【AAAI2023】Ultra-High-Definition Low-Light Image Enhancement: A Benchmark and Transformer-Based Method
【本文贡献】
构建了4K和8K超高清图像的基准数据集UHD-LOL,用于探索和评估图像增强算法。
基于UHD-LOL数据集,对现有的微光图像增强(LLIE)算法进行了基准测试,讨论了这些方法的性能和局限性。
提出了一种新的Transformer模型LLFormer,用于超高清微光图像增强(UHD-LLie)任务。
【网络结构】
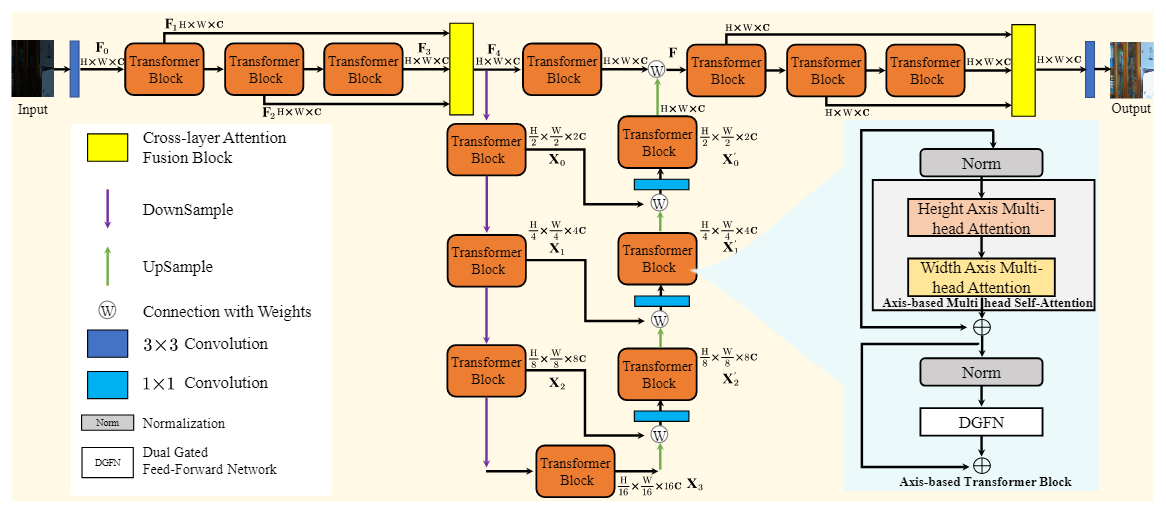
LLFormer的核心设计有三个,一个是基于轴的变换模块height axis multi-head attention和width axis multi-head attention,一个是双门控FFN——dual gated feed-forward network,另一个是跨层注意力融合模块,基于轴的多头自注意在跨通道维度的高度和宽度轴上依次进行自注意计算以降低计算复杂度,采用门控机制来提取有用的特征;跨层注意力融合模块在融合时学习不同层次特征的注意力权重。
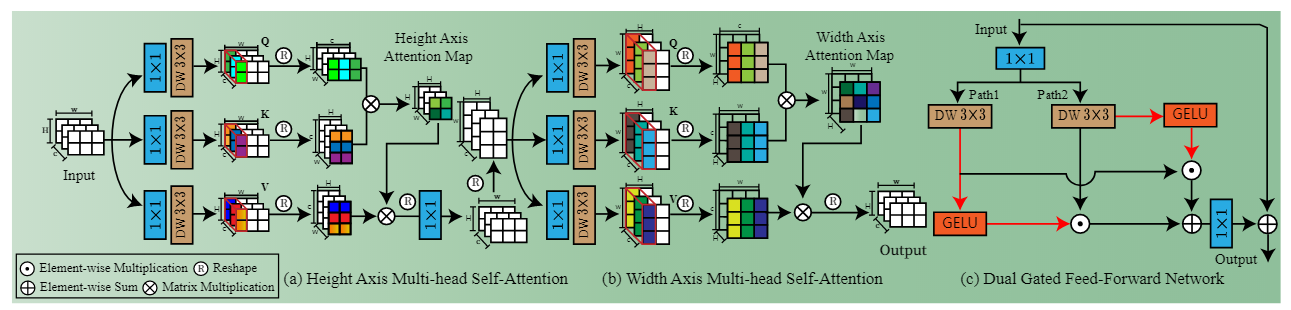
在Restormer的基础上,该网络有以下三个改进:
①对注意力的改进,以往的注意力要进行HW×HW的矩阵运算,体量较大,LLFormer将注意力计算分为了两步(即上图(a)和(b)),第一步计算H×H的attention map,第二步计算W×W的attention map,相比传统方法减少了计算量。
②对FFN的改进,将FFN改为双门控,使两个分支互相作为彼此的权重,如上图(c),从而获得了更加丰富的局部信息,增强了非线性建模能力。
③引入了Layer Attention,考虑了特征间的关联。
【学习心得】
以后的工作中可以尝试使用双门控来增强局部信息的提取能力,在有依据的情况下可以将注意力计算分解为多步,通过多步计算来控制计算量。
【NeurIPS2022】ShuffleMixer: An Efficient ConvNet for Image Super-Resolution
【本文贡献】
通过探索包含更多图像超分有用信息的大型内核的ConvNet,开发了一种高效的超分设计。
引入了一种通道分裂和混洗操作来有效地执行通道映射的特征混合。
扫描二维码关注公众号,回复: 15353160 查看本文章
为了更好地探索混洗混合器层的跨组特征之间的局部连通性,在所提出的超分设计中使用了MBConv。
【网络结构】

ShuffleMixer总体上说是一个轻量的使用大卷积核的网络模型,它由特征提取、特征混合和上采样三部分组成。
Feature Mixing Block(FMB)是该网络的关键结构,它由两个(a)所示的Shuffle Mixer Layer和一个(d)所示的Fused-MBConv(FMBConv)组成,这里的FMBConv起到了FFN的作用。
每个Shuffle Mixer Layer由两个(b)所示的channel projection模块和一个大的depth-wise卷积组成,卷积核大小为7×7。
channel projection包括频道拆分和混洗操作、(c)所示的Point-wise MLP、skip connection和layer norms。
【学习心得】
在使用Transformer搭建模型时,可以尝试使用channel shuffle来增加特征的交互性。
在图像超分辨率工作中,除了考虑像素变换,还可以多考虑频率域的变换和性质。
【ARXIV2212】A Close Look at Spatial Modeling: From Attention to Convolution
【本文贡献】
基于attention maps与查询无关、attention weights稀疏的问题,提出了FullyConvolutional Vision Transformer (FCViT),继承了Vision Transformer和ConvNet的优点。
【网络结构】
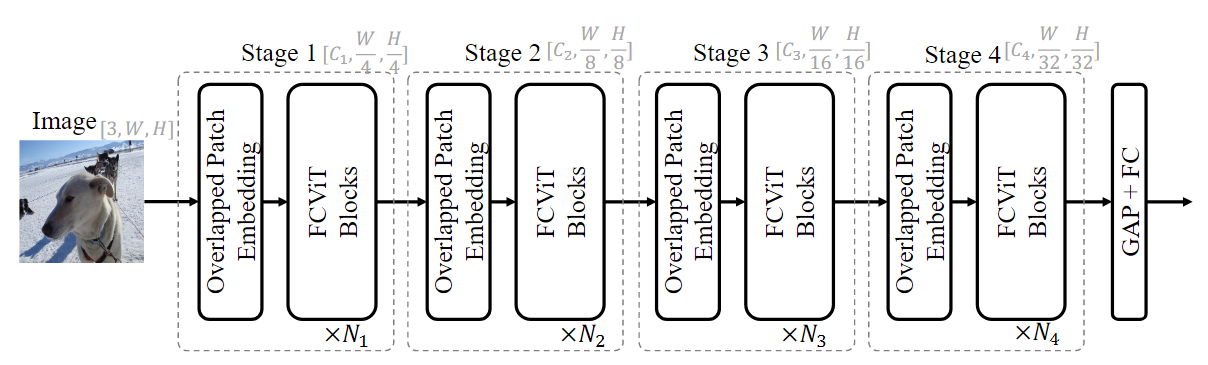
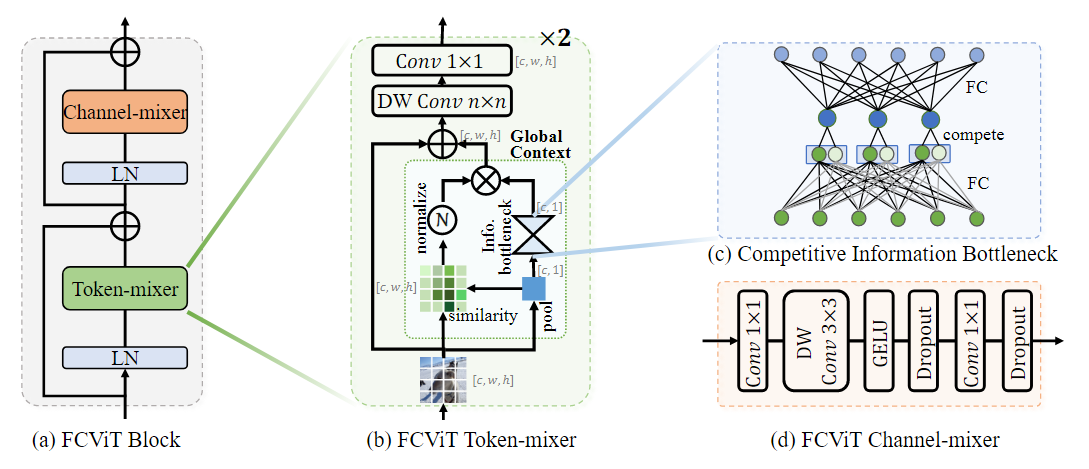
将特征矩阵与池化得到的矩阵相乘,得到相似性矩阵。
bottleneck的中间层引入竞争机制,选取其中较大的节点。
【学习心得】
bottleneck中的竞争机制可以尝试用于以后的工作中,并且这种竞争机制比dropout的解释性强,可以尝试将dropout替换为这种竞争机制(不过真的还有新的网络用dropout吗)。
【ARXIV2301】DEA-Net: Single image dehazing based on detail-enhanced convolution and content-guided attention
【本文贡献】
引入差分卷积来解决图像去雾问题,设计了一种细节增强卷积算法(DEConv),它包含并行卷积和差分卷积。
提出了一种新的注意机制CGA(content-guided attention),使用输入特征来引导空间重要性图(spatial importance map)的生成。
结合DEConv和CGA,并使用基于CGA的混合融合方案,提出了DEA-Net来重建高质量的无雾霾图像。
【网络结构】

该网络主要是在DEConv的基础上搭建DEB和DEAB,再添加了CGA(content-guided attention),这里的CGA是CBAM和channel shuffle的组合,先使用CBAM进行并行处理,再将特征分为两组,进行channel shuffle。
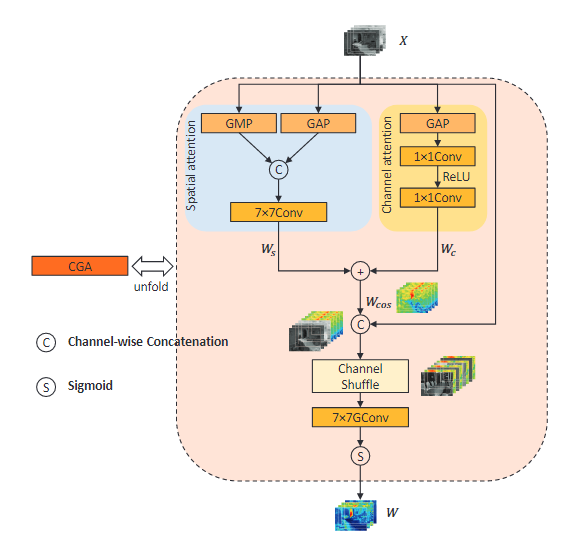
【学习心得】
今后的图像修复工作中可以尝试引入并行卷积和差分卷积,并行卷积可以减少参数量,加快训练速度;差分卷积可以增强特征的判别能力。
【ARXIV2212】DAE-Former: Dual Attention-guided Efficient Transformer for Medical Image Segmentation
【本文贡献】
提出了一种新的高效的双重注意机制来捕获输入特征向量的完整空间和通道上下文。
提出了一种跳过连接交叉注意(SCCA)模块,用于自适应地融合来自编码层和解码层的特征。
提出了一种用于医学图像分割的层次化U-Net结构——DAE-Former。
【网络结构】

DAE-Former的结构与U-Net类似,其中的双重注意力Dual Transformer Block由efficient attention和channel attention两部分组成,SCCA用于跳过连接,可以有效地为每个解码器提供空间信息,以便它可以在生成输出掩码时恢复细粒度的细节,对多尺度的特征进行融合,图中的ρ函数是归一化函数。
【学习心得】
在网络模型中适当进行归一化操作可以节省计算量,使得网络模型更适合实际应用。