前言
本文将和大家一起探讨python的多进程并发编程(上篇),使用内置基本库multiprocessing来实现并发,先通过官方来简单使用这个模块。先打好基础,能够有个基本的用法与认知,后续文章,我们再进行详细使用。
本文为python并发编程的第四篇,上一篇文章地址如下:
python:并发编程(三)_Lion King的博客-CSDN博客
下一篇文章地址如下:
python:并发编程(五)_Lion King的博客-CSDN博客
一、快速开始
官方文档:multiprocessing --- 基于进程的并行 — Python 3.11.4 文档
1、通过Process Explorer对比进程情况
基于官方代码,我加了“while True:”这个无线循环,以方便观察进程的情况。
这段代码创建了一个无限循环,在每次循环中使用multiprocessing模块的进程池来执行函数f(x)。具体步骤如下:
(1)导入multiprocessing模块的Pool类。
(2)定义了一个函数f(x),用于计算传入参数x的平方。
(3)在if __name__ == '__main__':条件下创建一个进程池p,并指定进程池的大小为5。
(4)使用p.map()方法并行地对给定的迭代对象[1, 2, 3]中的每个元素应用函数f(x),并返回结果。
(5)打印输出结果。
(6)进入无限循环。
from multiprocessing import Pool
def f(x):
return x*x
if __name__ == '__main__':
while True:
with Pool(5) as p:
print(p.map(f, [1, 2, 3]))运行前的进程情况:

运行时的进程情况:
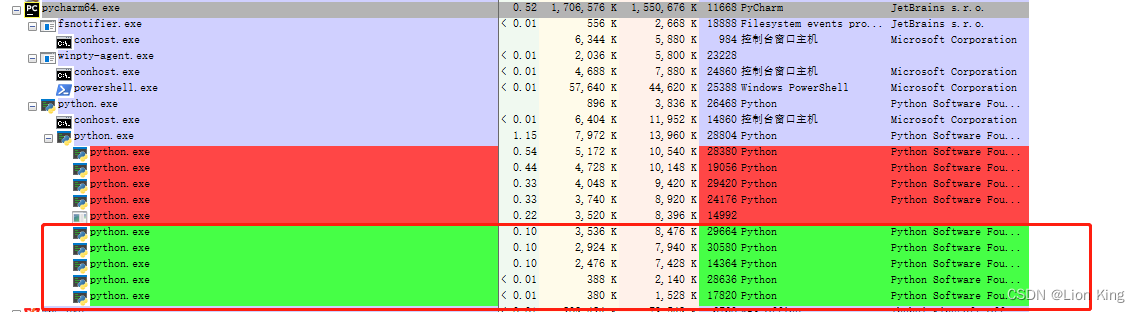
通过上述实验,我们知道,这个程序在不断创建5个进程并进行销毁,红色部分是被销毁的5个进程,绿色部分是新生成的5个进程。通过Pycharm运行脚本时,会先生成python.exe子进程,这个子进程又会生成python.exe子进程和conhost.exe子进程,而第二个python.exe子进程又会生成5个子进程,来执行任务。
修改一下上述代码让其报错:
from multiprocessing import Pool
def f(x):
return x*x
# if __name__ == '__main__':
# while True:
with Pool(5) as p:
print(p.map(f, [1, 2, 3]))这个实验告诉我们,进程只能在主模块( if __name__ == '__main__':)下运行,否则报如下错误:
RuntimeError:
An attempt has been made to start a new process before the
current process has finished its bootstrapping phase.
This probably means that you are not using fork to start your
child processes and you have forgotten to use the proper idiom
in the main module:
if __name__ == '__main__':
freeze_support()
...
The "freeze_support()" line can be omitted if the program
is not going to be frozen to produce an executable.
因此,为了避免在创建子进程时触发无限递归的问题,需要使用if __name__ == '__main__':条件来确保代码在主模块中执行。这是因为multiprocessing模块在Windows操作系统下的多进程实现中会创建一个新的Python解释器实例,而这段代码本身也包含了创建进程的操作,因此需要确保它只在主模块中执行一次。
2、进程类的使用
from multiprocessing import Process
import os
def info(title):
print(title)
print('module name:', __name__)
print('parent process:', os.getppid())
print('process id:', os.getpid())
def f(name):
info('function f')
print('hello', name)
if __name__ == '__main__':
while True:
info('main line')
p = Process(target=f, args=('bob',)) # 创建一个子进程,目标函数为f,传入参数为'bob'
p.start() # 启动子进程的执行
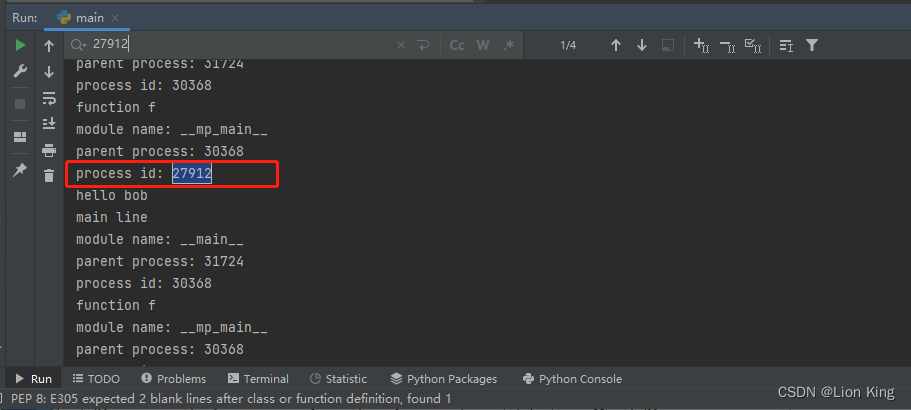
p.join() # 等待子进程执行结束以上代码使用了multiprocessing.Process模块来创建一个子进程,并在子进程中执行函数f。在主模块中,定义了两个辅助函数info和f。
info函数用于打印进程的相关信息,包括标题、模块名、父进程ID和当前进程ID。
f函数是子进程执行的目标函数,它接受一个参数name,在函数内部会调用info函数打印信息并输出hello加上传入的name参数。
在主模块中,首先调用info函数打印主线程的信息。然后,通过Process类创建一个子进程对象p,将目标函数设为f,传入参数('bob',)。接着,调用p.start()启动子进程的执行,子进程会执行函数f('bob')。最后,通过p.join()等待子进程执行结束。
在运行时,会输出主进程和子进程的相关信息,并打印出hello bob作为子进程执行的结果。

3、上下文启动方法
为了提高代码的可移植性和兼容性,在使用multiprocessing模块时,可以根据不同的操作系统设置适当的启动方法。通过使用mp.set_start_method('spawn'),可以确保代码在各个操作系统上都能正常运行(比如先判断系统类型,再调用该系统对应的方法),并且不需要针对不同的操作系统编写不同的代码逻辑。
import multiprocessing as mp
def foo(q):
q.put('hello')
if __name__ == '__main__':
mp.set_start_method('spawn') # 设置启动方法为'spawn'
q = mp.Queue() # 创建进程间通信的队列
p = mp.Process(target=foo, args=(q,)) # 创建子进程,目标函数为foo,传入参数为q
p.start() # 启动子进程的执行
print(q.get()) # 从队列中获取子进程放入的值并打印
p.join() # 等待子进程执行结束
其中,set_start_method('spawn')方法可以被 get_context('spawn') 替代。
4、在进程之间交换对象
队列
from multiprocessing import Process, Queue
def f(q):
q.put([42, None, 'hello'])
if __name__ == '__main__':
# 创建一个队列对象
q = Queue()
# 创建子进程,指定目标函数为f,将队列对象作为参数传递给子进程
p = Process(target=f, args=(q,))
# 启动子进程
p.start()
# 从队列中获取数据并打印
print(q.get()) # 输出 "[42, None, 'hello']"
# 等待子进程执行完成
p.join()
这段代码使用了multiprocessing模块中的Process和Queue来实现进程间通信。具体的代码解释如下:
(1)导入必要的模块:from multiprocessing import Process, Queue
(2)定义一个函数f,该函数接收一个Queue对象作为参数,并向队列中放入一个包含数据的列表[42, None, 'hello']。
(3)在if __name__ == '__main__':条件下,创建一个Queue对象q,用于进程间通信。
(4)创建一个子进程p,通过Process类的构造函数指定要执行的函数为f,并将Queue对象q作为参数传递给子进程。
(5)启动子进程p,并等待子进程执行完成。
(6)在主进程中使用q.get()方法从队列中获取数据,并打印结果[42, None, 'hello']。
(7)等待子进程执行完毕,调用p.join()进行阻塞,确保子进程执行完成后再继续执行主进程。
该代码实现了在主进程和子进程之间通过队列进行数据传递的功能。主进程创建了一个队列q,并将其作为参数传递给子进程p。子进程调用函数f将数据放入队列中,主进程通过q.get()方法从队列中获取数据并进行打印。这样就实现了主进程和子进程之间的数据交换。
管道
from multiprocessing import Process, Pipe
def f(conn):
# 向管道发送数据
conn.send([42, None, 'hello'])
# 关闭管道连接
conn.close()
if __name__ == '__main__':
# 创建管道,返回父进程和子进程的连接对象
parent_conn, child_conn = Pipe()
# 创建子进程,指定目标函数为f,将管道的子连接对象作为参数传递给子进程
p = Process(target=f, args=(child_conn,))
# 启动子进程
p.start()
# 从父连接接收数据并打印
print(parent_conn.recv()) # 输出 "[42, None, 'hello']"
# 等待子进程执行完成
p.join()
当我们在多进程编程中需要进行进程间通信时,可以使用管道(Pipe)来实现。上述代码演示了使用管道进行进程间通信的示例。
首先,我们导入了Process和Pipe模块。Process用于创建子进程,Pipe用于创建管道对象。
然后,定义了一个名为f的函数,该函数接受一个管道连接对象作为参数。在函数内部,我们使用send方法向管道发送了一个包含 [42, None, 'hello'] 的列表,并使用close方法关闭了管道连接。
在if __name__ == '__main__'条件下,我们创建了一个管道对象,通过Pipe()函数返回一个父连接对象和一个子连接对象。
接下来,我们创建了一个子进程 p,指定目标函数为 f,并将管道的子连接对象作为参数传递给子进程。
然后,我们启动子进程 p。
在父进程中,我们使用 parent_conn.recv() 方法从父连接接收数据,并打印接收到的数据。在这个例子中,我们接收到了 [42, None, 'hello'],并将其打印出来。
最后,我们使用 p.join() 等待子进程执行完成。
通过这段代码,我们实现了父进程和子进程之间的通信,使用管道作为数据传输的通道。父进程向管道发送数据,子进程从管道接收数据,并在父进程中打印出接收到的数据。这样就实现了简单的进程间通信。
二、队列与管道那些事儿
1、队列与它的作用
进程间通信的队列(Queue)是一种在多进程编程中用于在不同进程之间传递数据的机制。它允许一个进程将数据放入队列,而其他进程则可以从队列中获取这些数据。
队列在多进程编程中的作用主要有以下几个方面:
(1)数据共享:队列提供了一种安全可靠的方式来共享数据。不同进程可以通过队列进行数据的交换和共享,而不需要使用其他复杂的机制来处理数据的同步和互斥访问。
(2)同步机制:队列可以用作进程间的同步机制。例如,一个进程可以将任务放入队列中,而其他进程则可以从队列中获取任务并进行处理。这样可以实现进程之间的协调和同步,确保每个进程按照预期顺序执行任务。
(3)解耦:通过使用队列,可以将不同的进程解耦。每个进程可以独立执行自己的任务,通过队列进行数据交换,而不需要显式地依赖其他进程的状态和执行顺序。
(4)缓冲作用:队列可以作为数据的缓冲区,用于平衡生产者和消费者之间的速度差异。当生产者产生数据的速度超过消费者处理数据的速度时,数据可以暂时存储在队列中,避免数据丢失或生产者阻塞。这种缓冲机制可以提高系统的性能和稳定性。
总而言之,进程间通信的队列是一种重要的机制,用于实现不同进程之间的数据交换、同步和解耦,提高系统的可靠性、性能和可扩展性。
2、管道与它的作用
进程间通信的管道(Pipe)在多进程编程中用于实现两个进程之间的双向通信。
具体而言,管道提供了一个连接两个进程的通道,允许它们进行双向的数据传输。管道有两个端点,分别是父进程端和子进程端。父进程可以通过管道的一个端点发送数据给子进程,而子进程则可以通过另一个端点将数据发送回父进程。
进程间通信的管道的作用包括:
(1)数据传输:管道允许父进程将数据发送给子进程,子进程可以接收并处理这些数据,然后通过管道将处理结果发送回父进程。
(2)双向通信:管道提供了双向的通信能力,父进程和子进程可以在同一个管道上进行双向的数据交换,实现进程之间的相互通信。
(3)同步机制:管道提供了同步机制,确保发送和接收操作的顺序和一致性。如果一个进程尝试从管道中读取数据,但管道为空,该进程将被阻塞,直到管道中有数据可用。
(4)进程间解耦:通过使用管道,不同的进程可以相互解耦,它们只需关注通过管道发送和接收数据,而不需要关心其他进程的具体实现细节。
总的来说,进程间通信的管道提供了一个可靠、双向的通信通道,帮助不同的进程在并发执行时进行双向数据交换和协作。
3、队列与管道的区别
在Python的multiprocessing模块中,队列(Queue)和管道(Pipe)都可以用于实现进程间的通信,但它们有一些区别:
(1)功能:队列是一个线程安全的数据结构,支持多个进程往其中放入和取出数据,可以实现生产者-消费者模型。而管道是一个双向通道,可以在两个进程之间进行双向的数据传输。
(2)接口:队列提供了put()和get()等方法,用于在进程间安全地放入和取出数据。管道则提供了两个连接对象,可以通过发送和接收消息来实现进程间通信。
(3)通信方式:队列使用的是先进先出(FIFO)的方式,即先放入的数据先被取出。而管道可以双向传输数据,可以按照需要进行发送和接收。
(4)实现方式:队列是基于管道和锁机制实现的,因此它是进程安全的。管道则是通过创建两个连接对象来实现进程间通信。
总的来说,队列适用于多个进程之间需要进行数据共享和通信的场景,特别适合于生产者-消费者模型。而管道适用于需要双向通信的场景,可以在两个进程之间进行双向的数据传输。根据具体的需求和场景,选择合适的进程间通信方式。