
paper:https://arxiv.org/pdf/2303.15413.pdf
文章目录
Overview
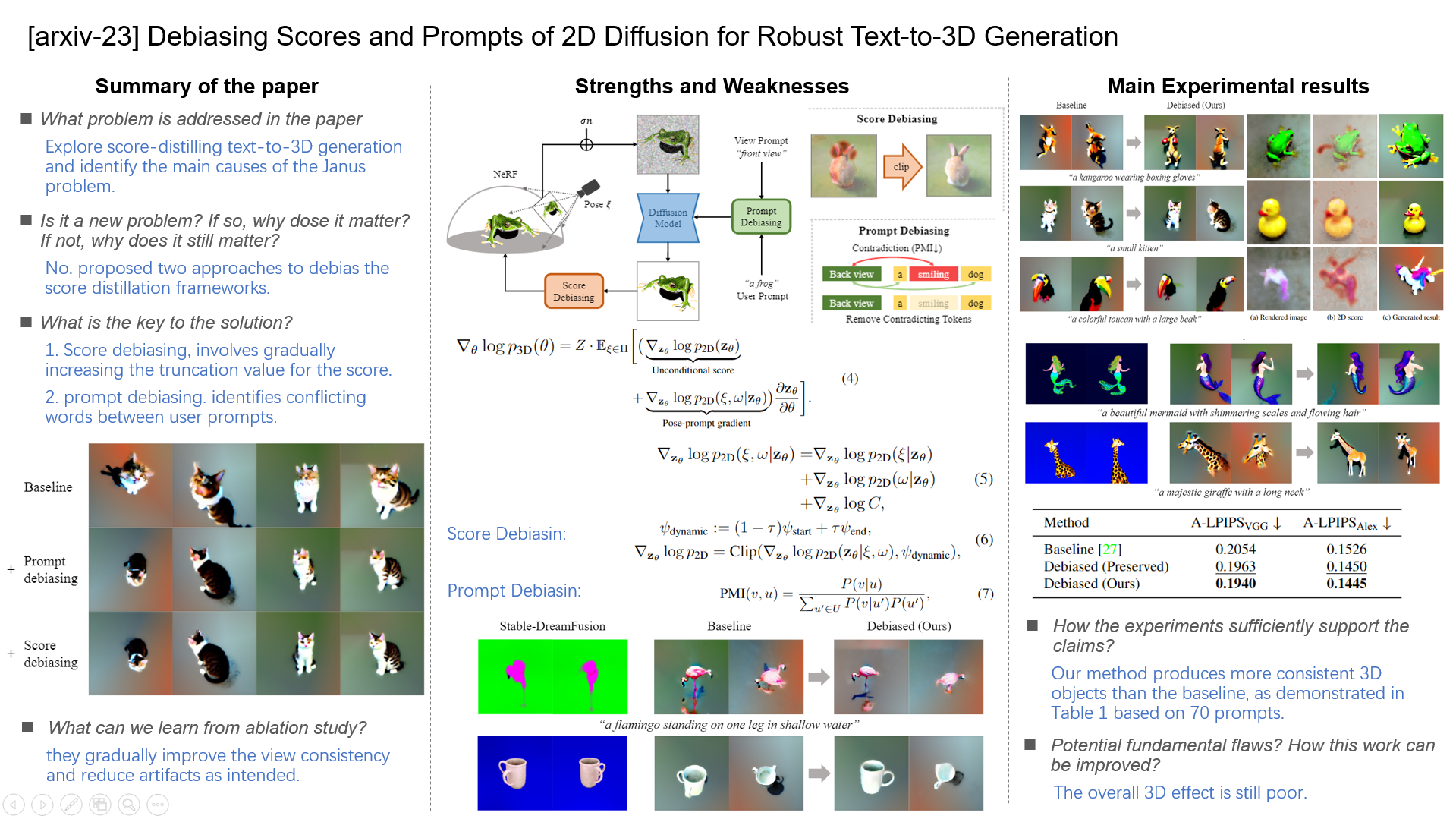
2. Score Distillation and the Janus Problem
Density function:: given a set of uniformly sampled viewpoints Π and user prompt ω.

By using this formulation, we avoid using Jensen’s inequality, in contrast to [27](Score Jacobian Chaining: Lifting Pretrained 2D Diffusion Models for 3D Generation).
Applying the logarithm to each side of the equation yields:

Using the chain rule, we obtain:

where Z = |Π| is a constant. The term in bracket, is practically estimated by diffusion models.
This is further expanded by applying Bayes’ rule as follows:

- The first gradient term, reflecting the unconditional score modeled by 2D diffusion models [5, 25], contains a bias that affects images viewed closely from specific viewpoints during early 3D optimization when zθ is noisy.
- the pose-prompt gradient in Eq. 4 is guidance [3,6,7,25] that drives the rendered image to better represent a specific camera pose and user prompt. The term is further expanded:

where C is defined as : which represents the pointwise conditional mutual information (PCMI).


Figure 2. Illustration of our framework. We propose prompt and score debiasing techniques to estimate robust and unbiased gradients of the 3D parameters w.r.t. the viewpoints.
3. Score Debiasing

Figure 3 . This visualization demonstrates that erroneous 2D scores result in critical artifacts, e.g., additional legs, beaks, and horns in this figure.
If the unconditional score, the term is biased to ward some viewing direction. It can negatively affect the 3D consistency and realism of generated objects through the chain rule(Eq. 3).
large magnitudes in the user prompt gradient can also cause issues by introducing text-related artifacts that are not present in the image rendered from a 3D field.
Such artifacts include extra faces, beaks, and horns (see Fig. 1 and Fig. 3), which are unrealistic or inconsistent with the 3D object’s structure.
Hence, adjusting this gradient is necessary to reduce the artifacts and improve the realism of the generated 3D objects. However, the 2D bias that flows into the 3D field has hardly been formulated or adjusted for better optimization and 3D consistency.
Dynamic thresholding of 2D-to-3D scores.
we propose an effective method that dynamically truncates the scores in order to mitigate the effects of bias and artifacts in the predicted 2D scores. Specifically, we linearly increase the truncation value throughout the optimization:


4. Prompt Debiasing
Identifying contradiction utilizing language models.
The prompt gradient term may cancel out the pose gradient term needed for the view consistency of generated 3D objects, as we can derive from Eq. 5

Figure 4. Samples from Stable Diffusion [18] given a text prompt with contradiction. Despite “Back view of” is given in the prompts, the word “smiling” in the prompt makes diffusion models biased towards the front view of an object.
we propose a method for identifying contradictions using language models trained with masked language modeling (MLM). Specifically, let V represent a set of possible view prompts, and let U be a set of size 2, which contains the presence and absence of a word in the user prompt for brevity. We then compute the following:

P (u) is a user-defined faithfulness. If P (u) = 1, the word will never be removed from the user prompt.
Eq. 7 is equal to the pointwise mutual information (PMI) since:

Reducing discrepancy between view prompts and object-space poses.
we make practical adjustments to the range of view prompts, such as reducing the azimuth range of the “front view” by half. Furthermore, we search for precise view prompts [16, 27] that give us improved results.
5. Comparison with Baseline
As shown in the qualitative results in Fig. 1, our methods reduce view inconsistencies in the 3D objects and mitigate the so-called Janus problem. This improvement come with little overhead compared to the baseline.

Figure 1. Comparison between the baseline (SJC [27]) and ours. Our debiasing methods qualitatively reduce view inconsistencies in zero-shot text-to-3D and the so-called Janus problem.
Our method produces more consistent 3D objects than the baseline, as demonstrated in Table 1 based on 70 prompts. Note that removing contradictions in prompts leads to better results.

Table 1. Quantitative evaluation. The best values are in bold, and the second best are underlined. Preserved means user prompts are preserved, i.e., P (u) = 1 for all u.

Figure 5. Improvement of view consistency through prompt and score debiasing. The baseline is original SJC [27], andPrompt and Score denote prompt and score debiasing, respectively. The given user prompt is “a smiling cat,” and the images are rendered from arbitrary viewpoints.
Figure 5 demonstrates that they gradually improve the view consistency and reduce artifacts as intended.
Conclusion
In this paper, we formulate and identify the sources of the Janus problem in zero-shot text-to-3D generation. In this light, we argue that debiasing the prompts and raw 2D scores is essential for the realistic generation. Therefore, we propose two methods that increase the quality and are applicable to existing frameworks with little overhead without 3D supervision, showing potential for future research in this promising area.