阿里云大数据ACP认证学习笔记
1.大数据基础
2.大数据计算服务Maxcompute
2.1基础知识
2.1.1购买Maxcompute并创建项目增加子用户
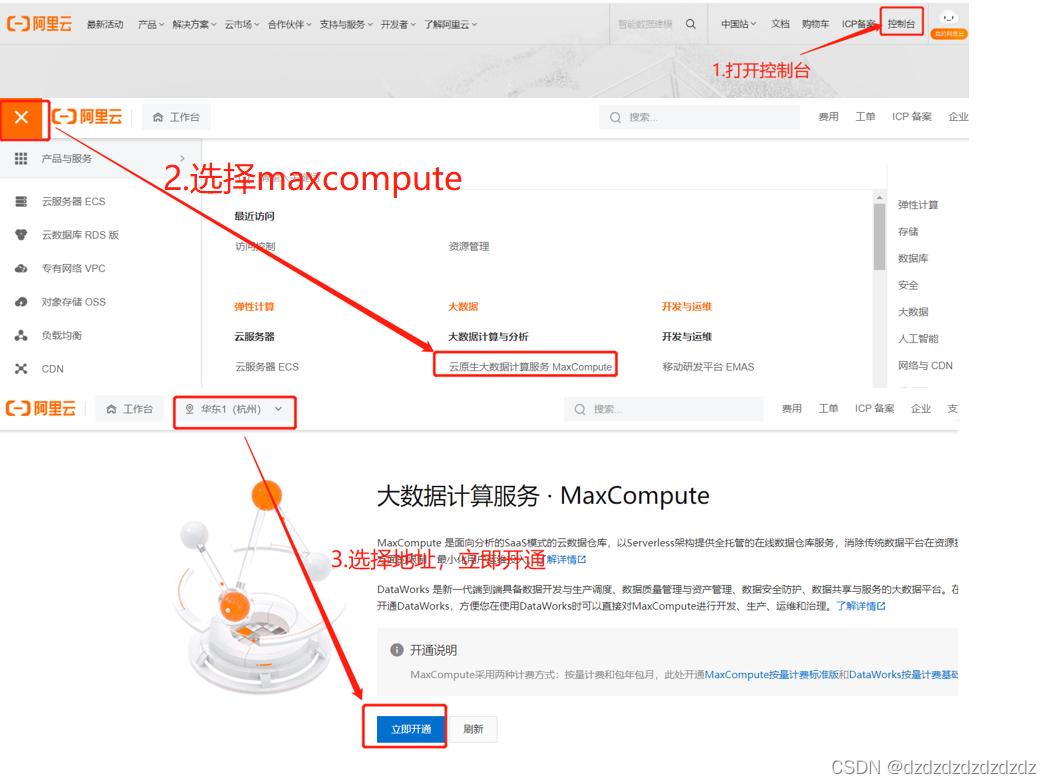
1.首先购买自己服务区的maxcompute:
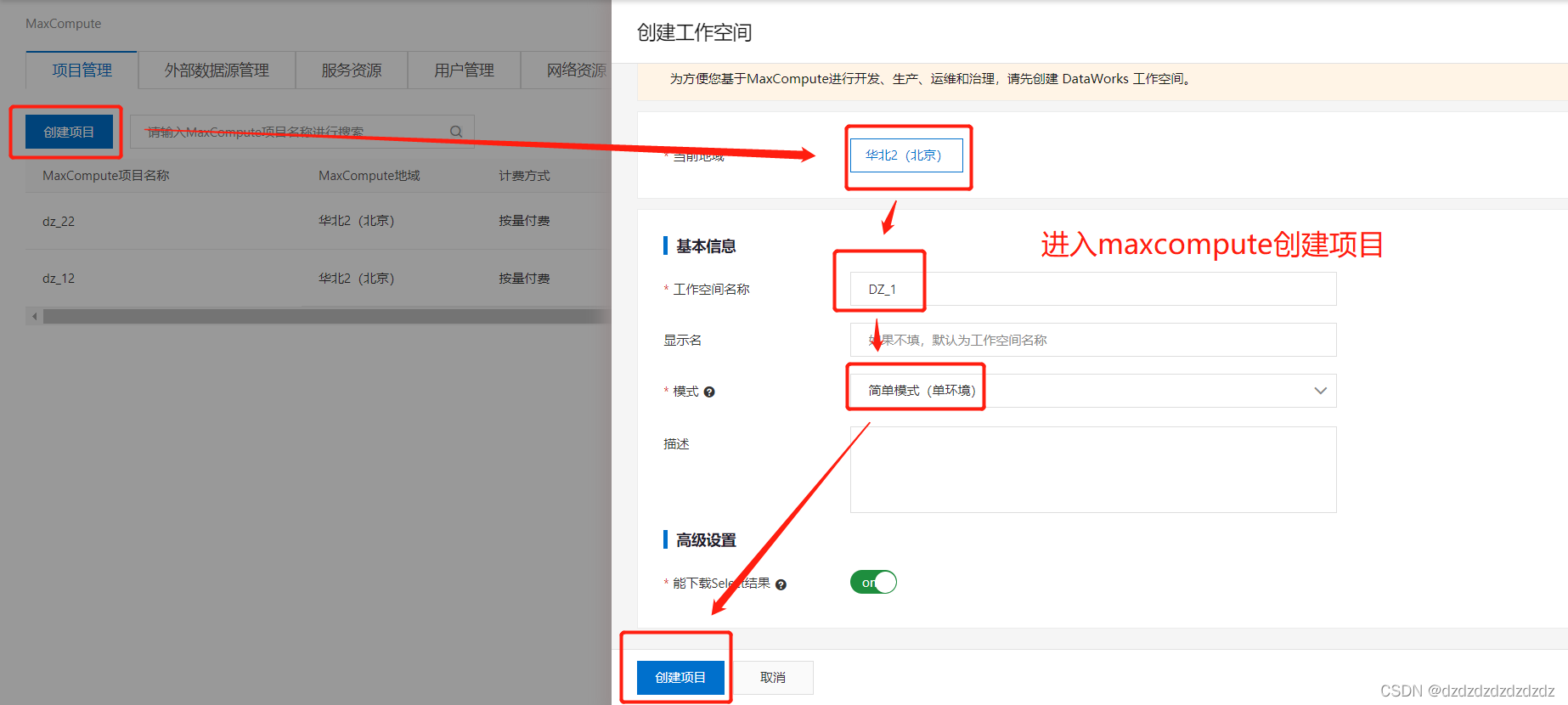
2.创建项目
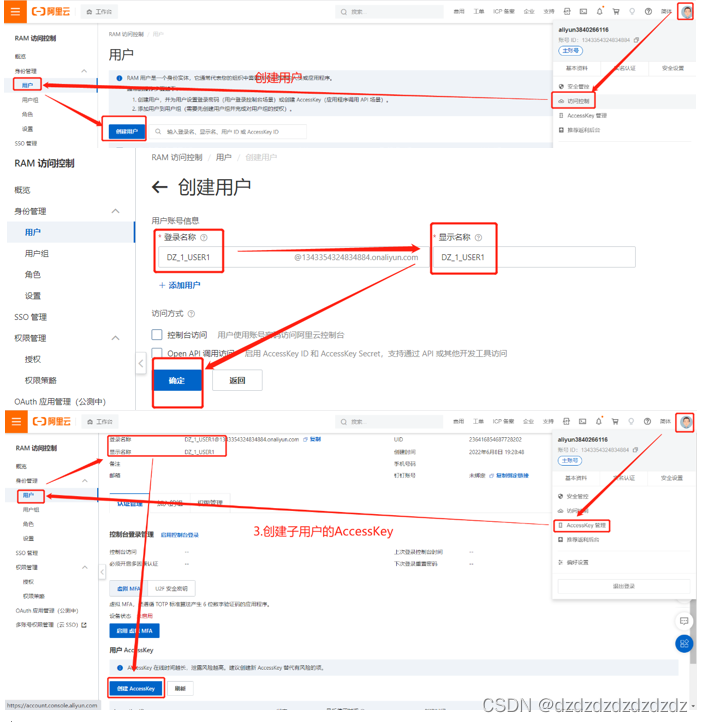
3.增加子用户并保存其AccessKey
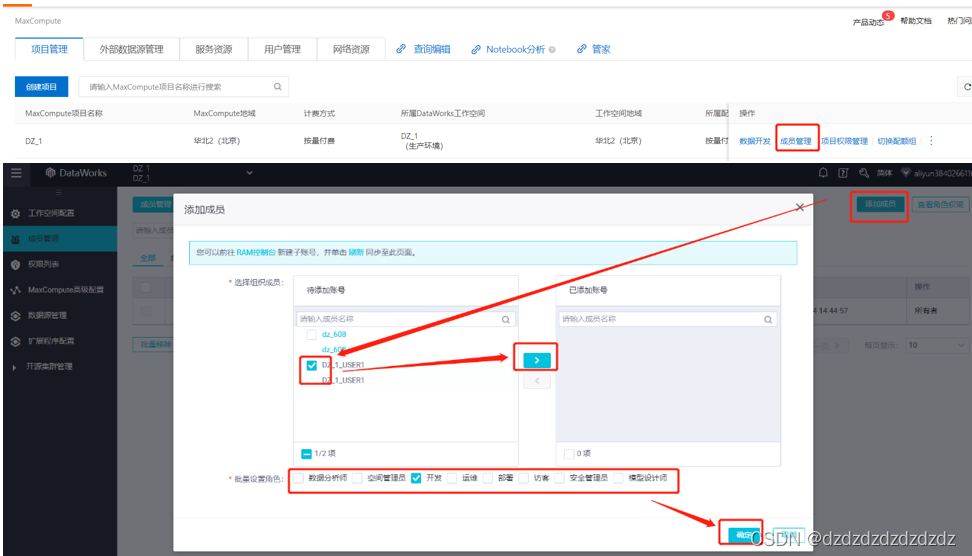
4.给项目增加用户权限
2.1.2创建ODPS
1.创建ODPS
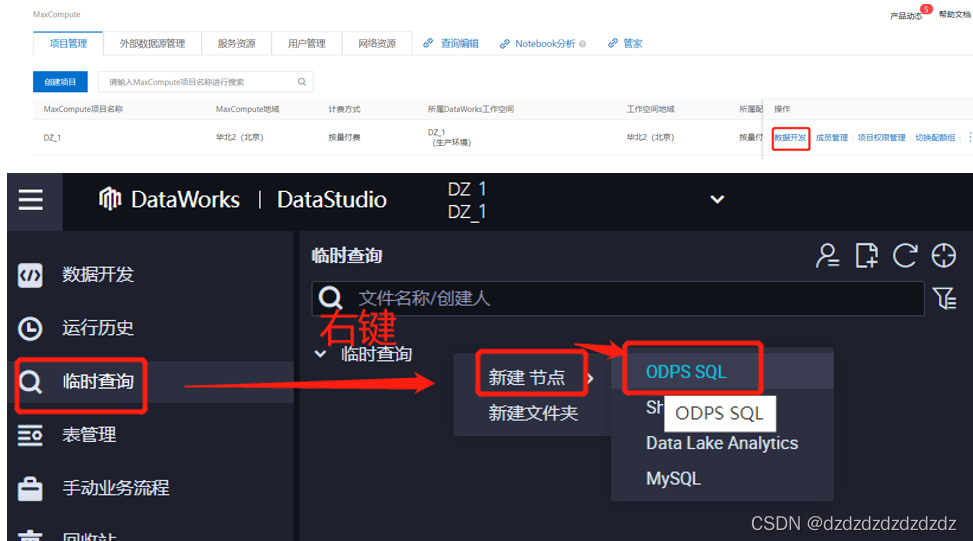
2.创建一个table:create table A (id bigint,name string);
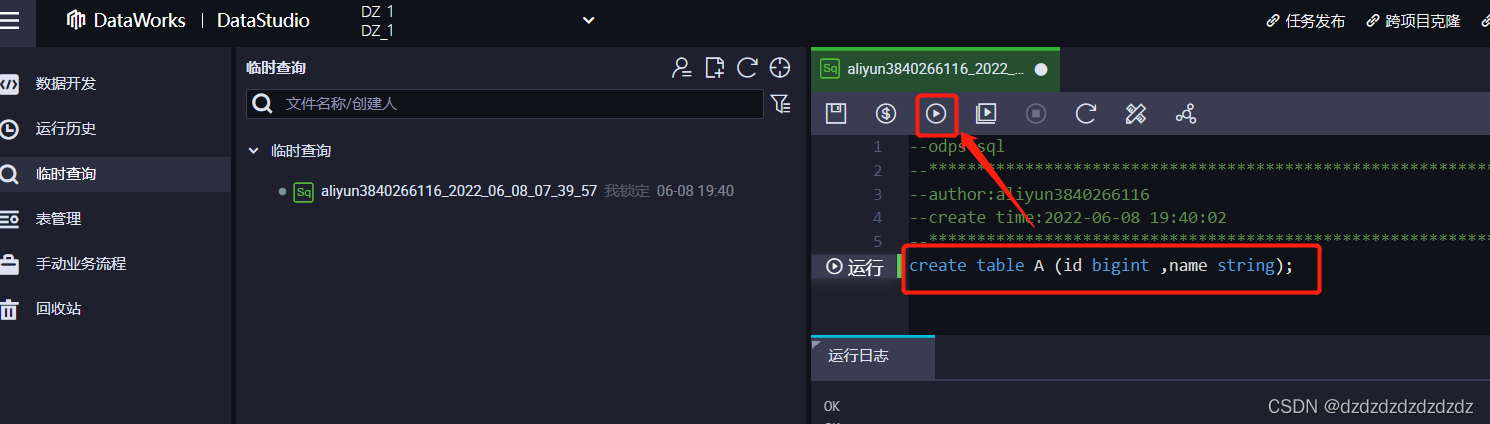
3.查看这个table:desc A;
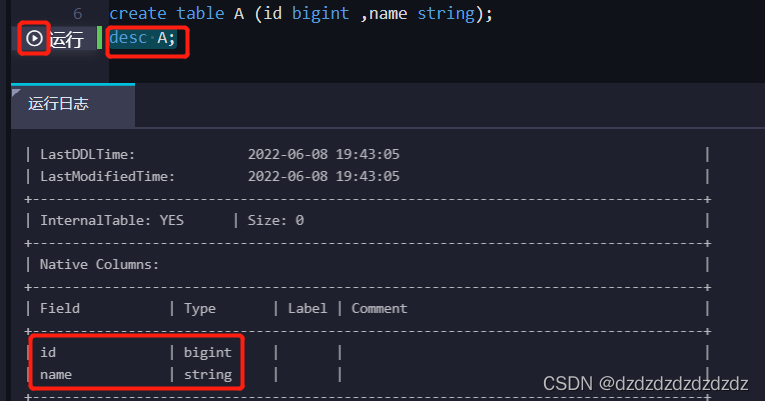
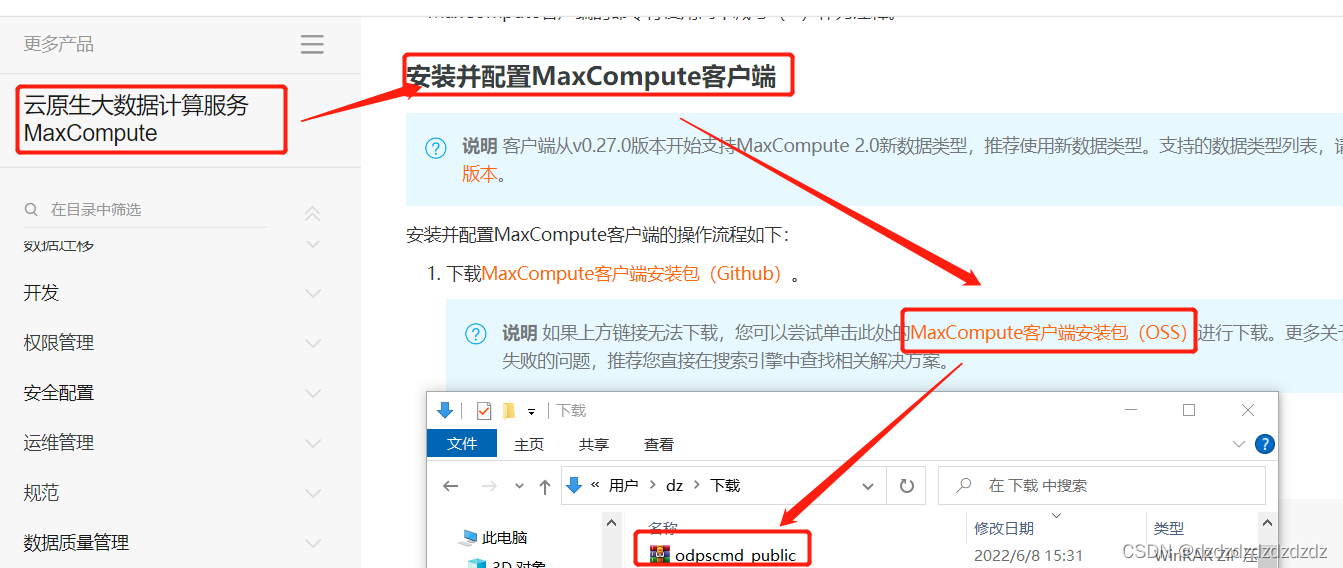
2.1.3maxcompute的命令行客户端odpscmd的安装与基本命令
1.在阿里官网下载安装包并解压
2.加压后打开conf目录下的唯一文件,并根据项目填写相关信息:
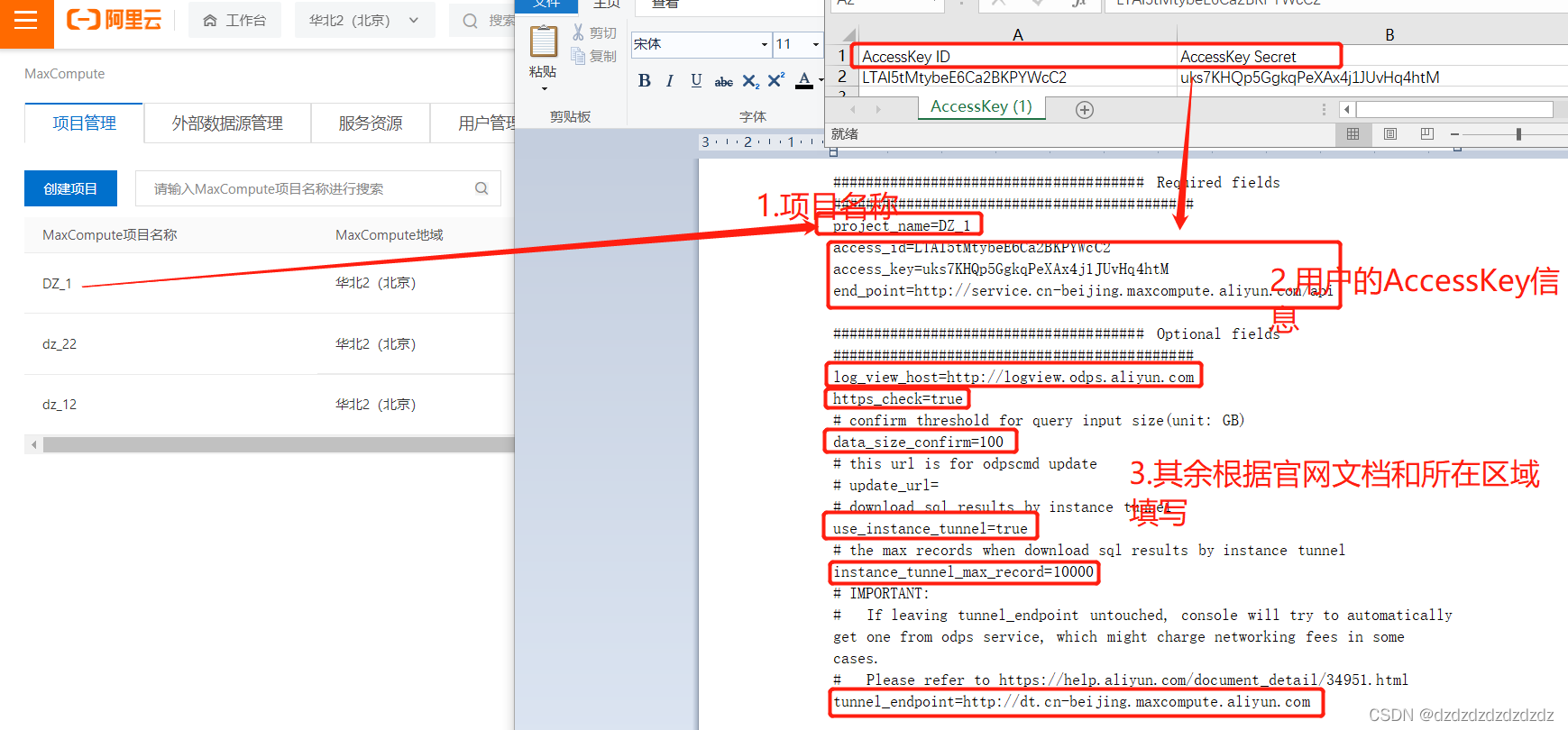
3.配置完文件后在bin目录下打开cmd,输入odpscmd.bat即可打开运行
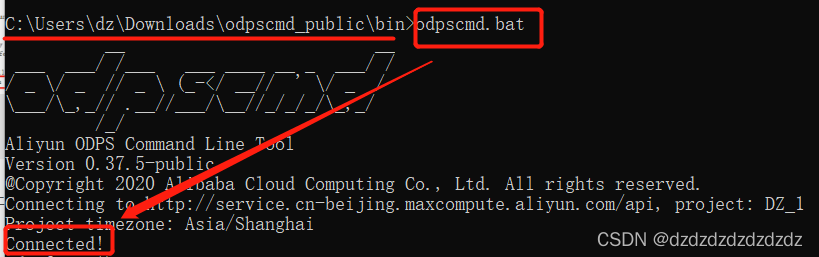
4.输入quit;即可退出odpscmd
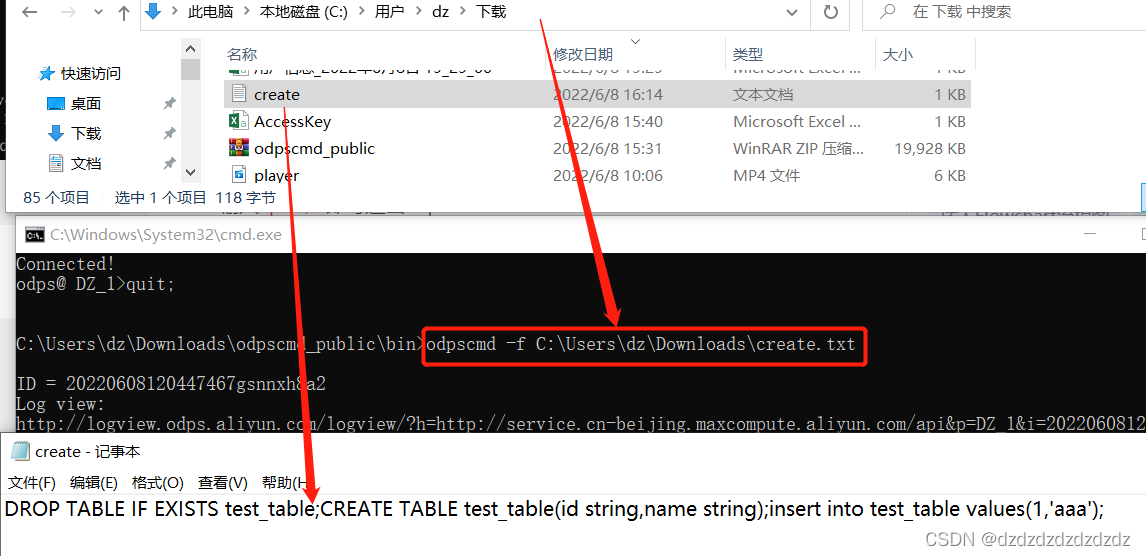
5.-f参数可以执行文件内的命令:odpscmd -f create.txt
6.-e参数可以执行SQL语句:odpscmd -e "select * from test_table;" 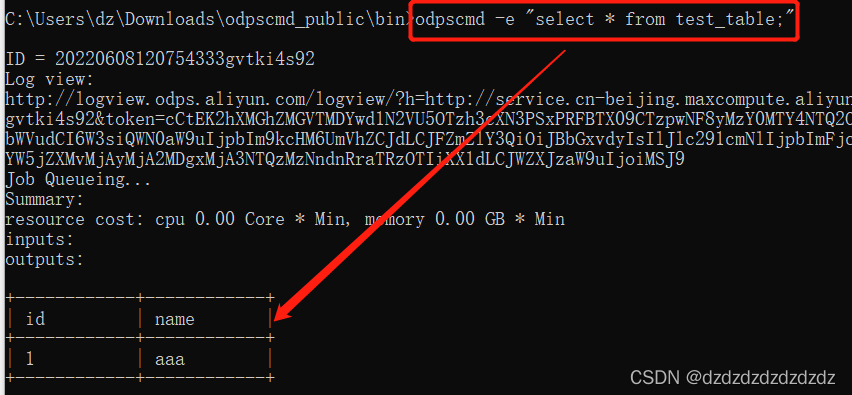
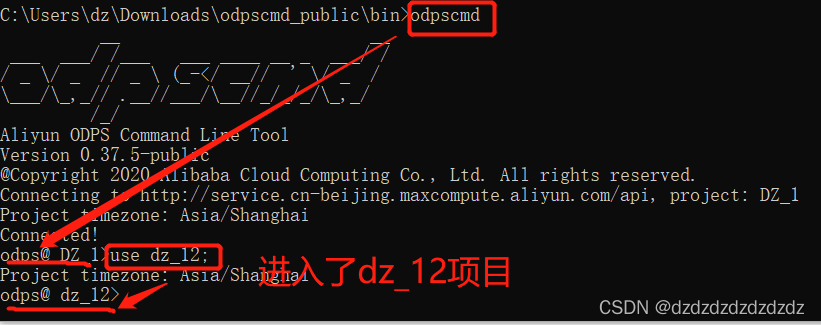
7.使用 use 项目名;即可跳转到用户的另一个项目,前提是用户有多个项目。
2.2数据上传与下载
2.2.1 tunnel批量离线处理
2.2.1.1tunnel上传
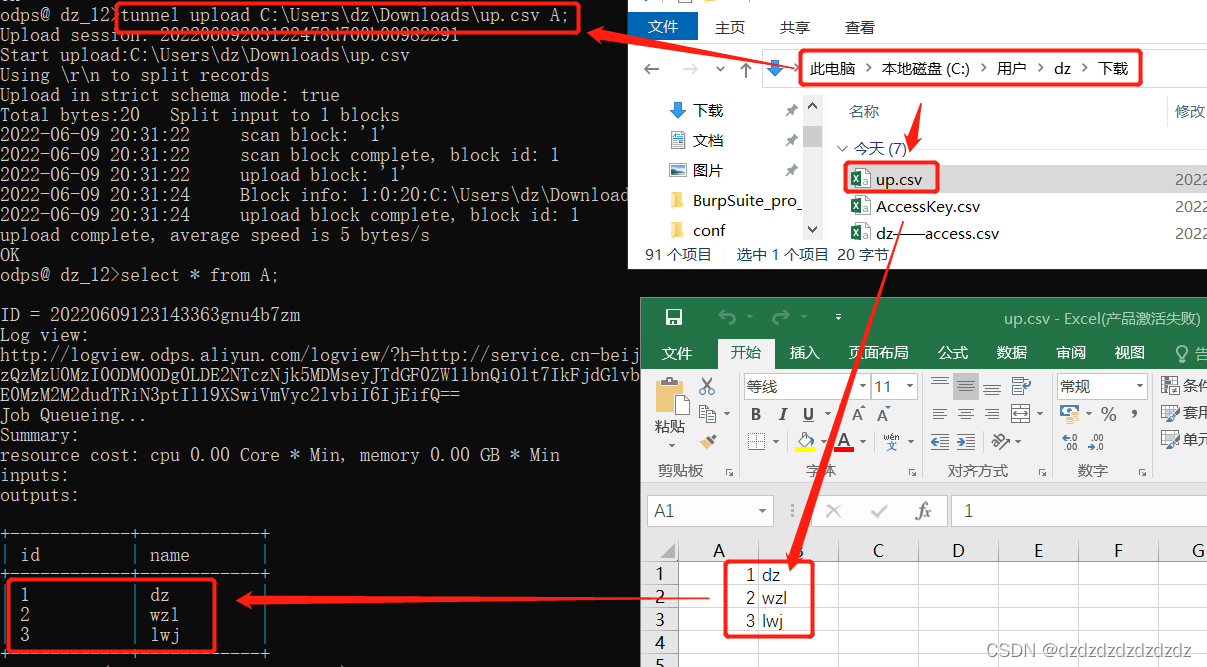
1.追加上传tunnel upload C:\Users\dz\Downloads\up.csv A;
drop table if exists A;#如果表存在删除
create table A(id int,name string);#创造表A,键是id和name
desc A;#查看表A
tunnel help;#查看tunel命令
tunnel upload C:\Users\dz\Downloads\up.csv A;#本地表up.csv内容追加上传到A表;
select * from A;#查看表A
truncate table A;#清理表A里的内容
2.分区表上传
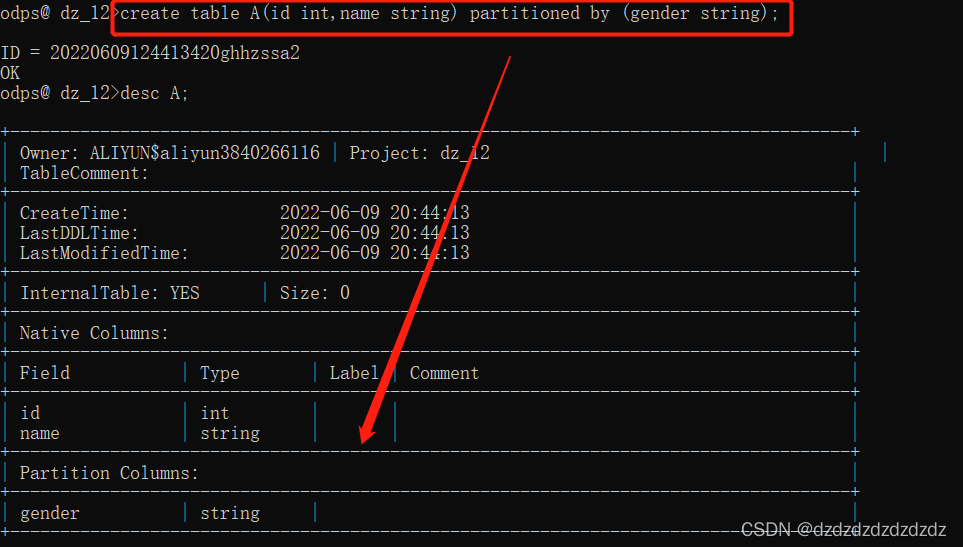
首先创造分区表
create table A(id int,name string) partitioned by (gender string);#按gender创造分区表
然后
tunnel upload C:\Users\dz\Downloads\up_p\up_1.csv A/gender='male' -acp=true;#上传本地表到此分区,没有此分区值则创建
select * from A where gender='male';查看分区值是此的分区表
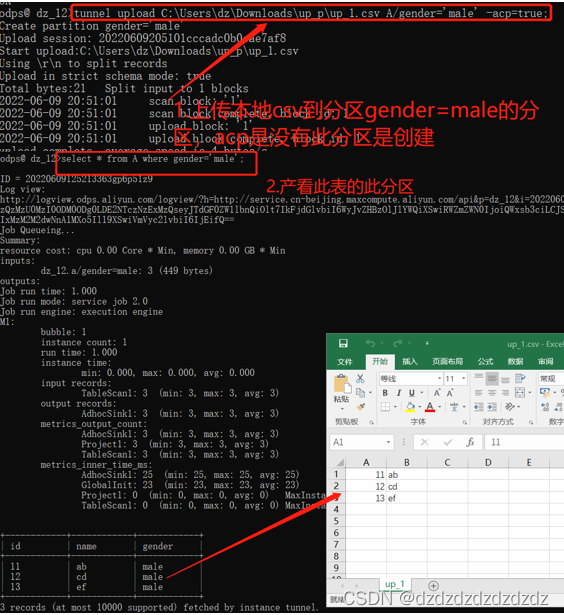
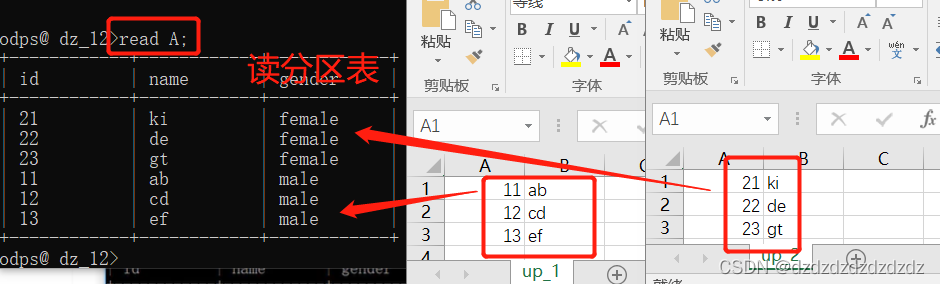
read A;#查看分区表的所有分区
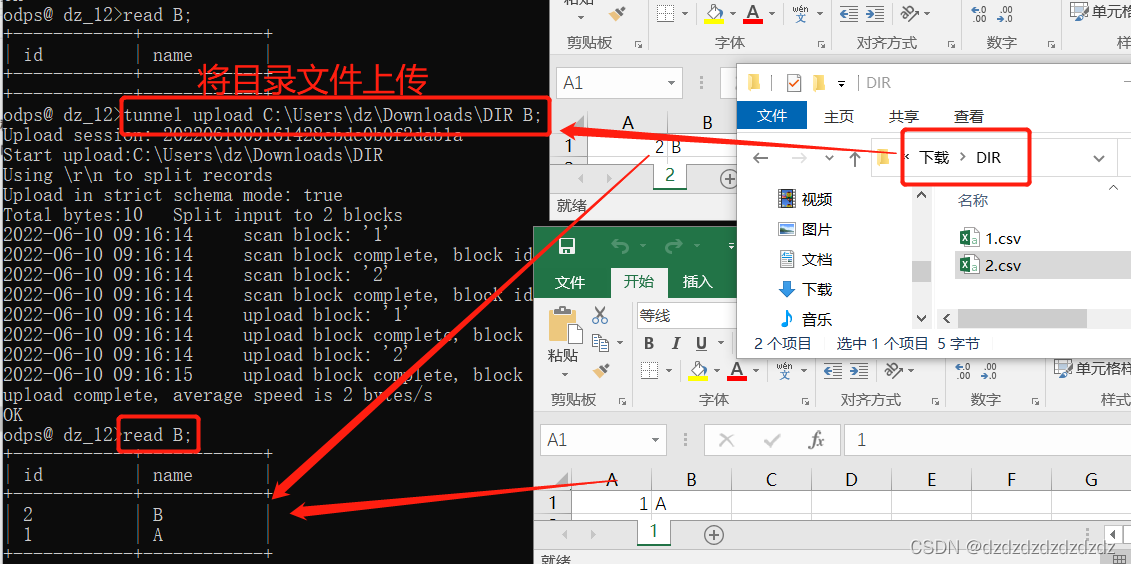
3.文件目录上传
tunnel upload C:\Users\dz\Downloads\DIR B;#将C:\Users\dz\Downloads\DIR下的所有文件上传到表B;
当文件夹内有格式不一样表格时:-dbr=true表示只把格式正确表格录入,错误的表格抛弃;
tunnel upload C:\Users\dz\Downloads\DIR B -dbr=true;#有格式错误的表格,抛弃此表格
4.参数scan扫描
scan=true时,先扫描数据,格式正确,再导入数据;
scan=false时,不扫描数据,直接导入数据;
scan=only时,仅扫描本地数据,扫描完不导入
5.分割符
行分隔符-rd(默认\r\n)和列分隔符-fd(,)
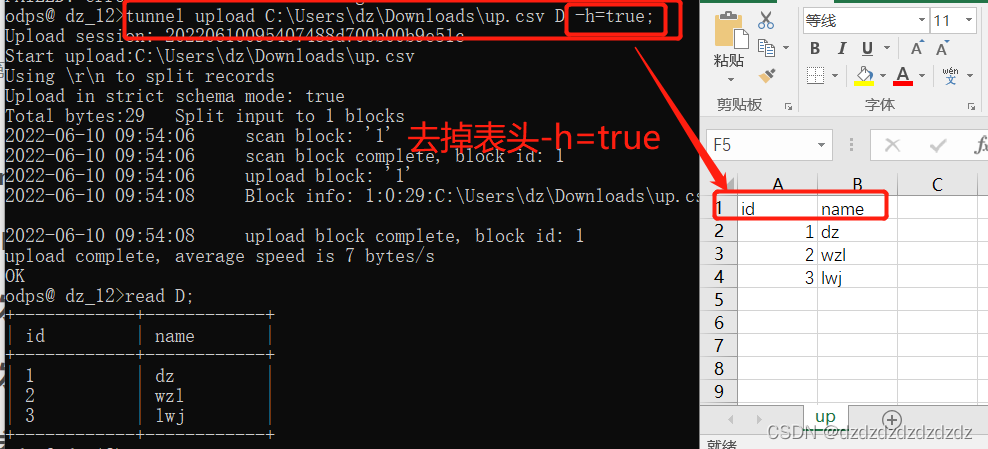
6.第一行表头
去掉csv文件的第一行表头:-h=true

2.2.1.2tunnel下载
1.下载分区表
tunnel download A C:\Users\dz\Downloads\download\A_d.csv;#下载分区表的所有分区
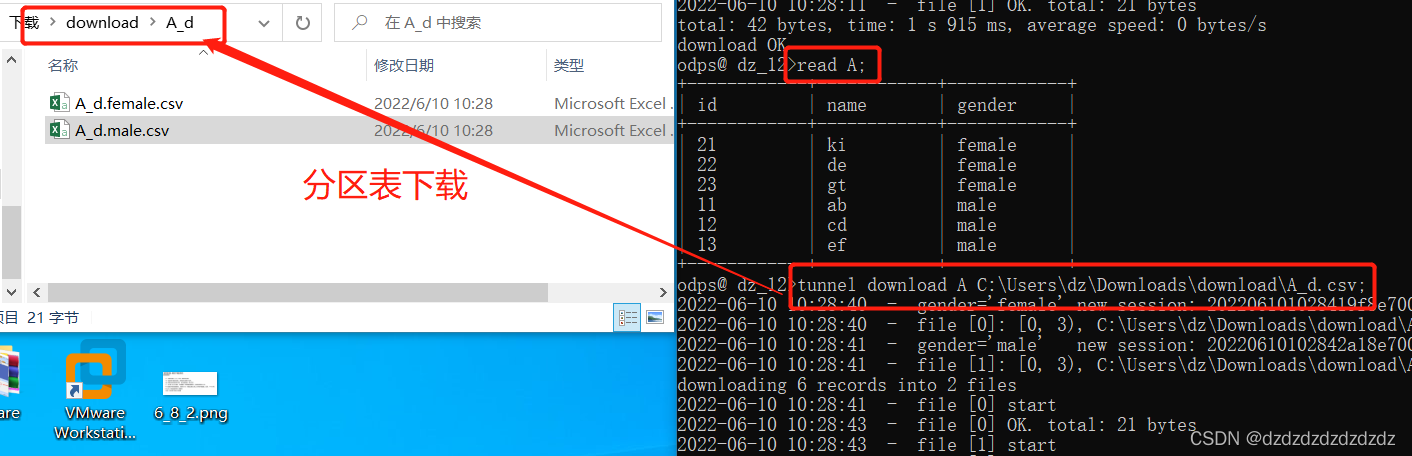
tunnel download A\gender="male" C:\Users\dz\Downloads\download\A_d_male.csv;#下载分区表的指定分区
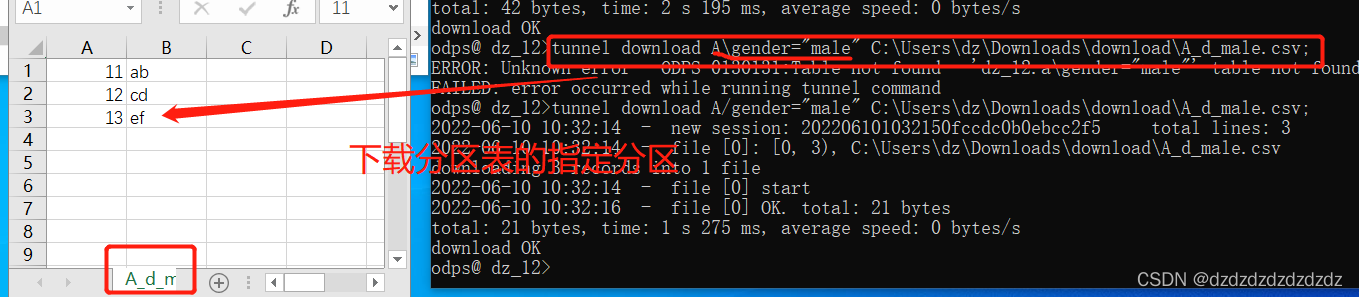
2.下载指定列:
-ci=列序号(序号从0开始)
-cn=列名称
tunnel download B C:\Users\dz\Downloads\download\B_d_ci0.csv -ci=0;
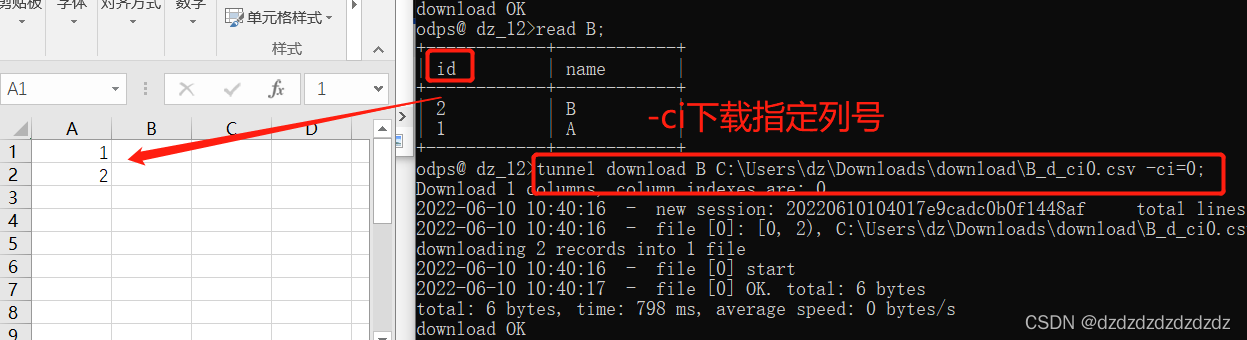
tunnel download B C:\Users\dz\Downloads\download\B_d_cnname.csv -cn="name";

3.代表头下载-h=true
tunnel download B C:\Users\dz\Downloads\download\B_d_h.csv -h=true;

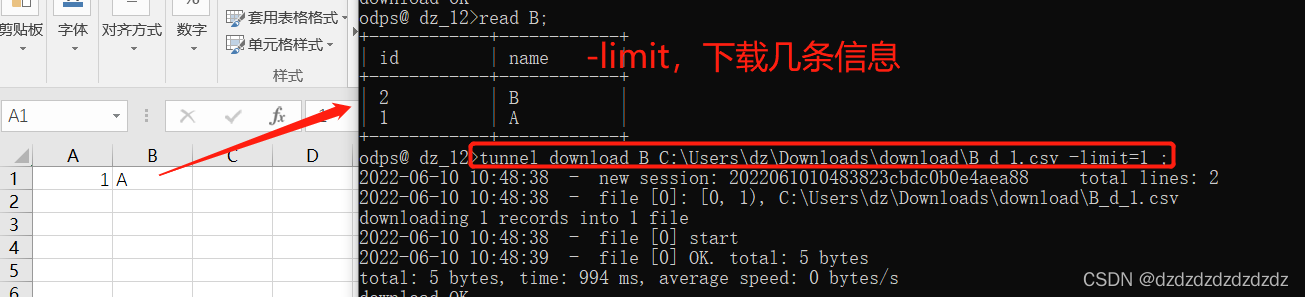
4.只允许下载几条信息:-limit=num;
tunnel download B C:\Users\dz\Downloads\download\B_d_1.csv -limit=1 ;

2.2.2使用javaSDK开发上传下载
1.首先在阿里云官网下载javasdk,并安装eclipse。
2.2.3 datahub实时处理通道

1.创建datahub项目
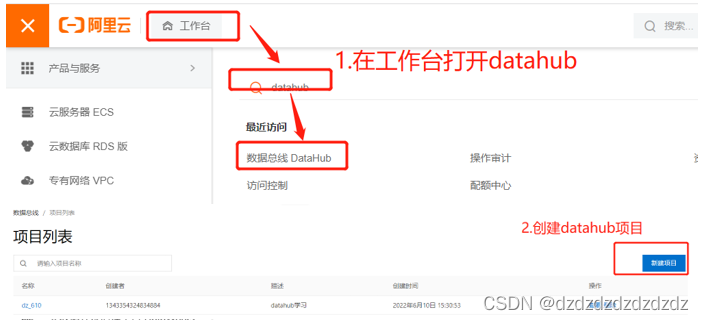
2.在项目中写入topic
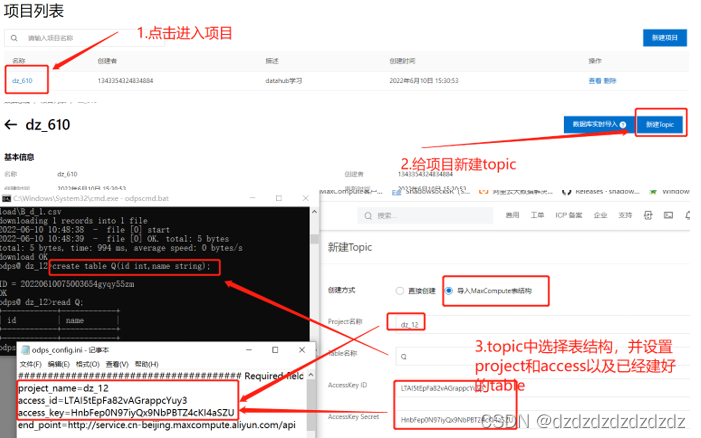
3.在topic中创建connect同步任务。

2.3maxcomputeSQL开发基础
2.3.1DDL
create table t_table01(id bigint,name string);#1.建表
desc t_table01;#2.看表
show create table t_table01;#3.查看建表语句
drop table t_table01;#4.删除表
select * from t_table01;#查看表
create table t_table01_p(id bigint,name string) partitioned by(class string);#1.创建分区表
desc t_table01_p;#2.查看分区表
create table AA as select * from A where gender="male";#使用as拿数据,不拿分区
create table AB like A;#使用like拿了表结构包括分区,不拿数据
alter table A set lifecycle 30;#1.设置分区表的生命周期是30天
alter table A disable lifecycle;#2.撤销分区表生命周期
select * from A where gender="male";#1.查看分区表,需要指定分区where
alter table A add if not exists partition(gender="unknown");#2.分区表增加分区gender=“unknown”
insert into A partition(gender="unknown") select 7,"someone";#3.指定分区unknow插入一条(7,someone)的数据
alter table A partition(gender="unknown") rename to partition(gender="trans");#4.将unknown分区名改为trans
alter table A merge partition(gender="male"),partition(gender="trans") overwrite partition(gender="unknow") purge;#5.将male和trans分区合并为unknow分区
alter table A rename to a_new;#6.修改表名A为a_new
alter table a_new add columns(desc string);#7.表加一列
create view v as select * from a_new;#1.创建视图
2.3.2DML
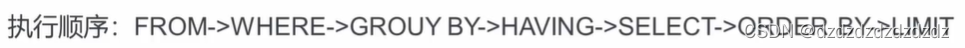
1.查询
list tables;#1.列出库内所有的表
select name,gender from aa;#2.查看aa表的name和gender两列
select name,gender from aa group by name,gender;#3.通过分组group by对这两列进行去重
select distinct name,gender from aa;#4.通过distinct对这两列进行去重
select * from aa limit 2;#5.查看aa表前两行
select * from (select * from aa where gender = 'female') a join (select * from aa where id = '21' and name = 'ki')b on a.id = b.id;#6.子查询
2.插入
insert into aa values(10,'dz','female');#1.aa表插入一行数据
create table aa2 like aa;#2.做一个aa的备份表,拿结构不拿数据
insert into aa2 select * from aa;2.把aa的数据全追加到aa2
insert overwrite table aa2 select * from aa;2.把aa的数据全覆盖到aa2,aa2里原数据删掉了
3.分区表
create table t_class_p (id int,name string)partitioned by(gender string);#1.创建分区表,gender分区
from aa insert into t_class_p partition(gender = '1') select id,name where id = 10 insert into t_class_p partition(gender = '2') select id,name where id = 11 insert into t_class_p partition(gender = '3') select id,name where id = 12;#2.多路输出,从aa表给分区表分别插入三个数据
set odps.sql.allow.fullscan =true;#3.设置分区表可以全局扫描
select * from t_class_p;#4.查询分区表所有内容
4.交、并、补、join
create table a1 as select * from aa where gender="female";#1.从aa表里分出gender为female的建表a1
create table a2 as select * from aa where gender="male";#2.从aa表里分出gender为male的建表a2
select id from a1 union all select id from a2;#3.a1表的id和a2表的id通过unio all求并集
select id from a1 union select id from a2;#4.使用union并集去重
select id from a1 intersect all select id from a2;#5.a1表的id和a2表的id通过intersect求交集
select id from a1 except all select id from a2;#6.使用except all求补集,在a1存在但在a2不存在
2.3.3内置函数
1.数学运算与字符处理
select 0.5*10*20*sin(60/180*3.1415926);#1.sin三角函数
select ceil(3.1415926),floor(3.1415926),round(3.1415926),trunc(3.1415926),conv('3.1415926',10,2);#2.ceil向上取整,floor向下取整,round四舍五入,trunc截取,conv10进制转换2进制。
select rand();#3.随机值,可以给种子
select abs(-2);#4.abs取绝对值
select power(-2,5);#5.-2的5次方
select sqrt(16);#6.16的均方根
select length("dacadc中文");#7.字符串长度,每个中文1个字符
select length("dacadc中文");#8.字符串长度,每个中文3个字符
select char_matchcount('asdf','asbrgdgf');#9.字符串1里面有几个在字符串2里面出现
select is_encoding("测试","utf-8");#10.测试编码是否utf-8
select instr("sdsdvfg","s");#11第2个字符在第1个字符的哪一个位置第一次出现,以1开头计数
select substr("dasdf",2,3);#从第2个字符开始剪切,剪切长度为3
2.日期处理和窗口函数
select getdate();#1.查询系统日期
select datediff(datetime '2022-06-18 20:00:00',datetime '2022-06-15 19:00:00','dd');#2.查看两个时间相差几天
select unix_timestamp(datetime '2022-06-13 20:00:00');#3.时间转换成时间戳
select from_unixtime(1655121600);#4.时间戳转换成时间
3.聚合和其他函数
在这里插入代码片
2.4UDF开发基础
用户自定义函数
2.5MR开发基础
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)“和"Reduce(归约)”,是它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。 当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
创建:map、reduce、drive三个java文件
2.6Graph开发基础
2.7权限与安全
show grants;#1.查看此用户在此项目下的权限
3.大数据开发与治理平台Dataworks
3.1数据集成
1.首先新建数据源,这里建mysql数据源

3.2数据开发
3.3任务运维
3.4数据管理
4.数据可视化分析平台Quick Bi
5.机器学习平台PAI
1.开通阿里云pai
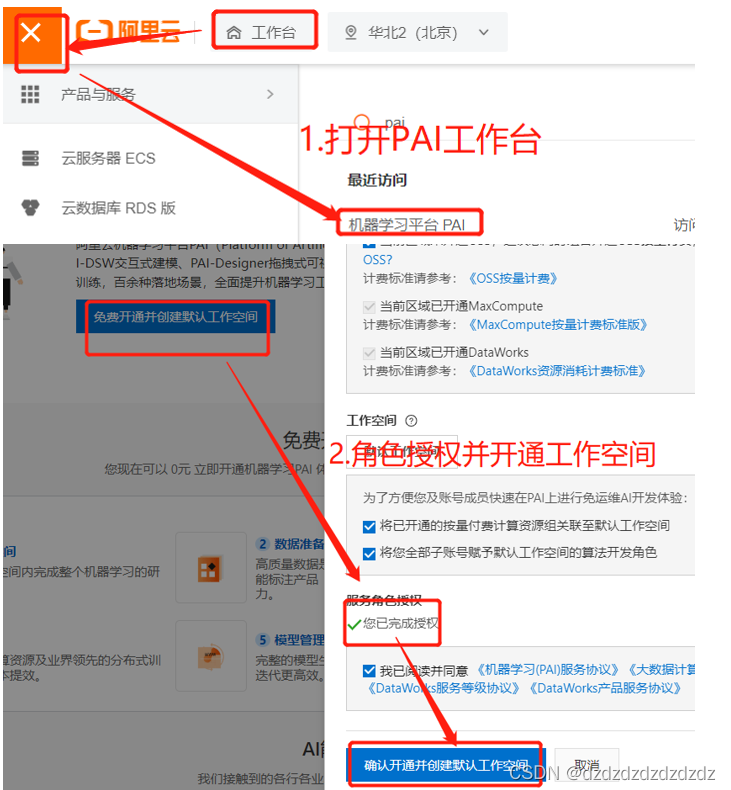
2.创建工作流并进入
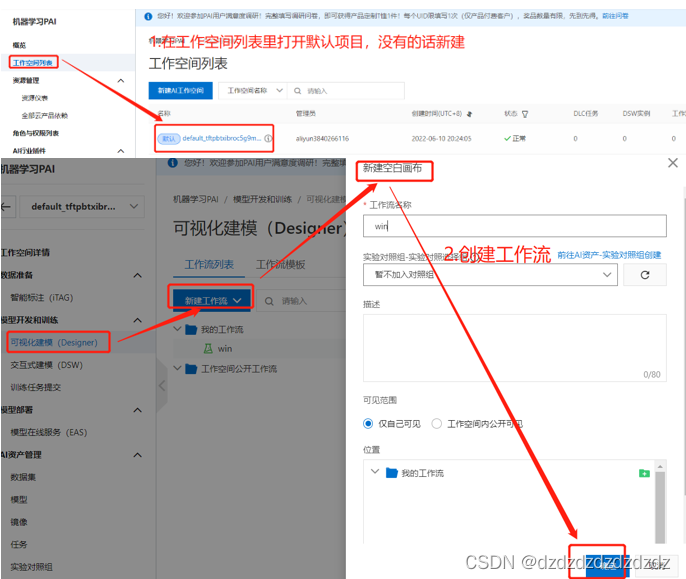
3.下载数据集,这里用红酒分类,然后把数据导入到工作空间。
操作可参考:https://blog.csdn.net/wyn_365/article/details/107284561