作者 | ShuYini
单位 | AINLPer
来自 | PaperWeekly
进NLP群—>加入NLP交流群

引言
Prompt Tuning 可以让预训练的语言模型快速适应下游任务。虽然有研究证明:当训练数据足够多的时候,Prompt Tuning 的微调结果可以媲美整个模型的训练调优,但当面对 Few-shot 场景时,PT 的调优方法还是存在一定的局限性。针对这个问题,复旦提出了多任务预训练模块化 Prompt(简称为:),来提高模型在 Few-shot 场景下的 PT 效果,使模型能够快速适应下游任务。

论文链接:
https://arxiv.org/pdf/2210.07565.pdf
代码链接:
https://github.com/Hzfinfdu/MPMP


背景介绍
基于 Prompt Learning 的预训练模型在 Few-shot 场景下取得了显著的进展,它缩小了模型训练和下游任务微调之间的差距,并且通过将下游任务转换成统一的语言建模任务,可以重复使用预训练模型头,而不是训练一个随机初始化的分类头来解决有限数据的任务。然而,基于 Prompt Learning 通常需要针对每个下游任务进行全参数微调,这就需要大量的计算资源,尤其当面对上百亿的大模型的时候。
随着时间推移,近期有很多工作致力于有效的 prompt learning 方法的研究,该方法只需学习少量的 soft prompt 参数,并且能够保持 PTM 主体参数不变。与模型的整体调优相比,prompt 调优优势明显,它对计算资源要求较低并且针对特定的下游任务能够实现快速调优匹配。但是尽管已经证明,当训练数据足够时,提示调整可以与完整模型调整的性能相匹配,但由于随机初始化的 soft prompt 在预训练和微调之间引入了新的差距,因此在 Few-shot 中无法从零开始训练 soft prompt。
「为了弥补 Prompt Tuning 的预训练和微调之间的差距,本文提出了多任务预训练模块化提示 (),它是一组在 38 个中文任务上预训练的可组合提示」,在下游任务中,预训练的 prompt 可以有选择地进行激活和组合,提高对未知任务的泛化能力。为了弥合预训练和微调之间的差距,将上下游任务制定为统一到了一个机器阅读理解任务中。
通过在梯度下降、黑盒调优两种学习范式的实验,证明了 在 Few-shot 学习场景中,相比比 Prompt tuning、完整模型调优和其它的 Prompt 预训练方法都具有显著的优势,最后作者还证明了仅通过学习 8 个参数来组合预训练的模块化提示,就可以实现对下游任务的快速适应。

方法介绍
方法主要通过以下三个步骤实现对下游任务的快速适应:(1) 在大规模无标签数据上进行自监督预训练;(2) 使用多任务学习进行预训练模块指令和相应的 route;(3) 激活并调整子集指令以进行对下游任务的适应。具体流程图如下所示:
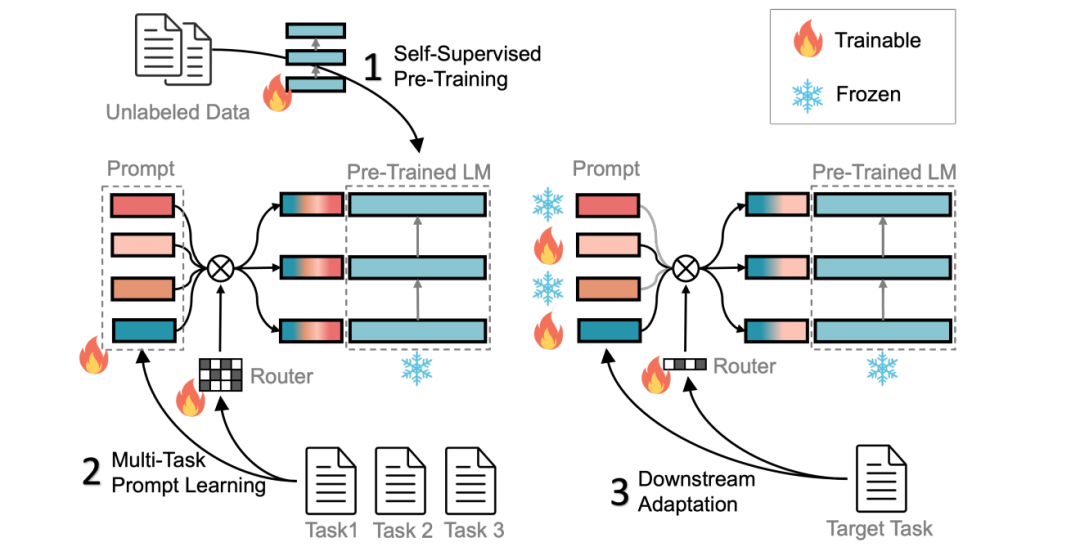
方法的主要内容包括:「统一为 MRC 任务、深度模块化 Prompt、多任务预训练、下游 FT」等四个方面。
「统一 MRC 任务」:基于 Prompt 的学习方法不能涵盖较广范围的任务,并且任务之间的标签词可能不同,从而导致预训练模型在不同任务上的效果不佳。基于 MCC 方法,可以将上下游任务转化成 MCC 任务使得不同任务可以共享相同的标签词,但该方法当面对大于 16 个标签的分类任务时仍存在局限性。为此 方法将上下游任务统一成机器阅读理解 (MRC) 格式,通过构建一个查询来进行分类任务,进而可以处理不同标签数的任务,从而实现更广泛的任务支持。
「深度模块化 Prompt」:为了增加 soft prompt 的能力,使其匹配训练数据的复杂性,作者从深度和宽度两个维度扩展了 soft prompt,具体如下图所示:
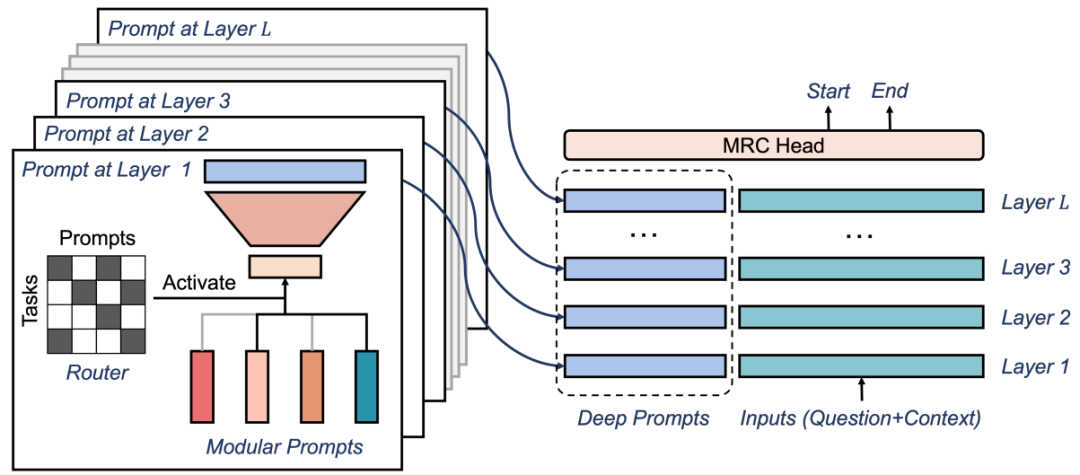
其中:首先在深度方面,作者增加了 LSTM 层或 Transformer Decoder 来实现深度扩展。这些层使得模型可以更好地学习输入序列的表示,并且能够考虑更多的上下文信息;其次在宽度方面,作者在 soft prompt 里面添加了更多的词汇和语义信息。通过深度和宽度的拓展,soft prompt 可以更好地匹配训练数据的复杂性,从而提高模型的性能和准确率。
「多任务预训练」:多任务学习已被证明可以提高各种任务的 prompt learning 的表现。作者对由 38 个不同类型、领域、大小的中文 NLP 任务组成的混合任务进行了深度模块化提示的预训练。为了处理不平衡的数据大小,对于每次向前计算,首先随机从 1 到 38 中选择一个任务 ID,然后获取对应于所选择任务的一个批次的训练数据,从而每个任务的学习步骤数量应该是相同的。
「下游 FT」:为了能够快速适应下游任务,本文通过两个阶段进行微调,如下图所示:
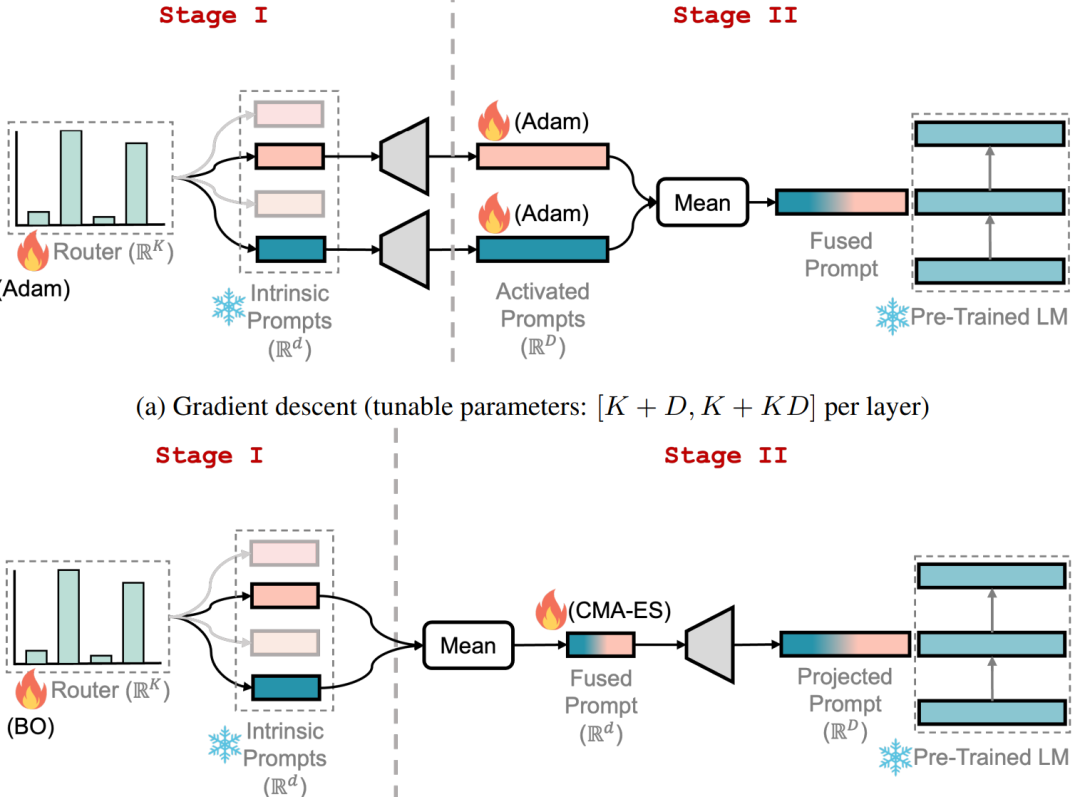
其中:在第一阶段,为每个层分配一个随机路由,并训练 route 选择性地重用预训练的模块提示来解决目标任务,同时保持所有其他参数冻结。在第二阶段,冻结 route 并只微调选择的提示。整个微调过程中,PTM 参数保持不变。同时作者探索了基于梯度下降和黑盒调优两种学习范式下的微调。对于梯度下降,使用 Adam 优化器进行两个阶段的微调。对于黑盒 FT,采用贝叶斯优化在第一阶段优化 route,并采用 CMAES 优化选择的内在 prompt ,同时冻结映射矩阵 A。

实验思路
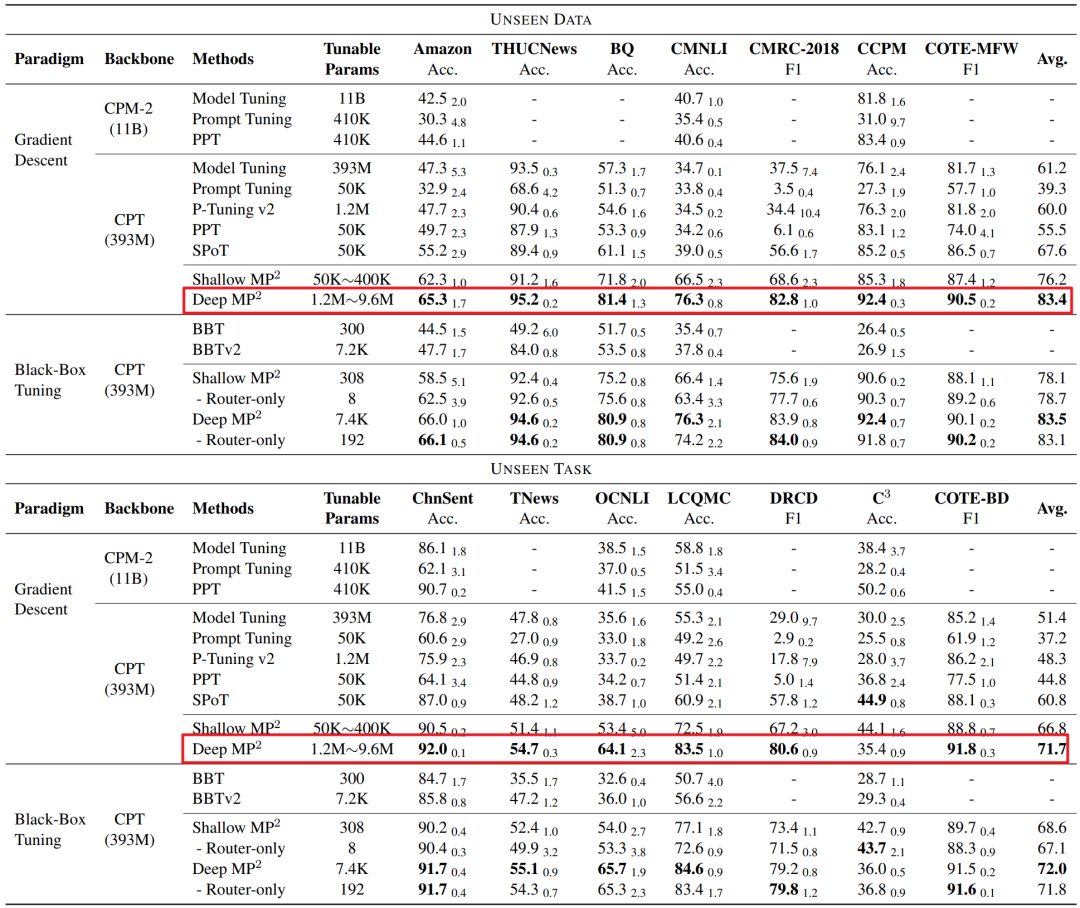
在 38 个中文 NLP 任务上预训练 ,然后在 14 个下游任务上进行评估。在 Few-Shot 下的实验表明,具体如下图所示,可以发现「其性能明显优于 PT、全模型微调和之前的 prompt 训练方法」。 仅通过调整 route(仅有 8 个参数)冻结 PTM 和所有 prompt,就可以实现对下游任务的快速适应。
进NLP群—>加入NLP交流群