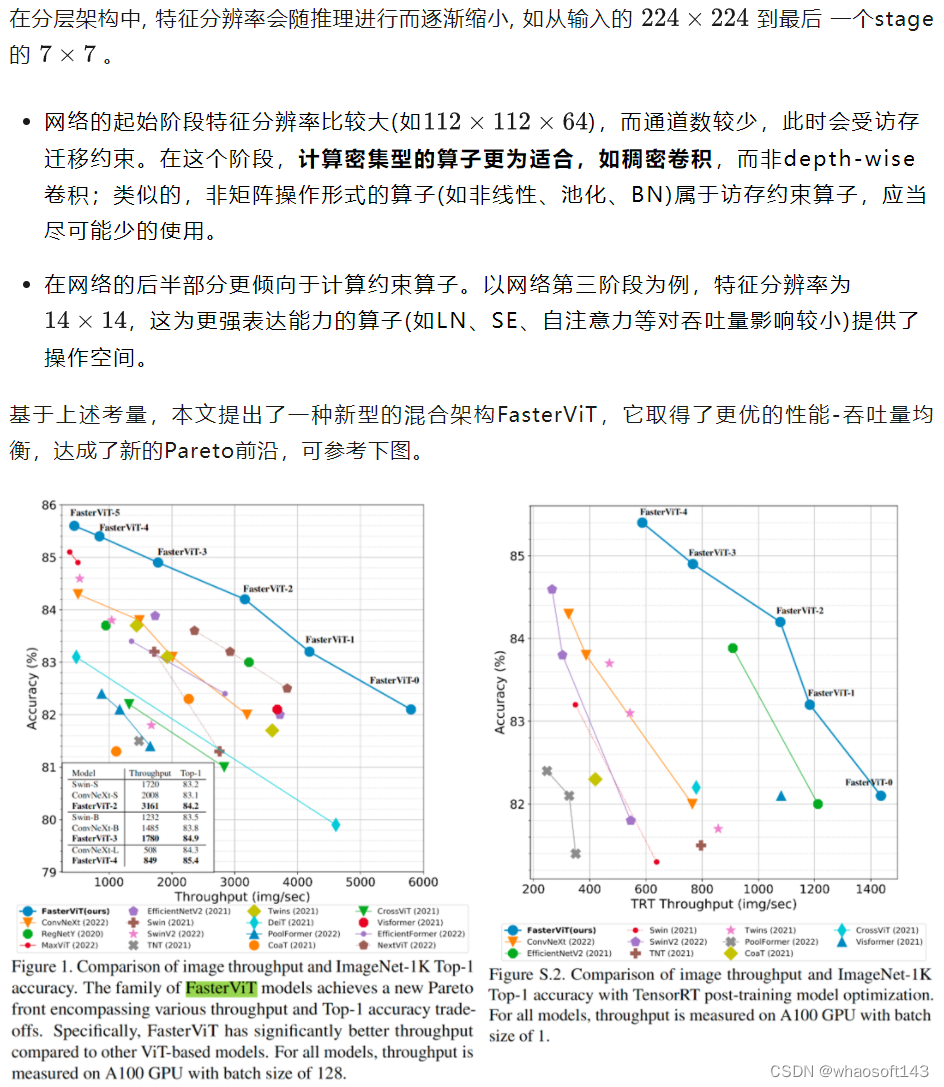
英伟达提出分层注意力,一种新型的混合架构FasterViT,它取得了更优的性能-吞吐量均衡,达成了新的Pareto前沿。
论文地址:https://arxiv.org/abs/2306.06189
代码地址:https://github.com/NVlabs/FasterViT
本文旨在面向主流硬件设备(如GPU)研发具有高吞吐量的骨干架构。当前主流硬件设备包含多个CUDA与Tensor核计算单元,它需要进行频繁的数据迁移进行计算,可能会受到数据移动带宽影响。因此,以下两种类型算子需要进行精心平衡以最大化吞吐量:
-
受计算量约束的算子称之为math-limited,笔者将其称之为计算约束算子;
-
受访存迁移约束的算子称之为memory-limited,笔者将其称之为访存约束算子。
 方案
方案
 上图给出了本文所提FasterViT架构示意图,从中可以看到:
上图给出了本文所提FasterViT架构示意图,从中可以看到:
-
在网络的前半部分,特征分辨率比较大,推理效率主要受访存约束,故它仅采用了卷积类操作以充分利用稠密卷积;
-
在网络的后半部分,特征分辨率比较小,推理效率会受计算约束,故它采用了attention等操作提升表达能力。

注2: 上述CT初始化步骤仅在每个stage执行一次, 每个Stage有自己独一的CTs。
 上图对比了不同全局-局部自注意力模块之间的区别,所提HAT将自注意力拆分为局部与亚全局形式且可压缩为2个稠密注意力。 whaosoft aiot http://143ai.com
上图对比了不同全局-局部自注意力模块之间的区别,所提HAT将自注意力拆分为局部与亚全局形式且可压缩为2个稠密注意力。 whaosoft aiot http://143ai.com
本文实验

ImageNet分类

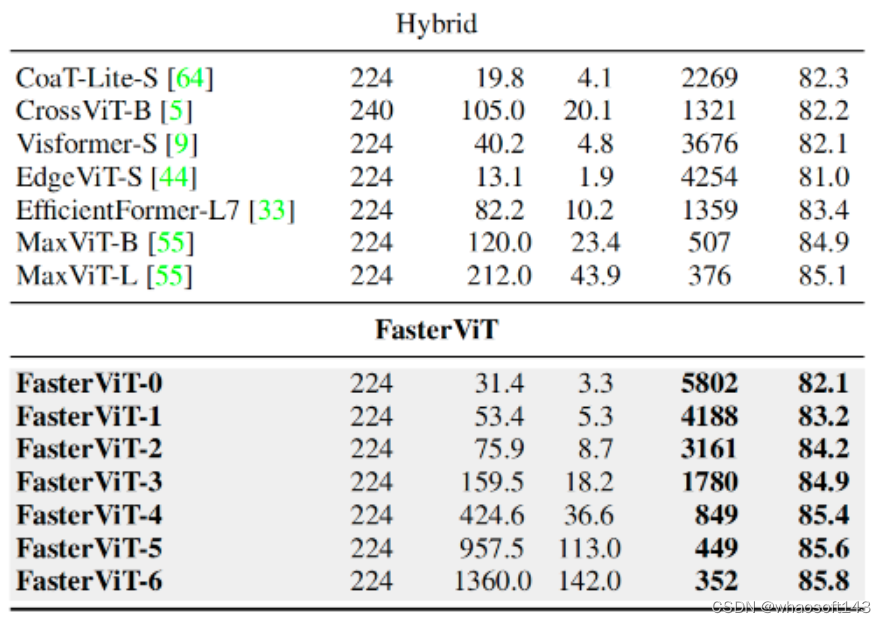 上表对比了不同Backbone在ImageNet分类任务上的性能,可以看到:
上表对比了不同Backbone在ImageNet分类任务上的性能,可以看到:
-
相比卷积架构,在同等吞吐量下,FasterViT具有更高的精度;
-
相比Transformer架构,FasterViT具有更快的推理速度;
-
相比其他混合架构,FasterViT具有更高的吞吐量,同时具有更优的Top1性能。
COCO检测与实例分割
 上表给出了COCO检测与实例分割任务上不同方案性能对比,从中可以看到:
上表给出了COCO检测与实例分割任务上不同方案性能对比,从中可以看到:
-
相比其他方案,FasterViT具有更优的精度-吞吐量均衡。
-
相比ConvNeXt-B,FasterViT指标高出0.2boxAP、0.3MaskAP,同时吞吐量高出15%;
-
相比Swin-B,FasterViT指标高1.0boxAP、1.0maskAP,同时吞吐量高出30%。
ADE20K分割

上表给出了ADE20K语义分割任务上不同方案性能对比,可以看到:
-
FasterViT具有更优的性能-吞吐量均衡;
-
相比Swin-B,FasterViT指标高出1.0mIoU@ss, 0.7mIoU@ms,同时吞吐量高出16.94%;
-
相比ConvNeXt-B,FasterViT指标高出0.4mIoU@ms,同时吞吐量高出7.01%。