一. 索引堆(Index Heap)
可是在构建堆的过程中有局限性:
- 如果元素是非常复杂的结构,例如字符串(一篇十万字的文章)等等,这样交换的代价是十分大的。不过这可以通过一些基本手段解决,
- 更加致命的是元素在数组中的位置发生改变,使得在堆中很难索引到它!例如元素下标是任务ID,元素值是优先级别。当将数组构建成堆后,下标发生改变,则意味着两者无法产生联系!在原来数组中寻找任务只需O(1),但是构建成堆后元素位置发生改变后需要遍历数组!所以才会引入“索引堆”这个概念。
总之就是:data部分的数据不动了,加了个index表示索引,利用index数组变化来形成堆,如index为10,则该元素就在索引10代表的data上去找。 元素比较的是data数组,元素交换的是索引值。
那么取值的话都是data[indexes[i]]是这个数构成的堆~

代码容易、但是有一个问题,就是假如修改下标为4的数据,那么就得维护index数组了,此时首先要找到下标为4的数据在哪,可以知道在9的位置上,但是这样就是O(n)级别了,此时优化可以到O(1),添加一个数组reverse,来表示此index在堆中的位置。这种方式叫方向查找。
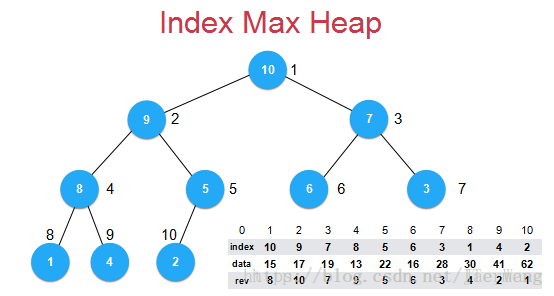
rev数组性质:

二、 堆衍生的问题
1. 使用堆实现优先队列
(1)OS系统执行任务
可以使用堆来作为优先队列,对于OS而言,每次使用堆可找到优先级最高的任务执行,就算此时有新的任务添加进行,插入堆中即可,动态修改任务的优先级也可满足。
2)在N个元素中选出前M个元素
例如在1,000,000个元素中选出前100名,也就是“在N个元素中选出前M个元素”。
按照之前学习的一些排序算法,性能最优可达到O(n*logn )但是使用了优先队列,可将时间复杂度从O(n*logn )降低为O(n *logM)!(若N是百万级别数字,其实这优化的不少)使用一个最小堆,使长度维护在100,将前100个元素放入最小堆之后再插入新的元素,此时只会将堆中最小元素移出去,堆的长度不变,将这1,000,000个元素遍历完后,最小堆中存放的100个元素就是前100名,因为比其小的元素全都请了出去。
2. 多路归并排序
可以使用堆来完成多路归并排序,首先思考归并排序思想,是将数组一分为二,两个子数组分别排序后进行归并,每次归并的过程只有两个子数组元素比较,其实在归并排序过程中可以一次分成多个(大于2,这里是4)子数组,再进行归并,每次比较4个元素的大小关系,理所当然想到逐个元素比较,但是可以将这4个元素放入堆中,再逐个取出来,取出来的元素属于哪个子数组,再添加这个子数组的下一个元素进入堆中,来维护这个堆。当n个数用n路归并,则这就是一个堆排序~
3. d叉堆
此部分主要讲解的是二叉堆,即每个节点最多有两个孩子,其实还有一种思想——d叉堆,下图是三叉堆,依然满足堆的特征。其中d越大,层数越少,同样在Shift Up、Shift Down时比较的次数增多,所以对于这个d的数量,也是性能之间的衡量。(二叉堆是最经典的)
4. 堆的实现细节优化
这里这位读者提供对细节优化的思路,切身去体会算法的“优化”,堆的实现细节优化还有:
- ShiftUp 和 ShiftDown 中使用赋值操作替换swap操作
- 表示堆的数组从0开始索引
- 没有capacity的限制,动态的调整堆中数组的大小