问题描述
- 读取给定的词典,以及输入待分词的字符串“春节将至,欢乐的气氛已悄悄降临。”,将词典中词串的概率转为词串的费用;
- 在词典中查找候选词,并返回;
- 计算累积费用并选择最佳前驱词;
- 输出分词计算过程,以及最终分词结果。
最大概率法的一元语法模型
待切分子串中所有的切分词串概率最大的词串即为最可能的切分结果,下图为贝叶斯公式 ,其中 p(z|w)和p(z) 都为固定值,所以只需要求出p(w) ,即词串的概率。
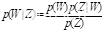
n元语法可以用来求词串概率,使用1元语法,即根据词表把输入串中所有可能的词都找出来,然后把所有可能的切分路径找出来,并从中找出最佳路径,即为切分结果。
由于最大概率法考虑的是某种字串出现的条件下,最可能划分的词串,而不是依赖于切分词的顺序等,只要存在歧义的句子中正确切分的词语曾经出现过且在词表中,就可能获得正确切分,因此在拥有大量标注语料的前提下,最大概率法可以在一定程度上避免切分交集型歧义和组合型歧义。
1、读取给定的词典
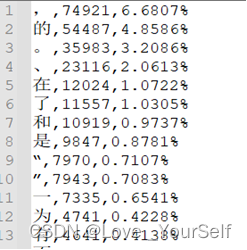
读取实验中给定的词表文件,这是一个csv形式的txt文件,这其中的内容包括字符、字符出现的频数、字符出现的频率三项内容,可以通过读取这个文件获得关于字符的相关信息,进而计算他们的费用。
2、费用的理解与计算
由于每个词出现的概率都是一个很小的正数,如果汉字串较长,最后得到的词串概率会很小,甚至趋近于0,无法显示,因此对概率取负对数,使乘法变为加法,使求最大值变为最小值,其中的 即为该词的费用, 即为词串的费用。利用文件的频率来计算相应的费用即可,这里使用到numpy的log函数,将百分数转化为相应的浮点数,然后再去对数求得费用;对于没有在词典中出现的词,将给这个词一个固定的费用,在这里给的是0.000001的负对数,函数代码如下:
代码如下:
def cost():
file = open(file='WordFrequency.txt', mode='r', encoding='utf-8')
str1 = '春节将至,欢乐的气氛已悄悄降临。'
lines = file.readlines()
dic = {
}
for line in lines:
item = line.split(',')
fre = item[2].strip('\n')
fre = fre.strip('%')
dic[item[0]] = np.log(float(fre) / 100)
3、选择候选词
对于一个候选词,在候选词列表中遍历其前边的候选词,若前边的候选词最后一个字在句子中的位置序号+1等于当前候选词的位置序号,则该候选词为当前候选词的前驱词。在遍历前驱词的同时,计算其累计费用,即前驱词费用+当前词费用,计算出最小累计费用,对应的前驱词即为最佳前驱词。选择候选词的时候先依次读取每一个字,然后判断这个字是否出现在词典中,如果出现在词典中,就将其加在候选词列表中然后继续向后遍历指定数量个字,看添加了指定数量的字符后是否还出现在字典中,如果存在那么也要将该词添加到候选词字典中
def get_candidate_words(sentence):
candidate_words = [] #存放候选词
for sp in range(len(sentence)):
w = sentence[sp]
if w not in dic.keys():
candidate_words.append([w, sp, sp]) # 有些字可能不在语料库中,把它作为单个字加进去,费用为一个定值
dic[w] = np.log(0.000001)
else:
candidate_words.append([w, sp, sp])
for mp in range(1, 20):
if sp + mp < len(sentence):
w += sentence[sp + mp]
if w in dic:
candidate_words.append([w, sp, sp + mp]) # 存储词,初始位置,结束位置
# print('候选词有:%s' % candidate_words)
return candidate_words
4、选择最佳的前驱词
遍历前驱词的同时,计算其累计费用,即前驱词费用+当前词费用,计算出最小累计费用,对应的前驱词即为最佳前驱词。选择最佳前驱词的时候,首先判断这个词出现的位置,如果它出现的位置为句子的首端,那么这个词没有前驱词,可以将其前驱词设置为null;如果他的位置不在句子首端,那么要计算这个词到前一个词的费用,也就是判断在它前面的所以候选词,如果这个词的开始位置等于在它前面的候选词的结尾位置加一,那么就要计算他们之间的费用,然后选出一个费用最小的最为这个词的前驱词,计算时使用前驱词的最小费用加上当前词的费用。
def get_pro_word(candidate_words): # 获得最佳前驱词以及它的费用
pro_word = {
}
for i in range(len(candidate_words)):
if candidate_words[i][1] == 0:
pro_word[candidate_words[i][0]] = ['null', dic[candidate_words[i][0]]] #候选词, 最佳前驱词, 累计费用
else:
now = candidate_words[i][1] # 当前候选词的第一个字在句子中的位置序号
for j in range(i-1, -1, -1): # 遍历当前候选词前边的候选词,找出它的前驱词
pro = candidate_words[j][2] # 前边词的第二个字在句子中的位置序号
if candidate_words[i][0] in pro_word:
fi = pro_word[candidate_words[i][0]][1]
else:
fi = -100
# print(pro_word, j)
if pro == now:
pass
elif pro + 1 == now:
if candidate_words[j][0] in pro_word.keys():
temp = dic[candidate_words[i][0]] + pro_word[candidate_words[j][0]][1]
else:
temp = dic[candidate_words[i][0]] + dic[candidate_words[j][0]]
if temp > fi:
pro_word[candidate_words[i][0]] = [candidate_words[j][0], temp]
# print(pro_word)
return pro_word
5、得到最后的分词结果
在候选词列表中找出最后一个字位置序号等于句子最后一个字位置序号的候选词,在其中选出累计费用最小的候选词,即为句子的终结词。从费用最少的终结词开始,向前倒推,得出最佳前趋词序列,即分词结果。在这里我选择了一个特殊的方法,假设每一个句子是以句号结尾的,并且只有一个句号,然后通过得到句号的前驱词,然后依次这么进行下去,直到某一个词的前驱词为null结束遍历,这样就可以得到一个以句号开始的一个最佳前驱词构成的列表,然后将这个列表进行逆序操作,最后以/最为分割,将列表中的元素进行分割,得到最后的分词结果。
def get_final_word(best_pro_word):
# 按照逆序处理后的最佳前驱词列表,方便处理,但是只能对以句号结尾的句子有效
result = []
result.append('。')
if '。' in best_pro_word.keys():
p = best_pro_word['。'][0]
while best_pro_word[p][0] != 'null':
result.append(p)
p = best_pro_word[p][0]
result.append(p)
result = reversed(result)
print('/'.join('%s' %id for id in result))
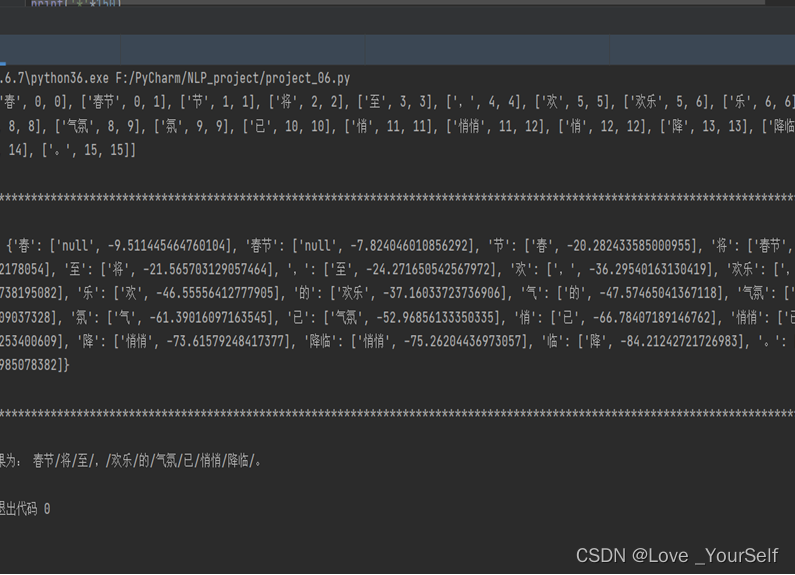
实验截图