前言
对于研究时间序列表征、时间序列分类,时间序列状态转换等方向,常用的简单粗暴的一个方法是SAX (Symbolic Aggregate approXimation), 由Jessica Lin等在2003年发表的论文中提出的,该论文的题目为《A Symbolic Representation of Time Series, with Implications for Streaming Algorithms》。
论文链接:https://www.cs.ucr.edu/~eamonn/SAX.pdf
一、时间表征方法
文中举例了很多种时间序列表征方法,并做了分类,具体可以在文中看看,不过都比较经典,毕竟有点久远了。
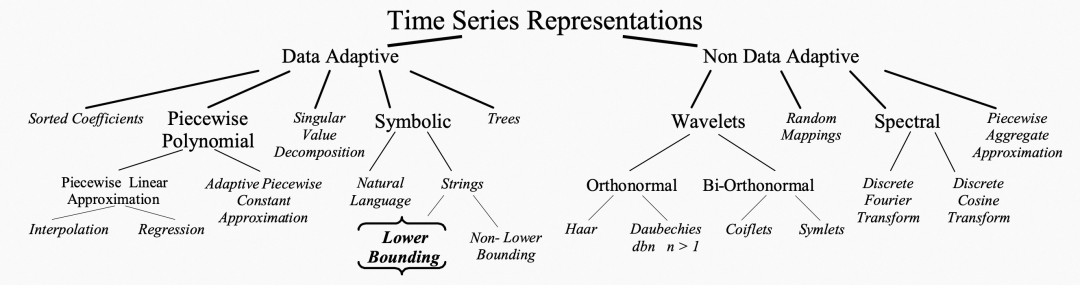
sax就属于{}那个分类
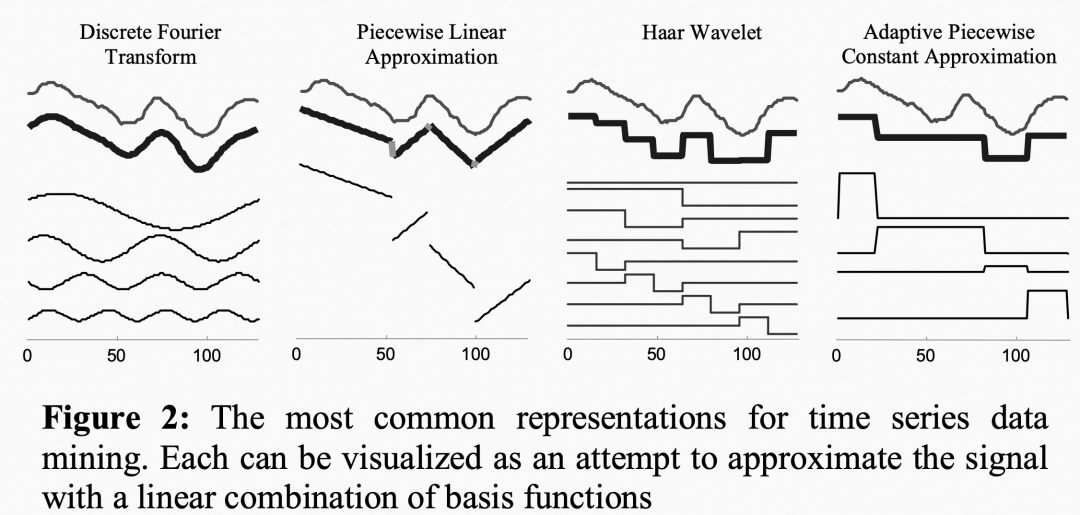 其中四种的可视化:
其中四种的可视化:
离散傅里叶变换(DFT)
离散小波变换(DWT)
分段线性(PAA)和分段常数模型(APCA)
奇异值分解(SVD)
举例的这几个我估摸着除了第三个其他都很熟悉了,当然第三个也很简单,不赘述了。
二、 SAX算法
2.1 概述
其实sax算法十分简单,且高效。

其实就两个步骤
Piecewise Aggregate Approximation
Symbol Representation
剩下两个是参数
w:PAA片段的个数
a:SR转换的alphabet里面元素的个数,比如a=3就是abc,如果是4就是abcd
2.2 PAA过程
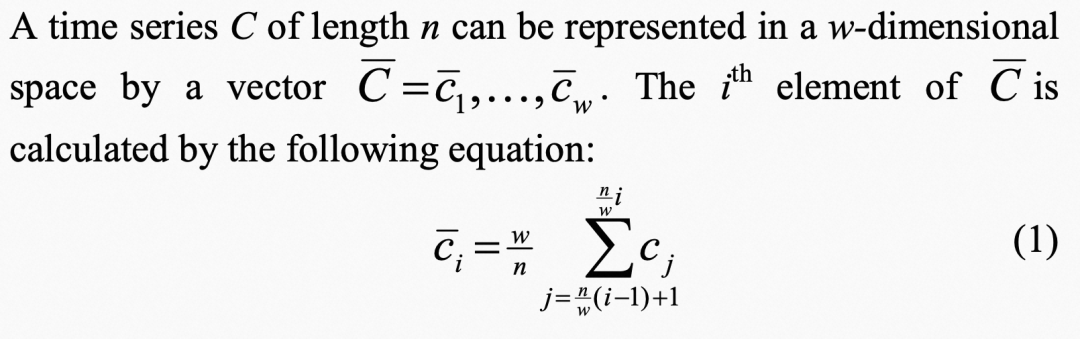
简单来说就是一个时间序列(一条线), 一共有n个点,现在转换为w个片段。
所以这里所谓的降维,是降的一个序列平行的维度,而并非pca的特征纬度的降维。
看一下图更清楚了:
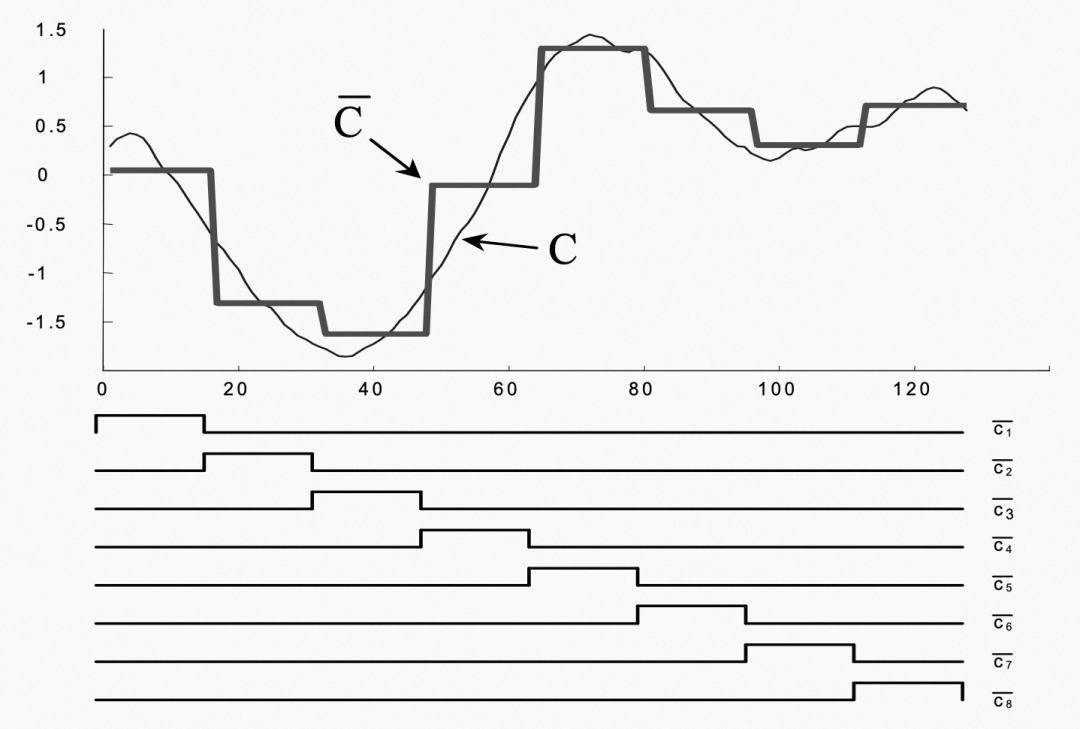
120个点转换为8个片段,可以试着带进公式看看(你会发现,其实就是要分成多少块,每一块算一下平均值罢了)
2.3 Discretization过程
转换为PAA后,可应用进一步转换以获取离散表示。
这里强调离散化要求产生具有等概率的符号,通过标准化的时间序列具有高斯分布,如下图
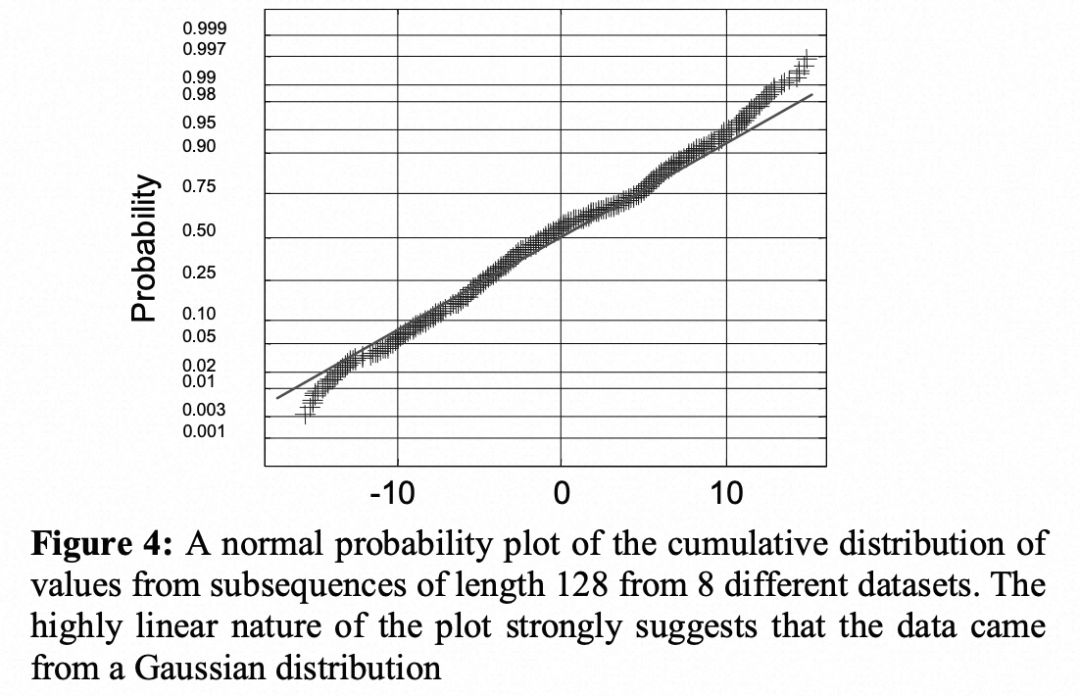
这幅图为从8个不同的时间序列中提取长度为128的子序列,并绘制得到的数据正态概率图。
这时通过breakpoints来进行离散化
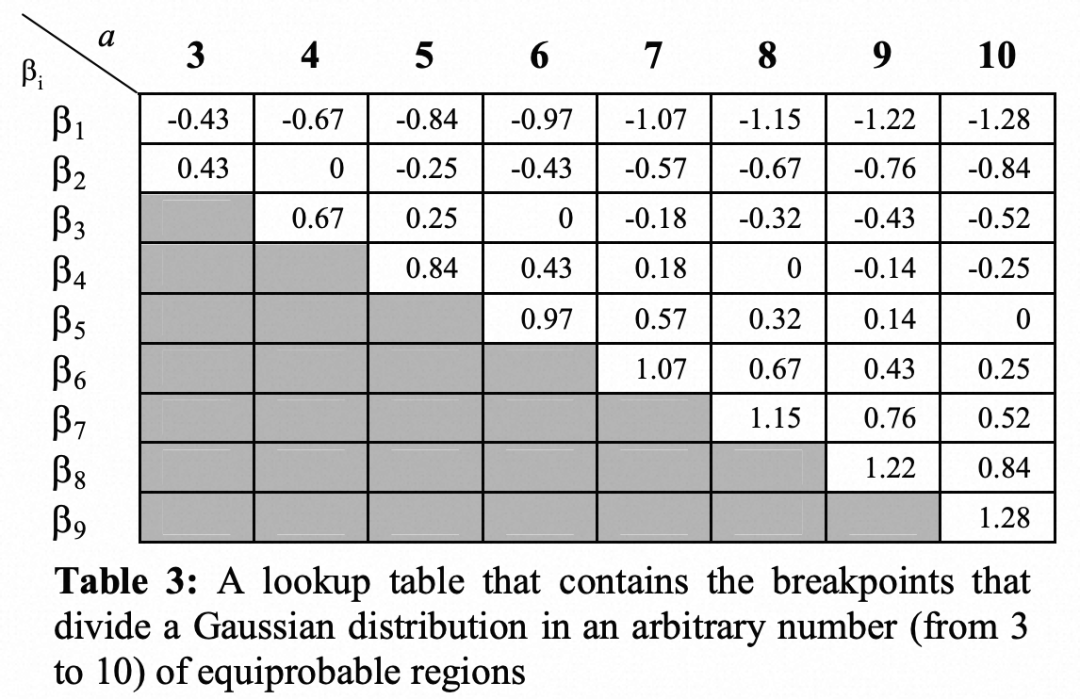
这里的数字345等代表离散个数,比如3的三个离散区间为(-inf,-0.43) [-0.43, 0.43)[0.43, inf)
这里的分割方式,都是按照Gaussian分不的等概率区间来分的。
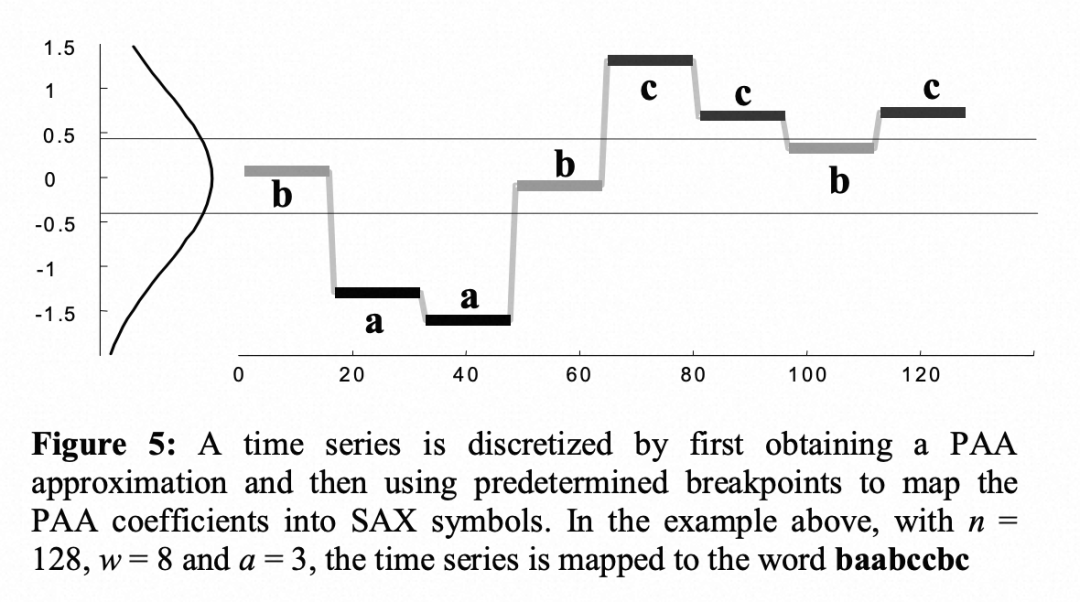
如果这里的离散用abc这种字母,则在离散为三个空间的话,则对应离散, 如下图所示:
(-inf,-0.43) -> a
[-0.43, 0.43)-> b
[0.43, inf)-> c
2.4 距离比较
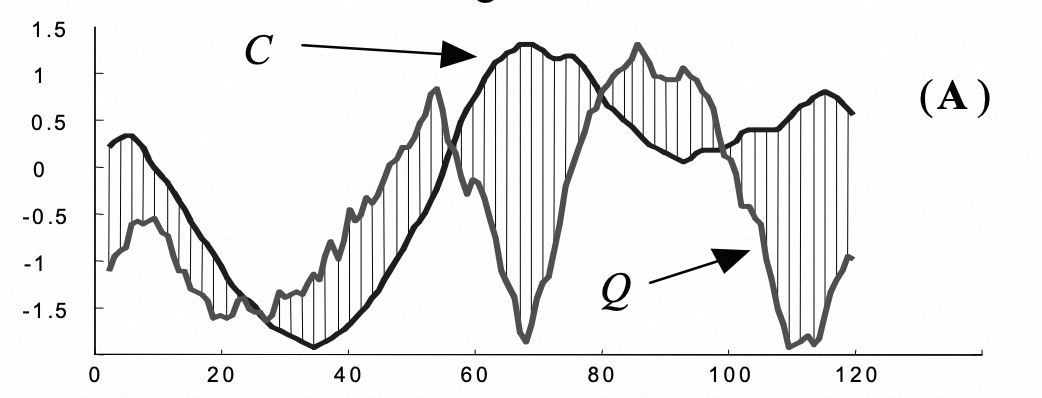
时间序列原始比较
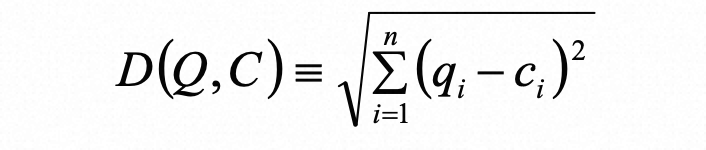
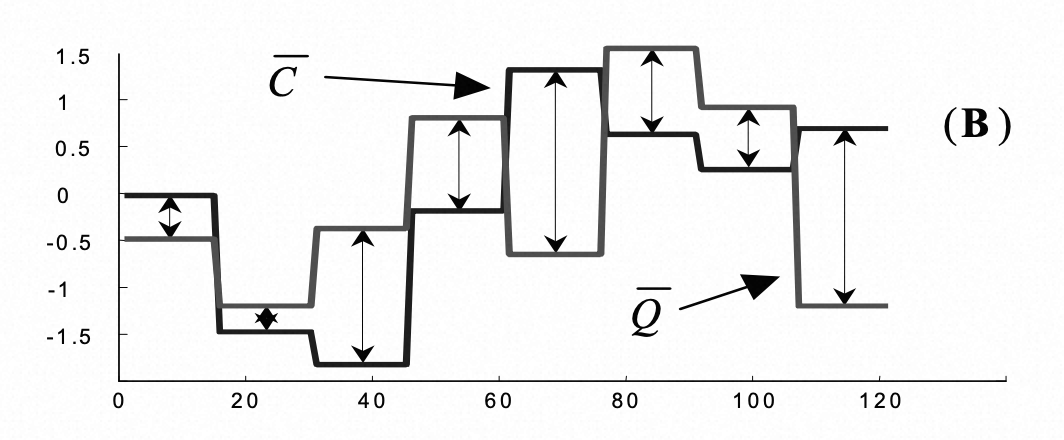
转换为paa比较
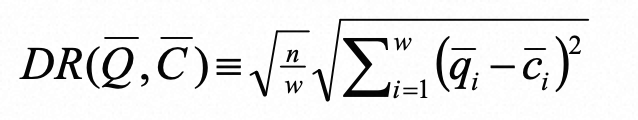
sax比较方式 遵循最小比较原则
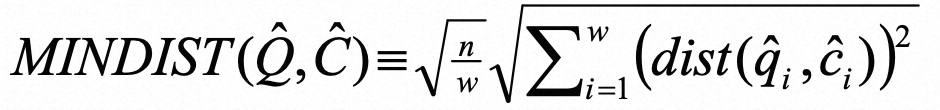
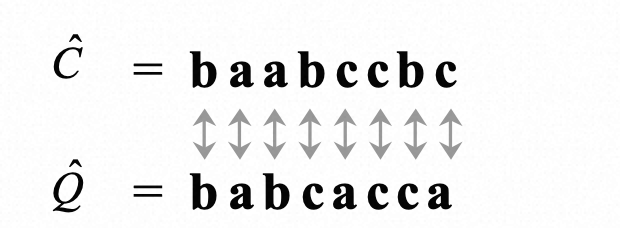
最小原则含义:
 相邻两个距离为0, 比如离散相邻的a和b的距离为0
相邻两个距离为0, 比如离散相邻的a和b的距离为0
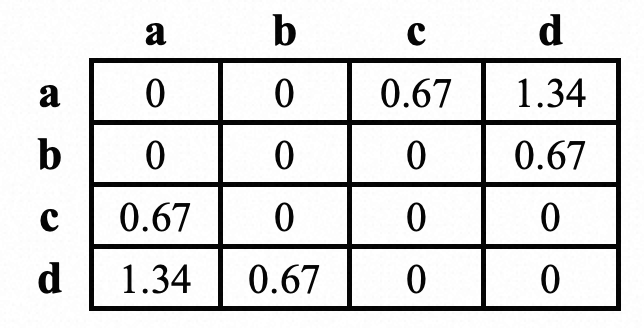
比如参考这个表格:
离散为四个,则
(-inf, -0.67) -> a
[-0.67, 0) -> b
[0, 0.67) -> c
[0.67, inf) ->d
ab距离为 -0.67-(-0.67) = 0 ac距离为 0-(-0.67) = 0.67
其实就是大的离散值代表的区间的下界限和小离散值代表区间的上界限相减得到距离
2.5 数据压缩
这里给出了sax和其他几种常见压缩方法的可视化对比
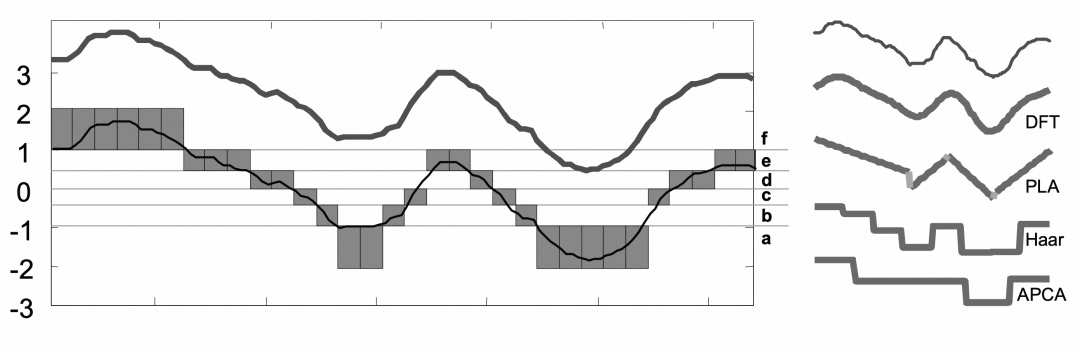
压缩完的时间序列离散化为:ffffffeeeddcbaabceedcbaaaaacddee
其他信息可以去看原文数据压缩部分Numerosity Reduction
三、结果
主要做了使用sax之后时间序列聚类和分类的实验
3.1 聚类
层次聚类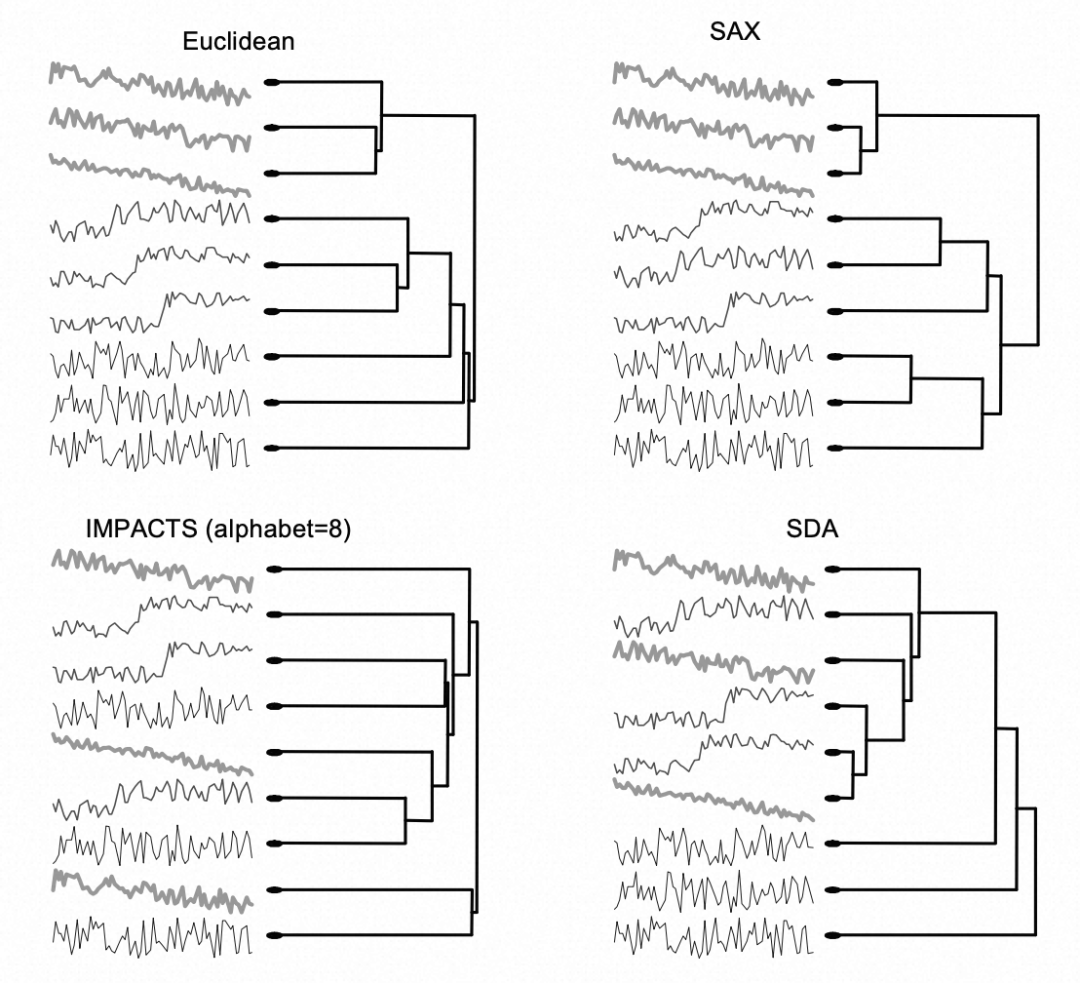
可以客观地说明SAX更优秀,因为它正确地将每个类别分配到其自己的子树中
3.2 分类
在cc和cbf两个数据集上测试,使用leaving-one-out cross validation方法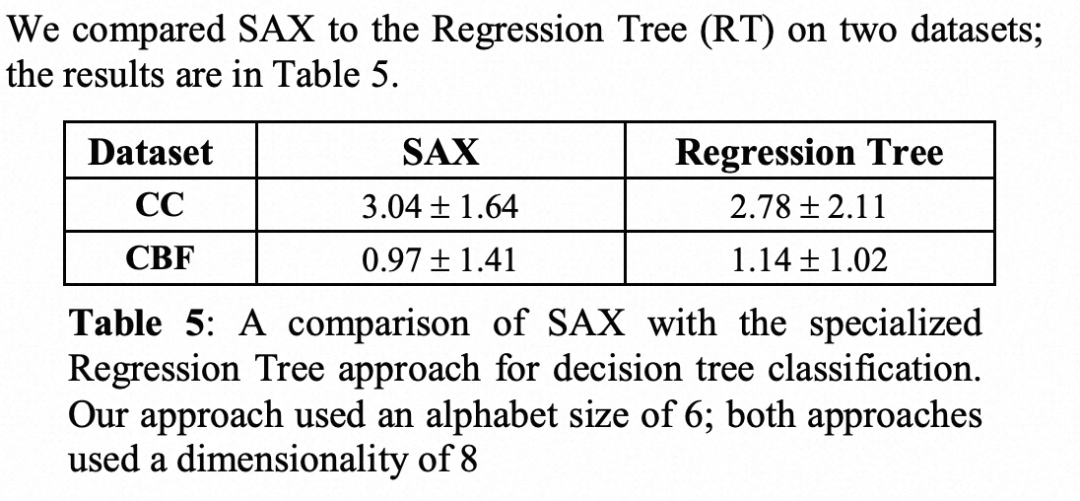
四、总结
breakpoint那里其实操作空间很大,可以自主的根据自己的场景去调整,或者可以通过对数据分布的学习,动态调整,并非一定要是Gaussian分布,而且要注意如果是动态学习的breakpoints,一定要记住在train的结果把breakpoints保留,类似于fit模式
尝试下来,极值对该方法影响还是很大的,最好去掉那些极大值之后再进行sax
Word Size和Alphabet size参数对最终的结果影响很大,受数据分布影响也很大,如果已经去掉极值,建议可以把要处理的数据进行sax转换之后再进行可视化,看是否可以保留原数据的模样
推荐阅读:
公众号:AI蜗牛车
保持谦逊、保持自律、保持进步

发送【蜗牛】获取一份《手把手AI项目》(AI蜗牛车著)
发送【1222】获取一份不错的leetcode刷题笔记
发送【AI四大名著】获取四本经典AI电子书