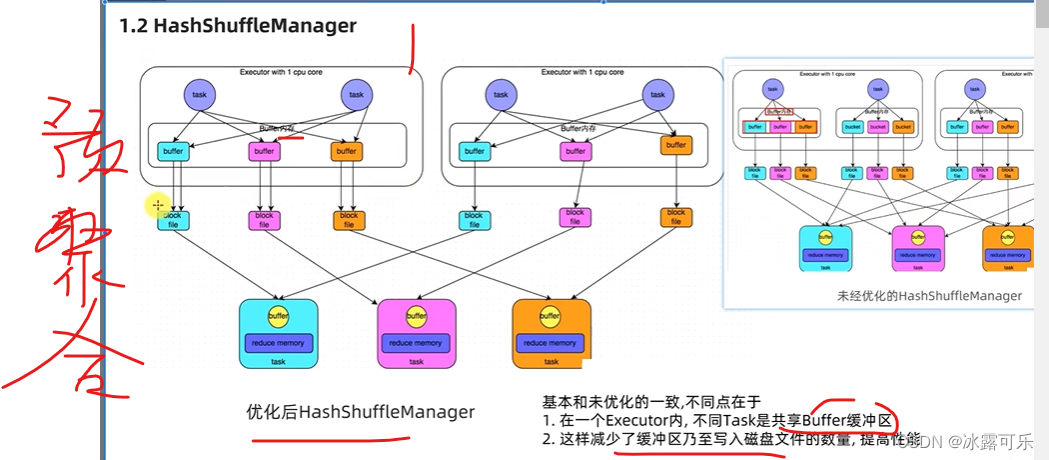
哈希洗牌,好办
内存加磁盘玩
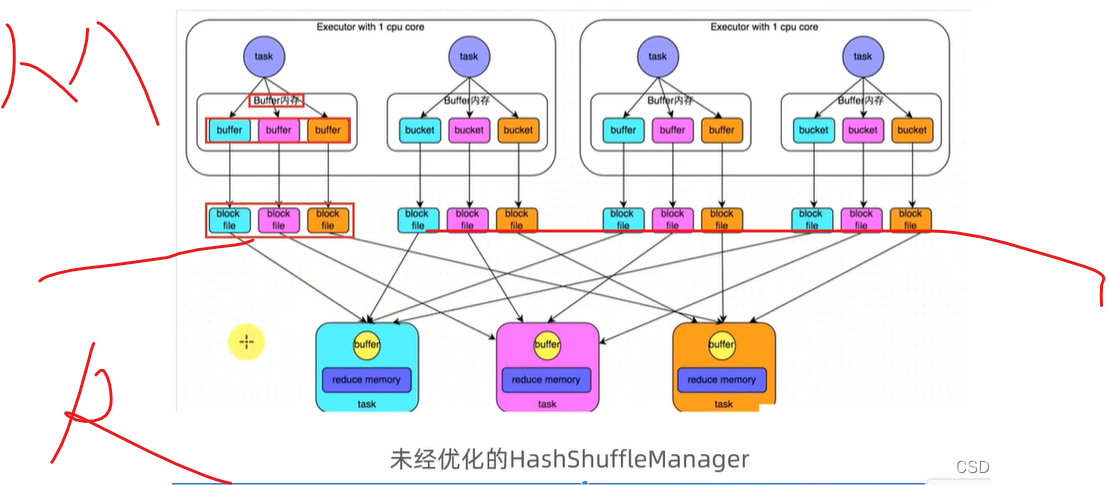
shuffle很费劲的
费时,费空间
排序洗牌
sortshufflemanager

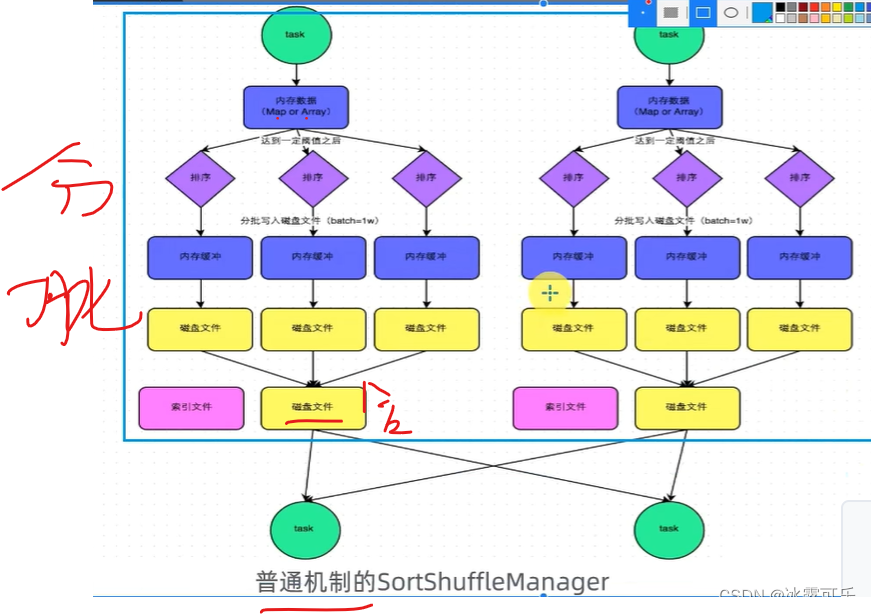
分批玩
索引是拉去文件的指引

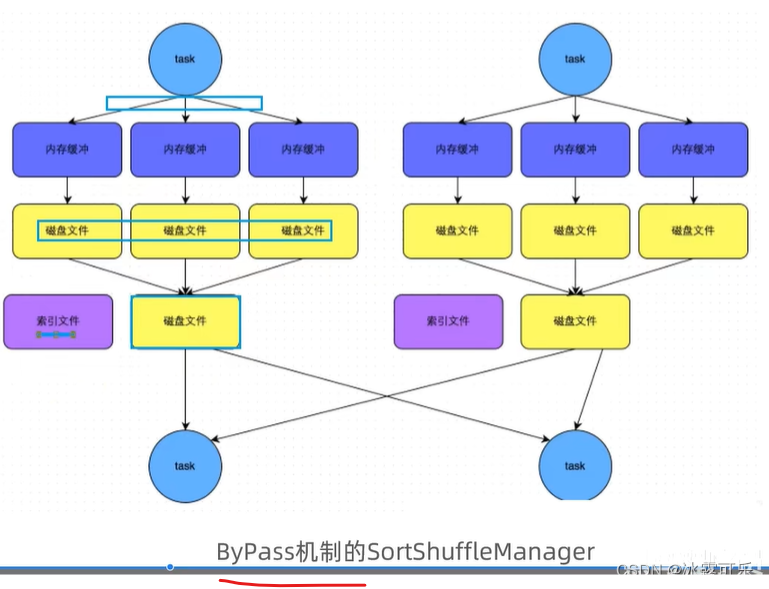
没有排序,时空性能都会提升

宽依赖是无法避免传输io的
尽量不要shuffle
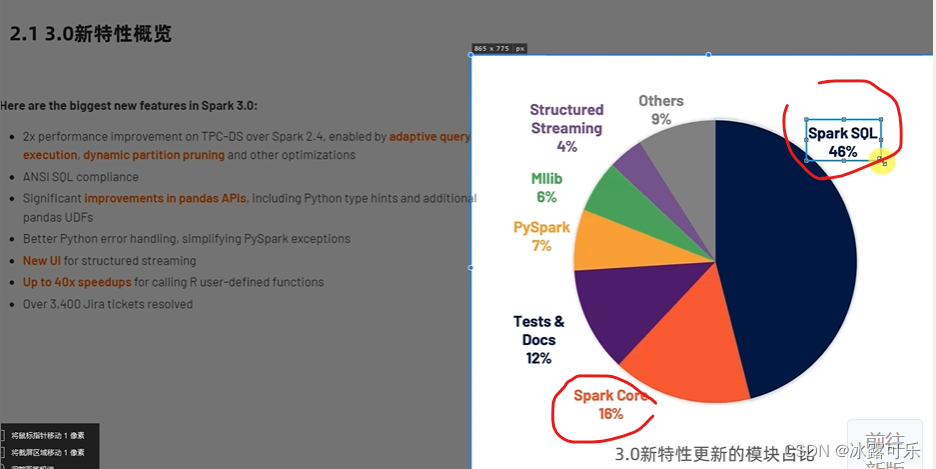
当前spark的重点是RDD和SQL
SQL很简单,很好学,所以sparkSQL很重要。
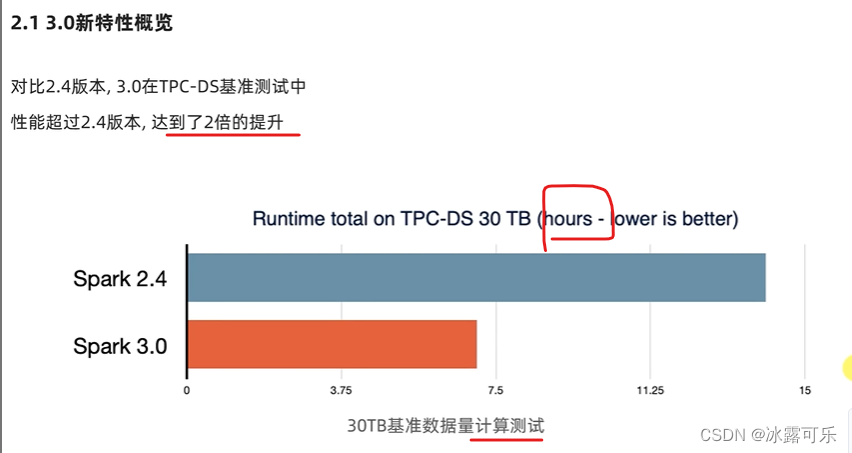

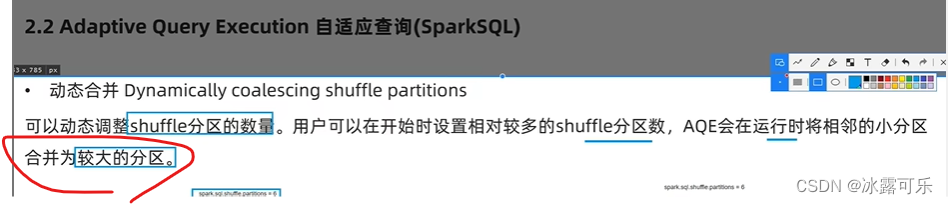
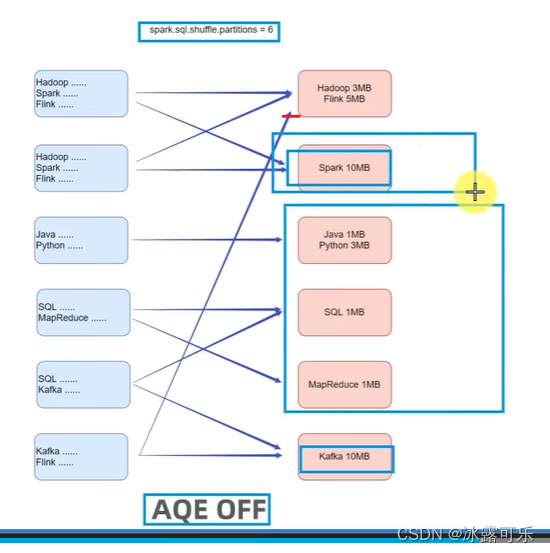
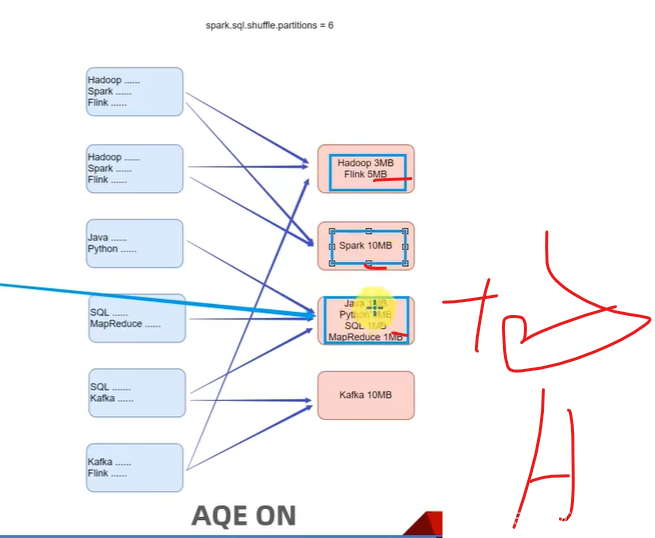
尽量让数据均衡
动态合并
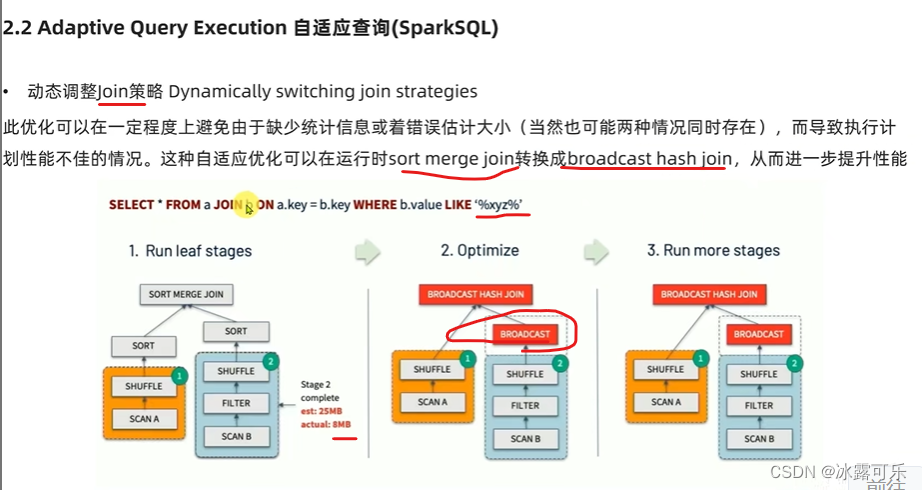
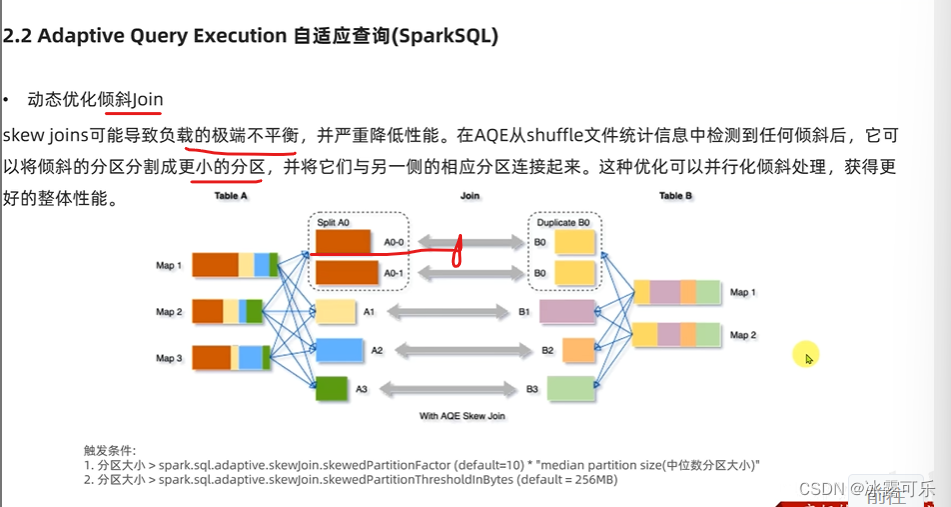
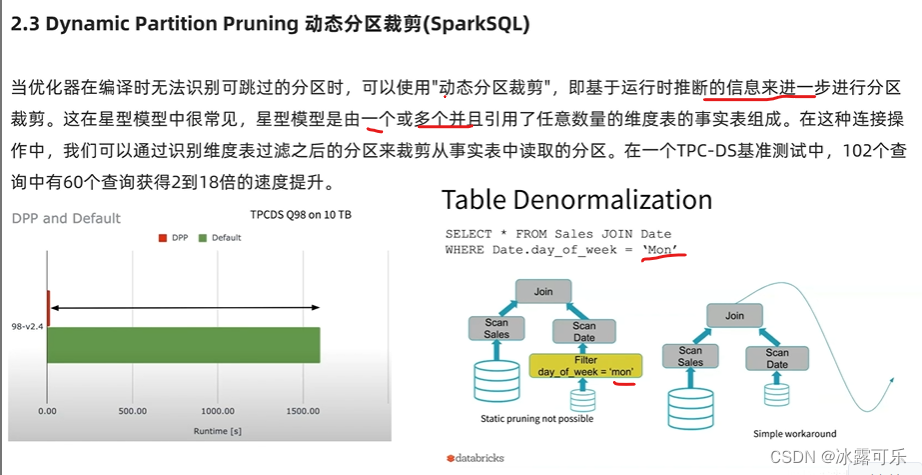
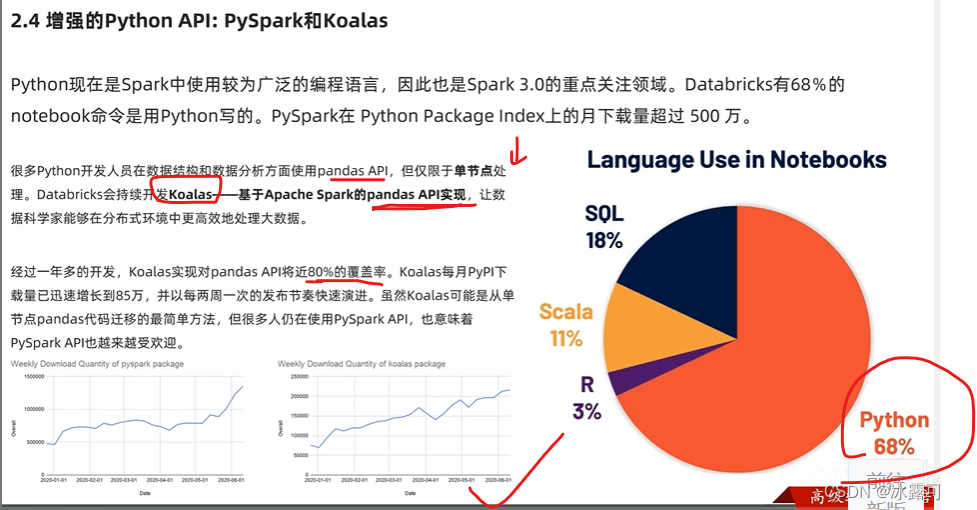
spark现在
pyspark和koalas数据库
底层就可以实现普通的python开发
也可以用pandas实现数据开发

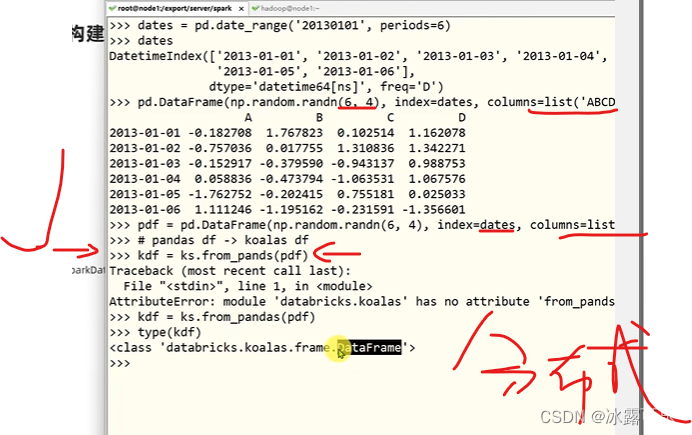
一波骚操作,就得到了分布式的数据
后续你用pandas操作时,都是分布式计算哦
你也可以通过spark创建数据,再转化为pandas分布式数据
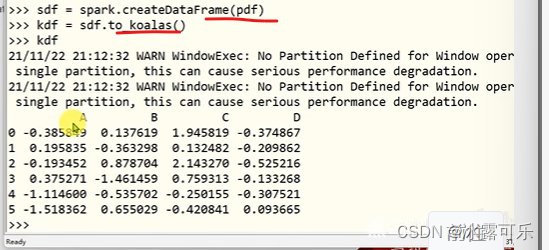
ks也能构建分布式pandas数据对象
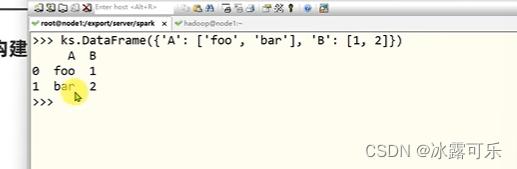
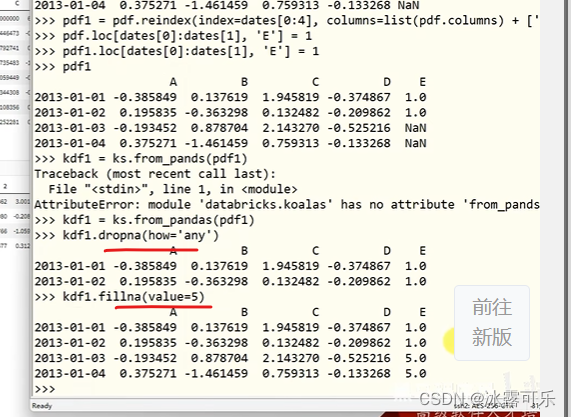
反正可以随意使用原生pandas的那些函数
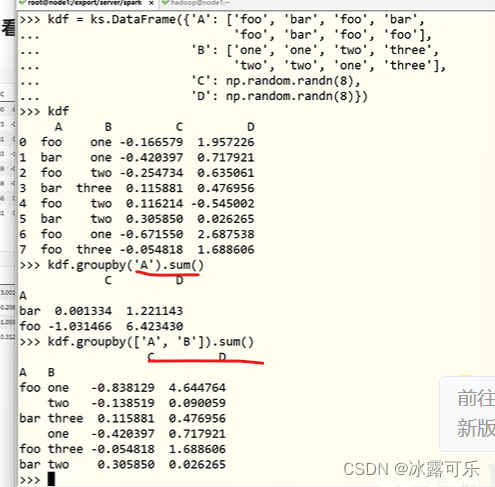
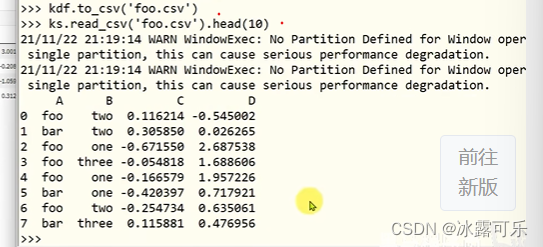
各种骚操作


总结
提示:重要经验:
1)
2)学好oracle,即使经济寒冬,整个测开offer绝对不是问题!同时也是你考公网络警察的必经之路。
3)笔试求AC,可以不考虑空间复杂度,但是面试既要考虑时间复杂度最优,也要考虑空间复杂度最优。