NVIDIA H100 80GB PCIe 动手进行 CFD 仿真
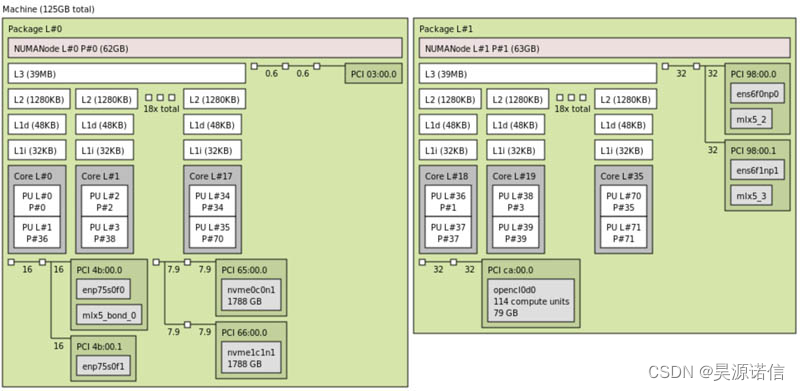
首先,我们有测试系统。这是在 NUMA 节点 L1 上具有 114 个计算单元和 80GB 内存的 OpenCL 设备的系统:
这是卡的 nvidia-smi 输出:
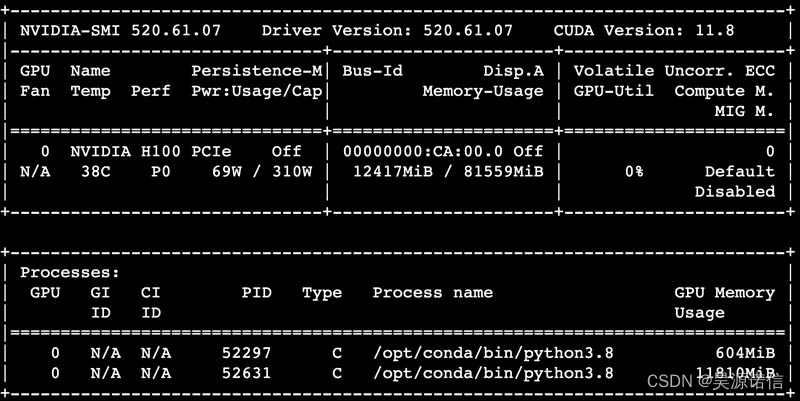
至于功耗,我们认为 68-70W 是相当正常的。310W 的最大功耗似乎有点高,但我们确实在某些 AI 工作负载上达到了这个数字。
尽管如此,我们还是想突出莫里茨的工作。以下是他的其他基准测试结果中的 NVIDIA H100 80GB 结果:
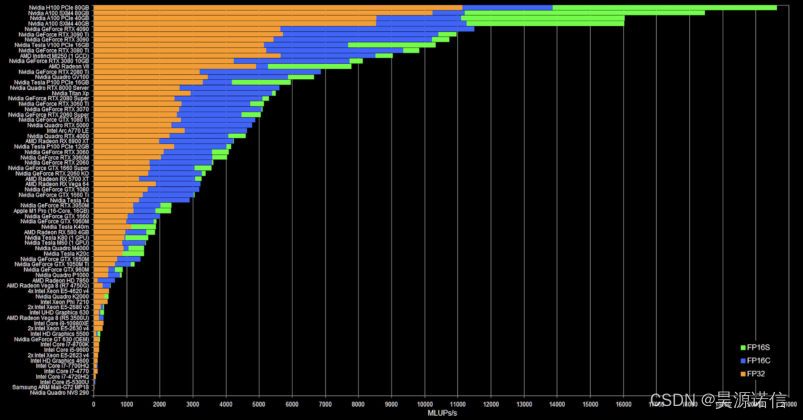
您可能需要查看上面图表的较大版本,但 H100 80GB PCIe 现在位于该图表的顶部。其次是 A100 SXM 80GB,然后是 PCIe A100,然后是 40GB SXM A100。无论如何,这是一个显着的改进。
以下是您从 Mortiz 那里看到的内容的描述:
这 3 个数字都是每秒 Mega Lattice UPdates,或者每秒计算多少百万个网格点。FluidX3D 是一种晶格玻尔兹曼方法 (LBM) 流体求解器,可在每个时间步计算立方网格上所有点的密度和速度。LBM 通过在内存中复制密度分布函数(DDF,这些只是浮点数)来工作,并且完全受带宽限制。FluidX3D 在 FP32 中执行所有算术运算,但对于此内存访问具有 3 级精度:
- FP32 : 标准 FP32
- FP16S:IEEE-754 FP16,在转换前/后具有比例因子;硬件支持转换
- FP16C:一种自定义的 16 位浮点格式,只有 4 位指数和更准确的 11 位尾数。在某些情况下,这比 FP16S 更准确。转换是通过大量整数运算手动完成的,需要大约 51 条指令。由于 LBM 受带宽限制,将 DDF 从 FP32 压缩为任一 FP16 格式会使性能翻倍。FP16C 大量使用 int 算术,因此通常没有那么快。在大多数情况下,压缩根本不会影响准确性。
对于某些数据点,上述功耗:
**FP32 :**217W
**FP16S:**257W
**FP16C:**277W
这样,效率是:
**FP32:**51.3MLUP/W
**FP16S:**74.5MLUP/W
**FP16C:**53.9MLUP/W
有关CFD 仿真及H100的更多信息,可查看【昊源诺信】