大模型的能力让学术和工业界都对通用人工智能的未来充满幻想,在前一篇博文中已经粗略介绍,
ALM的两大思路是推理和工具,本篇博文整理两篇关于Toolformer或Tool Learning的论文,即如何允许模型使用多种工具如日历、计算器、搜索系统等等来帮助提升LLMs的能力。
Toolformer: Language Models Can Teach Themselves to Use Tools
来自Meta AI。LLMs已经展现出十分出色的zero-shot和few-shot能力,特别是在规模上,但它们在基本功能方面也遇到了困难,比如算术、最新信息、幻觉,但在这些方面,显然更简单、更小的模型表现更好。 因此,一个简单的方法就是让它们能够使用外部工具,比如搜索引擎、计算器或日历(如下图所示,该模型自动决定调用不同的api实验任务,从上到下依次是:问答系统、计算器、翻译和维基百科搜索)。然而现有的方法要么依赖于大量的人工注释或将工具的使用限制为仅针对特定任务的,这阻碍了其在LLMs中更广泛地使用。

因此作者们引入了Toolformer,一个被训练以学习使用工具的模型,它有两个特点:
- 自监督。不仅仅与大量的人工注释成本有关,还因为人类认为有用的东西可能与模型认为有用的东西不同。
- 一般性。LLMs应该能够自己决定何时以及如何使用哪个工具,这可以得到一个更通用的工具。
为了使LLMS能够通过API调用来使用不同的工具,每个API的输入和输出都需要被表示为文本序列,从而可以将API调用无缝插入到任何给定的文本中,其中插入时使用特殊的令牌来标记即可(“”和“→” )。 e ( c ) = < A P I > a c ( i c ) < / A P I > e(c)=<API>a_c(i_c)</API> e(c)=<API>ac(ic)</API> e ( c , r ) = < A P I > a c ( i c ) → r < / A P I > e(c,r)=<API>a_c(i_c)→ r</API> e(c,r)=<API>ac(ic)→r</API>其中API调用是一个元组 c = ( a c , i c ) c = (a_c, i_c) c=(ac,ic),其中 a c a_c ac是API的名称, i c i_c ic是相应的输入,工具的结果为r,其可以包含在输入也可以不包含,当模型生成出→时,根据调用API得到结果r,从而借助外部工具的帮助继续生成。
怎样生成一个这样的数据集来对语言模型进行微调?人工标注太高昂,因此自监督的方式即利用LLMs的in-context learning能力是非常重要的。因此通过设计prompt和关于调用API的few-shot,让大模型自己去生成一些数据即可。作者们将一段纯文本数据集转换为使用API调用进行扩充的数据集,具体策略如下图所示,其分为三个步骤:
- Sample API Calls:利用LLM的上下文学习能力对大量潜在的API调用进行采样。 p i = p M ( < A P I > ∣ P ( x ) , x 1 : i − 1 ) p_i=p_M(<API>|P(x),x_{1:i-1}) pi=pM(<API>∣P(x),x1:i−1)
- Execute API Calls:执行这些API调用不同的工具。
- Filter API Calls:检查结果以过滤掉所有不会减少loss的调用(失败的调用)。 L i ( z ) = − ∑ j = i n w j − i l o g p M ( x j ∣ z , x a : j − 1 ) L_i(z)=-\sum^n_{j=i} w_{j-i} log p_M(x_j|z,x_{a:j-1}) Li(z)=−j=i∑nwj−ilogpM(xj∣z,xa:j−1)
所有过滤后的结果将与原始文本交错,以产生一个新的文本,如下图的 x ∗ x^* x∗中的红色所示。所生成的数据将用于LLMS的SFT训练。

文章中主要使用了5种工具,如下图所示:
- Question Answering。一种检索增强的LM,其经过了对自然问题的微调。
- Wikipedia Search。BM25,用于搜索来自维基百科的简短文本片段。
- Calculator。支持四种基本的算术运算,结果四舍五入到小数点后两位。
- Calendar。不需要有任何输入,其为需要时间意识的预测提供了时间上下文。
- Machine Translation。基于LM的机器翻译系统,600M参数的NLLB,支持200种语言,目标语言恒定英语。

Toolformer依然存在着以下不足:
- 无法链式使用不同工具。从训练方式来看,使用不同工具的数据是分别生成的,这使得模型无法配合使用多种工具。
- 无法交互地不断优化查询。这是为了防止模型不断调用API导致卡死,每个样本仅允许调用一次API,但这大大降低了模型的能力。
更详细的内容请看原文:
paper:https://arxiv.org/pdf/2302.04761.pdf
Tool Learning with Foundation Models
来自清华74 页的论文,正式把这个方向定义为Tool Learning,并开源了一个通用的工具学习框架。
“It is not only the violin that shapes the violinist, we are all shaped by the tools we train ourselves to use.”
不仅是小提琴塑造了小提琴家,我们都是由我们学会使用的工具所塑造的。
— Edsger W. Dijkstra
工具是对人类能力的扩展,旨在提高人类活动中的生产力、效率和解决问题。自文明诞生以来,工具就一直是人类不可或缺的一部分 。工具的创建和使用是由一个根深蒂固的愿望,以克服我们的物理限制和发现新的领域。更具体地说,随着工具的进步,我们可以轻松高效地完成越来越复杂的任务,解放时间和资源来追求更雄心勃勃的冒险。因此,工具一直是至关重要的因素,改变我们的学习、交流、工作和娱乐模式。纵观历史,人类一直是工具的发明和操作的主要媒介,这是智能体的一种惊人的表现。
如下图所示,从使用者的角度而言,工具大体可以被分为三类
- Physical Interaction-based Tools:物理交互工具。如机器人、传感器和可穿戴设备。
- GUI-based Tools:GUI驱动工具。拥有一个交互界面的工具,如浏览器、Microsoft Office、Adobe PhotoShop。
- Program-based Tools:基于程序的工具。需要通过代码来调用和控制,如Github Copilot,拥有极高的灵活性。

随着LLMs的出现,人工智能系统也有可能像人类一样熟练地使用工具。在这种方式下,即工具学习与基础模型的结合,可以融合专用工具(Tools)和基础模型(Foundation Models)的优势,以提高解决问题的准确性、效率和自动化程度。具体的优势在于:
- Mitigation for Memorization。使用实时工具执行来增强基础模型,以减轻记忆过程中的限制。例如,将记忆存储负载到搜索引擎。
- Enhanced Expertise。专门的工具更适合满足特定领域的需求,如使用Wolfram进行科学计算,这将把LLMs的能力推广到超出其能力范围的更广泛的任务中。
- Better Interpretability。工具执行的过程可以反映如何得到结果的整个过程,这允许更好的可解释性和透明度。
- Improved Robustness。基础模型容易受到对抗性攻击,比如微调prompt就可以翻转模型预测。这是因为模型的训练仍然严重依赖于训练数据的分布。相反,工具跟输入扰动无关,从而可以抵抗对抗性的攻击。

Tool Learning可以被分为两类,如上图所示,分为工具增强学习与工具导向学习。
- tool-augmented learning,工具增强学习,它试图通过来自各种工具的执行结果来增强基础模型,如调用搜索引擎、日历、计算器等。
- tool-oriented learning,工具导向学习,它将学习过程的主要目标从模型增强转移到执行工具本身。最具代表性的应用是机器人操作,其中LLMs被视为机器人系统的“大脑”,用于将高级任务分解为很多可执行的子计划。除了机器人外,像WebGPT可以浏览搜索引擎、WebShop可以浏览并购买商品、图像编辑等等。最近Auto-GPT的诞生进一步证明了基础模型在自动化定义plan和tool use上的潜力。
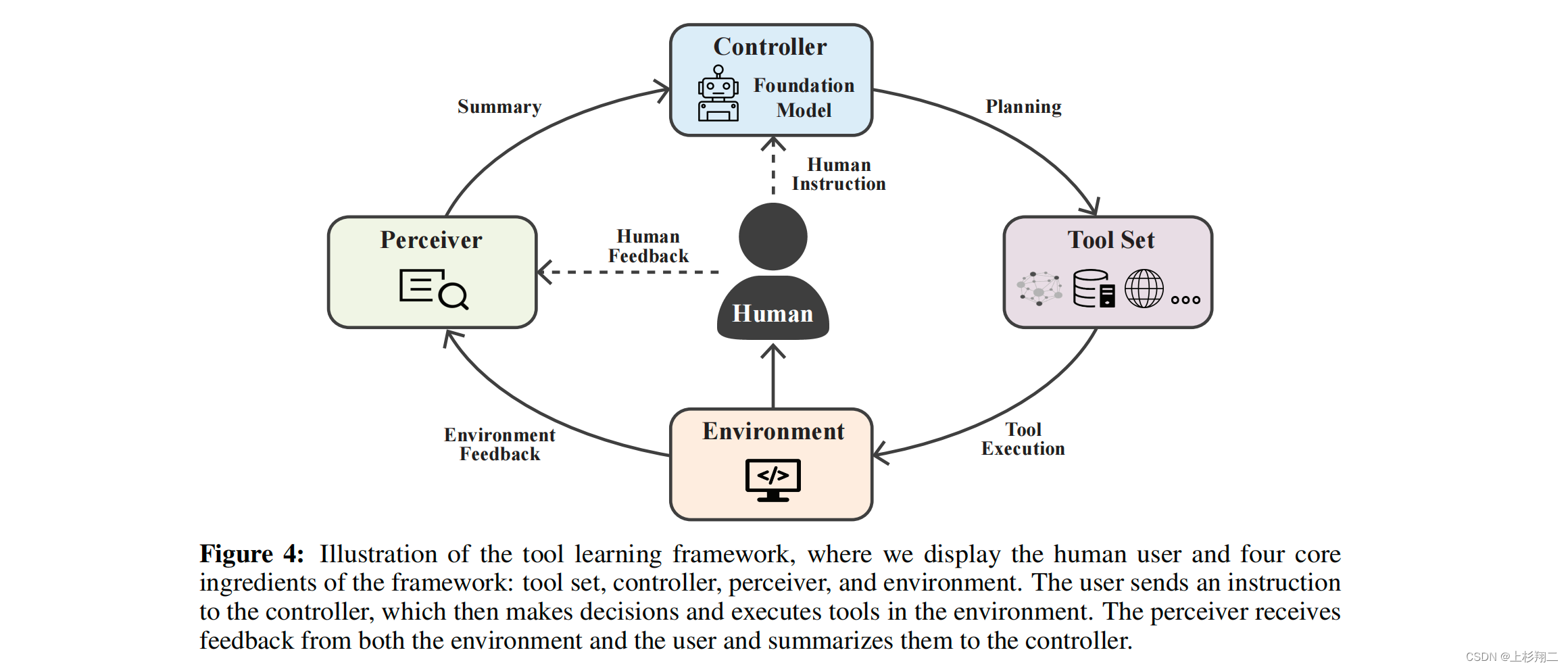
随后作者提出了一个Tool Learning的总体框架,如上图所示,它包括四个基本组成部分:
- tool set。包含不同功能的不同工具的集合,以API接口的形式出现,比如对于一个天气API,API的输入可以是位置和时间,输出可以是温度或风速。
- environment。环境是指工具所操作的外部世界,可以是虚拟的也可以是现实的。
- controller。充当整个系统的“大脑”,需要理解用户并与工具集建立连接,决策出使用策略与工具的使用计划。
- perceiver。感知器负责处理工具操作与环境的互动形成的反馈,通过读入这些反馈为控制器生成信号或摘要,指导控制器下一步的行动。通过观察这个反馈,控制器可以确定所生成的计划是否有效,以及在执行过程中是否存在需要解决的异常情况。在更复杂的情况下,perceiver应该是能够支持多种模式,如文本、视觉和音频,以捕获来自用户和环境的反馈的不同性质。
最关键的有两方面,根据用户query获得意图,然后通过意图制定具体执行计划。
The General Procedure: From Intent to Plan
为了准确地完成用户查询q所指定的任务,controller需要理解两个方面:
- 用户的潜在意图。这包括识别并形式化用户的自然语言查询,即意图理解。
- 工具集。需要理解每个工具的功能和目标,即工具理解。
如下图所示,zero-shot prompting与 few-shot prompting是两种流行的方式,其可以让controller学会去阅读并获取工具文档的知识。

Planning with Reasoning
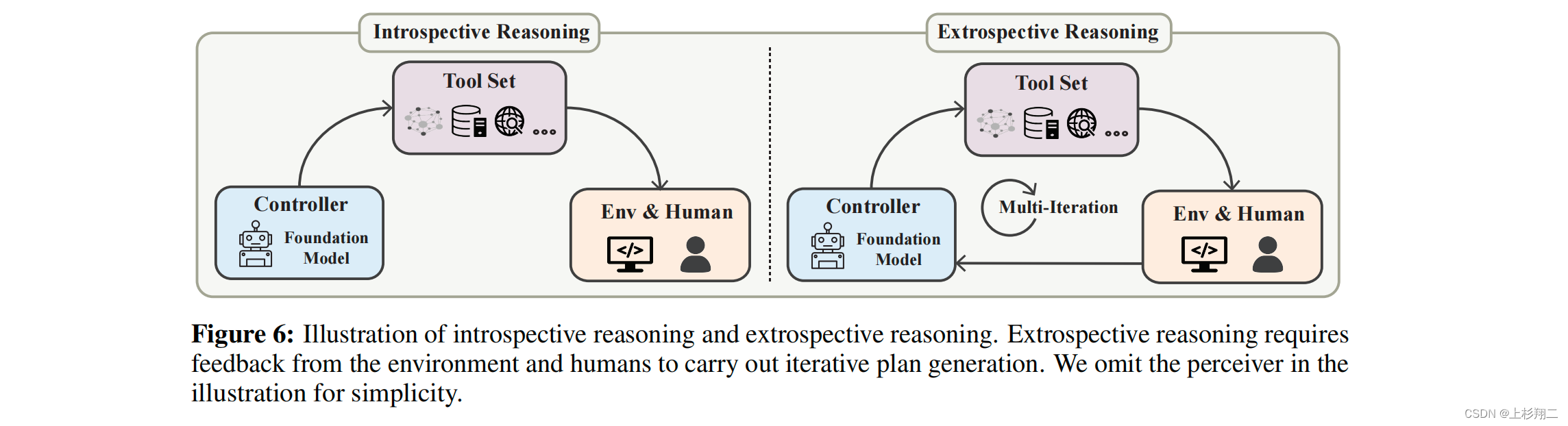
理解其意图和工具之后,仍然不足以处理复杂的任务。用户查询q通常意味是复杂的任务,需要以适当的顺序被计划为多个子任务,因此该过程需要进行推理。如下图所示是向内推理和向外性推理的示意图。前者涉及到在不与环境E交互的情况下生成一个工具使用的静态计划,而后者则通过与环境E的迭代交互过程中来逐步生成计划。
Tool Learning的训练过程可分为监督、半监督(构造若标签)和自监督。也可以从环境或人类的feedback中进行学习。此外对于通用的工具学习也可以考虑更加高效的学习与迁移知识:
- 元工具学习(Meta Tool Learning):模型能够反思自己的学习过程并在必要时调整新的工具使用策略。
- 课程工具学习(Curriculum Tool Learning):通过课程学习逐步向模型介绍更复杂的工具以便其建立在先前的基础上,并深入了解工具的方法来提高模型的泛化效果。
此外,作者们还讨论了其他重要的研究主题,包括
- 安全性和可信度(safety and trustworthiness),其中作者们强调潜在的风险来自对手(Adversaries,即外部攻击者)、治理(Governance,即技术的滥用)和可信度(准确和道德问题)。因此在某些高风险场景中(如自动驾驶)部署Tool Learning模型之前,有必要仔细考虑这些问题。
- 工具创建(tool creation),除了工具增强学习与工具导向学习外,或许人工智能也可以自己创造新工具。
- 个性化的工具学习(personalized tool learning),服务特定的用户,如金融领域。用户偏好与工具操作相结合将是一个挑战,此外还会有隐私保护问题。
- 具身学习(embodied learning),工具学习与具身代理的交叉能够实现,特别是直接控制代理或者使用真实世界的工具。
- 工具学习中的知识冲突(knowledge conflicts in tool learning),知识冲突会导致不准确和不可靠的模型预测,主要分为模型知识与增强知识之间的冲突(模型信息过时、模型信息错误、工具使用错误等都会导致这种问题)、来自不同工具的增强知识之间的冲突(工具本身可信度、工具的偏向、工具的底层不一样(如不同的翻译软件))。
- 其他开放的问题(other open problems),例如将工具使用能力视为机器智能的衡量标准和科学发现的工具学习。
paper:https://arxiv.org/pdf/2304.08354.pdf
code:https://github.com/OpenBMB/BMTools
下一篇博文介绍HuggingGPT、AutoGPT、WebGPT、WebCPM。