什么时候扩容?
当向容器添加元素的时候,会判断当前容器的元素个数,如果大于等于阈值(即当前数组的长度乘以加载因子的值的时候),就要自动扩容了。
默认长度16,加载0.75
扩容(resize)就是重新计算容量,向HashMap对象里不停的添加元素,而HashMap对象内部的数组无法装载更多的元素时,对象就需要扩大数组的长度,以便能装入更多的元素。当然Java里的数组是无法自动扩容的,方法是使用一个新的数组代替已有的容量小的数组,就像我们用一个小桶装水,如果想装更多的水,就得换大水桶。
如何扩容
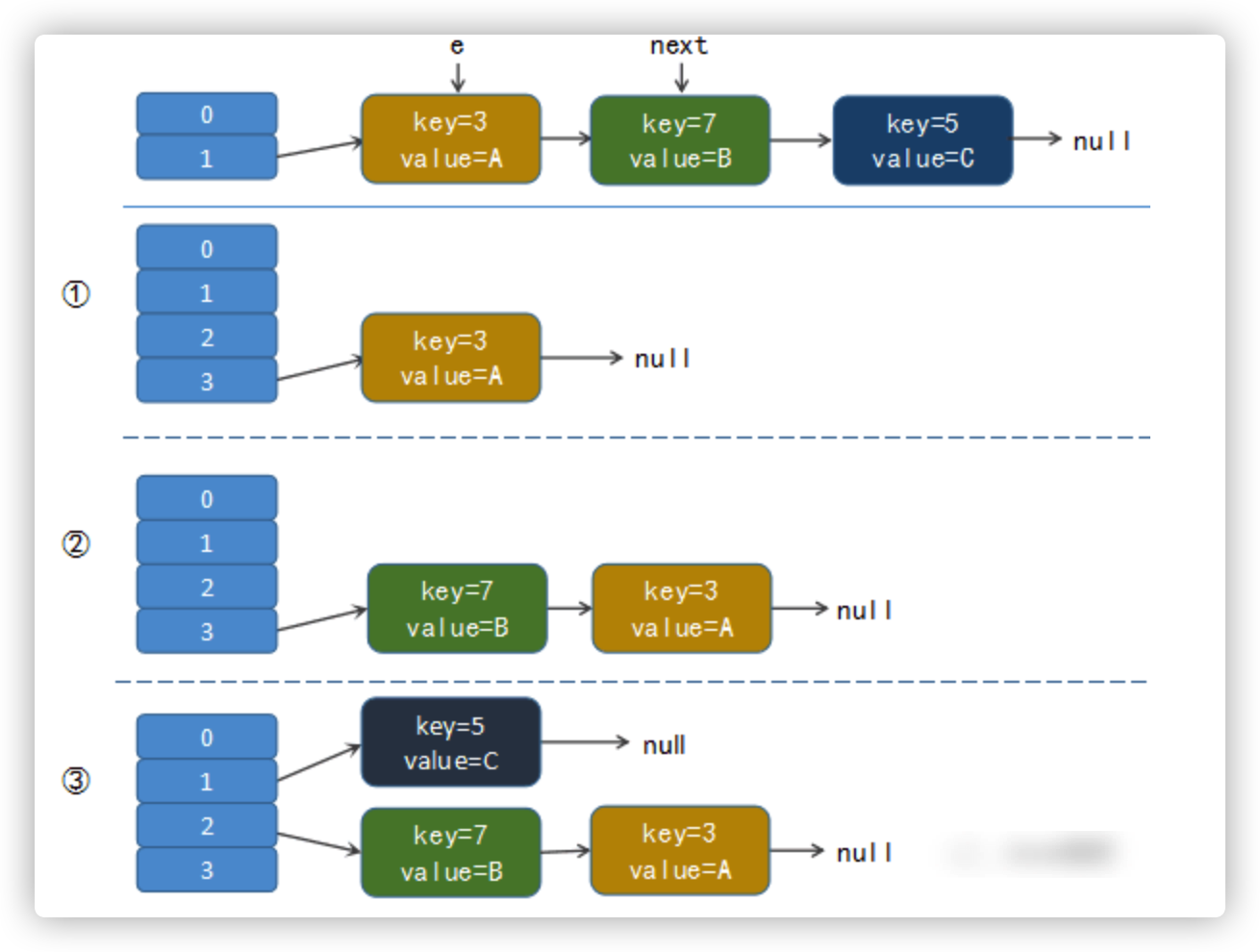
从上图,我们得知:
在resize之前,数据都冲突在旧数组下标为1的位置,可以看到有一个链表结构,且排序为3、5、7
-
第一次,转移数据,transfer key=3的数据到新数组,这个key3的next指向为null,因为新数组是对象数组,原来的值就是null
-
第二次,当key=3移动完了,就轮到key=7了,7对4取余数,所以移动到新数组之后,在这个新数组的下标和刚刚移动的key=3的下标是一样的,按照上面的代码key=7的元素的next指向table[3],当前table[3]=刚刚的key=3的元素,然后又把table[3]=key7了,这样就形成了如上的链表结构,也就是头插法链表,这个时候key=3先来的,就排到了链表尾部了;
-
第三次,我们转移key=5的元素,5对4取余数,最后这个元素落到了下标为1的位置;
通过上面整个过程的梳理,我们发现扩容的成本并不低,因为需要遍历一个时间复杂度为O(n)的数组,并且为其中的每个enrty进行hash计算。加入到新数组中,所以最好的情况是能够合理的使用HashMap的构造方法创建合适大小的HashMap,使得在不浪费内存的情况下,尽量减少扩容,这个就要根据业务来决定了。
JDK1.8的优化
我们使用的是2次幂的扩展(指长度扩为原来2倍),所以,元素的位置要么是在原位置,要么是在原位置再移动2次幂的位置。
元素在重新计算hash之后,因为n变为2倍,那么n-1的mask范围在高位多1bit(红色),因此新的index就会发生这样的变化:
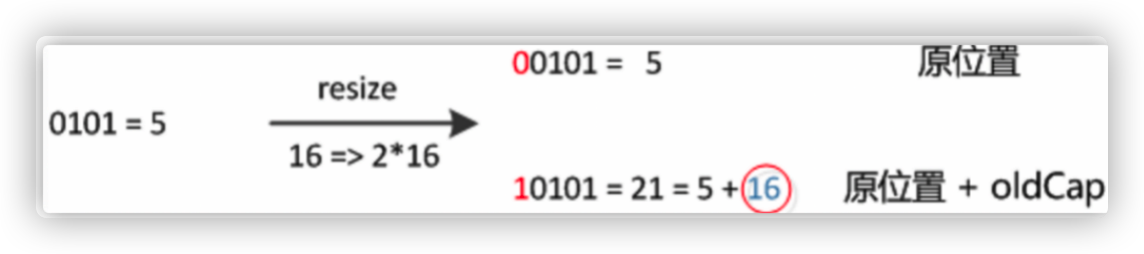
因此,我们在扩充HashMap的时候,不需要像JDK1.7的实现那样重新计算hash,只需要看看原来的hash值新增的那个bit是1还是0就好了,是0的话索引没变,是1的话索引变成“原索引+oldCap”
这个设计确实非常的巧妙,既省去了重新计算hash值的时间,而且同时,由于新增的1bit是0还是1可以认为是随机的,因此resize的过程,均匀的把之前的冲突的节点分散到新的bucket了。这一块就是JDK1.8新增的优化点。JDK1.8尾插不会倒置链表(并发头插会有死循环)。